UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xd5 in position 0: invalid continuation byte
出现原因:CSV文件不是UTF-8进行编码,而是用gbk进行编码的。jupyter-notebook使用的Python解释器的系统编码默认使用UTF-8.
解决方式有两种;
第一种:
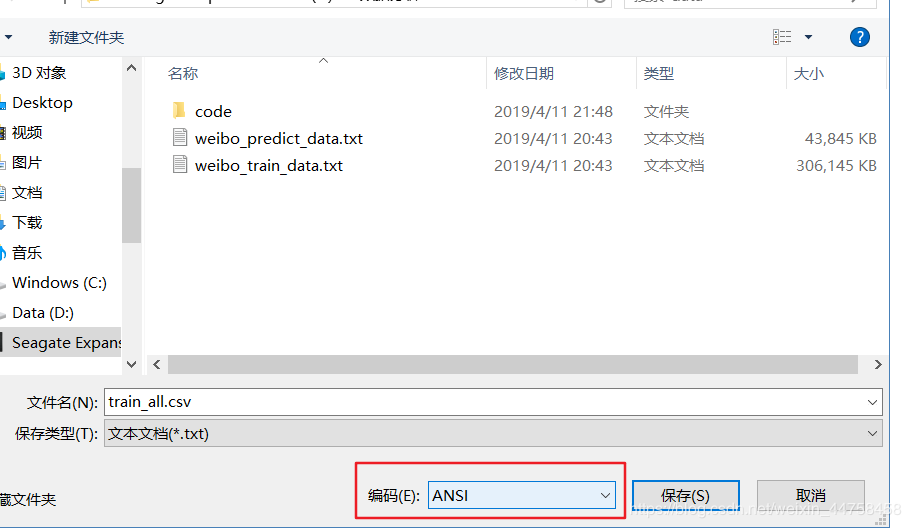
1.找到使用的csv文件--->鼠标右键--->打开方式---->选择记事本
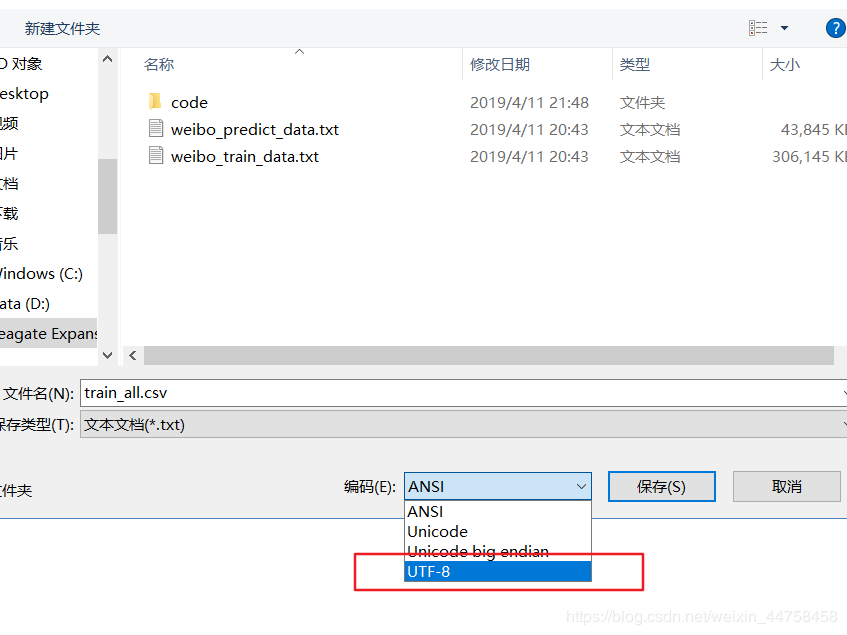
2.打开文件选择“文件”----->"另存为“,我们可以看到默认编码是:ANSI,选择UTF-8重新保存一份,再使用pd.read_csv()打开就不会保存了
第二种:
使用pd.read()读取CSV文件时,进行编码
pd.read(filename,encoding='gbk')
比如:
with open('E:/***.csv', 'r', encoding="gbk") as f:
————————————————
版权声明:本文为CSDN博主「砍柴樵夫」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_44758458/article/details/89220989