3.11 随机初始化(Random+Initialization)
当你训练神经网络时,权重随机初始化是很重要的。对于逻辑回归,把权重初始化为0当然也是可以的。但是对于一个神经网络,如果你把权重或者参数都初始化为0,那么梯度下降将不会起作用。

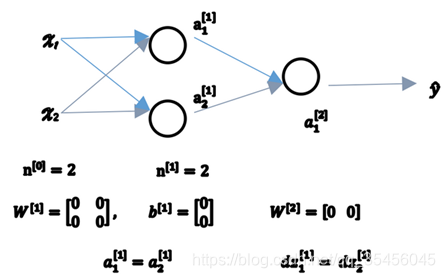

由此可以推导,如果你把权重都初始化为0,那么由于隐含单元开始计算同一个函数,所有的隐含单元就会对输出单元有同样的影响。一次迭代后同样的表达式结果仍然是相同的,即隐含单元仍是对称的。通过推导,两次、三次、无论多少次迭代,不管你训练网络多长时间,隐含单元仍然计算的是同样的函数。因此这种情况下超过1个隐含单元也没什么意义,因为他们计算同样的东西。当然更大的网络,比如你有3个特征,还有相当多的隐含单元。
如果你要初始化成0,由于所有的隐含单元都是对称的,无论你运行梯度下降多久,他们一直计算同样的函数。这没有任何帮助,因为你想要两个不同的隐含单元计算不同的函数,这个问题的解决方法就是随机初始化参数。你应该这么做:把W^([1])设为np.random.randn(2,2)(生成高斯分布),通常再乘上一个小的数,比如0.01,这样把它初始化为很小的随机数。然后b没有这个对称的问题(叫做symmetry breaking problem),所以可以把 b 初始化为0,因为只要随机初始化W你就有不同的隐含单元计算不同的东西,因此不会有symmetry breaking问题了。相似的,对于W([2])你可以随机初始化,b([2])可以初始化为0。



事实上有时有比0.01更好的常数,当你训练一个只有一层隐藏层的网络时(这是相对浅的神经网络,没有太多的隐藏层),设为0.01可能也可以。但当你训练一个非常非常深的神经网络,你可能会选择一个不同于的常数而不是0.01。下一节课我们会讨论怎么并且何时去选择一个不同于0.01的常数,但是无论如何它通常都会是个相对小的数。
好了,这就是这周的视频。你现在已经知道如何建立一个一层的神经网络了,初始化参数,用前向传播预测,还有计算导数,结合反向传播用在梯度下降中。
