爬取所有英雄头像
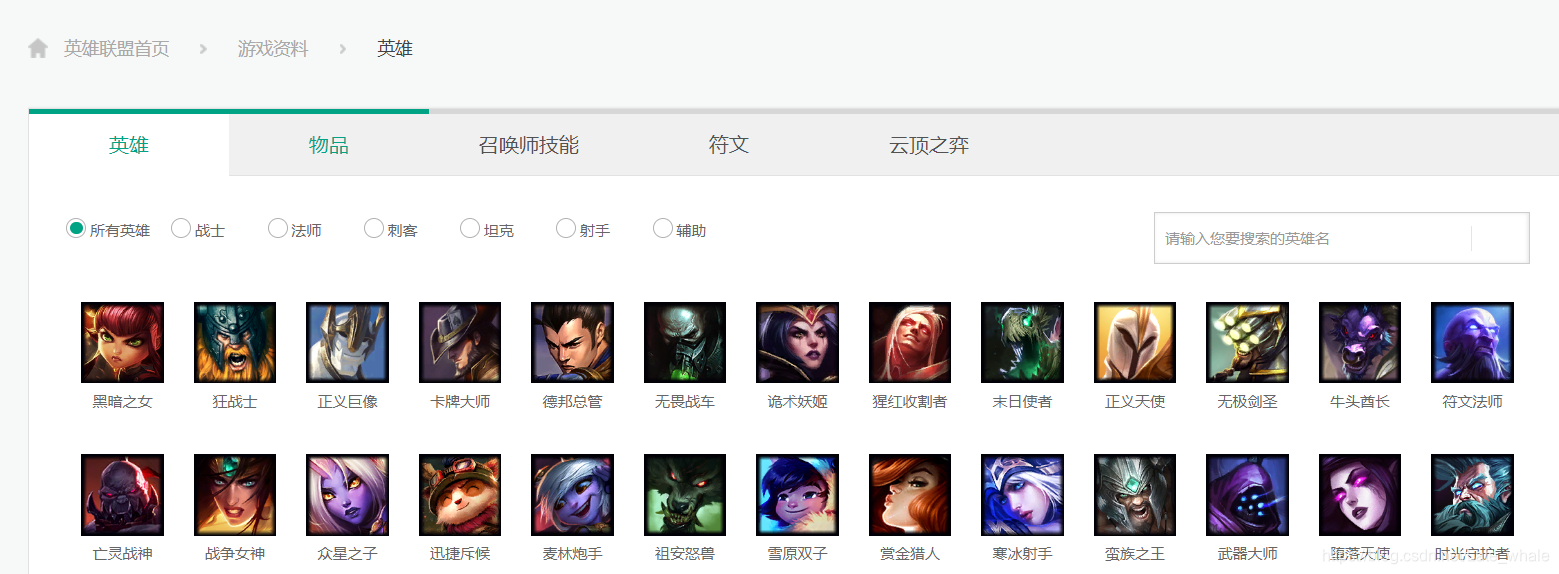
选择爬取目标
这里我们选择
https://lol.qq.com/data/info-heros.shtml
寻找图片位置
通过浏览器的检查功能,寻找图片所在位置
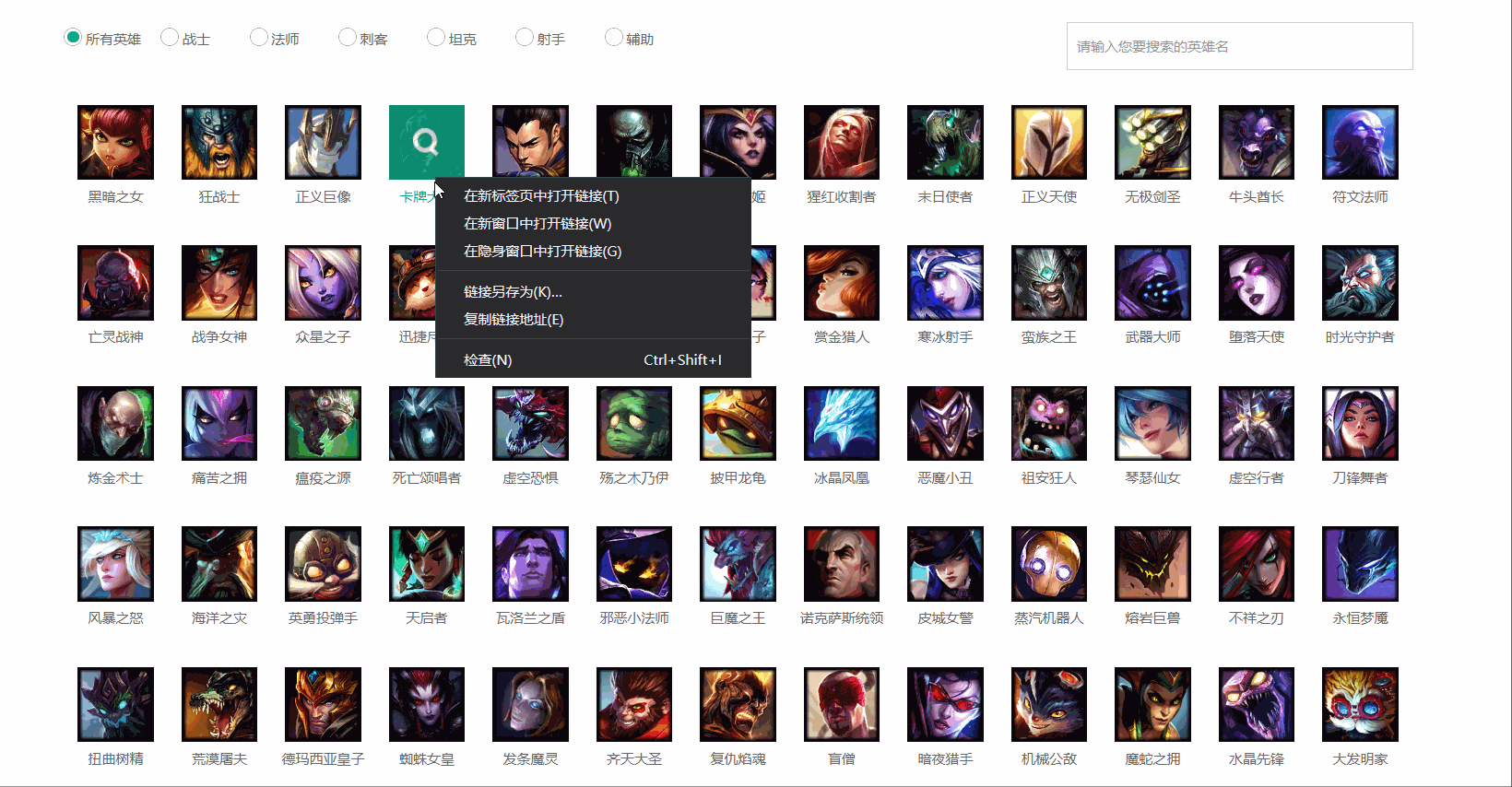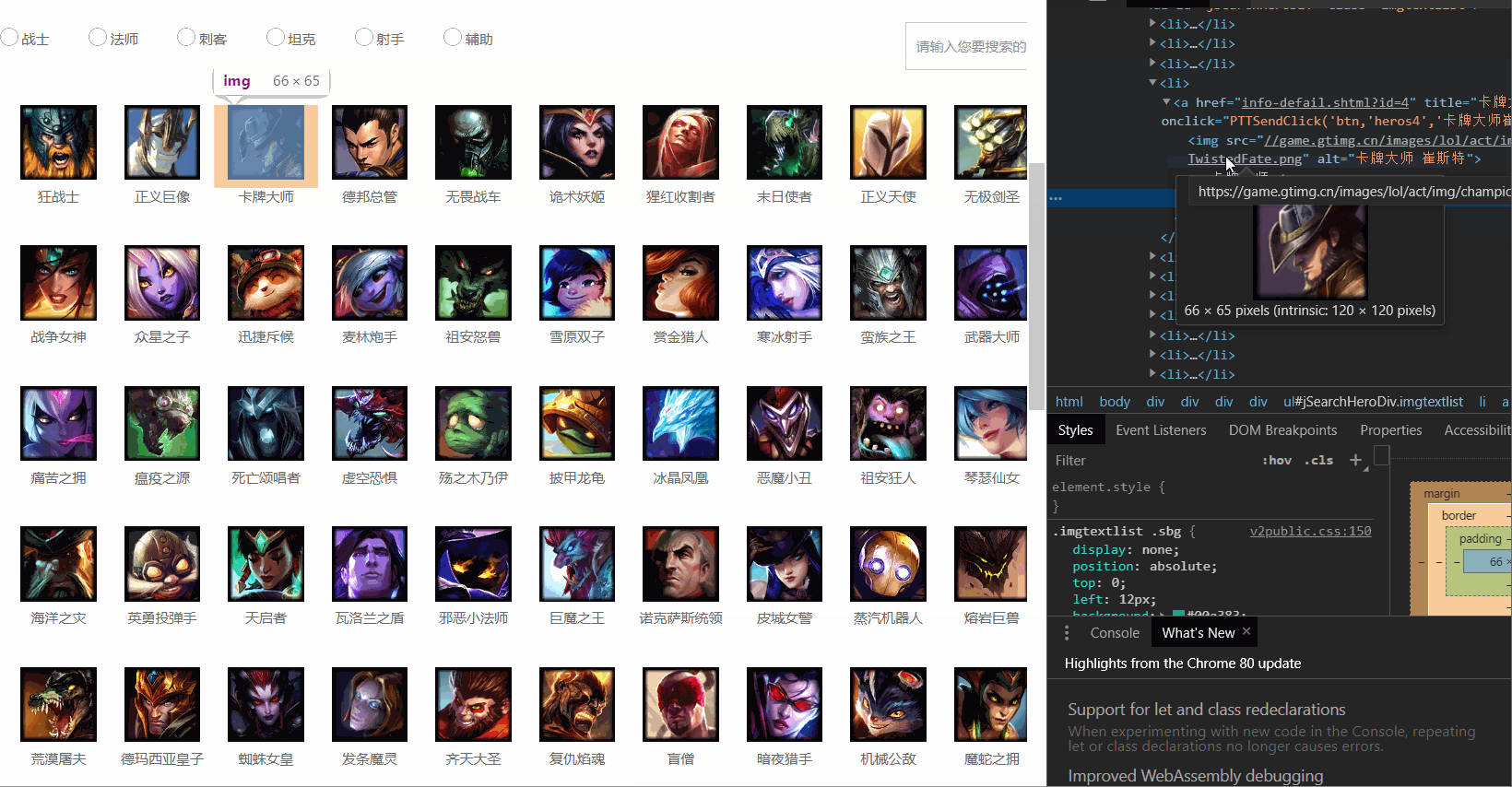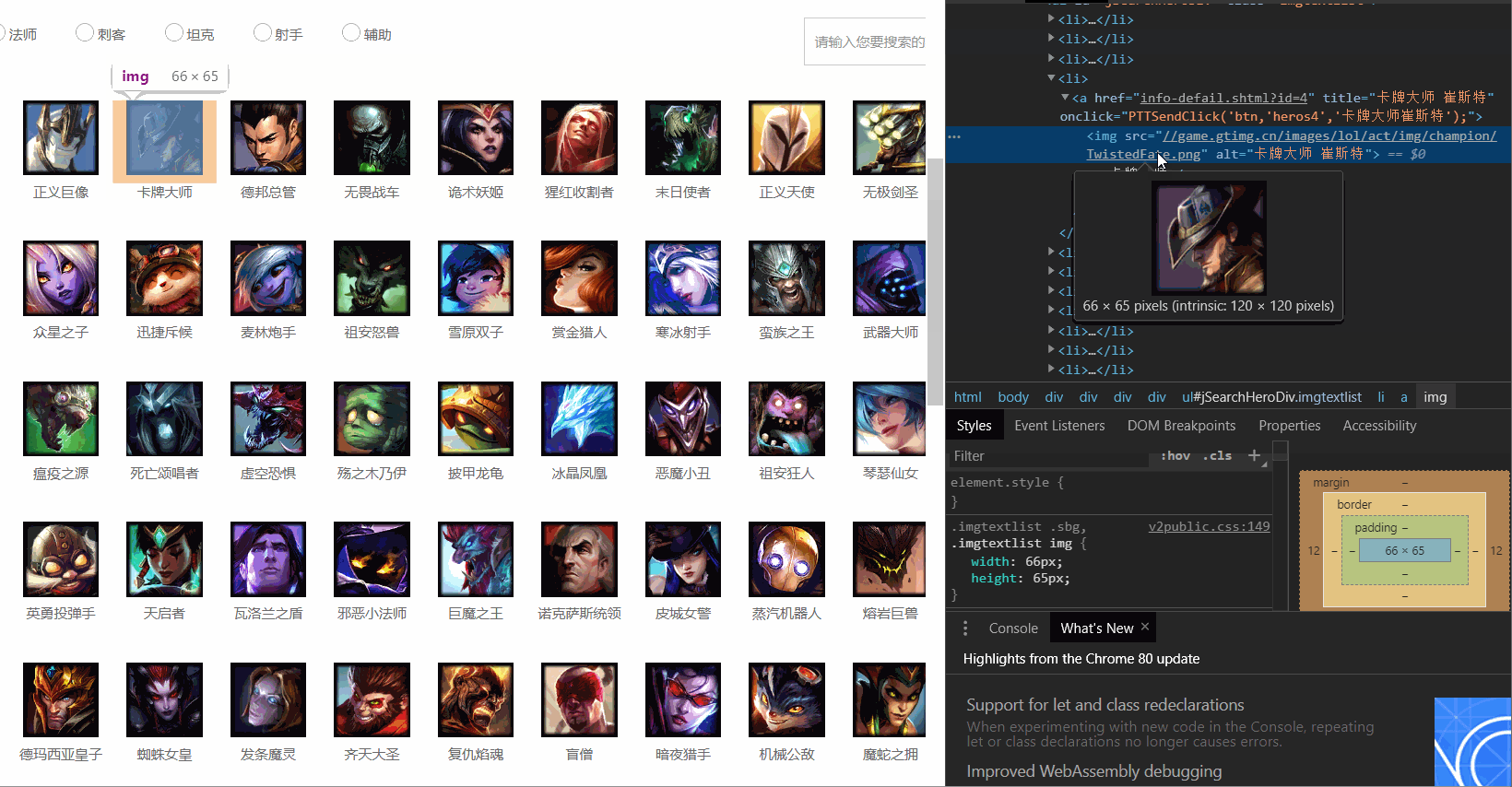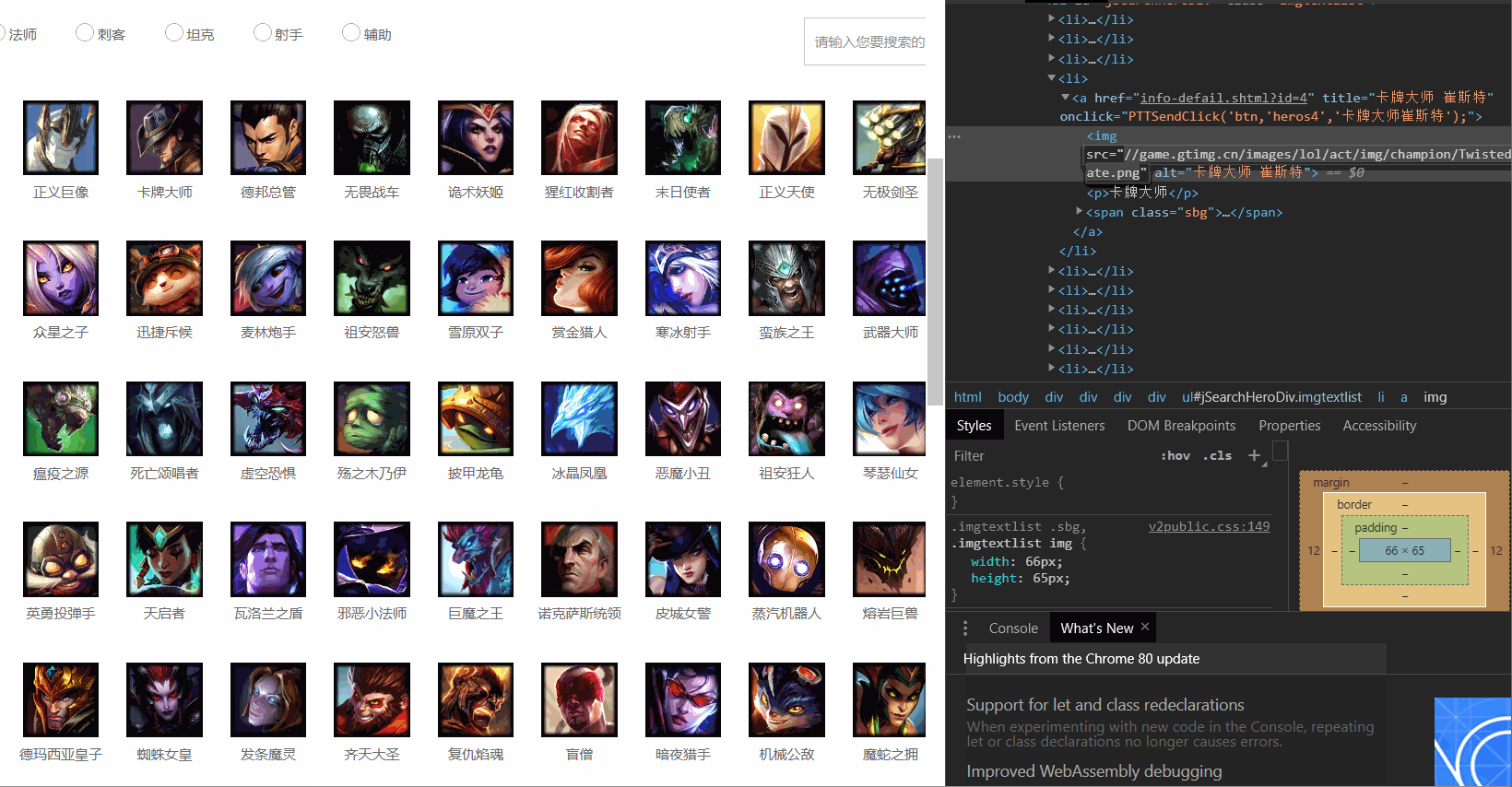


观察发现所有英雄头像都处于"<img src="">"里面
所以,构建正则表达式如下
pattern1='<img src="(.+?)">'
是不是觉得腾讯的东西太简单了?其实,你一爬就会发现根本没有图片后面我发现这里使用的是js动态加载的
经过我反复琢磨,终于发现资源文件都在//lol.qq.com/biz/hero/champion.js
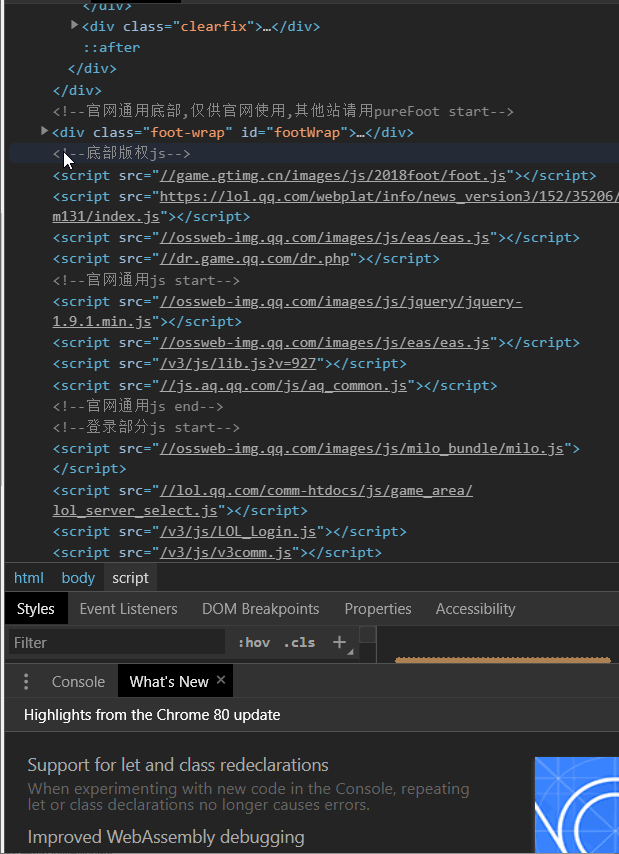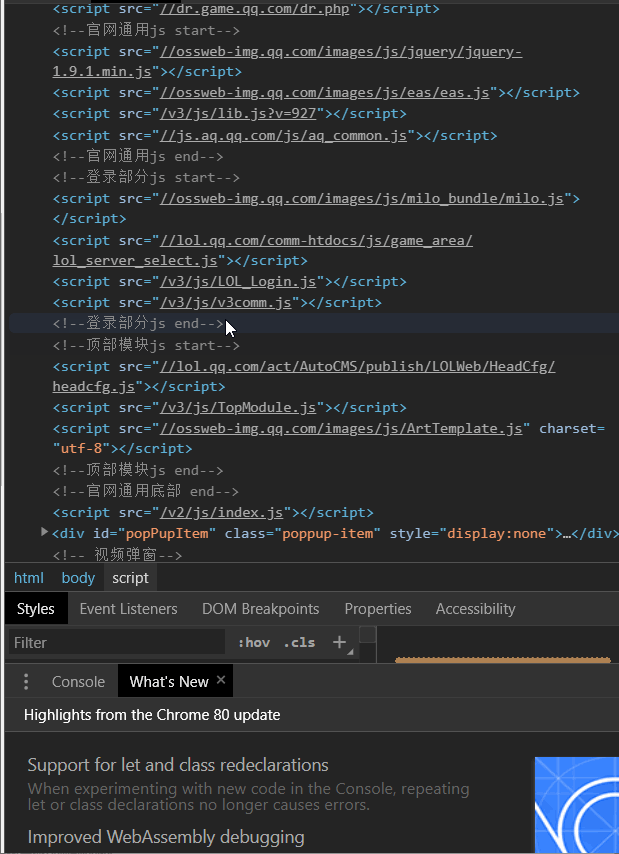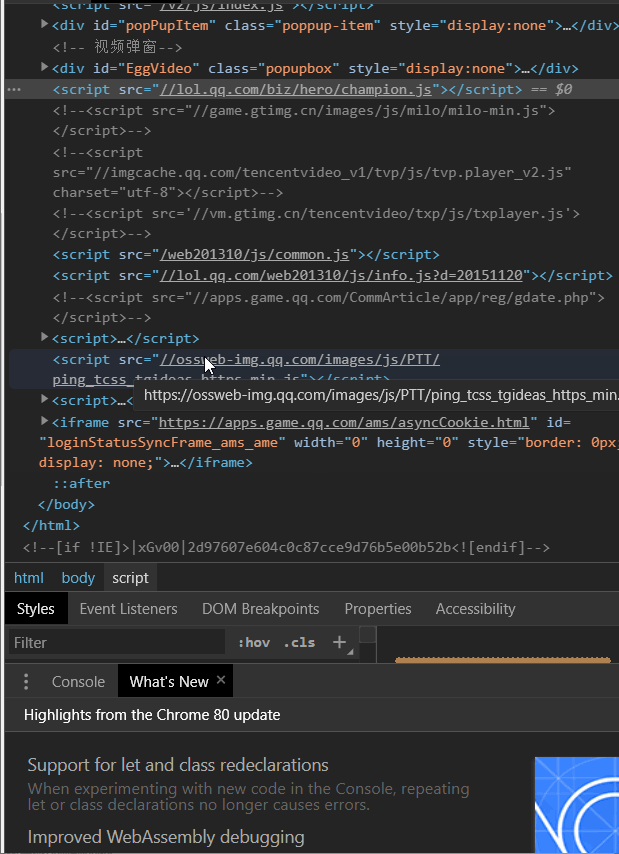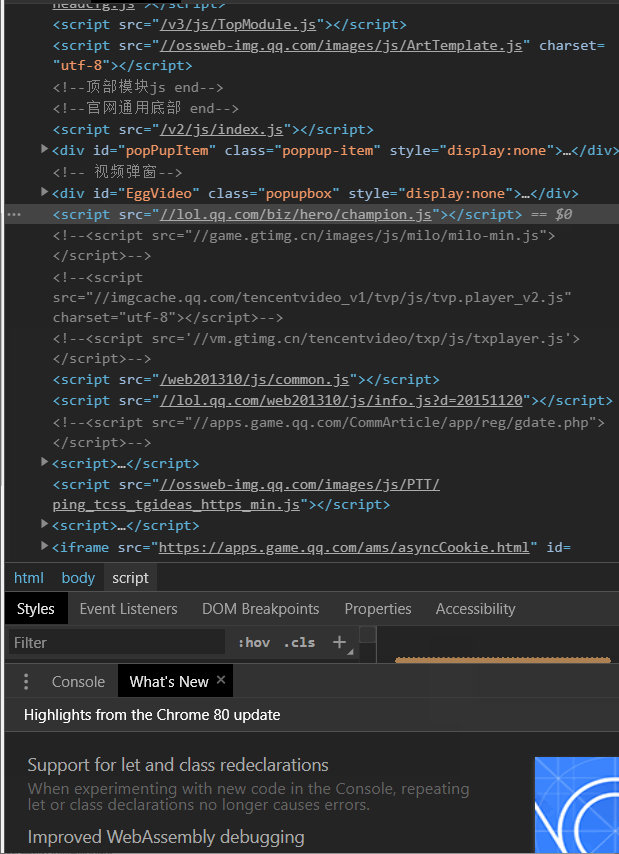
引入selenium和phantomjs
dr = webdriver.PhantomJS()
用phantomjs 解析js
构造xpath对元素定位
img=dr.find_elements_by_xpath('//ul//li//a//img')
获取每个英雄的名字和头像url
观察发现 每个img标签的src属性是url,alt属性是名字

for i in img:
i.get_attribute('src')
i.get_attribute('alt')
最终步骤
最终代码
from selenium import webdriver
import urllib.request
#无头浏览器
dr = webdriver.PhantomJS()
#打开网页
dr.get('https://lol.qq.com/data/info-heros.shtml')
#xpath定位
img=dr.find_elements_by_xpath('//ul//li//a//img')
try:
for i in img:
name=i.get_attribute('alt')
url=i.get_attribute('src')
imgname="D:/picture/"+str(name)+".jpg"
#保存进本地
urllib.request.urlretrieve(url,filename=imgname)
except urllib.error.URLError as e:#简单异常处理
pass
#退出浏览器
dr.quit()
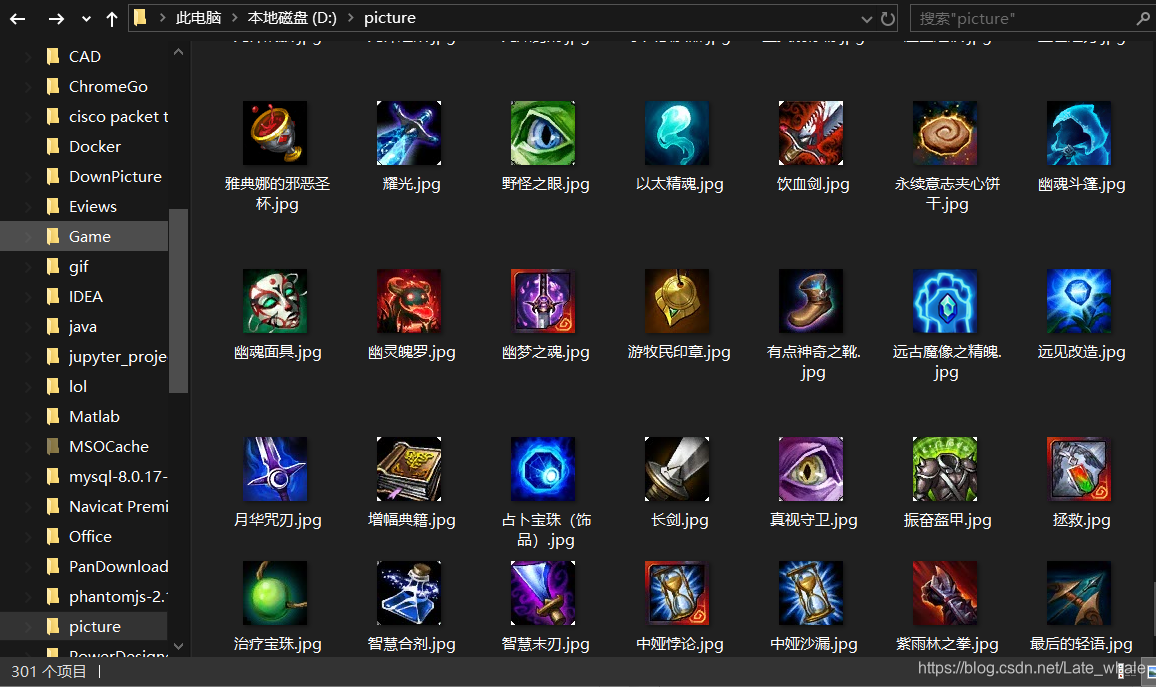
结果展示
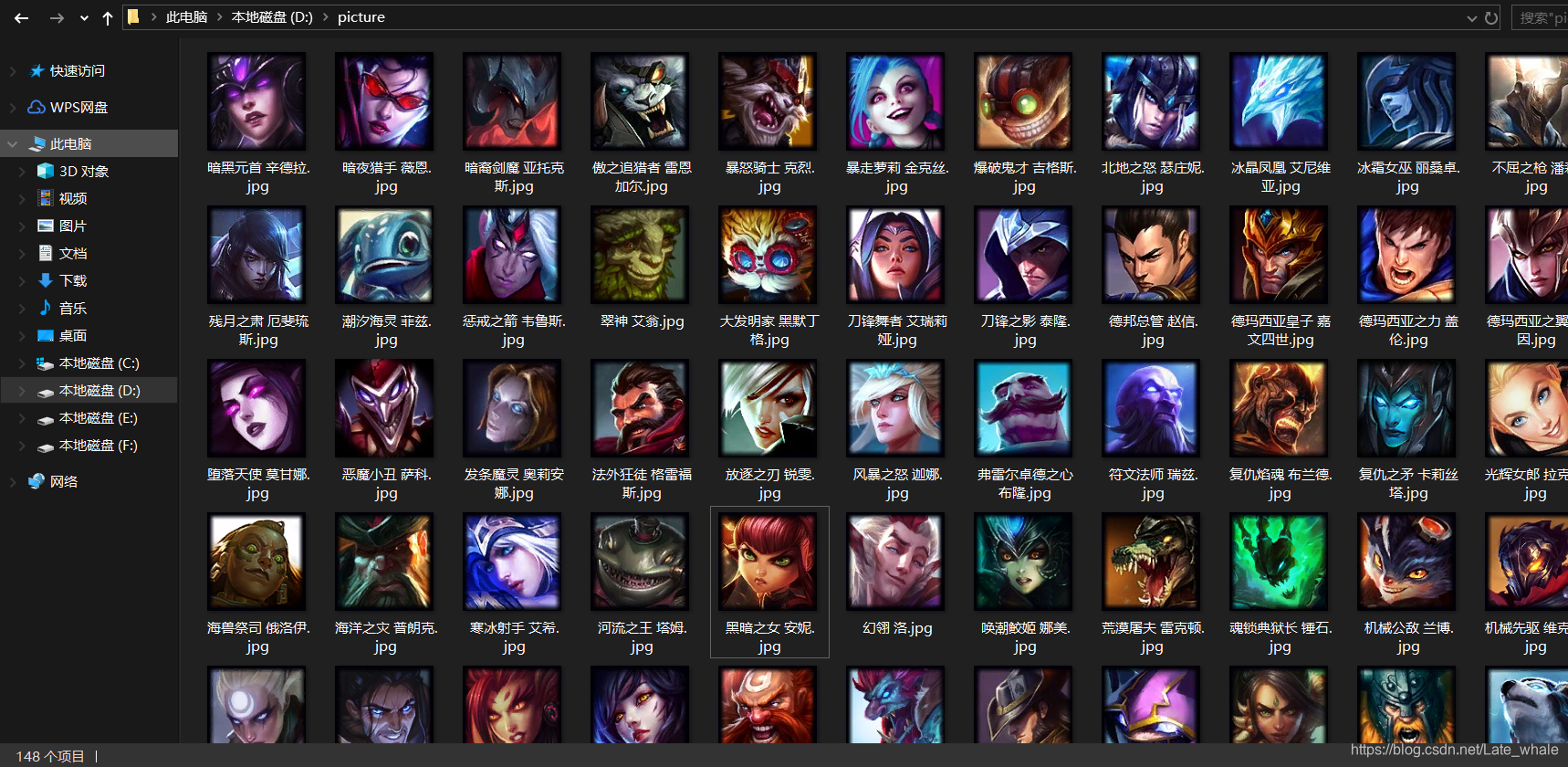
至此,148个英雄头像爬取完毕
爬取装备图片
装备与英雄的大部分都相同,只需简单几步即可实现爬取装备图片
https://lol.qq.com/data/info-item.shtml
xpath也稍微有点不一样
dr.find_elements_by_xpath('//div//ul//li//img')
装备的名称位于img同级标签
dr.find_elements_by_xpath('//div//ul//li//p')
图片和名字是两个列表
最终代码
try:
j=1 # 因为之前的xpath匹配出来多一个图片,这里从一开始去掉
for i in name_list:#遍历name列表
name=i.text
url=img_list[j].get_attribute('src')#获取图片url
j=j+1
imgname="D:/picture/"+str(name)+".jpg"
print(name+url)
#保存进本地
urllib.request.urlretrieve(url,filename=imgname)
except urllib.error.URLError as e:#简单异常处理
pass
成功展示
鞋子和打野刀存在命名重复,会被覆盖一部分