该日志收集系统,是用来收集基于springCloud分布式系统的生产环境。为了方便数据统计和分析,我将日志生成的格式,转化为JSON格式。 具体如何生成,稍后另写一篇文章介绍。
线上架构流程图:
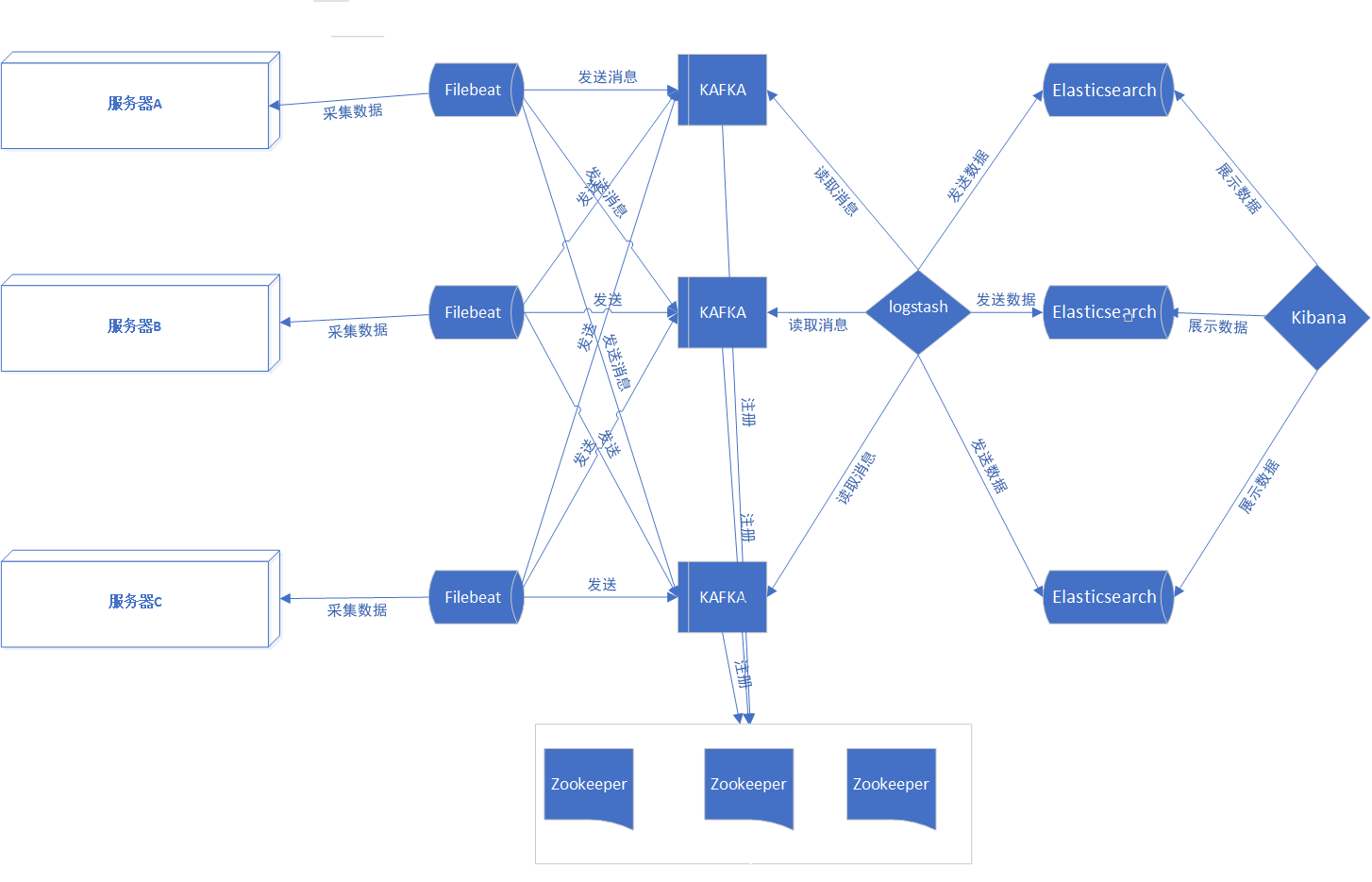
四、安装logstash
1、创建logstash 容器
------------------------------安装 logstash ---------------------------------------------
### 启动简单版,然后 copy 文件到 宿主机,最后删除该容器
sudo docker run -tid \
--hostname=keda_logstash \
--name=keda-logstash \
-p 15044:5044 \
-p 19600:9600 \
-v /etc/localtime:/etc/localtime \
-e TZ='Asia/Shanghai' \
-e LANG="en_US.UTF-8" \
logstash:7.4.2
docker cp keda-logstash:/usr/share/logstash/config/ /usr/docker/software/logstash/
docker cp keda-logstash:/usr/share/logstash/data/ /usr/docker/software/logstash/
docker cp keda-logstash:/usr/share/logstash/pipeline/ /usr/docker/software/logstash/
docker cp keda-logstash:/usr/share/logstash/vendor/ /usr/docker/software/logstash/
docker stop keda-logstash
docker rm keda-logstash
## 修改完配置文件。 在启动 正式版容器
sudo docker run -id \
--net docker-network-slave2 \
--ip 192.168.0.250 \
--restart=always \
--privileged=true \
--hostname=slave_logstash \
--name=keda6-slave2-logstash \
-p 15044:5044 \
-p 19600:9600 \
-v /usr/docker/software/logstash/config/:/usr/share/logstash/config/ \
-v /usr/docker/software/logstash/data/:/usr/share/logstash/data/ \
-v /usr/docker/software/logstash/pipeline/:/usr/share/logstash/pipeline/ \
-v /usr/docker/software/logstash/vendor/:/usr/share/logstash/vendor/ \
-v /etc/localtime:/etc/localtime \
-e TZ='Asia/Shanghai' \
-e LANG="en_US.UTF-8" \
logstash:7.4.2
2、如果容器无法启动,需要停止容器,删除 data目录下的 .lock 文件,
然后,对 data目录下的所有文件付权限(chmod 777 *),在重启 start,就行了

3、修改配置文件
input {
kafka {
bootstrap_servers => "xxx.xx.xx.44:19092,xxx.xx.xx.124:19092,xxx.xx.xx.170:19092"
#自动将偏移量重置为最新偏移量
auto_offset_reset => "latest"
#发出请求时传递给服务器的ID字符串。其目的是通过允许包含逻辑应用程序名称来跟踪IP /端口以外的请求源
client_id => "logstash-kafka-base"
# 理想情况下,您应该拥有与分区数一样多的线程,以实现完美的平衡-线程多于分区意味着某些线程将处于空闲状态
consumer_threads => 3
topics => ["gateway_topic","eureka_topic"]
type => "keda-base"
}
kafka {
bootstrap_servers => "xxx.xx.xx.44:19092,xxx.xx.xx.124:19092,xxx.xx.xx.170:19092"
#自动将偏移量重置为最新偏移量
auto_offset_reset => "latest"
#发出请求时传递给服务器的ID字符串。其目的是通过允许包含逻辑应用程序名称来跟踪IP /端口以外的请求源
client_id => "logstash-kafka-nginx"
# 理想情况下,您应该拥有与分区数一样多的线程,以实现完美的平衡-线程多于分区意味着某些线程将处于空闲状态
consumer_threads => 3
topics => ["keda-nginx_topic"]
type => "keda-nginx"
}
kafka {
bootstrap_servers => "xxx.xx.xx.44:19092,xxx.xx.xx.124:19092,xxx.xx.xx.170:19092"
#自动将偏移量重置为最新偏移量
auto_offset_reset => "latest"
#发出请求时传递给服务器的ID字符串。其目的是通过允许包含逻辑应用程序名称来跟踪IP /端口以外的请求源
client_id => "logstash-kafka-project-one"
# 理想情况下,您应该拥有与分区数一样多的线程,以实现完美的平衡-线程多于分区意味着某些线程将处于空闲状态
consumer_threads => 3
topics => ["keda-information-main_topic"]
type => "kafka-project-one"
}
kafka {
bootstrap_servers => "xxx.xx.xx.44:19092,xxx.xx.xx.124:19092,xxx.xx.xx.170:19092"
#自动将偏移量重置为最新偏移量
auto_offset_reset => "latest"
#发出请求时传递给服务器的ID字符串。其目的是通过允许包含逻辑应用程序名称来跟踪IP /端口以外的请求源
client_id => "logstash-kafka-project-two"
# 理想情况下,您应该拥有与分区数一样多的线程,以实现完美的平衡-线程多于分区意味着某些线程将处于空闲状态
consumer_threads => 3
topics => ["keda-project_topic"]
type => "kafka-project-two"
}
}
filter {
mutate{
rename => {
"@timestamp" => "logstash-timestamp"
}
}
if [type] == "keda-nginx" {
json {
source => "message"
remove_field => ["message"]
}
date{
match =>["time_local","dd/MMM/yyyy:HH:mm:ss Z"]
}
grok{
match => { "@timestamp" => ["%{TIMESTAMP_YYYYMMDD:indextime}"]}
}
}else{
json {
source => "message"
# remove_field => ["message","host","agent","ecs"]
}
date{
match =>["timestamp","yyyy-MM-dd HH:mm:ss.SSS"]
# locale => "en"
# timezone => "+00:00"
}
grok{
match => { "timestamp" => ["%{TIMESTAMP_YYYYMMDD:indextime}"]}
}
}
# mutate{
# lowercase => [ "level" ]
# }
# ruby {
# code => "event.set('indextime',event.get('@timestamp').time.localtime + 8*60*60 )"
# }
# json {
# source => "json"
# # remove_field => ["message","host","agent","ecs"]
# }
# date{
# match => ["timestamp","yyyy-MM-dd HH:mm:ss.sss"]
# }
}
output {
if [fields][log_topic] in ["gateway_topic","eureka_topic"] {
# if [type] == "keda-base" {
elasticsearch {
hosts => ["http://172.19.174.184:19200","http://172.19.252.91:19200","http://172.19.71.141:19200" ]
index => "%{service}-%{+YYYY.MM}"
# index => "%{service}-%{indextime}"
# user => elastic
# password => keda123456 keda-information-main_topic
}
}else if [fields][log_topic] in ["keda-information-main_topic","keda-project_topic"] {
elasticsearch {
hosts => ["http://172.19.174.184:19200","http://172.19.252.91:19200","http://172.19.71.141:19200" ]
index => "%{service}-%{+YYYY.MM}"
# index => "%{service}-%{indextime}"
# user => elastic
# password => keda123456
}
}else if [type] == "keda-nginx" {
elasticsearch {
hosts => ["http://172.19.174.184:19200","http://172.19.252.91:19200","http://172.19.71.141:19200" ]
index => "nginx-%{+YYYY.MM}"
# index => "nginx-%{indextime}"
# user => elastic
# password => keda123456
}
}else if [type] == "mysql" {
elasticsearch {
hosts => ["http://172.19.174.184:19200","http://172.19.252.91:19200","http://172.19.71.141:19200" ]
index => "mysql-%{indextime}"
# user => elastic
# password => keda123456
}
}else {
# stdout {
# codec => rubydebug
# }
elasticsearch {
hosts => ["http://172.19.174.184:19200","http://172.19.252.91:19200","http://172.19.71.141:19200" ]
index => "other-%{service}-%{indextime}"
# user => elastic
# password => keda123456
}
}
}
4、重新启动,就行了。
