Union-Find 算法应用
文章目录
一、回顾Union-Find的框架
class UF
{
// 记录连通分量个数
private int count;
// 存储若干棵树
private int[] parent;
、// 记录树的“重量”
private int[] size;
public UF(int n)
{
this.count = n;
parent = new int[n];
size = new int[n];
for (int i = 0; i < n; i++)
{
parent[i] = i;
size[i] = 1;
}
}
/* 将 p 和 q 连通 */
public void union(int p, int q)
{
int rootP = find(p);
int rootQ = find(q);
if (rootP == rootQ)
return;
// 小树接到大树下面,较平衡
if (size[rootP] > size[rootQ])
{
parent[rootQ] = rootP;
size[rootP] += size[rootQ];
}
else
{
parent[rootP] = rootQ;
size[rootQ] += size[rootP];
}
count--;
}
/* 判断 p 和 q 是否互相连通 */
public boolean connected(int p, int q)
{
int rootP = find(p);
int rootQ = find(q);
// 处于同一棵树上的节点,相互连通
return rootP == rootQ;
}
/* 返回节点 x 的根节点 */
private int find(int x)
{
while (parent[x] != x)
{
// 进行路径压缩
parent[x] = parent[parent[x]];
x = parent[x];
}
return x;
}
public int count()
{
return count;
}
}
算法的关键点有 3 个:
- 1、
用parent数组记录每个节点的父节点,相当于指向父节点的指针,所以parent数组内实际存储着一个森林(若干棵多叉树)。 - 2、
用size数组记录着每棵树的重量,目的是让union后树依然拥有平衡性,而不会退化成链表,影响操作效率。 - 3、
在find函数中进行路径压缩,保证任意树的高度保持在常数,使得union和connectedAPI 时间复杂度为 O(1)。
有的菇凉们可能会问,既然有了路径压缩,size数组的重量平衡还需要吗?这个问题很有意思,因为路径压缩保证了树高为常数(不超过 3),那么树就算不平衡,高度也是常数,基本没什么影响。
我认为,论时间复杂度的话,确实,不需要重量平衡也是 O(1)。但是如果加上size数组辅助,效率还是略微高一些,比如下面这种情况:
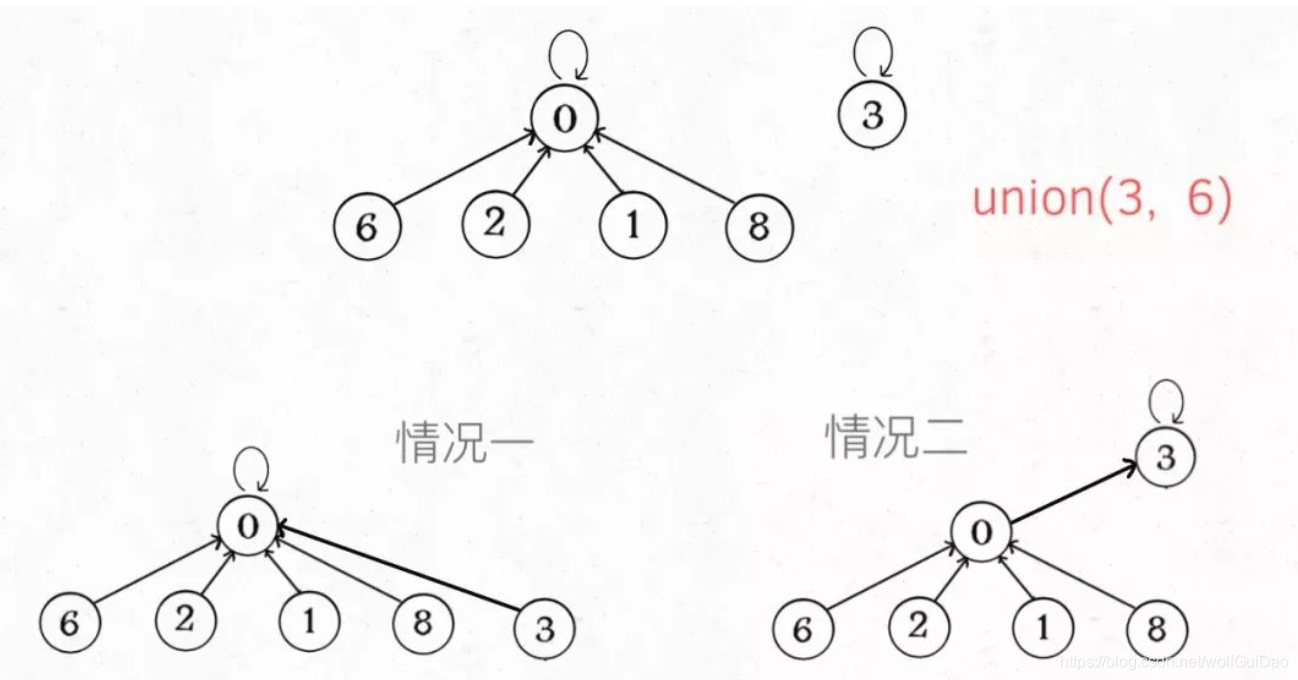
- 如果
带有重量平衡优化,一定会得到情况一,而不带重量优化,可能出现情况二。高度为 3 时才会触发路径压缩那个while循环,所以情况一根本不会触发路径压缩,而情况二会多执行很多次路径压缩,将第三层节点压缩到第二层。 - 也就是说,
去掉重量平衡,虽然对于单个的find函数调用,时间复杂度依然是 O(1),但是对于 API 调用的整个过程,效率会有一定的下降。当然,好处就是减少了一些空间,不过对于 Big O 表示法来说,时空复杂度都没变。
下面言归正传,来看看这个算法有什么实际应用。
二、Union-Find 算法解决DFS问题
很多使用 DFS 深度优先算法解决的问题,也可以用 Union-Find 算法解决。
1.题目描述:被围绕的区域
给定一个二维的矩阵,包含 'X' 和 'O'(字母 O)。
找到所有被 ‘X’ 围绕的区域,并将这些区域里所有的 ‘O’ 用 ‘X’ 填充。
示例:
X X X X
X O O X
X X O X
X O X X
运行你的函数后,矩阵变为:
X X X X
X X X X
X X X X
X O X X
解释:
被围绕的区间不会存在于边界上,换句话说,任何边界上的 'O' 都不会被填充为 'X'。
任何不在边界上,或不与边界上的 'O' 相连的 'O' 最终都会被填充为 'X'。如果两个
元素在水平或垂直方向相邻,则称它们是“相连”的。
2.分析
注意哦,必须是完全被围的O才能被换成X,也就是说边角上的O一定不会被围,进一步,与边角上的O相连的O也不会被X围四面,也不会被替换:
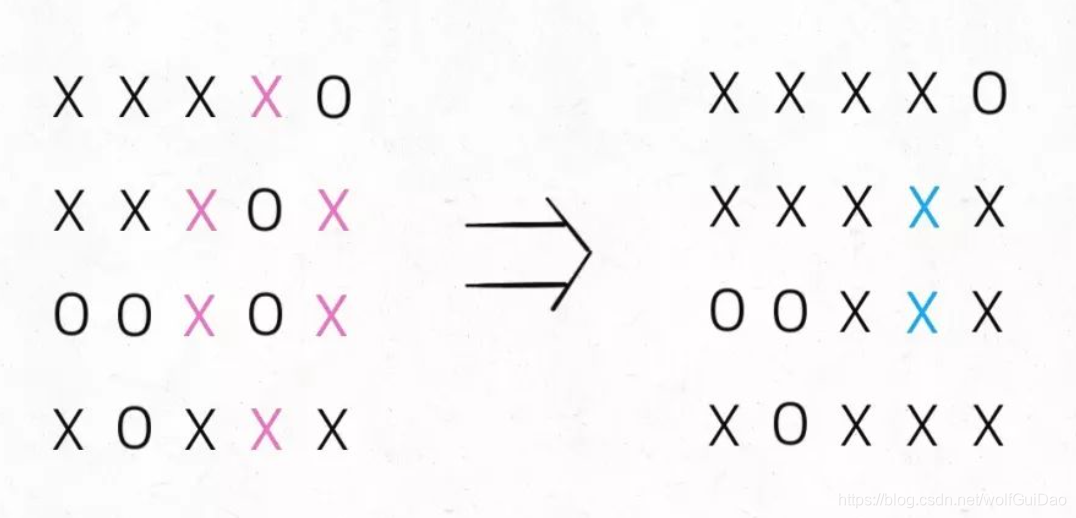
- 解决这个问题的传统方法也不困难,
先用 for 循环遍历棋盘的四边,用 DFS算法把那些与边界相连的O换成一个特殊字符,比如#;然后再遍历整个棋盘,把剩下的O换成X,把#恢复成O。这样就能完成题目的要求,时间复杂度O(MN)。 - 这个问题也可以用 Union-Find 算法解决,虽然实现复杂一些,甚至效率也略低,但这是使用 Union-Find算法的通用思想,值得一学。
- 你可以把那些
不需要被替换的O看成一个拥有独门绝技的门派,它们有一个共同祖师爷叫dummy,这些O和dummy互相连通,而那些需要被替换的O与dummy不连通。
这就是 Union-Find 的核心思路,明白这个图,就很容易看懂代码了:
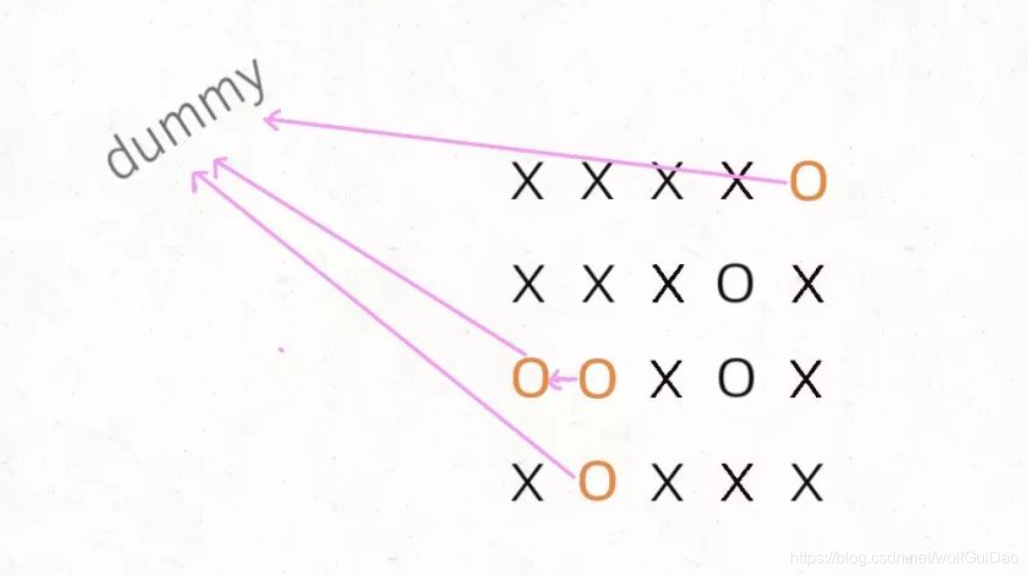
- 首先要解决的是,根据我们的实现,
Union-Find底层用的是一维数组,构造函数需要传入这个数组的大小,而题目给的是一个二维棋盘。 - 这个很简单,
二维坐标(x,y)可以转换成x * n + y这个数(m是棋盘的行数,n是棋盘的列数)。敲黑板,这是将二维坐标映射到一维的常用技巧。 - 其次,我们之前描述的「祖师爷」是虚构的,需要给他老人家留个位置。
索引[0.. m*n-1]都是棋盘内坐标的一维映射,那就让这个虚拟的dummy节点占据索引m*n好了。
3.代码
传统DFS解法:
class Solution {
public:
void solve(vector<vector<char>>& board) {
if(board.size()<3)
return ;
int m=board.size();
int n=board[0].size();
for(int i=0;i<m;i++)
{
dfs(i,0,board);
dfs(i,n-1,board);
}
for(int i=0;i<n;i++)
{
dfs(0,i,board);
dfs(m-1,i,board);
}
for(int i=0;i<m;i++)
{
for(int j=0;j<n;j++)
{
if(board[i][j]=='O')board[i][j]='X';
if(board[i][j]=='*')board[i][j]='O';
}
}
return ;
}
void dfs(int x,int y,vector<vector<char>>&board)
{
if(x<0||y<0||x>=board.size()||y>=board[0].size()||board[x][y]!='O')
return ;
board[x][y]='*';
dfs(x+1,y,board);
dfs(x-1,y,board);
dfs(x,y+1,board);
dfs(x,y-1,board);
return ;
}
};
并查集解法:
void solve(char[][] board)
{
if (board.length == 0)
return;
int m = board.length;
int n = board[0].length;
// 给 dummy 留一个额外位置
UF uf = new UF(m * n + 1);
int dummy = m * n;
// 将首列和末列的 O 与 dummy 连通
for (int i = 0; i < m; i++)
{
if (board[i][0] == 'O')
uf.union(i * n, dummy);
if (board[i][n - 1] == 'O')
uf.union(i * n + n - 1, dummy);
}
// 将首行和末行的 O 与 dummy 连通
for (int j = 0; j < n; j++)
{
if (board[0][j] == 'O')
uf.union(j, dummy);
if (board[m - 1][j] == 'O')
uf.union(n * (m - 1) + j, dummy);
}
// 方向数组 d 是上下左右搜索的常用手法
int[][] d = new int[][]{{1,0}, {0,1}, {0,-1}, {-1,0}};
for (int i = 1; i < m - 1; i++)
for (int j = 1; j < n - 1; j++)
if (board[i][j] == 'O')
// 将此 O 与上下左右的 O 连通
for (int k = 0; k < 4; k++)
{
int x = i + d[k][0];
int y = j + d[k][1];
if (board[x][y] == 'O')
uf.union(x * n + y, i * n + j);
}
// 所有不和 dummy 连通的 O,都要被替换
for (int i = 1; i < m - 1; i++)
for (int j = 1; j < n - 1; j++)
if (!uf.connected(dummy, i * n + j))
board[i][j] = 'X';
}
这段代码很长,其实就是刚才的思路实现,只有和边界O相连的O才具有和dummy的连通性,他们不会被替换。
说实话,Union-Find 算法解决这个简单的问题有点杀鸡用牛刀,它可以解决更复杂,更具有技巧性的问题,主要思路是适时增加虚拟节点,想办法让元素「分门别类」,建立动态连通关系。
1.题目描述:判定合法算式
这个问题用 Union-Find 算法就显得十分优美了。题目是这样:
给你一个数组equations,装着若干字符串表示的算式。每个算式equations[i]长度都是 4,而且只有这两种情况:a==b或者a!=b,其中a,b可以是任意小写字母。你写一个算法,如果equations中所有算式都不会互相冲突,返回 true,否则返回 false。
例:
比如说,输入["a==b","b!=c","c==a"],算法返回 false,
因为这三个算式不可能同时正确。
再比如,输入["c==c","b==d","x!=z"],算法返回 true,
因为这三个算式并不会造成逻辑冲突。
2.分析
我们前文说过,动态连通性其实就是一种等价关系,具有「自反性」「传递性」和「对称性」,其实==关系也是一种等价关系,具有这些性质。所以这个问题用 Union-Find 算法就很自然。
核心思想是,将equations中的算式根据 == 和 != 分成两部分,先处理==算式,使得他们通过相等关系各自勾结成门派;然后处理!=算式,检查不等关系是否破坏了相等关系的连通性。
3.代码
boolean equationsPossible(String[] equations) {
// 26 个英文字母
UF uf = new UF(26);
// 先让相等的字母形成连通分量
for (String eq : equations)
{
if (eq.charAt(1) == '=')
{
char x = eq.charAt(0);
char y = eq.charAt(3);
uf.union(x - 'a', y - 'a');
}
}
// 检查不等关系是否打破相等关系的连通性
for (String eq : equations)
{
if (eq.charAt(1) == '!')
{
char x = eq.charAt(0);
char y = eq.charAt(3);
// 如果相等关系成立,就是逻辑冲突
if (uf.connected(x - 'a', y - 'a'))
return false;
}
}
return true;
}
