import requests
from bs4 import BeautifulSoup
allUniv=[]
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def fillUnivList(soup):
data = soup.find_all('tr')
for tr in data:
ltd = tr.find_all('td')
if len(ltd)==0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
allUniv.append(singleUniv)
def printUnivList(num):
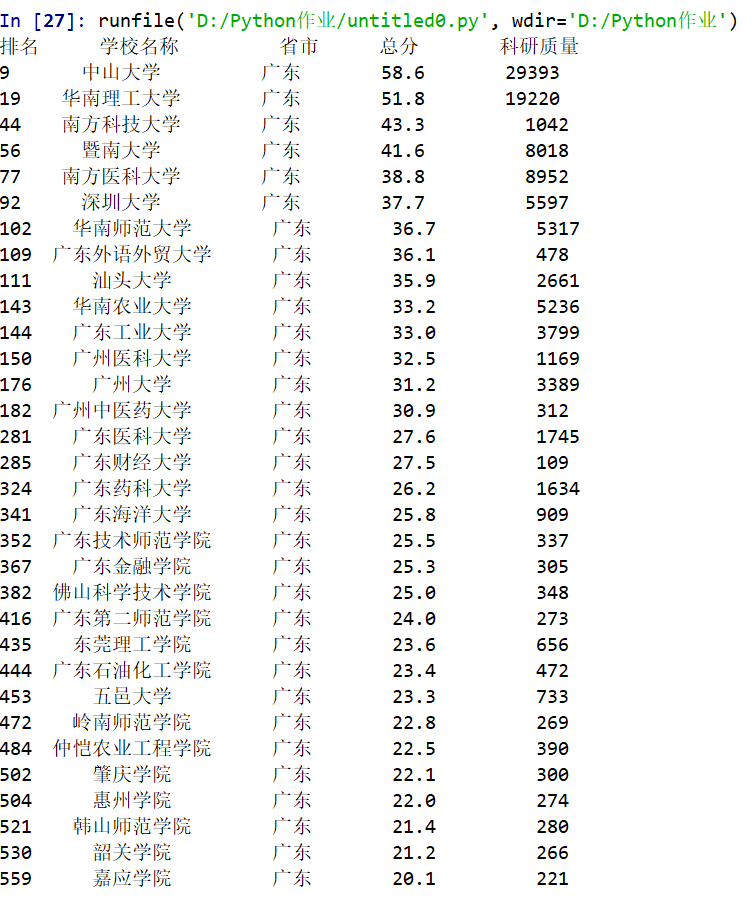
a="广东"
print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}".format(chr(12288),"排名","学校名称","省市","总分","科研质量"))
for i in range(num):
u=allUniv[i]
#print(u[1])
if a in u:
print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^8.1f}{5:{0}^10}".format(chr(12288),i+1,u[1],u[2],eval(u[3]),u[7]))
def main():
url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html'
html = getHTMLText(url)
soup = BeautifulSoup(html,"html.parser")
fillUnivList(soup)
num=len(allUniv)
printUnivList(num)
main()
import requests
from bs4 import BeautifulSoup
allUniv=[]
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def fillUnivList(soup):
data = soup.find_all('tr')
for tr in data:
ltd = tr.find_all('td')
if len(ltd)==0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
allUniv.append(singleUniv)
def printUnivList(num):
a="广东技术师范学院"
print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}".format(chr(12288),"排名","学校名称","省市","总分","科研质量"))
for i in range(num):
u=allUniv[i]
#print(u[1])
if a in u:
print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^8.1f}{5:{0}^10}".format(chr(12288),i+1,u[1],u[2],eval(u[3]),u[7]))
def main():
url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html'
html = getHTMLText(url)
soup = BeautifulSoup(html,"html.parser")
fillUnivList(soup)
num=len(allUniv)
printUnivList(num)
main()