问题描述:公司有个不常用的系统提供给外部客户使用,隔三岔五会接到有客户反映页面刷不出来的问题。
临时解决:重启应用进程立马生效,或等待一段时间后即可正常访问。
先来了解下系统部署方式:
1)这个系统使用的应用连接的是我们备用数据库;
2)备用数据库目前只给这个系统的应用使用。
下面进行两组简单的测试:
1)本地PLSQL连接,过一段时间后会断掉。(排除应用侧问题)
2)将应用配置成访问主用数据库,问题现象消失(排除应用侧问题+1)
好了,排除了应用侧的问题,那么问题就集中在了数据库侧,通过与网络工程师沟通,备用数据库独立用了一台硬件防火墙,其他都是共用的,和主库无差异。
问题基本就定位到这了:
1)备用数据库上层防火墙问题(网络工程师排查,防火墙配置与主库一致)
2)备用数据库问题(数据库工程师排查,数据库配置与主库一致)
好了,大家都说没问题,那我们就只能通过分析拿数据说话了。
-----------------------------------------------------
进入正式测试阶段:
1)断开应用外部流量,重启应用,应用和DB服务器都建立了连接。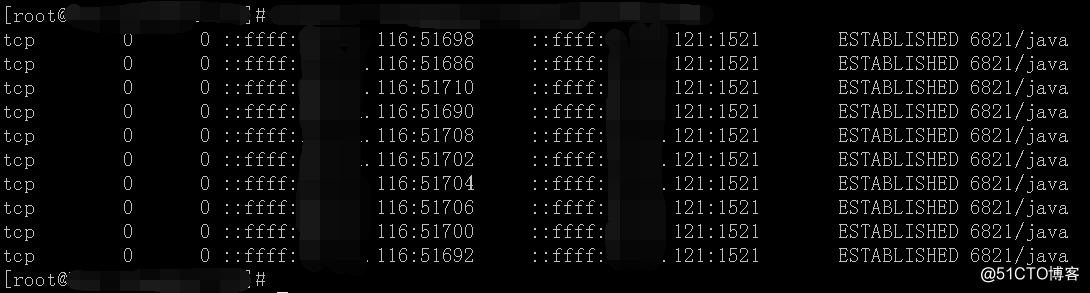
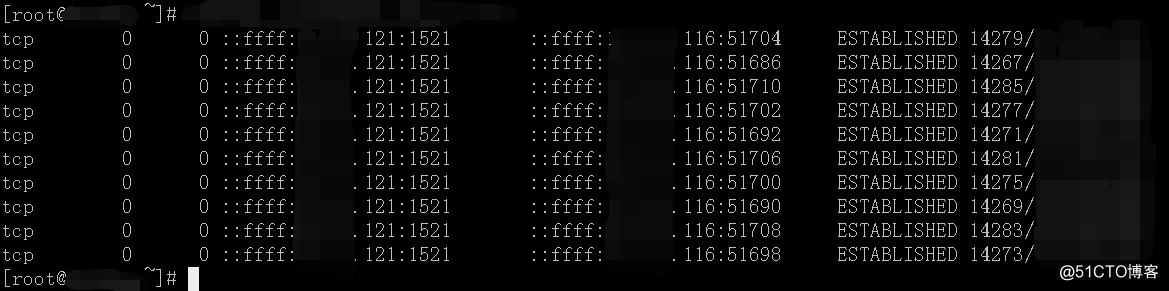
2)过几小时后,应用的连接还在,DB服务器的连接都没有。

what?DB服务器你凭什么断我应用连接啊?你断我也不告诉我吗?!!!
通过抓包发现,DB服务器当时是发送了keepalived检测消息,但是应用你没有收到啊。(DB大写的冤枉~~)

嘿,防火墙你出来,我(应用)为什么没有收到?
3)此时,通过访问请求页面已打不开,一直在请求中,通过在应用侧抓包发现,应用有发送请求给DB,DB却也没有收到。(DB你可以出来,也骂一顿应用了,哈哈)

啦啦啦:这个时候,一切的定位都指向了防火墙,等把防火墙挪掉就知道了,问题到这里基本就定位结束了。
PS:其实后来又做了一次测试,就是连接建立后过30分钟,应用和DB两侧连接都是正常的,但是前端请求就访问不了了,即DB还没触发keepalived机制,应用就触发了TCP重传机制,所以更可以说明问题不在应用和DB两侧了。
加餐话题
想知道DB是过了多久断开的吗?应用又是连了多少次才重新建立连接的吗?他们的检测机制又是什么样的呢?
加餐开始:
1、DB端的断开机制。
DB作为服务端,当2小时内都没有收到客户端(应用)的请求,就会触发操作系统的keepalived机制。
具体如下:
net.ipv4.tcp_keepalive_time = 7200 #2小时后,开始发起ack检测
net.ipv4.tcp_keepalive_probes = 9 #一共进行9次检测
net.ipv4.tcp_keepalive_intvl = 75 #每次检测间隔75秒
抓包示例:
发起的keepalived检测一共发起了9次,每次75秒,一共花费了10分钟,当都没有收到响应,就会发起RST结束当前连接。
也就是说,应用和DB建立的连接,在没有外部请求的情况下,通过DB和应用之前通讯断开的情况下,DB会在2小时10分钟后断开连接。
2、应用端的重连机制。
当外部没有请求的情况下,应用作为客户端,之前建立的连接始终“保持着”。
当外部发起请求时,会触发TCP重连机制。
具体如下:
Linux重传机制:
最小重传时间是200ms
最大重传时间是120s
重传次数为15
不信你看: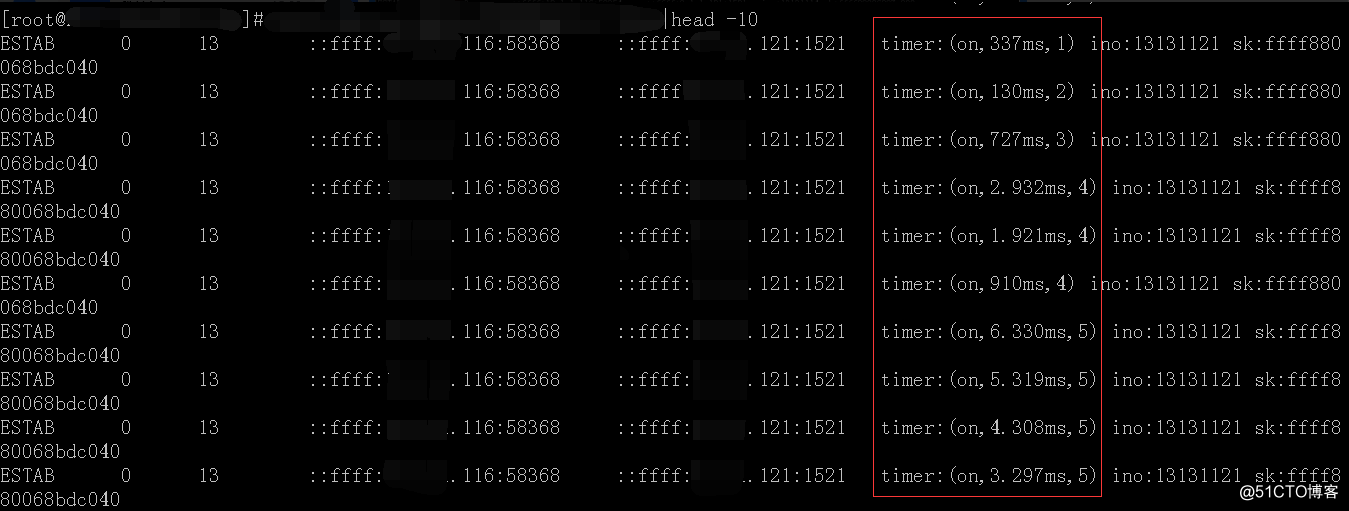
中间省略。。。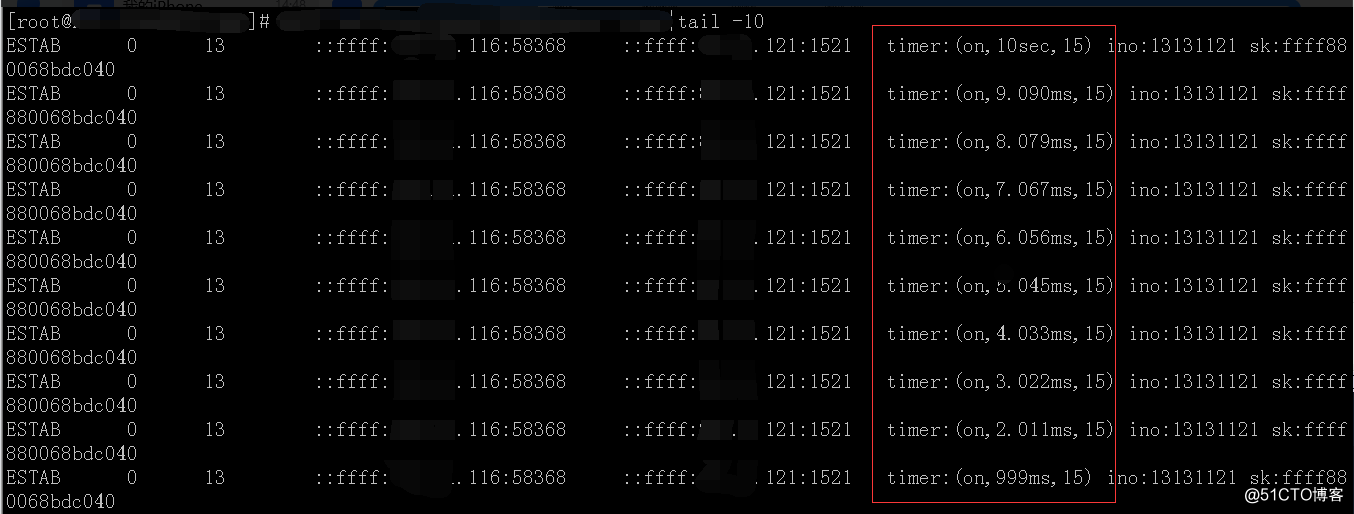
timer:(on,9.794ms,15) 具体含义分别是:TCP重传机制开启,重传倒计时,重传次数。
抓包示例: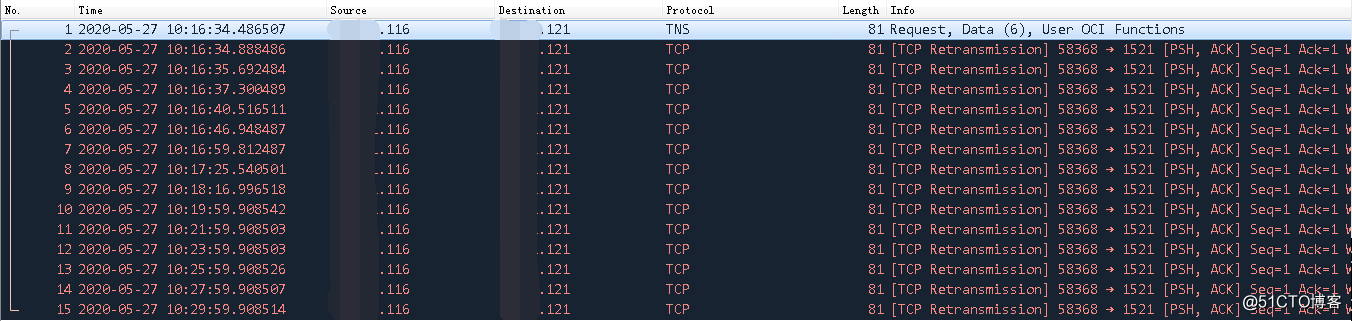
再来看看最后一次的重传时间: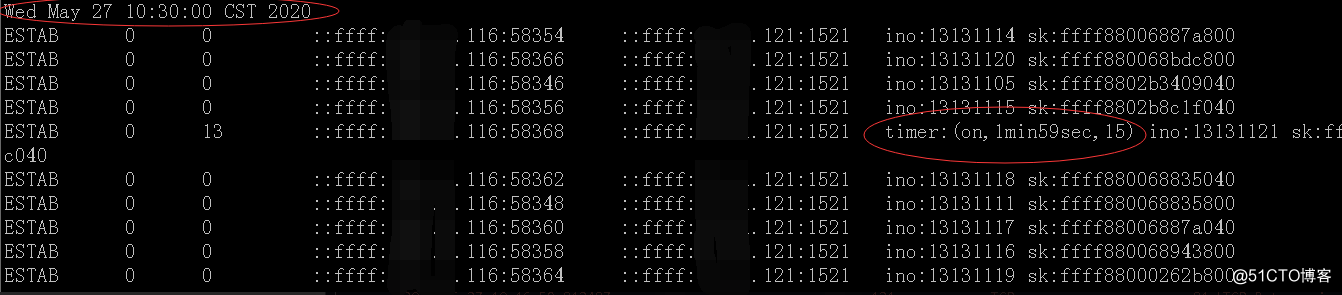
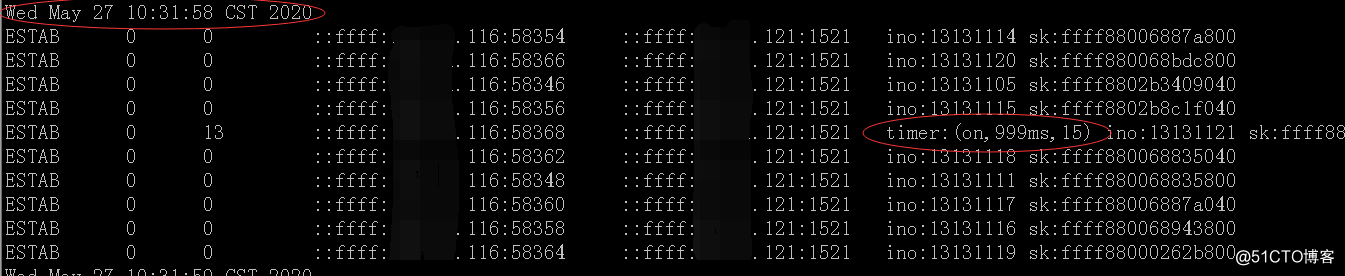
可以看出,在重传第15次后,还需要再等2分钟后,确定没收到才要关闭,即10:31:58 第16次是自我关闭连接(不再发送消息)。
通过命令分析出来的和LINUX自身的TCP重传机制(图片来自网上)其实是一样的: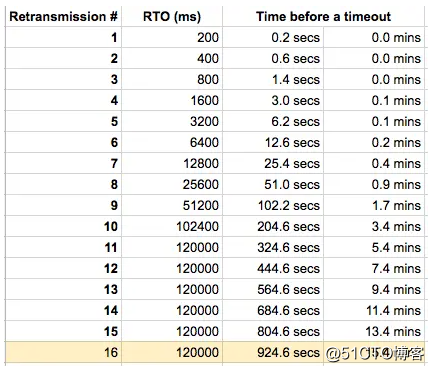
可以看出,一个连接的TCP重传机制需要花费15.4分钟,才能重新创建连接。
所以,到这里,就可以解释为什么上面说的,当客户反应访问不了,过一段时间后就又可以访问的现象了。
这里应用和DB保持着10个连接,当DB侧全部超时后,第一个请求过来,会选择其中一个空闲的连接,触发了TCP重传机制,需要等待15.4分钟。一个客户访问页面可能会触发N个请求,那么就会等待15.4*N分钟。
即用户可以打开页面的时间需要等待15.4分钟~154分钟。