本篇论文:Underexposed Photo Enhancement using Deep Illumination Estimation来自CVPR2019,腾讯优图实验室投递,算是在近来low-light images enhancement中较为知名的论文了。
搞笑的是,团队已经解散了 - -…,深圳的优图
摘要
不像之前的工作那样直接学习图像到图像的映射,本论文网络中引入中间照明来将输入与预期的增强结果相关联,这增强了网络从专家修饰的输入/输出图像对中学习复杂照片调整的能力。在此模型的基础上,构造了一个对光照采用约束和先验的损失函数,准备了一个包含3000个曝光不足图像对的新数据集,并对网络进行训练,使其能够有效地学习针对不同光照条件的丰富的各种调整。
Introduction
论文方法结果与iPhone和lightroom上的自动增强结果的对比。

论文的三个主要贡献:
- 提出了一种通过估计图像到光照的映射 (有点类似retinex理论中的illumination map) 来增强曝光不足照片的网络,并基于各种光照约束和先验知识设计了新的损失函数,能有效地保持对比度、饱和度
- 使用了包含3000张暗光图像的数据集,每张都有一个经过专家润色过的参考版本。·
- 利用现有数据集和新的数据集进行了评估,并从定性和定量两个方面论证了我们的方法的优越性。
Methodology
Image Enhancement Model
是期望的正常曝光图片,I是原始输入暗光图像,F为希望寻找到的映射函数。在retinex相关论文中,F函数的逆常S认为可以作为illumination map,可以得出这样的公式:
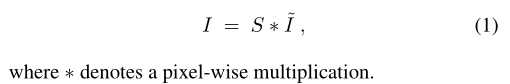
即把S作为retinex中的illumination map,把
作为retinex中的reflectance map
retinex理论即一张图像可以分解为光照分量illumination map和反射分量reflectance map,博主自己以后应该也会出一篇文章介绍retinex相关方法。
所以,作者假设,假如我们已知S,那么可以得到下面的公式,来得出经过增强的图片:
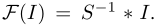
不像其他文章,本论文的S是包含了RGB三个通道的信息而不是单个通道的信息,可以在颜色增强方面得到更好的质量。作者称,使用中间光照的优点是其具有较为简单的形式,而且具有已知的先验,能够使网络具有更强的泛化能力,以适应不同的光照条件。
结构介绍

原始图像经过down-sampling下采样得到低分辨率的图像,再经过编码器网络(预训练的VGG16),通过local feature extractor和global feature extractor得到低分辨率下的illumination prediction,再经过上采样,得到原始分辨率的illumination map,即S。
因为网络多在低分辨率的图像下进行工作,所以速度很快。但是网络作者并没有介绍多少,就告知了使用VGG16的编码器,其中local extractor包含两个卷积层,global extractor包含两个卷积层和三个全连接。
得到S之后,根据公式:
就可以得到期望的正常曝光图片。整个网络就建立在这个公式上。
数据集
作者建立了一组3000张图片的数据集,包含了各种各样的场景和曝光条件,2750张作为训练集,250张作为测试集。并且提出没有使用MIT-Adobe FiveK数据集作为训练集的原因,一是此数据集是针对通用图像进行增强并不是暗光图像,暗光图片占比较少(about 4%);二是数据集的光照场景不丰富。所以作者用索尼和佳能相机拍摄图像,并且在flicker网站收集了keywords为 “under-exposed”, “low-light”, and “backlit”大约15%的图像组成了数据集。
Loss Function
总loss:
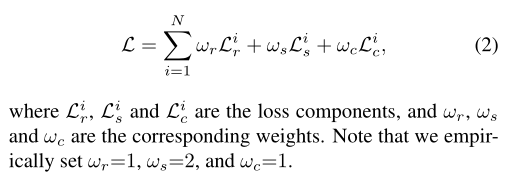
其中Lr、Ls和Lc分别为reconstruction loss、smooth loss和color loss,权重分别为1、2和1。
1.reconstruction loss
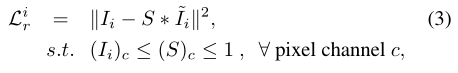
使用L2 loss,换句话说就是计算增强后的图像与原图像的差异,其中要注意的是S的取值范围 !!!!:
这里取S下界为 I,是为了保证在公式 F(I)=S-1*I 中,增强结果F(I)大于1,大于1意思是一定比原图I更亮;而S上界为1的原因是不会让增强图像黑的地方更黑,也就是反向提亮,因为F(I)=S-1*I,这里用的是S的倒数,如果S大于1,则乘以小于1的数所以会反向提亮(变暗)。
2.smooth loss
smooth loss的提出是因为根据先验知识,在自然图像中照明通常是局部平滑的,作者称,使用smooth loss可以增强网络泛化能力,提高图像的对比度。具体假设q和p为图像中相邻的像素,又有相似的照明值,而且S-1是大于1的,有:
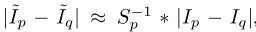
来使得对比度加强。下面是smooth loss:
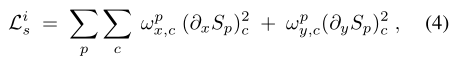
代表偏导数,这里有垂直和水平的偏导数,
是空间不同(每通道)的smoothness 权重:
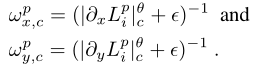
其中,L为原始图像的对数;
是控制图像对梯度敏感程度的参数(鉴定图像照明是否连续),这里为1.2;
设置为0.0001,防止除数为零。
作者称,smooth loss使照明在具有小梯度的像素上是平滑的,而在具有大梯度的像素上是不连续的,对于曝光不足的照片,图像内容和细节往往较弱,照明不一致会导致大的梯度。
3.Color Loss
针对于颜色恢复设计的loss,将RGB三通道看做三维向量,计算增强图像与ground truth之间的余弦距离:
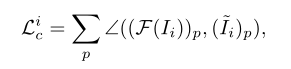
作者称,因为在reconstruction loss中已经有了L2 loss,但是L2 loss只是数值上测量色差,不能保证颜色向量的方向是相同的,可能导致颜色mismatch,所以使用了夹角的loss。
4.关于loss的消融实验
实验证明了使用reconstruction loss可以恢复更多的细节;添加smooth loss增强了对比度,使用color loss让增强图像和专家修饰过的图像更加一致,颜色相比更加艳丽自然。

Experimental Results
关于数据集,作者在自己的数据集上进行了训练和测试;同时在MIT-ADOBE FiveK数据集上选取了5000张raw原始图像,这些都有被五个不同的专家润色过的,但是这里选择的是C专家,同时用4500张作为训练集,500张作为测试集。
下图是论文方法和SOTA方法的结果对比:

通过用户调查,作者针对这几个指标,对比各个方法的视觉效果:细节是否容易被感知、颜色是否生动、结果是否真实、结果是否过曝、比原图更好看吗和总体评价。

作者还使用了PSNR和SSIM作为指标,进行了定量定性的比较,对比了其他方法,还对loss的消融实验做了对比:

同时作者还提出了论文方法的两个limitation,那就是不能增强极暗区域和去噪能力堪忧。

博主总结
- 本论文通过估计中间光照图(类retinex理论)来进行暗光增强,网络结构上比较简单清晰易懂,最重要的就是估算光照图S的流程和设计了不同用处的loss
- reconstruction loss通过计算距离来恢复细节;smooth loss增强对比度,此loss即作者称的局部光滑约束;color loss增强颜色,达到和专家润色的图像相同的色彩生动程度
- 训练测试为paired的数据(专家润色作为ground truth),且作者好像一直没有公布其数据集- -…,虽然作者称使用中间光照可以加先验来增加泛化性,但是论文也没有展示针对自然图像进行测试,博主对论文方法的现实泛化能力表示质疑。关于泛化性,使用无监督的GAN技术会得到更好的泛化性能,在我已发布的博文中也有一篇使用了这种方法:EnlightenGAN:Deep Light Enhancement without Paired Supervision。
- 关于去噪,作者是在limitation中提出,同时指出网络下一步优化就是去噪能力,但是鉴于深圳优图都解散了,应该是没法优化了。也有其他的网络,考虑了去噪能力,并且通过注意力图针对性地去噪,就在我已发布的博文Attention-guided Low-light Image Enhancement。