文章目录
前言
这篇文章是搭建高可用,高负载的第二篇。来学习的是搭建Mysql数据库集群,使其能够在模拟高并发的情况下,在其中的一些Mysql结点宕机的情况下也能够正常的访问,不会因为一个结点的宕机,就不能够再提供服务。在上一篇文章中讲到的是环境的搭建,具体参看linux环境搭建,里面详细讲解了环境的搭建,有需要的可以移步去看那篇文章。
具体的其中配置文件可以参看github中有一系列的文件配置信息。有需要学习的小伙伴可以对其进行下载,自行根据博客配置
正文
选择哪一种搭建集群的方式
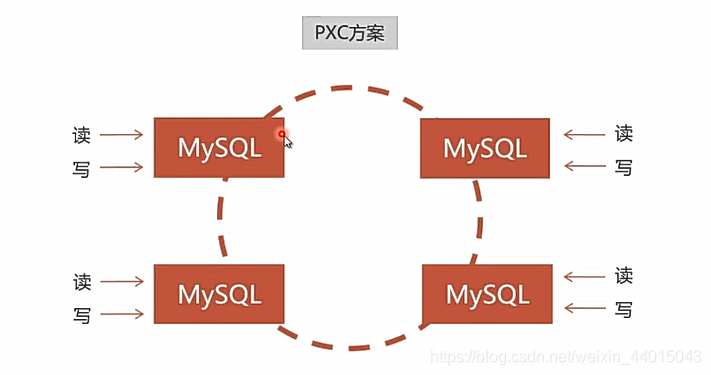
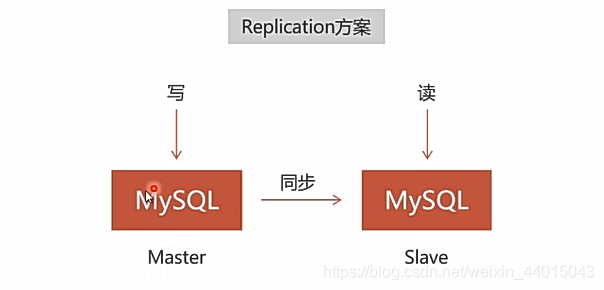
对于mysql来说有两种搭建集群的方法:Replication与PXC,如下图所示:

对于第一种情况的Replication弱一致性表示是对于当前结点的数据,在集群中的另外一个结点并不一定能够访问到,所以一般也都是价值比较低的数据。对于PXC来说实现的是强一致性,表示对于任意结点中的数据在其他的结点中也都能够访问到。对于阿里的服务器集群,及当下的主流网站,对于数据库集群的搭建都是采用第二种方法,下面来看具体的信息。
PXC
对于数据的同步是双向的,数据在每一个结点上面都可以进行读写。
同步复制,事务在所有集群节点要么同时提交,要么不提交
Replication
对于数据的同步是单向的,就是例如我们在名为Master的结点上写入数据,对于Slave结点上可以读取到Master写入的数据,但是对于在Slave上写入的数据,在Master就不能读取到。
安装docker
既然是要在Docker上配置mysql数据库集群,这里就先在linux服务器上安装Docker(这里说明以下对于dockers也是虚拟机,VM也是虚拟机,为什么说不使用到VM进行虚拟环境的搭建,然后搭建数据库集群? 因为对于VM来说是重量级的,对于Docker来说是轻量级的。对于VM每一个Vm虚拟机都是切实占用内存空间。但是对于Docker来说多个docker虚拟机来共享分配的空间大小,基础的配置不变,只是在其上进行了进一步的封装,更加便捷与易于管理与维护)
Docker操作的基本命令
- 先更新软件包,其中的
-y表示确定的意思
yum -y update
- 安装Docker虚拟机。-y也表示确定意思。
yum install -y docker
- 运行、重启、关闭Docker虚拟机
service docker start
service docker restart
service docker stop
- 搜索镜像
docker search 镜像名称
eg: docker search java
注意: 这里直接使用Docker的源镜像在国外可能会很慢,所以我们这里使用国内比较好的加速器进行加速。
DaoCloud跳转链接
复制以下代码进入到linux环境下运行,注意若是无法复制,使用XShell连接复制运行。
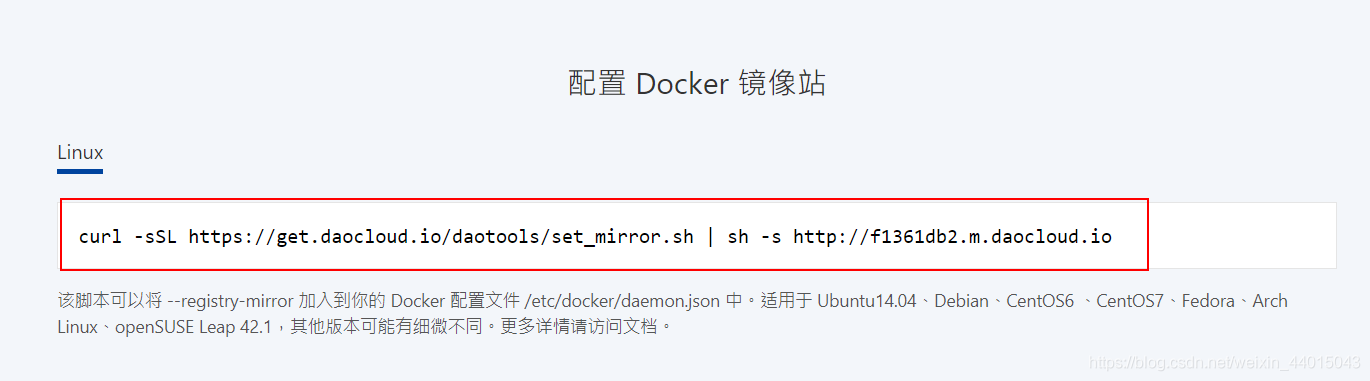
运行成功以后,输入命令 vi /etc/docker/daemon.json,将下图第一行最后的,去掉。然后重新启动docker输入service docker restart。
 5. 下载镜像
5. 下载镜像
docker pull 镜像名称
- 查看镜像
docker images
- 删除镜像
docker rmi 镜像名称
- 运行容器
docker run 启动参数 镜像名称
- 查看容器列表
docker ps -a
- 停止、挂起、恢复容器
docker stop 容器ID
docker pause 容器ID
docker unpase 容器ID
- 查看容器信息
docker inspect 容器ID
12.删除容器
docker rm 容器ID
- 数据卷管理
docker volume create 数据卷名称 #创建数据卷
docker volume rm 数据卷名称 #删除数据卷
docker volume inspect 数据卷名称 #查看数据卷
- 网络管理
docker network ls 查看网络信息
docker network create --subnet=网段 网络名称
docker network rm 网络名称
- 避免VM虚拟机挂起恢复之后,Docker虚拟机断网
vi /etc/sysctl.conf
- 文件中添加
net.ipv4.ip_forward=1这个配置
#重启网络服务
systemctl restart network
安装PXC集群
- 前面我们提到我们使用PXC进行集群的搭建,所以先要对PXC镜像进行安装。
docker pull percona/percona-xtradb-cluster
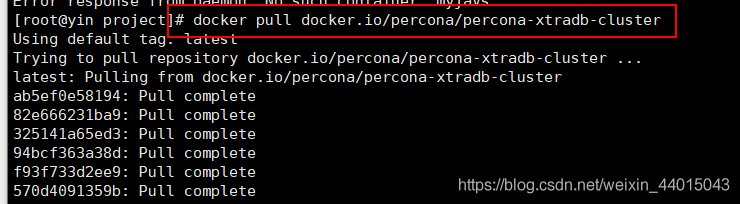
2. 为镜像更改名字:
docker tag percona/percona-xtradb-cluster pxc
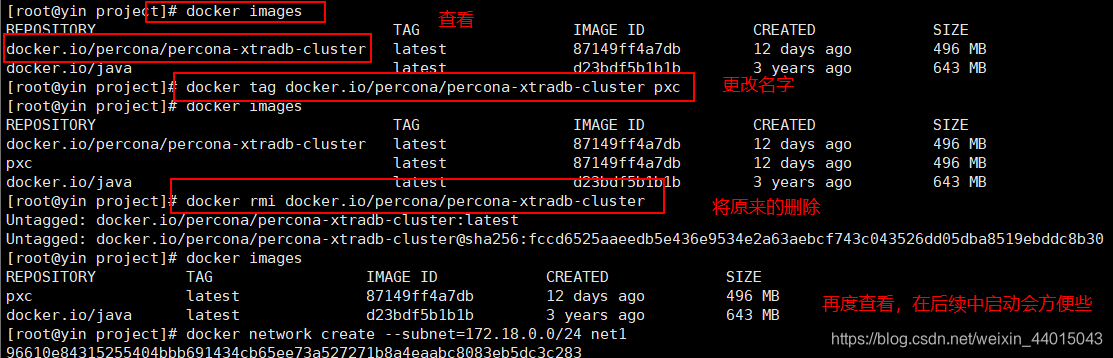
3. 创建net1网段
docker network create --subnet=172.18.0.0/16 net1
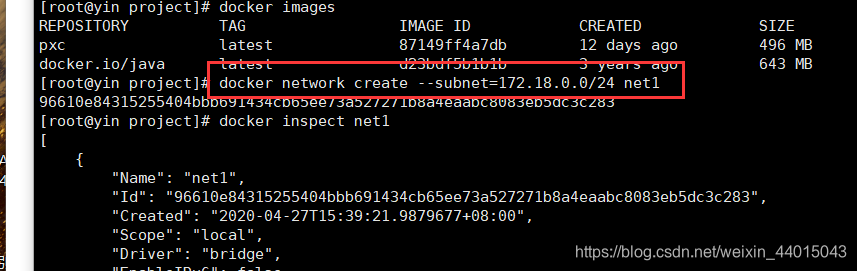
-
创建5个数据卷
docker volume create --name v1
docker volume create --name v2
docker volume create --name v3
docker volume create --name v4
docker volume create --name v5
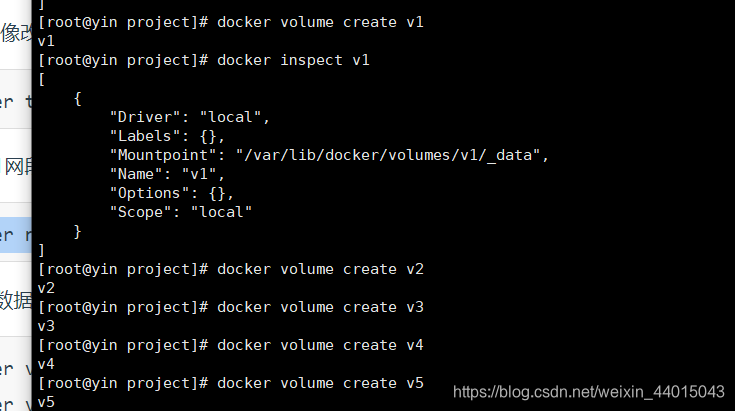
-
创建5节点的PXC集群
注意,每个MySQL容器创建之后,因为要执行PXC的初始化和加入集群等工作,耐心等待1分钟左右再用客户端连接MySQL。另外,必须第1个MySQL节点启动成功,用MySQL客户端能连接上之后,再去创建其他MySQL节点。
#创建第1个MySQL节点
docker run -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -v v1:/var/lib/mysql -v backup:/data --privileged --name=node1 --net=net1 --ip 172.18.0.2 pxc
#创建第2个MySQL节点
docker run -d -p 3307:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=node1 -v v2:/var/lib/mysql -v backup:/data --privileged --name=node2 --net=net1 --ip 172.18.0.3 pxc
#创建第3个MySQL节点
docker run -d -p 3308:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=node1 -v v3:/var/lib/mysql --privileged --name=node3 --net=net1 --ip 172.18.0.4 pxc
#创建第4个MySQL节点
docker run -d -p 3309:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=node1 -v v4:/var/lib/mysql --privileged --name=node4 --net=net1 --ip 172.18.0.5 pxc
#创建第5个MySQL节点
docker run -d -p 3310:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=node1 -v v5:/var/lib/mysql -v backup:/data --privileged --name=node5 --net=net1 --ip 172.18.0.6 pxc
这个时候,我们就创建了5个SQL节点,我们可以使用本地的Navicat进行测试连接:
此时PXC集群已经搭建完成,对于在一个数据库中进行的更改,在其他数据库中也能够看得到,这里我们在db5中添加一个新表student,添加一定的字段:
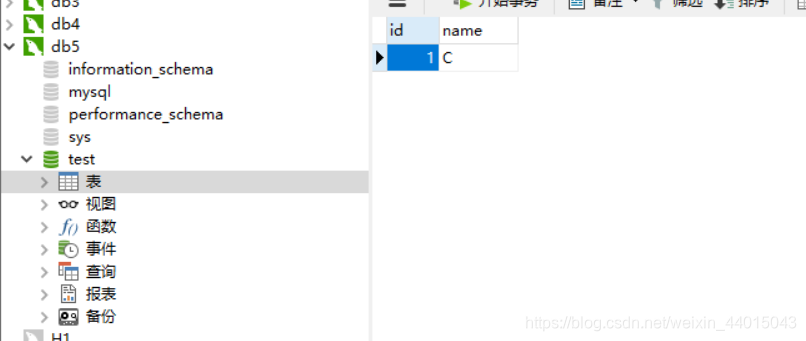
发现在db3中,可以看到也有对应的更改。
负载均衡
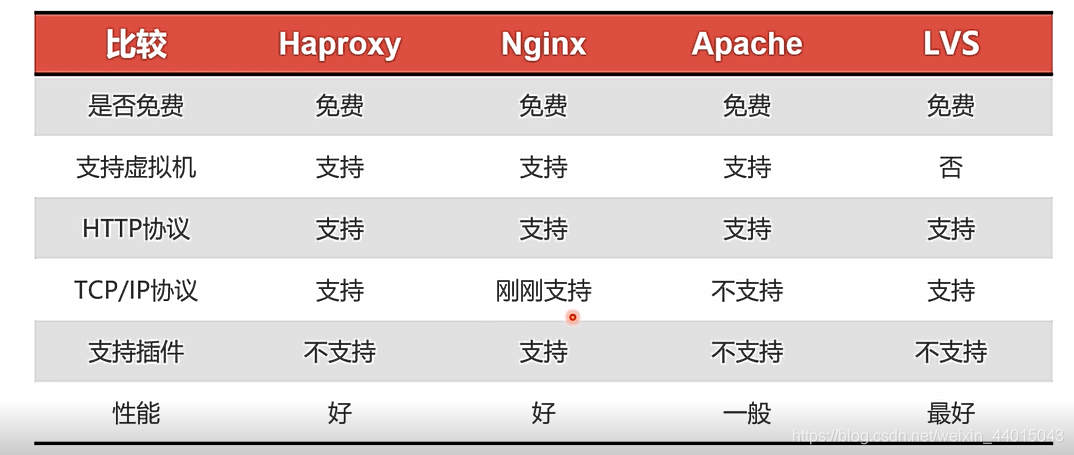
至于搭建负载均衡,可能很多小伙伴想到的是使用nginx进行负载均衡的搭建,这里来进行一个对比:对于Tcp/IP协议Haprosy已经成功运行了很多年,但是对于Nginx来说才刚刚开始支持,并且对于Haproxy支持的类型也比较多和稳定。
对于以上PXC集群已经搭建完成,这个时候就可以将数据进行同步。但是对于数据库上线以后,我们不能够将所有的数据请求打在同一个节点的上面,既然集群已经搭建完成,我们就需要让所有的节点都参与到数据的读写中,在数据请求到达时候要均匀的分布到每一个结点,所以就需要使用到负载均衡,将所有的节点都能够承担数据的访问请求。
- 安装Haproxy镜像
docker pull haproxy
- 使用
配置文件如下:
global
#工作目录
chroot /usr/local/etc/haproxy
#日志文件,使用rsyslog服务中local5日志设备(/var/log/local5),等级info
log 127.0.0.1 local5 info
#守护进程运行
daemon
defaults
log global
mode http
#日志格式
option httplog

#日志中不记录负载均衡的心跳检测记录
option dontlognull
#连接超时(毫秒)
timeout connect 5000
#客户端超时(毫秒)
timeout client 50000
#服务器超时(毫秒)
timeout server 50000
#监控界面
listen admin_stats
#监控界面的访问的IP和端口
bind 0.0.0.0:8888
#访问协议
mode http
#URI相对地址
stats uri /dbs
#统计报告格式
stats realm Global\ statistics
#登陆帐户信息
stats auth admin:abc123456
#数据库负载均衡
listen proxy-mysql
#访问的IP和端口
bind 0.0.0.0:3306
#网络协议
mode tcp
#负载均衡算法(轮询算法)
#轮询算法:roundrobin
#权重算法:static-rr
#最少连接算法:leastconn
#请求源IP算法:source
balance roundrobin
#日志格式
option tcplog
#在MySQL中创建一个没有权限的haproxy用户,密码为空。Haproxy使用这个账户对MySQL数据库心跳检测
option mysql-check user haproxy
server MySQL_1 172.18.0.2:3306 check weight 1 maxconn 2000
server MySQL_2 172.18.0.3:3306 check weight 1 maxconn 2000
server MySQL_3 172.18.0.4:3306 check weight 1 maxconn 2000
server MySQL_4 172.18.0.5:3306 check weight 1 maxconn 2000
server MySQL_5 172.18.0.6:3306 check weight 1 maxconn 2000
#使用keepalive检测死链
option tcpka
- 创建两个Haproxy容器
#创建第1个Haproxy负载均衡服务器
docker run -it -d -p 4001:8888 -p 4002:3306 -v /home/soft/haproxy:/usr/local/etc/haproxy --name h1 --privileged --net=net1 --ip 172.18.0.7 haproxy
#进入h1容器,启动Haproxy
docker exec -it h1 bash
haproxy -f /usr/local/etc/haproxy/haproxy.cfg
#创建第2个Haproxy负载均衡服务器
docker run -it -d -p 4003:8888 -p 4004:3306 -v /home/soft/haproxy:/usr/local/etc/haproxy --name h2 --privileged --net=net1 --ip 172.18.0.8 haproxy
#进入h2容器,启动Haproxy
docker exec -it h2 bash
haproxy -f /usr/local/etc/haproxy/haproxy.cfg

完成以上以后我们就可以开始进行本地的验证验证是否成功。前面提到了映射到本地的4001端口,就是说由Docker虚拟机的8888端口映射到linux虚拟机的4001端口,然后我们在本地进行连接的访问处理:
输入http://XXX.XXX.2.34/4001/dbs 发现对于以下的五个节点都有正常的运行。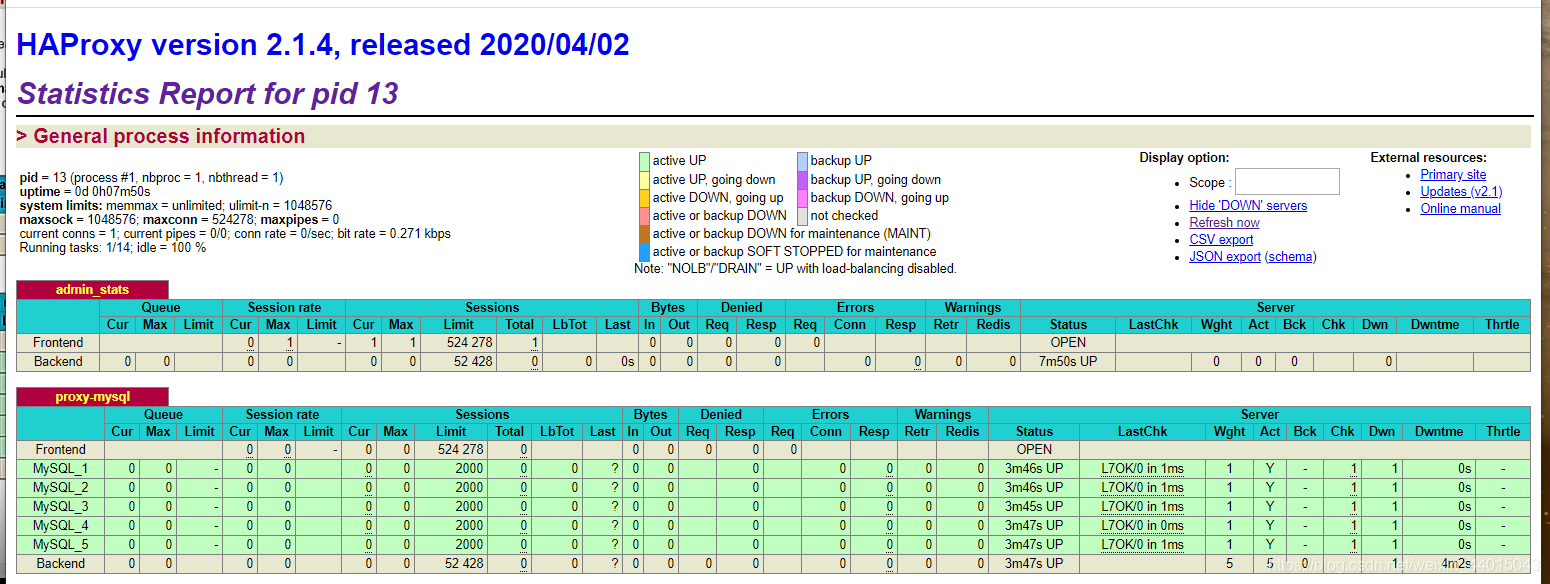
然后我们使用以下语句,挂掉一个结点docker stop node1再次查看情况。发现Mysql_1已经停止运行。
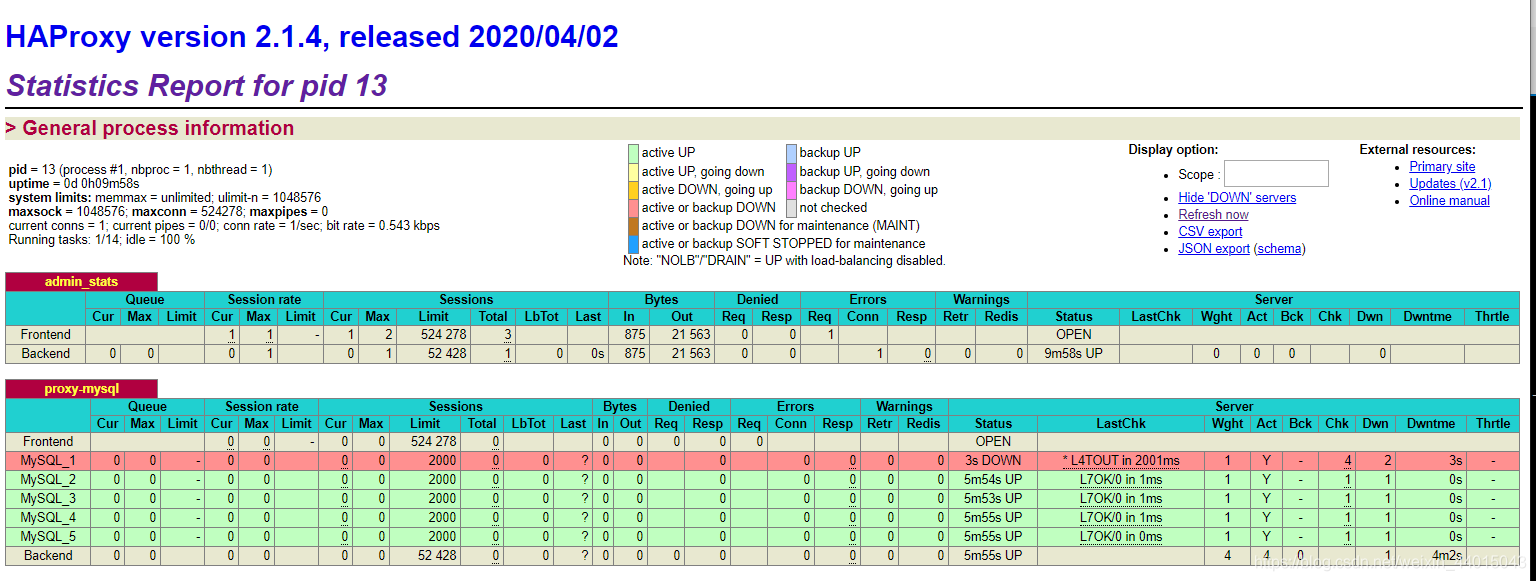
这个时候,在本地进行连接:
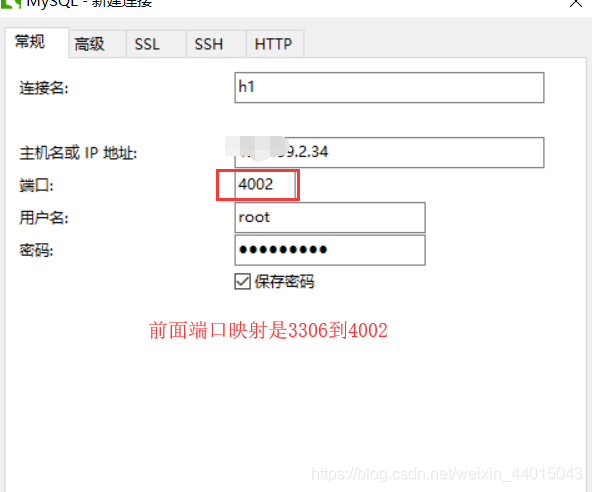
然后在h1中进行一个更改,会发现对于其他的数据库连接也会有相对应的更改(除去db1,因为前面我们已经把db1给停掉)。
通过以上的操作我们就暂时完成了对多个数据库进行了集群的搭建,使用到的是PXC,数据的强一致性。但是对于我们有了数据库集群,我们访问时候还是会访问到同一个节点,所以需要使用到负载均衡,使得我们搭建的数据库集群,在面对数据请求时候,能够将请求分布在各个节点之上,减少单个结点的压力。
双机热备
前面我们提到使用到了Haproxy技术实现了负载均衡,但是情况如下图所示:对于前端发送过来的请求通过Haproxy将请求数据分发确实能够降低每一个数据库实例的负载,但是若是Haproxy直接出现了故障,前端发起的请求就根本不可能到达后端的数据库,所以对于一个Haproxy不能够成为我们的瓶颈,还是要设置多个Haproxy实现双机热备。
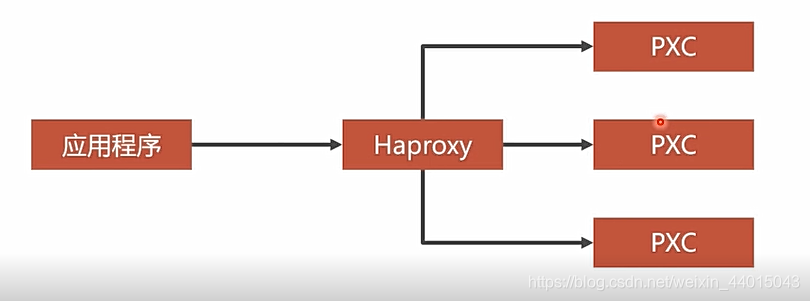
想要实现双机热备技术我们需要先了解一个知识点就是虚拟IP。
在linux的网卡中可以设置多个虚拟ip地址,然后将这些ip地址分配给对应的程序。
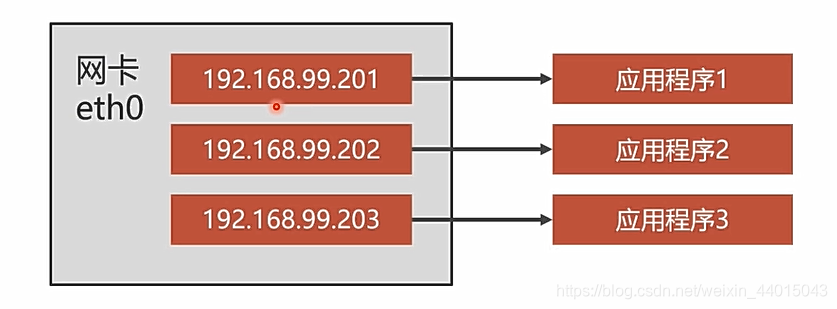
具体实现细节
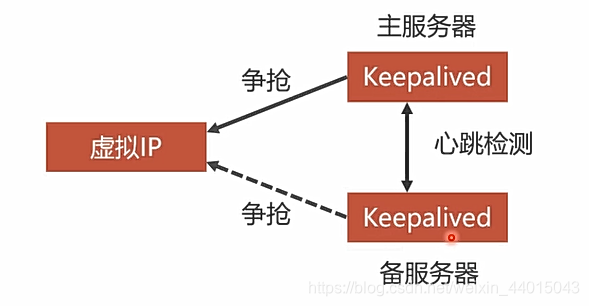
- 首先我们需要先定义对应的虚拟ip,然后将两个Haproxy定义在两个容器中,这里使用到了
KeepAlived,将Haproxy存放在这两个容器中,此时这两个容器来抢占设置的虚拟Ip,如下图所示:对应的两个KeepAlived谁先抢到虚拟ip就被认定为是主服务器,对于备用服务器会和主服务器之间进行心跳检测,如果备用服务器没有收到主服务器的心跳检测响应,就意味着主服务器可能出现了故障,这个时候备用服务器就可以去抢用虚拟IP。
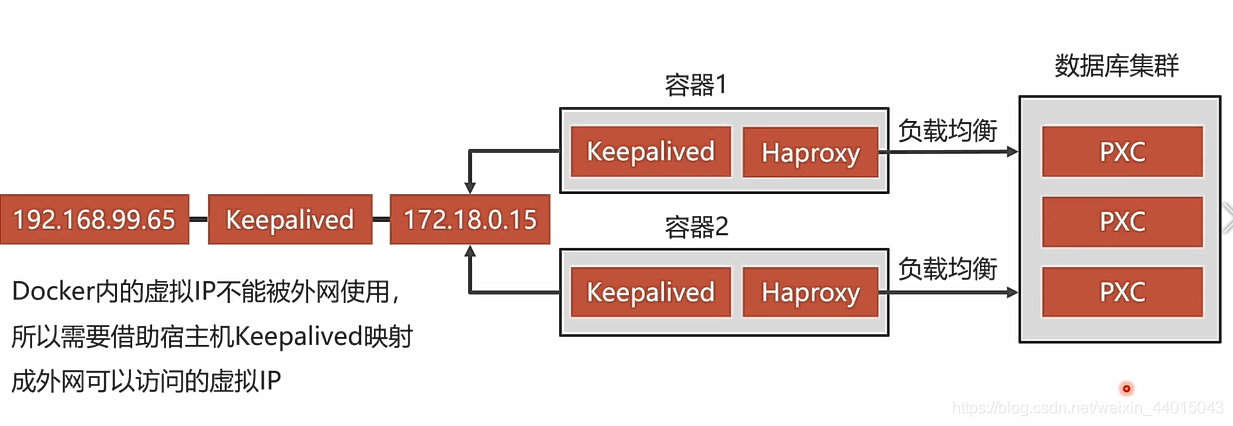
- 以上我们介绍了双机热备的实现原理,现在来整体观看一下具体的实现流程:
- 首先最右边是数据库集群,就是我们在最开始搭建的五个数据库结点的集群,然后使用到Haproxy实现负载均衡。
- 使用到一个Haproxy进行负载均衡可能就会出现一个Haproxy出现故障时候,对于整个数据库的集群都不能够再访问,所以需要搭建双机热备(两个Haproxy来实现)使用到Keepalived,搭建容器来抢用虚拟ip地址如下图中的172.18.0.15。
- 对于这个虚拟ip地址是docker内部的ip地址,需要使用到宿主机的Keepalived来将宿主机的192.168.99.65地址映射到docker内部的虚拟ip地址。
- 此时流程执行是:
- 访问到节点192.168.99.65时候,keepalived映射到docker内部的*172.18.0.15**。
- 对于这个虚拟ip地址两个Haproxy容器来抢占这个ip地址,抢到的是主服务器,没有抢到的就是备用服务器,两者之前会开启心跳检测,在一个发生故障时候,另外一个能够及时替补上。
- 最后使用负载均衡访问数据库节点,减少单个数据库结点的压力。
安装keepalived
因为我们有两个Haproxy,所以要先进入到对应的haproxy中:
- 对应的haproxy节点1
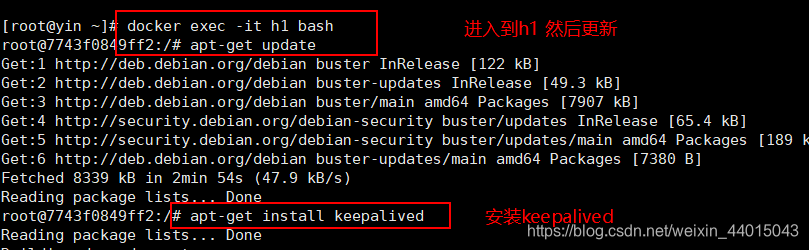
#进入h1容器
docker exec -it h1 bash
#更新软件包
apt-get update
#安装VIM
apt-get install vim
#安装Keepalived
apt-get install keepalived
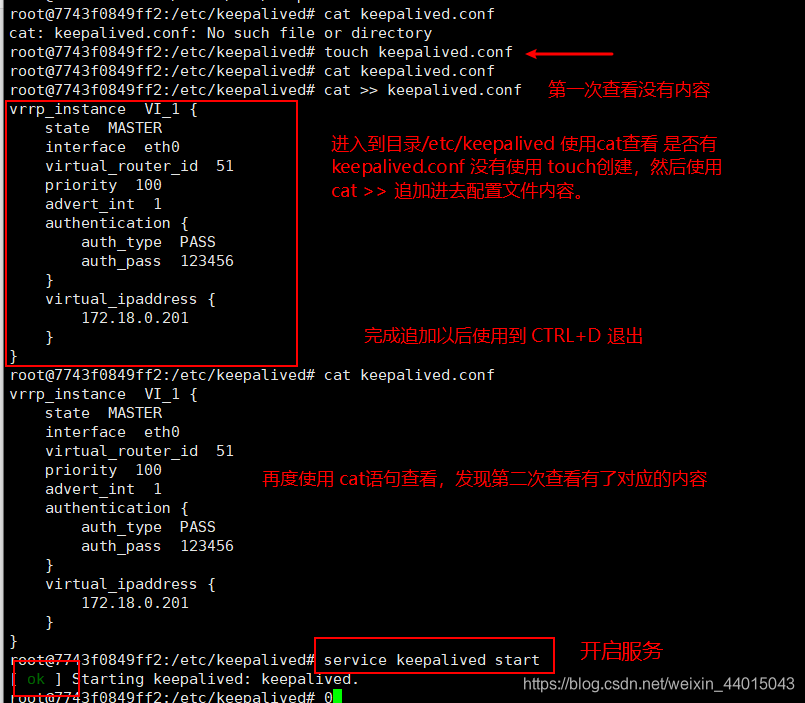
#编辑Keepalived配置文件(参考下方配置文件)
vim /etc/keepalived/keepalived.conf
# 这里若是不想下载vim可以使用 cat追加的方式
#启动Keepalived
service keepalived start
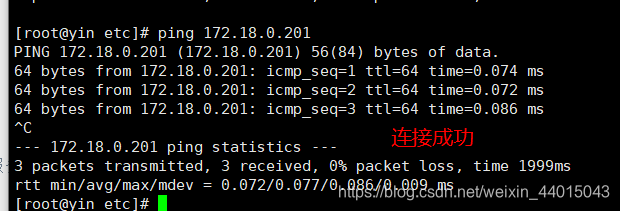
#宿主机执行ping命令
ping 172.18.0.201
将文件内容追加的配置文件中:
进行测试连接:
h1配置文件信息如下:
vrrp_instance VI_1 {
state MASTER
# 对于state的值有两个属性有两个属性,一个是 MASTER(表示主服务器,对于BACKUP表示备用服务器,我们在配置的时候将两个值都设置为MASTER 来共同抢用虚拟ip。)
interface eth0
# 保存到哪一个网卡,是一个虚拟的网卡
virtual_router_id 51
# keepalived 0-255 之间
priority 100
# 权重设置 硬件配置调整数字。
advert_int 1
# 心跳检测,1 表示1s。
authentication {
auth_type PASS
auth_pass 123456
}
# 心跳检测登录到某一个结点。
virtual_ipaddress {
172.18.0.201
}
# 虚拟ip设置 docker内部能看到
}
- 对应的haproxy节点2 (配置如同h1所示,这里不再进行逐一演示)
#进入h2容器
docker exec -it h2 bash
#更新软件包
apt-get update
#安装VIM
apt-get install vim
#安装Keepalived
apt-get install keepalived
#编辑Keepalived配置文件
vim /etc/keepalived/keepalived.conf
#启动Keepalived
service keepalived start
#宿主机执行ping命令
ping 172.18.0.201
配置文件内容如下:
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
172.18.0.201
}
}
-
宿主机安装Keepalived,实现双击热备
#宿主机执行安装Keepalived yum -y install keepalived #修改Keepalived配置文件 vi /etc/keepalived/keepalived.conf #启动Keepalived service keepalived start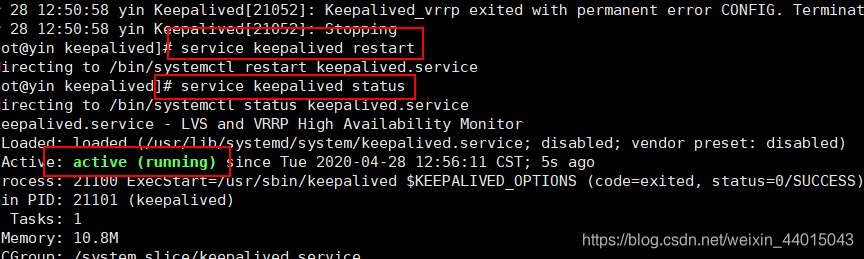
Keepalived配置文件如下:
进入到/etc/keepalived/keepalived.conf 进行修改如下:vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.99.150 } } virtual_server 192.168.99.150 8888 { delay_loop 3 lb_algo rr lb_kind NAT persistence_timeout 50 protocol TCP real_server 172.18.0.201 8888 { weight 1 } } virtual_server 192.168.99.150 3306 { delay_loop 3 lb_algo rr lb_kind NAT persistence_timeout 50 protocol TCP real_server 172.18.0.201 3306 { weight 1 } }
数据的冷热备份
冷备份
数据的备份分为冷备份与热备份之分,对于冷备份来说,需要系统下线将数据进行备份以后,再将系统进行上线处理。当然也有折中的办法,就是对于我们配置的而多个PXC结点,因为其中的数据都是相同的所以可以先下线一个PXC结点,然后进行数据备份完成以后再重新上线即可。

热备份
LVM:是Linux系统自带的一种备份的方式,Linux对某一个分区创建一个快照(就是将当前所有运行的状态记录下来,后面可以恢复到这个快照,就是恢复到创建快照时候机器的所有配置与状态)然后实现对这个分区数据的一个备份。原则上,可以备份任何类型的数据库 mysql,MonoDB,Innodb,但是比较麻烦而且还需要对数据库进行上锁,只能读取,不能够写入。
XtraBackup: 能够实现在写入的同时对数据库进行备份处理,性能比较高,并且还不需要对数据库进行加锁。支持全量备份,与增量备份。
全量备份与增量备份:数据的全部备份就是对数据库进行全部的备份,增量备份就是哪些数据发生了变化就对哪些数据进行备份。对于第一次的备份一定要采用全量备份,后面时候可以采用到增量备份。