一、简介
1.Hashtable:Entry<K,V>的数组加链表结构,默认长度11,扩容因子0.75,每次扩容后长度为(之前的长度*2)+1。基于synchronized方法保证线程安全。
put方法:计算索引值,判断应该放在哪个索引下,如果这个索引下有相同key,则覆盖,返回旧值,否则返回null。
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
get方法:计算当前哈希值,和应该在哪个索引下,遍历索引,如果hash和key匹配到,返回对应value,否则返回null。
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
2.ConcurrentHashMap:Node<K,V>的数组加链表||树状结构,默认长度16,扩容因子0.75,每次扩容后长度为之前的长度*2。在索引下添加当前Entry<K,V>。基于cas、synchronized和volatile保证线程安全。
put方法:根据 key 计算出 hashcode 。判断是否需要进行初始化。根据 key 定位出的 Node,如果为空使用 CAS写入。如果当前处于扩容阶段,则参与扩容,否则使用 synchronized 锁写入数据。如果当前链表长度大于8则转换为树状结构。
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
get方法:计算哈希,定位索引,如果是在主干上,直接返回value,如果是树那就按照树的方式获取值。否则按照链表的方式遍历获取值。
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
3.ConcurrentSkipListMap:Node<K,V>的链表结构。有序,基于cas和volatile实现线程安全。
结构示例如下:例如查找哈希值为3的节点,先确定在头结点和哈希值为5这个节点内,然后在确定在2-5内,然后定位到3。
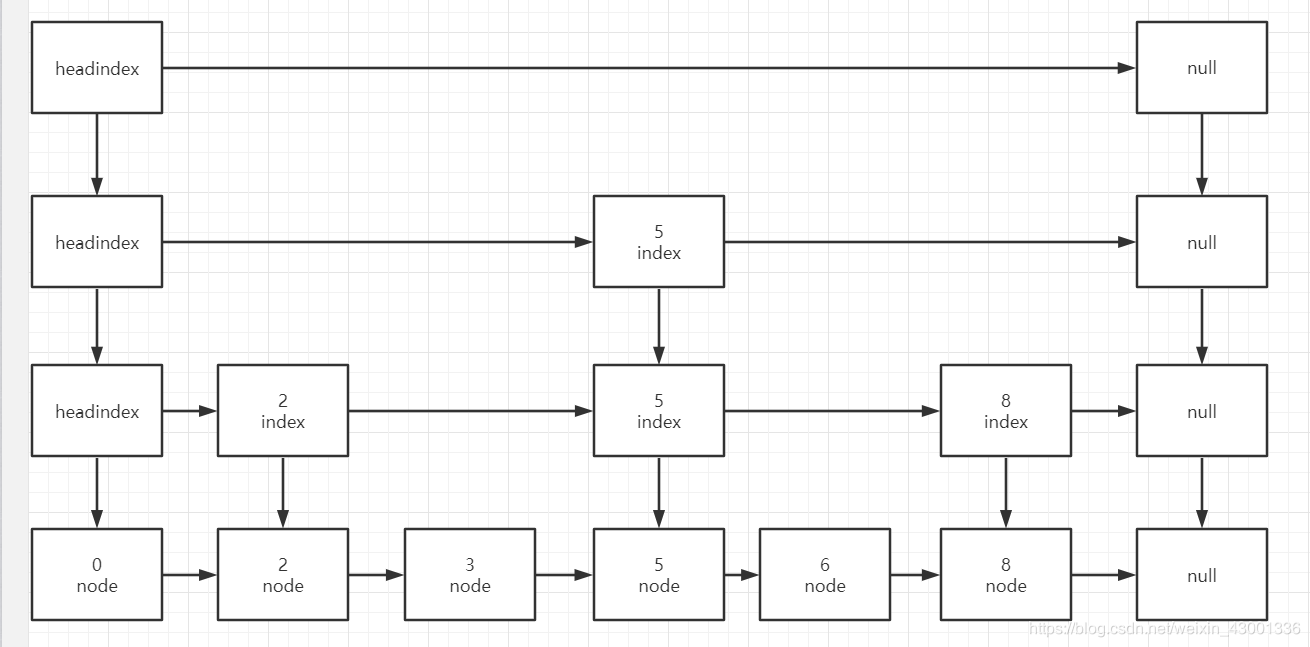
put方法:首先找到插入位置即找到key的前继节点和后继节点。新建节点z,并将新节点z插入,更新跳表。
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
return doPut(key, value, false);
}
private V doPut(K kkey, V value, boolean onlyIfAbsent) {
Comparable<? super K> key = comparable(kkey);
for (;;) {
Node<K,V> b = findPredecessor(key);//查找前驱数据节点
Node<K,V> n = b.next;//后继节点
for (;;) {
if (n != null) {
Node<K,V> f = n.next;
//后继两次读取不一致,重试
if (n != b.next) // inconsistent read
break;
Object v = n.value;
//后继数据节点的值为null,表示该数据节点标记为已删除,删除该数据节点并重试。
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
//b节点被标记为已删除,重试
if (v == n || b.value == null) // b is deleted
break;
int c = key.compareTo(n.key);
if (c > 0) {//给定key值大于当前,后移,继续寻找合适的插入点
b = n;
n = f;
continue;
}
if (c == 0) {//找到 onlyIfAbsent 入参就位true 设置值成功
if (onlyIfAbsent || n.casValue(v, value))
return (V)v;
else
break; // restart if lost race to replace value
}
}
//新建数据节点
Node<K,V> z = new Node<K,V>(kkey, value, n);
//绑定到下一节点
if (!b.casNext(n, z))
break; // restart if lost race to append to b
int level = randomLevel();//随机的索引级别
if (level > 0)
//建立索引
insertIndex(z, level);
return null;
}
}
}
private void insertIndex(Node<K,V> z, int level) {
HeadIndex<K,V> h = head;
int max = h.level;
if (level <= max) {//索引级别已经存在,在当前索引级别以及底层索引级别上都添加该节点的索引
Index<K,V> idx = null;
for (int i = 1; i <= level; ++i)//首先得到一个包含1~level个索引级别的down关系的链表,最后的idx为最高level索引
idx = new Index<K,V>(z, idx, null);
addIndex(idx, h, level);//新增索引
} else { // 新增索引级别
//索引级别加一
level = max + 1;
Index<K,V>[] idxs = (Index<K,V>[])new Index[level+1];
Index<K,V> idx = null;
//更新索引
for (int i = 1; i <= level; ++i)
idxs[i] = idx = new Index<K,V>(z, idx, null);
HeadIndex<K,V> oldh;
int k;
for (;;) {
oldh = head;
int oldLevel = oldh.level;
//更新头索引级别
if (level <= oldLevel) { // lost race to add level
k = level;
break;
}
HeadIndex<K,V> newh = oldh;
Node<K,V> oldbase = oldh.node;
//更新head索引
for (int j = oldLevel+1; j <= level; ++j)
newh = new HeadIndex<K,V>(oldbase, newh, idxs[j], j);
if (casHead(oldh, newh)) {
k = oldLevel;
break;
}
}
addIndex(idxs[k], oldh, k);
}
}
get方法:找到key的前继节点,然后找到前继节点的后继节点,如果key的值和前继节点的后继节点相等则返回value。
public V get(Object key) {
return doGet(key);
}
private V doGet(Object okey) {
Comparable<? super K> key = comparable(okey);
for (;;) {
// 找到对应的节点
Node<K,V> n = findNode(key);
if (n == null)
return null;
Object v = n.value;
//不为null 返回value
if (v != null)
return (V)v;
}
}
private Node<K,V> findNode(Comparable<? super K> key) {
for (;;) {
// 找到key的前继节点
Node<K,V> b = findPredecessor(key);
// 找到前继节点的后继节点
Node<K,V> n = b.next;
for (;;) {
// 如果n为null,直接返回null。
if (n == null)
return null;
//前继节点的后继节点的后继节点
Node<K,V> f = n.next;
// 如果两次读取到的后继节点不同 重新遍历。
if (n != b.next) // inconsistent read
break;
Object v = n.value;
// 如果前继节点的后继节点值为null 删除前继节点的后继节点并 前继节点的后继节点的后继节点绑定到前继节点
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
//前继节点被删除 跳出
if (v == n || b.value == null) // b is deleted
break;
// 若n是当前节点,则返回n。
int c = key.compareTo(n.key);
if (c == 0)
return n;
// 前继节点的后继节点的key小于当前key,则说明跳表中不存在key对应的节点,返回null
if (c < 0)
return null;
// 向下继续查找。
b = n;
n = f;
}
}
}
二、代码代码举例
说明:创建两个线程分别向Hashtable、ConcurrentHashMap、ConcurrentSkipListMap、HashMap容器对象添加10000个元素,最后打印容器长度。Hashtable结果:20000,ConcurrentHashMap结果:20000,ConcurrentSkipListMap:20000,HashMap:<20000(添加元素方法不是同步的,连两个线程放的key进行哈希运算后确定放的位置相同并且都为null情况下,t1线程放完,t2会覆盖t1存放的值)。
public static void main(String[] args) {
// HashMap<UUID,String> map = new HashMap<>();
// Hashtable<UUID,String> map = new Hashtable<>();
// ConcurrentHashMap<UUID,String> map = new ConcurrentHashMap<>();
ConcurrentSkipListMap<UUID,String> map = new ConcurrentSkipListMap<>();
new Thread(() ->{
for (int i = 0; i < 10000; i++) {
map.put(UUID.randomUUID(),"1");
}
}).start();
new Thread(() ->{
for (int i = 0; i < 10000; i++) {
map.put(UUID.randomUUID(),"1");
}
}).start();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(map.size());
}
三、Hashtable、ConcurrentHashMap、ConcurrentSkipListMap对比
1.Hashtable:使用synchronized保证线程安全,锁定方法,效率低。
2.ConcurrentHashMap:使用cas、synchronized、volatile保证线程安全,效率较高。
3.ConcurrentSkipListMap:有序、跳表结构,基于cas、volatile保证线程安全、效率较高。