1 执行计划中的“点”
1.1 顺序扫描Seq Scan


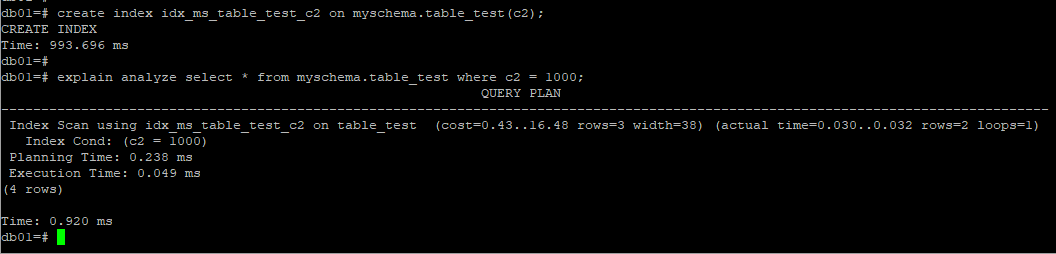
1.2 索引扫描IndexScan
如果不需要回表的话,执行计划如果表达这种逻辑?
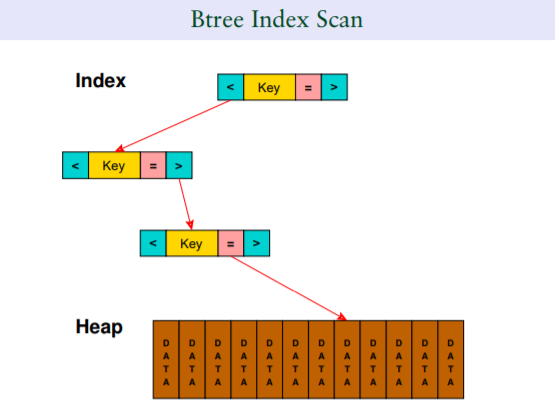
1.3 Index Only Scan

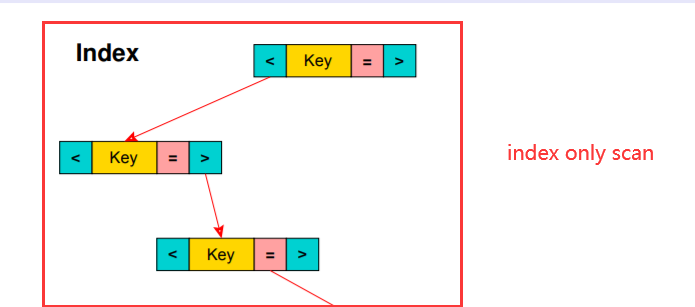
1.4 位图索引扫描Bitmap Index Scan
bitmap的图形化示例,其中包含了两部分,第一是bitmap的生成过程,第二是多个bitmap之间的与(或)操作后排序,然后回表的过程。
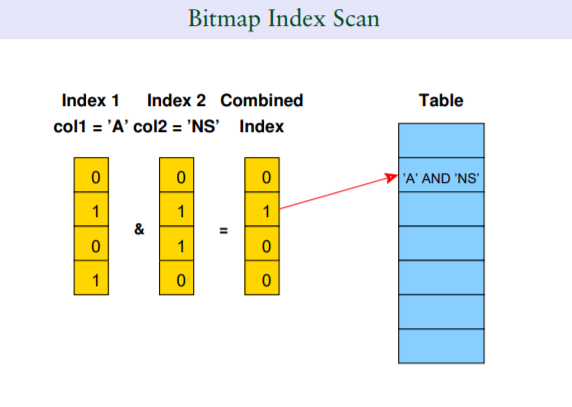
1.5 预期的index only scan没有出现
由于Index Only Scan表示仅需要索引就可以找到所需要的数据,无需回表,那么同样在无需回表的情况下,postgresql如何区分对索引树(b+)树的查找(真正的二分法查找)和扫描(扫描整颗B+树)?这个是一个有意思的问题,这里刻意创建一个抑制索引使用的但是无需回表的查询: select c2 from myschema.table_test where c2+1 = 1001;,
看看会发生什么,这也是笔者在解除postgresql执行计划后一个百思不得其姐的问题,他竟然总的是走了一个全表扫描???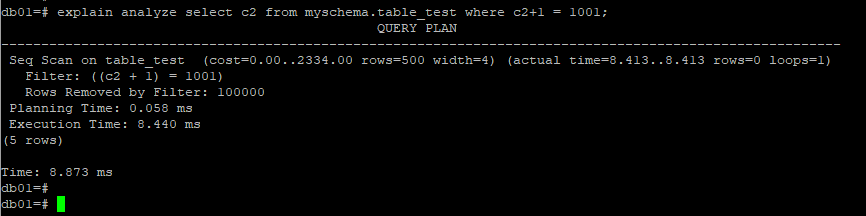
对于这个查询,可以肯定的是,索引树的大小(size)是肯定小于基表的堆结构的,即便是无法直接使用到索引,但是扫描整个索引树的代价是远远小于整个基表的, 最后还是从官方文档中发现这个对这个问题的解释,真相还是有点意外。

其实这个并不难理解,当where条件时c+1 = 1001的时候,因为c+1 并不是一个直接可用的索引字段,优化器并不知道这个表达式经过计算后可以转换成一个索引字段,因此会走全表扫描。
在Postgresql中是行不通的,类似查询Postgresql中并不会扫描一个较小的二级索引来实现count计算,而依旧走的是一个全面扫描。
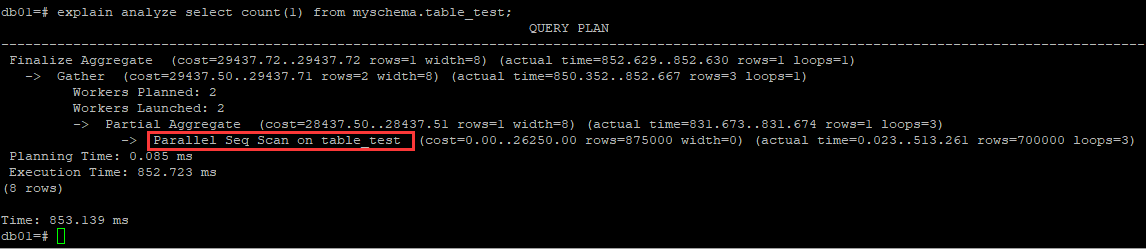
事务可见性以及MVCC,这一点还是比较有搞头的,埋个坑先: 因为事务的可见性只在数据行中标记,对索引是不生效的, 难道说通过二级索引回表找到的记录,都要进行一次可见性判断?
2 执行计划中的“线”
相比MySQL执行计划连接路径的贪心算法,贪心算法最大的问题在于只关心局部,而不关心整体,可能每一步都是最优解,但最终可能不是最优解的情况。
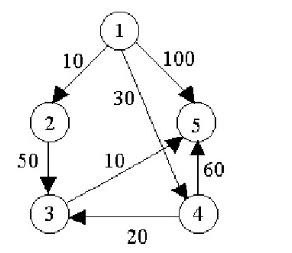
postgresql采用动态规划算法和遗传算法结合起来生成执行计划,理论上说postgresql的执行计划生成算法是更加优秀的, 类似图的最短路径算法,比如从1到5的最短路径:
2,对于动态规划算法会走1=》4=》3=》5的路径,其代价明显优于贪心算法的结果。
贪心算的问题也很明显,也是实际使用种MySQL会经常被人吐槽子查询的问题,以及个人实际遇到的派生表的性能问题,尽管MySQL在这方面一直在改进。
对于动态规划算法可以遍历所有路径来获取一个最短路径,这种算法在节点数超过一定程度之后的时间复杂度会呈指数级增长,因此postgresql也会采用折中一些的遗传算法来实现。
前者实现简单,时间复杂度低,但存在非最优解的情况;
后者尽管可以得到最优解,但是其时间复杂度要大于贪心算法。
其实这恰恰吻合了互联网项目短平快的特点么,所以MySQL适合这一套,有点野路子的风格(话说mysql的出身就比较野路子)。
3 执行计划中的“面”
3.1 join方式
这里的“面”是表与表之间的连接处理方式,其实就是经典的loop join,merge join,hash join这三种join方式。
3.1.1 loop join
适合处理两个较小的结果集的场景,同时,尽管是较小的结果集,在有索引驱动的情况下loop join的效率也会相对较高,第二个图例就代表着基于索引驱动的loop join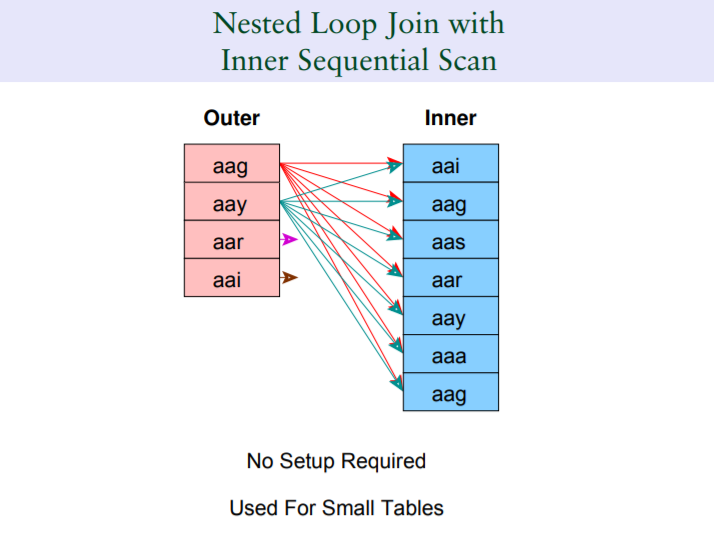

3.1.2 merge join
适合处理两个有序结果集的场景,或者jion双方本身存在一致的索引键
相比loop join只有outer表会前推,merge join在join的时候,outer和inner表同时有一个“前推”的过程,也就是说随着join的进行,outer表的键对inner表的探测次数会越来越少。
要清楚,outer table和inner table的有序是merge join的因,而非果。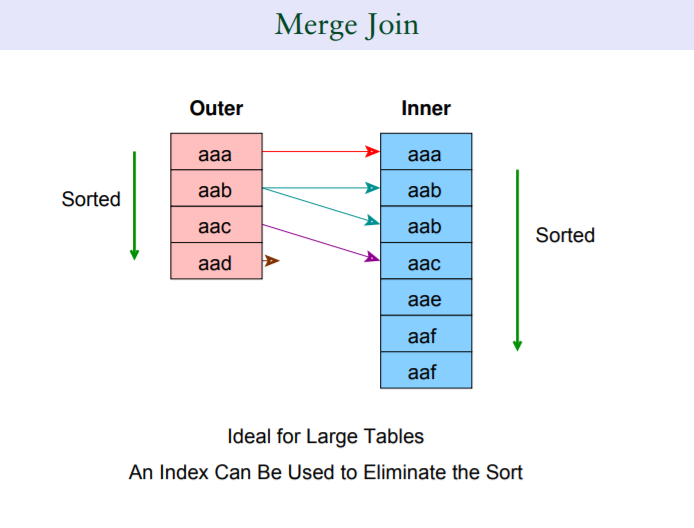
3.1.3,hash join
对于无索引且结果集较大的场景,属于重量级的查询处理。
其实平时不得见经常出现hash join,如果一个系统的查询中经常出现hash join,也不见得是一件好事,在前面两种足够“轻量级”join方式处理不动时的一种选择。
相比以上两种join方式,hash join可能较为难理解一点:hash join简单说分两个阶段,第一个阶段是构建hash桶,对join双方较小的一个表的连接键生成hash桶,第二个阶段是对join的另外一张表的键值基于hash运算后进行探测。
为什么要这么做?其实还是跟“join条件上没有索引有关”,相当于间接性地生成了一个hash索引,因此这种情况适合join双方都变较大,且没有索引的场景。
那么,为什么在重量级的join情况下为什么不加索引呢,所以上面也说了,经常看到hash join并不代表什么好现象,而是一种不得已的选择。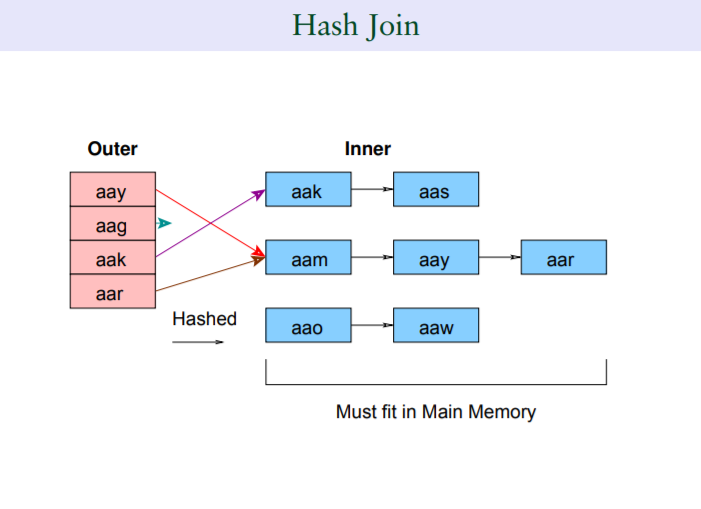
并行查询
并行查询可以应用在绝大多数上述的点线面中
比如并行Seq Scan,并行Index Scan,并行join等等,其目的就是多个CPU协同工作,然后汇总的一种思路,这一点postgresql还是比较给力的,当然也不是并行线程数越多越好(max_parallel_workers)。
强制查询提示
查询提示作为优化的debug作用,可以尝试强制按照非默认的执行方式来对比,参考这里:https://blog.csdn.net/jackgo73/article/details/89711523
以上截图这些有趣的图片来自于:https://momjian.us/main/writings/pgsql/internalpics.pdf