一、问题描述
- 现在有40亿个不重复的unsigned int的整数,并且是没有排过序的。然后现在再随机给出几个数字
- 现问:如何快速判断这几个数字是否在这40亿个数中?
二、解决方案1(在内存中解决)
- 第一步:unsigned int的取值范围为
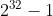 (为4294967295),显然已经超过了40亿
(为4294967295),显然已经超过了40亿
- 第二步:我们创建一个大小为4294967295bit的数组(4294967295bBit = 536870911Bytes = 524287Kb = 512Mb),因此内存只占用了512M左右,初始化时所有的bit位为0
- 第三步:我们可以将这40亿个数字存放到bit数组对应的位置,并将对应的位置置1
- 第四步:想要查找哪个数字,就查找对应的比特位就行了(时间复杂度为O(1),因为直接通过索引查找)
三、解决方案2(在磁盘中解决)
- 这个问题在《编程之美》中曾出现过
- 第一步:unsigned int的取值范围为,因此我们可以把这40亿个的每个数字用一个32位的二进制来表示
- 第二步:把这40亿的数字首先都放在一个文件中
- 第三步:然后读取这个文件,将最高位为0的存放到一个文件中(例如取名为A.txt,里面的数字<=20亿),将最高位为1的存放到一个文件中(例如取名为B.txt,里面的数字>=20亿)
- 然后根据要查找的数字到对应的文件中查找,如果查找到了就结束查找
- 没有查找到,进入第四步
# A.txt: 这些数字<=20亿, 存放到一个文件中
0xxx xxxx xxxx xxxx xxxx xxxx xxxx xxxx
# B.txt: 这些数字>=20亿, 存放到另一个文件中
1xxx xxxx xxxx xxxx xxxx xxxx xxxx xxxx
- 第四步:将上面的每个文件再分别分为两个文件,与上面的原理一样,一个文件的次比特位为1,另一个文件的次比特位为0
- 这样又把要查找的数字的范围折成一半了,因此想要查找哪个文件就到哪个文件中去找到,如果查找到了就结束查找
- 没有查找到,进入第五步
# A.txt分为A2_1.txt、A2_2.txt两个文件
# A2_1.txt: 这个文件中的数字的第二个比特位为1
01xx xxxx xxxx xxxx xxxx xxxx xxxx xxxx
# A2_2.txt: 这个文件中的数字的第二个比特位为0
01xx xxxx xxxx xxxx xxxx xxxx xxxx xxxx
# B.txt分为B2_1.txt、B2_2.txt两个文件
# B2_1.txt: 这个文件中的数字的第二个比特位为1
11xx xxxx xxxx xxxx xxxx xxxx xxxx xxxx
# B2_2.txt: 这个文件中的数字的第二个比特位为0
10xx xxxx xxxx xxxx xxxx xxxx xxxx xxxx
- 第五步:与上面相同的道理,将每个文件再分别分为两个文件,对应的文件的数字的第三个比特位分别为1和0
- ......以此类推,直到找到位置
- 这种方法的时间复杂度为O(logn)