OCR for semantic segmentation
论文地址
这是我的第一篇博客,近期做了很多语义分割的任务,尤其是19年影响较大的HRNet和OCR,借这篇博客记录一下,接触这个方法也是因为要使用HRNet做语义分割任务,然后发现19年霸榜的HRNet+ocr,这里记录一下OCR的方法,HRNet在以后的博客中记录吧。
前言
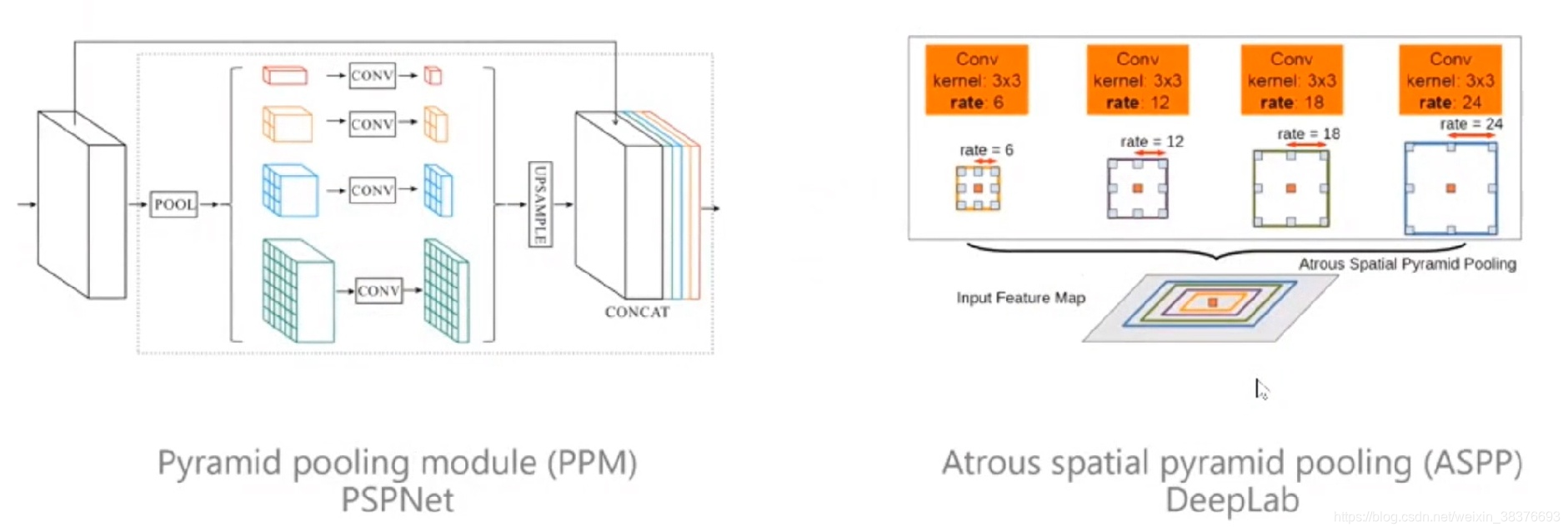
当前的FCN没有解决好物体上下文信息。因为单独看一个像素,很难知道这个像素是属于某一个物体的,因为像素给我们的信息是RGB的信息,如果不给予足够多的上下文信息是很难判断的。下图列举了商汤科技的PSPNet和谷歌的ASPP。PSPNet通过给每个象素周围建立多尺度的表征获取上下文信息,当时这个方法取得了非常大的突破,主要的模型有Parsenet,PSPNet等。同时谷歌的ASPP也用了类似于空洞卷积的方式来实现上下文信息获取,DeepLabV2以后都使用了这个结构。
核心思想和主要贡献
核心思想:
同时考虑像素和区域来计算像素和区域之间的关系,利用每一类的全局语义依赖给每个像素进行加权,生成每个像素的语义表示,然后根据语义表示判断像素的类别。这种方法是一种关系上下文方法,与双重注意和ACFNet有关。不同之处在于区域形成和像素区域关系计算。某种意义上来说,也是一种由粗到细的策略。

在上图中,ASPP通过不同的空洞卷积来采集像素的上下文信息,不同颜色代表不同的空洞卷积,包含背景和目标像素。OCR则是通过周围像素的表征来寻找目标,具体是将红色像素周围属于物体的像素点取出来作为上下文信息。
主要贡献:
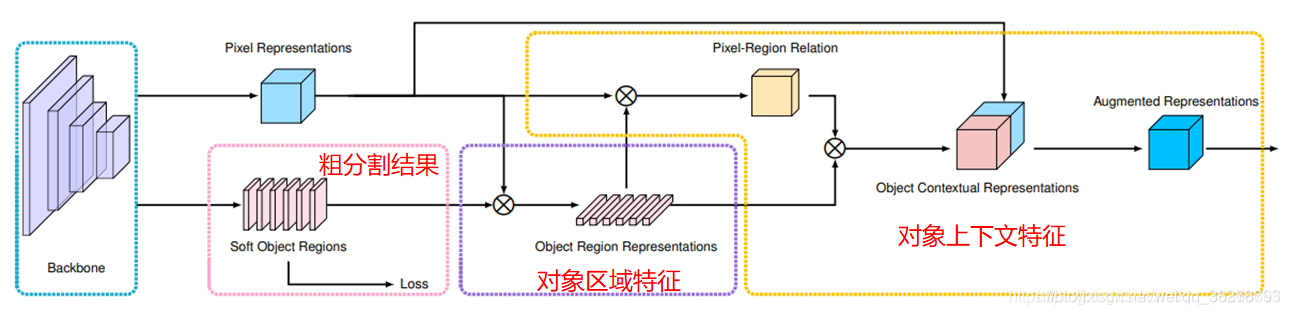
提出了一种新的关系上下文方法,该方法根据粗分割结果学习像素与对象区域特征之间的关系来增强像素特征的描述。通过与前面的方法对比,可以得出:与之前的关系上下文得出对象与对象的结果不同,OCR学习了像素与对象区域的关系。
整体结构
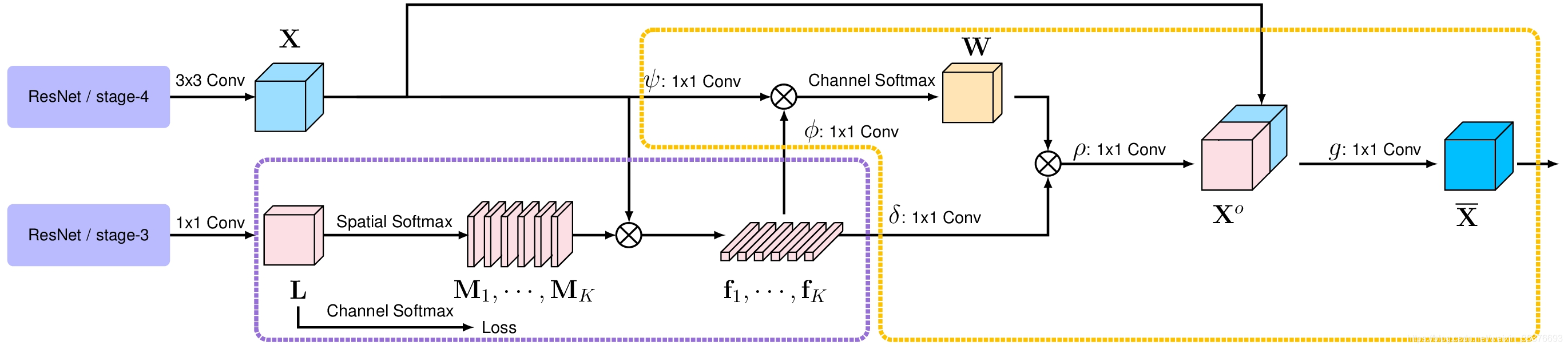
整体结构为上图(ResNet为backbone),主要有两个部分:估计紫色虚线框中的对象区域和表示,以及计算橙色虚线框中的对象上下文表示。紫色框内又可以分为两部分,第一部分将上下文像素划分为一组软对象区域,每个软对象区域对应一个类别,对应于M1——Mk输出的粗分割结果;第二部分是通过聚合相应对象区域中的像素表示作为每个对象区域的表示。对应于紫色框剩余部分。
具体方法
Backbone:ResNet or HRNet
Pixel Representations:backbone得到的特征图先进行
的上采样(具体为什么用
可以参考HRNet关于
卷积的说明)。
Soft Object Regions:对backbone得到的特征图进行
卷积上采样,然后进行语义分割得到粗分割结果(特征图通道为类别数目)。
Object Region Representations:每类对象的特征表示为
Pixel-Region Relation:每个像素与每个对象区域之间的关系 。
Augmented Representations:将对象上下文模块与初始特征图concat得到Object Contextual Representations,再进行通道数改变(变为类别通道数)。
对比试验
像素-区域关系方法

ACFNet:
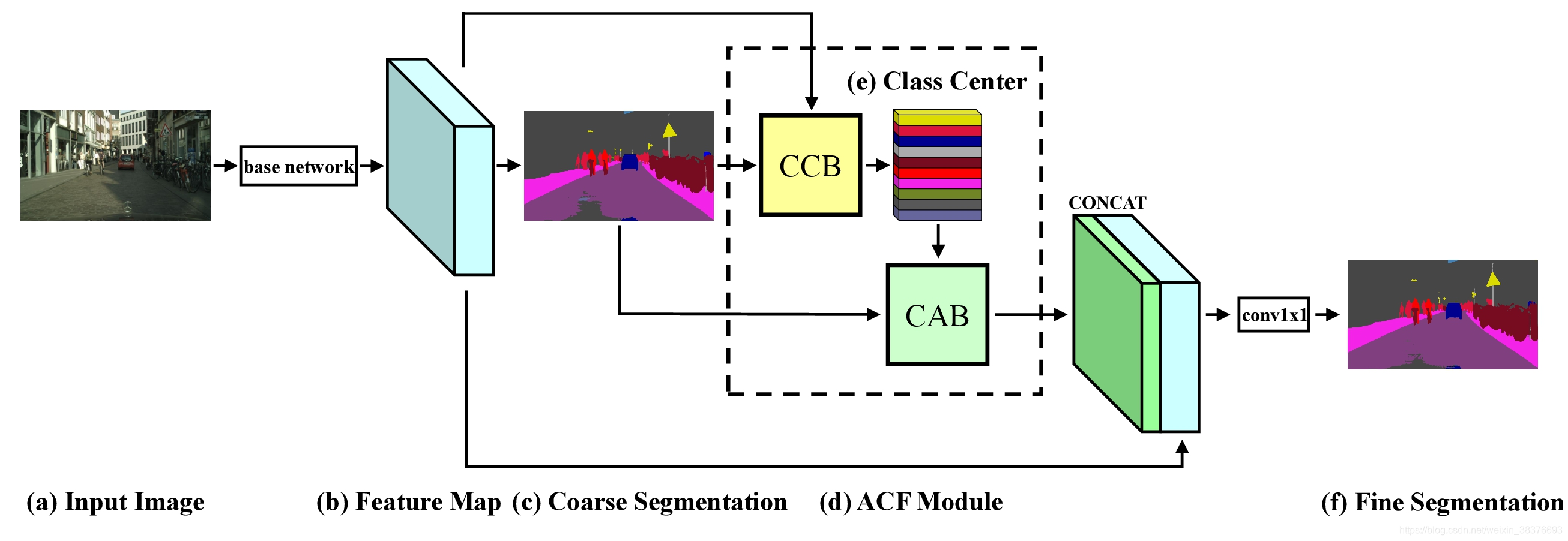
给定输入图像(a),我们首先使用CNN(基础网络)来获取较高层的特征图(b)和相应的粗略分割结果(c)。然后,应用注意力分类特征(ACF)模块(d),根据每个像素的粗略分割结果,计算出不同类别的分类中心(e)和每个像素的注意力分类特征。最后,将注意力类别特征和特征图(b)连接起来以获得最终的精细分割(f)。网络主体操作由CCB模块与CAB模块实现。整体结构与OCR相似,不同点在于对象区域特征的计算部分,ACFNet只是将属于某一类对象的所有特征进行了简单的加和平均(即Class Center),所以效果比较差。
多尺度上下文方法

PPM以及ASPP在上方可以看到,使用DeepLabV3+和HRNet+OCR进行分割时后者表现确实好一些。
关系上下文方法

DANet
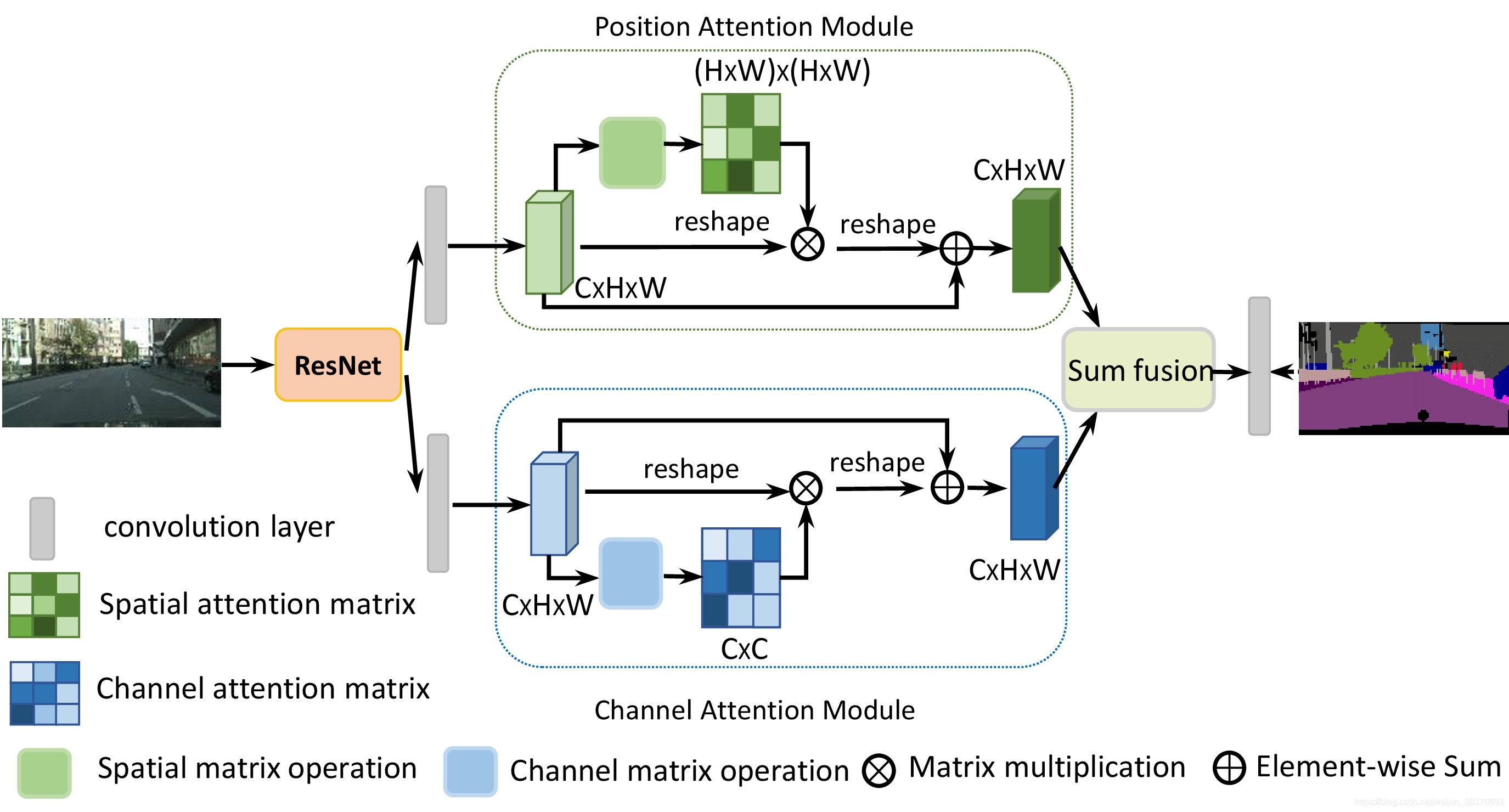
DANet引入了一种自我关注机制,分别捕获空间和通道维度中的特征依赖性。具体而言,在扩张的FCN顶部附加两个平行的注意模块。一个是position attention模块,另一个是channel attention模块。对于position attention模块,引入自我关注机制来捕获特征映射的任意两个position之间的空间依赖性。对于某个position的特征,通过加权求和在所有position聚合特征来更新,其中权重由相应两个position之间的特征相似性决定。也就是说,具有相似特征的任何两个position可以促进相互改进,而不管它们在空间维度上的距离。对于channel attention模块,使用类似的自我关注机制来捕获任意两个channel映射之间的channel依赖关系,并使用所有channel映射的加权和来更新每个channel映射。最后,融合这两个注意模块的输出以进一步增强特征表示。
多尺度上下文方法是将不同感受野的特征综合起来对特征进行丰富(通常基于金字塔池化或空洞卷积),关系上下文方法是利用特征之间的关系对特征进行丰富(通常基于自注意力机制)
主流模型对比
以Cityscapes val的结果为对比,可以看到HRNetV2+OCR的结果是较好的。

LIP数据集的各模型比较:

与PASCAL VOC 2012测试中的最新技术的比较:

与COCO-Stuff 测试集上的最新技术对比:

总结
在语义分割任务中,HRNet+OCR的表现优于目前绝大多数的语义分割模型,此博客仅记录学习OCR过程,在我实验的语义分割中,DeepLabV3+ + Xception的效果比HRNetV2+OCR差一点,加上OCR的HRNet比原来会涨0.1左右。