通过深度对抗性互学习改进领域适应情绪分类

Abstract
域适应情绪分类是指在已标记的源域上进行训练,以很好地推断未标记的目标域上的文档级情绪。大多数现有的相关模型包括一个特征提取器和一个情绪分类器,其中特征提取器致力于从两个领域学习领域不变特征,而情绪分类器只在源领域上进行训练,以指导情绪提取器。因此,他们缺乏一种机制来利用目标域中的情绪极性。我们设计了一种新的深度对抗互学习方法,包括两组特征提取器、领域判别器、情绪分类器和标签识别器。域鉴别器使特征提取器能够获得域不变特征。同时,每组的标签检测器通过同级分类器生成的情绪预测来探索目标域的文档情感极性,并指导本组特征提取器的学习。该方法以端到端的方式实现了两组间的相互学习。该方法实现了两组学生端到端的相互学习。在多公共数据集上的实验表明,我们的方法获得了最先进的性能,验证了通过标签探针进行交互学习的有效性。
Introduction
自适应域情绪分类的目的是训练一个已标记的源域能够很好地推断未标记的目标域上的文档级情绪。它是情感分类(Liu 2012)和无监督域自适应(Ben-David et al. 2010)研究的自然交叉,随着Amazon, Yelp,等在线浏览平台的蓬勃发展而受到广泛关注。一方面,评论的总量非常庞大,这给人们寻求有效的情感分类模型带来了机会(Tang,Qin,Liu 2015a)。另一方面,大量的评审领域(如amazon中的产品类别)使得在每个领域手工注释足够的数据来训练特定领域的模型变得非常困难。因此,开发自动适应领域的方法是这个领域的当务之急。值得注意的是,该任务比其他跨领域情感分类任务更具挑战性,因为后者需要目标领域的标记数据(Peng et al. 2018)。
一个简单的解决方案是直接将训练在源域上的情感分类模型应用到目标域。它不从目标域获得任何训练指导。然而,这并不理想,因为它忽略了不同领域之间的语义差距。
领域相关情绪词的潜在小集合交集表明,改进朴素解决方案的潜力巨大。因此,建立一个适应领域的情感分类模型,对提高分类效果具有重要意义。
现有的相关研究可归为两大类:
- 两阶段方法(Blitzer、Dredze和Pereira2007;Glorot, Bordes,和Bengio 2011;Ziser Reichart2018;
- 端到端模型(Ganin et al. 2016;He et al. 2018;Qu等,2019)。
两阶段的方法是在第一阶段近似地构造无监督特征提取器或手动选择跨域的主特征。在第二阶段,在标记的源域上训练一个情绪分类器。然而,第一阶段不能直接由 ground-truth 指导,而中心(pivot)特征的选择有一点过于经验性和昂贵。另一方面,受益于先进的学习技术,如对抗性学习(Ganin and Lempitsky 2015)和最大平均差异(Gretton等人,2005)。2012a),端到端模型在不依赖枢轴特征的情况下,通过对领域变量特征抽取器和情感分类器的整体训练,克服了上述问题。然而,尽管他们取得了很好的结果,但在大多数端到端模型中仍然存在一个主要的限制:来自目标域的数据没有被充分利用。也就是说,他们的情感分类器和特征抽取器忽略了目标域评论文本中的情感极性。在这方面的一项相关研究(He et al. 2018)通过自集成自举技术在目标域获得伪标签,以训练其情绪分类器和特征提取器。然而,伪标签是由早期版本的情感分类器异步生成的,与当前版本相比,它是一个较弱的分类器,并且可能会限制训练的有效性。
在本文中,我们提出了一种新的学习方法——深度对抗互学习(DAML)。通过对无标签目标域的情绪极性学习,实现了域适应情绪分类。这部分是受到最近提出的深度互动学习(DML)的启发(Zhang et al。2018年)对于有监督的单域任务,两个分类模型通过同步推断的情感标签分布(补充真实标签)相互教导。相互学习的合理性在于,这些模型可以协作学习,并在整个训练过程中将自己所学的知识传递给彼此。这使得模型对数据中的噪声具有鲁棒性。我们通过DAML将交互学习扩展到无监督的跨域情感分类场景。它包括两组特征抽取器,域鉴别器,情感分类器和标签探测器。与标准的互学习不同,我们利用每组中的标签检测器来学习目标域中由另一组分类器生成的文档伪标签分布情况。同时,标签探测器通过梯度反向传播来指导相应群体中的抽取器的学习。通过上述方式,probers充当分类器和提取器之间的桥梁,确保它们使用目标域中的感知信息。探测器的另一个优点是,它们使分类器不必彼此对齐,这是标准交互所需要的,但在完全无监督的场景中会损害性能(见图3a)。此外,我们利用梯度反向层(GRL) (Ganin et al. 2016)使用域鉴别器学习域变体特征提取器。两组模型可以看作是端到端相互学习的两个模型,以提高在目标域上的泛化能力。
我们将这项工作的主要贡献总结如下:
- 我们讨论了在目标域中情感极性的学习,这在以前的研究中被忽略了。我们提出了一种结合了一般学习和交互学习优点的DAML,以及引入了从分类器中学习并指导抽取器学习的标签探测器。据我们所知,这是首次采用互学习方法进行领域适应情绪分类的研究。
- 我们还验证了与标签检验者相互学习比直接应用标准相互学习效果更好。
Related Work
Domain adaptation
领域适应一直是一个有吸引力的研究课题,因为它的实际应用是标记数据只能在一个源域内获得(Panand Yang 2009)。源人们普遍认为,源域与目标域之间的分布差距是最根本的挑战。为了解决这个问题,早期的基于实例的方法根据重要性抽样的思想重新衡量每个源示例,以匹配目标数据分布(Huang等人。2007年)。最近在学习不同域特征表示方面的进展包括:对抗学习(Ganin和Lempitsky 2015),它训练提取器欺骗域分类器,以及最大平均偏差(MMD) (Gretton et al. 2012b),它测量了域偏移的程度并使其最小化。在基于领域的情感分类的具体场景中,基于数据点的方法首先启发式地选择领域共享中心特征,然后利用这些特征学习特定领域情感词的对应关系。然而,这种经验式的分离代价有点高,而且它的不准确性会被传递到接下来的学习步骤中。其他一些研究(Glorot, Bordes,和Bengio 2011)采用了类似的两阶段过程,第一阶段学习无监督域变特征提取器(如堆栈去噪自动编码器(Vin-cent et al. 2008)),然后将获得的特征作为输入训练一个感知分类器。由于上述方法的第一阶段的性质是不受情感标签的引导,因此有可能通过端到端的方式来提高它们。近期的一些方法(Ganin et al. 2016;He et al. 2018;Qu et al. 2019)采用对抗式学习或MMD来完成端到端学习。然而,正如前面所讨论的,他们不可避免地会受到在目标领域忽视情绪极性的限制,或者不能有效地利用它们。相比之下,我们的工作提出了新的DAML方法来解决上述问题,这是本文最重要的贡献。
Sentiment classification
尽管已有关于领域适应性情绪分类的研究,但大量的工作致力于开发性能良好的单域情感分类模型(Zhang and Wang 2015),尤其是基于深度学习的模型,包括递归神经网络(Socheret al。2013),卷积神经网络(Kim 2014),循环神经网络(Tang,Qin,Liu 2015a)等。据我们所知,分层注意力网络(HAN)(Yang等人。2016)是最先进的情感分类模型,根据(Chen等人。2016;Wu等人。因此,我们的工作采用了除最后一个前馈输出层之外的HAN的主要部分作为特征提取器。
Deep mutual learning
深入的相互学习(Zhang et al。2018)是最近在模型蒸馏背景下开发的一种学习方法 (Hinton, Vinyals, and Dean 2015), 但是它没有使用一个更大的教师模型来指导训练过程。除了学习适应真实的标签之外,DML使分类器通过模仿其他分类器,推断标签分布并发现其应用(Kanaci et al. 2019;Wu et al. 2019)同时相互学习。然而,目前尚无研究探讨其在领域适应分类任务中的作用。随后,我们在实验中表明,将对立学习与标准互学习的朴素结合并不能提高任务的执行效率。
Our Approach

Approach Overview
该方法由两组特征提取器、领域识别器、情绪分类器和标签识别器组成。这两个组具有完全相同的结构,但有各自的参数,其中每个组都与源和目标域相关联。特征提取器从源域和目标域获取文档作为输入,并最终获得文档表示,这些文档表示被输入到每个组的其他组件中。在域判别损失的指导下,域判别器与梯度反向层一起保证提取器得到域不变特征。通过基于互学习Loss的优化方法,每组中的检测器与另一组中的分类器相关联。此外,每个分类器还对应一个分类loss带标记的源域。

Feature Extraction
我们使用HAN作为特征提取器来生成情感文档的表示。HAN采用层次结构来反映文献的词级结构和句子级结构。




Sentiment Classification

Domain Adaptation
为了使特征抽取器具有学习领域不变表示的能力,我们考虑了对抗学习方法。特别是,我们引入了一个域判别器D,它试图找出一个文档向量是从哪来的。相反,特征提取器的目标是欺骗D。



一旦FE能够防止鉴别器D从源域或目标域分离数据,则假定FE已被成功地训练成在一定程度上只保留与域无关的信息。
Integration with Mutual Learning
到目前为止,我们已经能够从建模其数据分布的角度利用目标域。然而,由于所涉及的情绪信息没有被明确地捕捉到,这一点还远远不能令人满意。
一种自然的解决方法是生成目标域的伪标签来指导情感分类模型的学习。
在被研究的单域任务中,受相互学习(Zhang et al. 2018)的激励,我们首先考虑将标准相互学习(sML)纳入我们的框架的一种直接方式。我们将上述的特征提取器、情感分类器和领域判别器扩展为两组(模型)
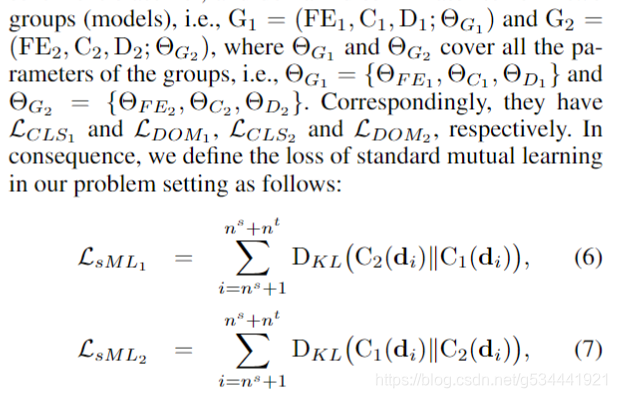

直观的是,由于参数初始化的不同,每个组中的特征抽取器和情感分类器在相互学习的指导下,试图获得一些不同的能力(例如,聚焦于潜在特征空间的某些特殊部分)来追求其同类群的相似结果。因此,他们可以将一些专有知识传递给同行。值得注意的是,式6和式7只是用另一组的预测标签来指导每个组,但没有告诉他们如何获得这些伪标签,因此并不强迫他们获得非常相似的特征表示。然而,将这些伪标签应用到无监督的域适应场景的方式是值得质疑的。这是因为要求两个分类器信任各自生成的伪标签(见Eq. 6和Eq. 7)在域适应方面有一点受限,在这种情况下,两个分类器实际上看不到目标域中的任何标记数据。因此,分类器可能不够强大,无法互相教导,这就导致他们被对方的预测误导,无法获得改进的分类性能(验证见图3)。为了避免降低分类性能,同时保留从目标域学习情绪极性的能力,我们在每一组中引入了另一个组合,称为标签检测器§,其结构与情绪分类器相同,但有自己的可学习参数。标签检验器的目标不是像情绪分类器那样进行情绪分类。每个探测仪探测目标域中另一组感知到的情绪信息,并将该知识传递给同一组的特征提取器,充当特征提取器与另一组的情绪分类器之间的桥梁。

Experiments
Experimental Setup
Datasets
我们采用多个不同来源的公开数据集来评估DAML。第一对源和目标数据集是Yelp和IMDB数据集。其中一个问题是Yelp有5个情感标签,而IMDB有10个。为了对齐用于领域适应的情绪标签空间,我们简单地将IMDB中情绪标签的分数除以2,然后四舍五入。
此外,为了研究同一来源的不同网络的效果,我们选择了三个领域,i.e., Electronics, CD, and Clothing, from the Amazondataset (McAuley et al. 2015)。
对于每个领域,训练集有80,000个文档,测试集和开发集都有10,000个文档。所有这些统计数据在表1中进行了详细总结。
Evaluation
在(Tang, Qin, and Liu2015b)的研究之后,我们的实验中模型的性能根据acc和rmse进行了比较,前者保证了分类性能,后者表明了预测评级和地面真实评级之间的差异。
对于无监督领域适应任务,目标领域开发集的不可用性导致两个问题。
首先,不可能根据每个目标域开发集的性能对每个任务的超参数进行调优,因此,正如(He等人2018年)所做的,我们建立了一个仅适用于onetask(Yelp→IMDB)的开发集。
其次,我们无法根据模型在目标域中的性能对其进行早期停止。作为一种选择,我们使用每个源域的开发集来确定早期停止。
具体来说,对于每个模型,当它在训练过程中在开发集上达到更好的效果时,我们会保存它的参数。最后将保存的性能最好的参数作为模型参数,在目标域上进行测试。本工作中所实验的模型均采用上述方法确定模型参数。对于每一种基于相互学习的方法,选择在源程序开发集上表现最好的分类器,并最终在目标域上进行评估。
Implementations
正如在特征提取部分中提到的,我们的方法使用HAN作为特征提取器,因为它的性能很好。为了进行公平的比较,我们也使用其他方法来使用HAN。尽管双向编码器表示来自变压器(BERT)(Devlin等人。2019)作为一个强大的文本特征提取器,我们在本地实验中没有找到比HAN更好的结果的合适设置。尽管来自双向编码Transformer(BERT)(Devlin等人,2019)表示作为一个强大的文本特征提取器,我们在本地实验中没有找到比HAN更好的结果的合适设置。在训练过程开始之前,Word2vec学习200维单词嵌入(Mikolov et al。2013年)。Word2vec在所有实验域中的所有可用数据上进行训练。所有域的超参数都是固定的。
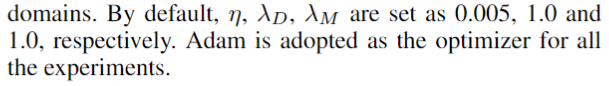
对于基线,如果它们的源代码可用,我们直接利用它们,只需调整输入和调整参数。否则,我们将参考他们论文中显示的设置来实现它们。对于基线,如果它们的源代码可用,我们直接利用它们,只需调整输入和调整参数。否则,我们将参考他们论文中显示的设置来实现它们。
Baselines
本文采用以下端到端域自适应传感器分类模型进行比较。
Naive
我们用一个由HAN实现的情感分类模型进行了实验,该模型没有任何领域自适应技术。它在源域上训练,然后在目标域上直接测试
DANN(Ganin et al. 2016)
引入对抗性判别器对不同域的数据进行区分,使特征提取器通过对鉴别器的干扰,最终生成域不变性的潜在特征向量。
MMD(Gretton et al. 2012a)
作为另一种常见的领域适应方法,MMD应用于特征提取器,使其与领域无关。主要将多尺度域适应的结果与对抗域适应的结果进行比较,以检验对抗域适应的有效性。
WDGRL(Shen et al. 2017)
这种方法与DANN相似,但使用Wasserstein距离而不是JS-divergence作为鉴别器的损失函数。
DAS(He et al. 2018)
该方法采用熵微化和自集成自举方法,在最小化域发散的前提下对分类器进行优化。
ACAN(Qu et al. 2019)
ACAN在特征提取器的顶部引入了两个分类器网络。两个分类器之间的差异被增加以提供不同的视图,同时提取器学习通过最小化这种差异来创建远离类别边界的更好的特征。
为了充分研究我们方法背后的机制,我们考虑以下变体。
Naive Ensemble (NE)
为了表明DAML在利用多个并行模型方面的良好性能,我们设计了一个朴素集成框架,该框架获取两个领域适应模型返回的概率,并将它们的附加情况作为其预测。
ML(Zhang et al. 2018)
如前一节所述,它是标准的交互学习与对抗性学习直接应用于我们的任务中。
Feature Alignment (FA)
该方法通过对每个输入文档的两个特征提取器输出之间的欧氏距离进行最小化,在潜在特征层水平上对两个分类模型进行排序。