写在前面
最近在做一个异常检测项目,采用LANL数据集进行实践,找到了一份基于LANL数据集和CERT数据集的异常检测实践源码。花了一些时间研究源代码,这里把研究的结果记录下来。
源代码
使用的源代码链接为:https://github.com/pnnl/safekit。基于这篇源代码有两篇异常检测论文,如果有兴趣的也可以去下载阅读。一篇是Recurrent Neural Network Language Models for Open Vocabulary Event-Level Cyber Anomaly Detection,另一篇是Deep Learning for Unsupervised Insider Threat Detection in Structured Cybersecurity Data Streams。
代码结构
代码结构如下:
|—data_examples 存放原始LANL和CERT数据集处理后得到的特征值数据
|—cert 存放cert处理后得到的特征
|—lanl 存放lanl处理后得到的特征
|—agg_feats 应该是对应DNN模型的特征
|—lm_feats 应该是对应LSTM模型的特征
|—docs 这部分目前还没看
|—examples 存放了几个DNN和LSTM的实践ipynb代码
|—dnn_agg.ipynb 基于LANL的DNN实践代码
|—LANL_LM_data.ipynb 对于LANL原始数据集的数据处理
|—simple_lm.ipynb 基于LANL的LSTM实践代码
|—safekit 存放特征提取,模型的代码等
|—features 对于两个数据集的特征提取代码
|—models 原始的dnn,孤立森林等算法的模型实现代码
|—test 基于两个数据集的LSTM和DNN实践测试代码
|—agg_test.py DNN实践代码
|—lanl_lm_tests.py LSTM实践代码
|—setup.py 用于配置代码环境,安装需要的包等
重要文件解读
examples文件夹
(1)dnn_agg.ipynb
首先是导入LANL数据集对应的特征json文件lanl_count_in_count_out_agg.json,然后得到事件计数特征值在特征向量中对应的起始位置index,用datastart_index表示。
dataspecs = json.load(open('../safekit/features/specs/agg/lanl_count_in_count_out_agg.json', 'r'))
datastart_index = dataspecs['counts']['index'][0]
我们来看一下lanl_count_in_count_out_agg.json文件中有些什么
num_features是特征向量的维度,也就是特征数目;time是发生的时间;user是用户标识,这里有30000个用户class类别;redteam是代表是否为redteam事件;counts中就是事件计数值。加起来就是137维的特征向量。
{
"num_features": 137,
"time": {
"index": [0],
"num_classes": 0,
"meta": 1,
"feature": 0,
"target": 0 },
"user": {
"index": [1],
"num_classes": 30000,
"meta": 1,
"feature": 0,
"target": 0 },
"redteam": {
"index": [2],
"num_classes": 0,
"meta": 1,
"feature": 0,
"target": 0 },
"counts": {
"index": [3,4,5,6,7,8,9,10,11,12,13,14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30,
31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47,
48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81,
82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98,
99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112,
113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126,
127, 128, 129, 130, 131, 132, 133, 134, 135, 136],
"num_classes": 0,
"meta": 0,
"feature": 1,
"target": 1 }
}
接下来是得到我们的数据,不过我没有找到begin_no_weekends2.txt这个文件。
data = OnlineBatcher('/home/hutch_research/data/lanl/agg_feats/begin_no_weekends2.txt', 256, skipheader=True)
之后是得到Tensorflow中要用的placeholder,也就是代码中的x。
feature_spec = make_feature_spec(dataspecs)
x, ph_dict = join_multivariate_inputs(feature_spec, dataspecs, embed_ratio, min_embed, max_e
之后将x代入dnn模型函数中得到一个h值,这个h值在后面用来计算loss损失值。在计算loss值的时候使用eyed_mvn_loss这个损失函数,这个损失函数其实就是我们熟知的对预测结果做平方误差(squared error)。得到的loss_matrix是一个loss矩阵,然后通过tf.reduce_sum得到loss向量,最后通过tf.reduce_mean得到最后的loss平均值,也就是loss。
h = dnn(x, layer_list)
loss_spec = make_loss_spec(dataspecs, eyed_mvn_loss)
loss_matrix = multivariate_loss(h, loss_spec, ph_dict)
loss_vector = tf.reduce_sum(loss_matrix, reduction_indices=1)
loss = tf.reduce_mean(loss_vector)
接下来定义一个write_results函数,来将每一个minibatch中的time,user,redteam,loss这些值写入到文件outfile中。
def write_results(data_dict, feat_loss, outfile):
for d, u, t, l in zip(data_dict['time'].flatten().tolist(),
data_dict['user'].tolist(),
data_dict['redteam'].flatten().tolist(),
feat_loss.flatten().tolist()):
outfile.write('%s %s %s %s\n' % (int(d), u, int(t), l))
接下来就是调用ModelRunner函数来将模型需要的学习率(learning_rate),优化器(optimizer)等都确定好, 前面已经确定好了loss损失值和ph_dict。eval_tensors中是我们在训练的时候需要获得的tensor值(这里不就是,最后我们要得到的loss损失值嘛)
# other args incl. learning rate, optimizer, decay rate...
model = ModelRunner(loss, ph_dict, learnrate=lr, opt='adam')
loss_feats = [triple[0] for triple in loss_spec]
# list of tensors we want to retrieve at each training step; can also add loss_matrix to this
eval_tensors = [loss, loss_vector]
现在来到最重要的训练环节。首先是定义一个训练停止的准则,通过EarlyStop函数来确定训练是否该结束了(结束包括:训练达到最大次数,loss值已经收敛等等)。data是我们前面得到的输入数据值,通过data.next_batch()不断的得到一个个的batch。while循环里面就是不断的迭代训练,model.eval是得到我们需要的loss值,model.train_step是进行训练。data_dict就是我们在计算图启动前要用的dict。这里还调用了前面定义的write_results来不断的将每次的结果写到outfile中(这里的写入文件是results文件)。这里还有一个print函数用来输出每一个batch的loss值(可以看到下面的输出相邻行的index之间是相差256,其实就是输出一个个的batch)check_error就是通过调用EarlyStop来不断判断是否该结束了。
 (2)LANL_LM_data.ipynb
(2)LANL_LM_data.ipynb
这个ipynb文件就是对LANL的原始数据集进行处理,得到我们后面训练需要的特征值。这部分的详细代码这里先不谈,以后再补充。
(3)simple_lm.ipynb
这个ipynb文件是基于LANL数据集的LSTM训练代码。基本结构和上面的dnn_agg.ipynb差不多。区别大概就是用到的输入数据(也就是特征值)的格式不同,LSTM使用的输入数据是lanl/char_feats/word_day_split/下的文件,对数据的处理也不同。得到的结果都一样,都是得到每一个batch对应的loss值。
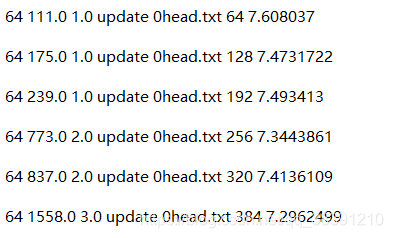
这部分也输出了每一个batch的结果,如下图所示。就拿第一行来说吧,64表示的是batch_size,111.0表示一个batch的line中的第一个值(因为一个batch中有64个data,因此只输出这次batch中的第一个),1.0表示一个batch的second中的第一个值,后面是update或者fixed(通过is_training来确定是fixed还是update),后面的0head.txt是目前使用的txt文档(有0head.txt,1head.txt,2head.txt这三个,按照顺序使用),后面的64就是目前的计数(第一行是64,第二行是128,中间差64,也就是一个batch_size),最后一个值7.608037是我们需要的最重要的值,那就是loss值。其实可以这样理解,前面的6个值都是输出一下这次batch的输入数据中的一些值,只有最后的loss值才是我们训练得到的。
test文件夹
前面的examples中只是一些示例代码,这里的test文件夹中的python文件才是我们测试要用的完整的代码。
agg_tests.py文件和lanl_lm_tests.py其实就是运行前面的一些python文件,进行训练得到结果。拿lanl_lm_tests.py文件来说,定义了一个datapath参数,用来放LSTM要用的特征值。定义了一个logfile参数,用来写入训练时候的一些log日志(可以在这个log文件中看训练的时候报的错误)。
# # ============================================================================
# # ================== SIMPLE LSTM =============================================
# # ============================================================================
with open(args.logfile, 'a') as log:
log.write('simple word forward lstm\n\n\n')
print('simple word forward lstm\n\n\n')
ok = os.system('python %s/simple_lm.py ./ %s/lm/lanl_word_config.json %sword_day_split/ -encoding word -skipsos -test -delimiter , 2>> %s' % (modelpath, specpath, args.datapath, args.logfile))
num_finished += ok == 0
all_okay += ok != 0
上面的这段代码其实就是实际运行的代码,os.system中就是实际每一个LSTM对应的运行命令,每次训练都需要确定modelpath, specpath, args.datapath, args.logfile这四个参数。前面的modelpath, specpath在lanl_lm_tests.py中前面已经定义好了,就差 args.datapath, args.logfile这两个参数,前面已经说了这两个参数的含义。所以我们在cmd中运行lanl_lm_tests.py这个文件的时候就需要输出args.datapath, args.logfile这两个参数,下面给出一个示例(示例来自Github源码中的readme),这个示例就是运行lanl_lm_tests.py代码,后面的data_examples/lanl/lm_feats/就是args.datapath参数,后面的test.log就是args.logfile参数。
python test/lanl_lm_tests.py data_examples/lanl/lm_feats/ test.log
模型实现
LSTM模型
LSTM模型的输入特征是每一行日志对应一行输入。data_examples/lanl/lm_feats下面有三个文件夹。表示以word作为分隔和以char作为分隔,特征向量的维度分别为12和122.
写在后面
还有一些这次没有解读的文件以后补充。。。