我们都知道MySQL底层实现借助了B+Tree的数据结构。那么这是为什么呢?下面我将以二叉树->红黑树->B树->B+树的顺序从数据结构的优劣来讲解为什么会有这样的选择。

索引存在的意义
索引的建立是为了提高MySQL的检索速度,而提高这个检索速度的方法无非就是将要检索的数据组成更加利于增删改查操作的结构,从而从时间和空间上进行优化。
二叉搜索树
利用什么结构来实现索引?我想很多人第一个想到的就是二叉搜索树。如下图。左边是数据表,这里为col2列添加索引,如右边所示使用二叉搜索树实现。树的每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针。
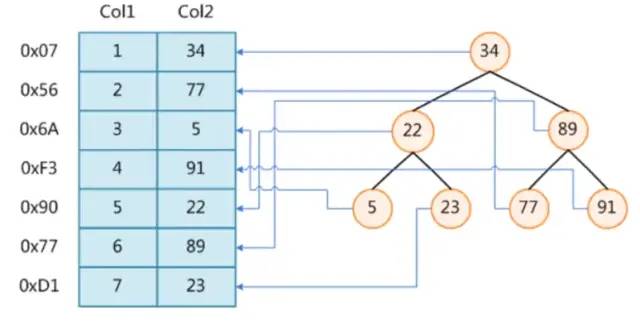
对于普通的二叉搜索树,时间复杂度是其树高,比如说要查找77,查找路径为34->89->77。这看起来是一个不错的想法,然而当树极度倾斜的情况下它却会退化成一个链表,可以想象一下对col1添加这种索引的效果。
红黑树
为了让搜索树的结构不退化为链表,并尽量的保持左右高度差较小,二叉平衡树便出现了,而红黑树就是一个“近似平衡”的二叉树。它通过某些策略保证了树高,从而使时间复杂度维持在O(logn)。
那为什么这个结构也没有入选呢?这个就要考虑到数据库本身的量级,当数据量很大时,如果将索引存储在内存中,虽然访问速度快,但是占用的内存会非常多。因此常把索引存在磁盘中,然而这样的话每次访问节点就是一次IO操作,树的高度就相当于操作磁盘的次数,因此优化的重点就放在了如何减少IO操作次数即减少树的高度上。
那么为了尽量的减少这个树高,一种想法就是让树“多分叉”,分叉越多,树的高度自然就会降低。
B树
而B树就是这样一个平衡且多叉的结构。他的每个节点不再只存储一个数据,而是存储多个,如下图(其中data存储键值对应行的地址)。
-
叶节点具有相同的深度,叶节点的指针为空
-
所有索引元素不相同
-
节点中的数据索引从左到右递增排列
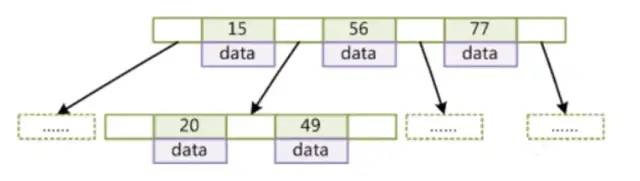
我们可以通过对节点中存储值数量的控制来控制整个树高。
至此,上面所说的“硬性”问题差不多都已经解决了,但是本着追求极致的态度,我们要想办法进一步进行优化。
B+树
B+树是在B树基础上的改进,如下图:
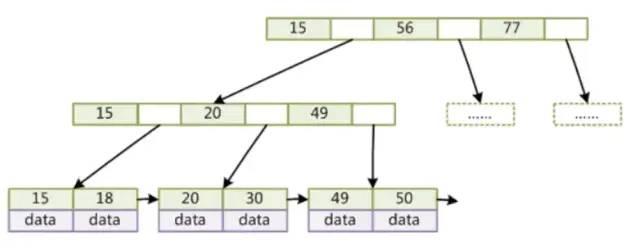
他的改变包括如下几点:
-
非叶子节点不存储data,只存储索引
我们想要每次加载进内存的节点尽可能的包含更多的索引,以使树的高度尽可能的低,但由于内存空间限制,节点中可放的内容也是有限制的,故B+树在B树的基础上去掉了data部分,以存储更多的索引。 -
叶子节点包含所有索引字段
上面造成的结果。 -
叶子节点用指针
如果没有叶子节点间的指针,当我们想要查找某个区间时,比如[20,50],我们需要先查询一遍20位置,再查询一遍49位置,才能把所有查询出来。叶子节点间指针的存在提高了区间访问效率。
顿悟ing
为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
-
整型:容易比较排序形成B+树
-
自增:每次在最后添加,避免B+树中间叶子节点再分裂导致的大量运算