光学字符识别(OCR)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
前几个月,猿妹曾和大家分享过一个热门的中文OCR项目———chineseocr_lite。这两天猿妹才知道,百度也开源了一款超轻量级中文OCR,总模型大小仅8.6M,只有chineseocr_lite,那真真是超轻量级别的神级OCR。
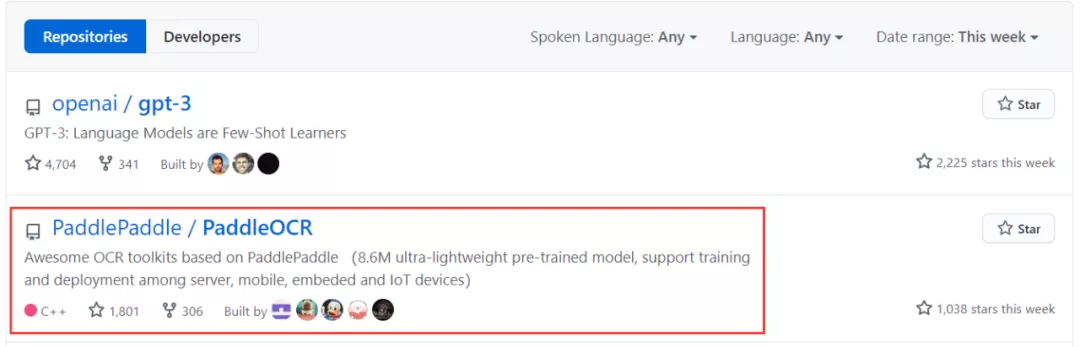
PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力使用者训练出更好的模型,支持iOS和Android系统,功能如此齐全,难怪霸榜Github热榜:
PaddleOCR具有以下特性:
- 超轻量级中文OCR模型,总模型仅8.6M
- 使用通用中文OCR模型
- 多种预测推理部署方案,包括服务部署和端侧部署
- 多种文本检测训练算法,EAST、DB
- 多种文本识别训练算法,Rosetta、CRNN、STAR-Net、RARE
- 可运行于Linux、Windows、MacOS等多种系统
说了这么多,还是一起来看看效果吧,先来看看通用中文OCR效果展示:

再来看看超轻量级中文OCR效果展示,无论是横排文字还是竖排文字,都是不在话下的,而且识别准确率相当高。

当然你要说他零失误那就有点夸张了,比如下面这一张,就出现了一个字识别错误:

支持空格的中文OCR效果展示

通用模型

除了丰富的功能,文档教程也是十分全面,不信你看:

有什么不懂的直接找文档准没错,不知道百度开源的这款神器你粉了么?
最后附上Github地址:https://github.com/PaddlePaddle/PaddleOCR