使用lxml的parse方法解析本地html时,提示如下错误:
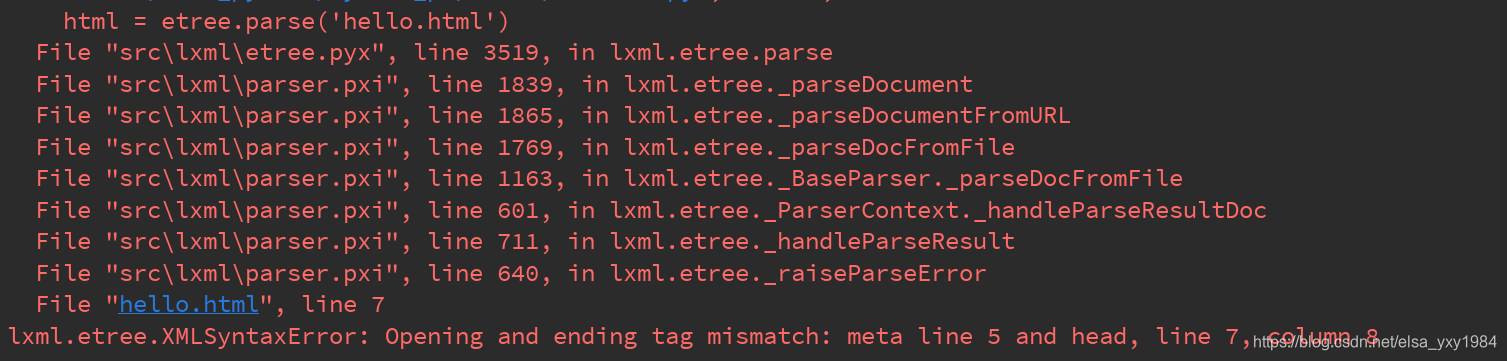
查了一下,应该是本地的html文件有错误,标签不匹配
本地html文件,内容见下图
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
hello,中国
</body>
</html>后来发现是<meta charset="UTF-8">这一行少了/符号
修改为:<meta charset="UTF-8"/>
执行就正确了。
看起来lxml的parse方法对html的格式要求非常严格啊
附上解析本地html的python代码
from lxml import html
etree = html.etree
# 获取本地html文档
html = etree.parse('hello.html')
result = etree.tostring(html, encoding='utf-8').decode()
print(result)注:文章内容主要是记录学习过程中遇到的问题以及解决方法。留个记录,同时分享给有需要的人。如有不足之处,欢迎指正,谢谢!