1. Redis学习
===========
0.1还原程序
0.1.1 修改YML配置文件

0.1.2 修改pro图片路径

0.1.3 修改Nginx配置文件

0.1.4 修改hosts文件

1.1 缓存机制
说明:使用缓存可以有效的降低用户访问物理设备的频次.快速从内存中获取数据,之后返回给用户,同时需要保证内存中的数据就是数据库数据.
思考:
1.缓存的运行环境应该在内存中.(快)
2.使用C语言开发缓存
3.缓存应该使用什么样的数据结构呢--------K-V结构 一般采用String类型居多 key必须唯一 . v:JSON格式
4.内存环境断电即擦除,所以应该将内存数据持久化(执行写盘操作)
5.如果没有维护内存的大小,则容易导致 内存数据溢出. 采用LRU算法优化!!!

1.2 Redis介绍
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
原子性说明: Redis的操作是单进程单线程操作,所以没有线程并发性的安全问题. 采用队列的方式一个一个操作.
Redis常见用法:
1.Redis可以当做缓存使用
2.Redis可以当做数据库使用 验证码
3.Redis可以消息中间件使用 银行转账等
1.3 Redis安装
1).解压 Redis安装包
`[root@localhost src]# tar -zxvf redis-5.0.4.tar.gz`
* 1

2). 安装Redis
说明:在Redis的根目录中执行命令
命令: 1.make
2.make install

1.4 修改Redis的配置文件
编辑redis.conf
1).命令 vim redis.conf
命令1: 展现行号 :set nu

修改位置1: 注释IP绑定

修改位置2: 关闭保护模式

修改位置3: 开启后台启动

1.5 redis 服务器命令
1.启动命令: redis-server redis.conf
2.检索命令: ps -ef | grep redis
3.进入客户端: redis-cli -p 6379
4.关闭redis: kill -9 PID号 | redis-cli -p 6379 shutdown

- Redis入门案例
=============
1.6 引入jar包文件
`<!--spring整合redis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
</dependency>`
1.7 编辑测试API
package com.jt.test;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;
public class TestRedis {
/**
* 1.测试redis程序链接是否正常
* 步骤:
* 1.实例化jedis工具API对象(host:port)
* 2.根据实例 操作redis 方法就是命令
*
* 关于链接不通的说明:
* 1.检查Linux防火墙
* 2.检查Redis配置文件修改项
* 2.1 IP绑定
* 2.2 保护模式
* 2.3 后台启动
* 3.检查redis启动方式 redis-server redis.conf
* 4.检查IP 端口 及redis是否启动...
*
* */
@Test
public void test01(){
String host = "192.168.126.129";
int port = 6379;
Jedis jedis = new Jedis(host,port);
jedis.set("cgb2006","好好学习 天天向上");
System.out.println(jedis.get("cgb2006"));
//2.练习是否存在key
if(jedis.exists("cgb2006")){
jedis.del("cgb2006");
}else{
jedis.set("cgb2006", "xxxx");
jedis.expire("cgb2006", 100);
}
}
}
总结:1.修改redis配置文件(vim redis.conf),修改三个地方;2.在window中idea导入架包;写test类;
- Redis入门案例
=============
1.1 Redis常见用法
1.1.1 setex学习
`/**
* 2.需求:
* 1.向redis中插入数据 k-v
* 2.为key设定超时时间 60秒后失效.
* 3.线程sleep 3秒
* 4.获取key的剩余的存活时间.
*
* 问题描述: 数据一定会被删除吗??????
* 问题说明: 如果使用redis 并且需要添加超时时间时 一般需要满足原子性要求.
* 原子性: 操作时要么成功 要么失败.但是必须同时完成.
*/
@Test
public void test02() throws InterruptedException {
Jedis jedis = new Jedis("192.168.126.129",6379);
jedis.setex("宝可梦", 60, "小火龙 妙蛙种子");
System.out.println(jedis.get("宝可梦"));
/* Jedis jedis = new Jedis("192.168.126.129",6379);
jedis.set("宝可梦", "小火龙 妙蛙种子");
int a = 1/0; //可能会出异常
jedis.expire("宝可梦", 60);
Thread.sleep(3000);
System.out.println(jedis.ttl("宝可梦"));*/
}`
1.1.2 setnx
`/**
* 3.需求如果发现key已经存在时 不修改数据.如果key不存在时才会修改数据.
*
*/
@Test
public void test03() throws InterruptedException {
Jedis jedis = new Jedis("192.168.126.129", 6379);
jedis.setnx("aaaa", "测试nx的方法");
/*if(jedis.exists("aaa")){
System.out.println("key已经存在 不做修改");
}else {
jedis.set("aaa", "测试数据");
}*/
System.out.println(jedis.get("aaaa"));
}`
1.1.3 set 超时时间原子性操作
`/**
* 需求:
* 1.要求用户赋值时,如果数据存在则不赋值. setnx
* 2.要求在赋值操作时,必须设定超时的时间 并且要求满足原子性 setex
*/
@Test
public void test04() throws InterruptedException {
Jedis jedis = new Jedis("192.168.126.129", 6379);
SetParams setParams = new SetParams();
setParams.nx().ex(20);
jedis.set("bbbb", "实现业务操作AAAA", setParams);
System.out.println(jedis.get("bbbb"));
}`
1.1.4 list集合练习
`@Test
public void testList() throws InterruptedException {
Jedis jedis = new Jedis("192.168.126.129", 6379);
jedis.lpush("list", "1","2","3");
System.out.println(jedis.rpop("list"));
}`
1.1.5 redis事务控制
`@Test
public void testTx() throws InterruptedException {
Jedis jedis = new Jedis("192.168.126.129", 6379);
//1.开启事务
Transaction transaction = jedis.multi();
try {
transaction.set("aa", "aa");
//提交事务
transaction.exec();
}catch (Exception e){
e.printStackTrace();
//回滚事务
transaction.discard();
}
}`
2.秒杀业务逻辑—分布式锁机制
6988 —1块 1部手机 20显示抢购成功 并且支付了1块钱…
问题:
1.tomcat服务器有多台
2.数据库数据只有1份
3.必然会出现高并发的现象.
如何实现抢购…
2.1常规锁操作
2.1.1 超卖的原因

2.1.2 同步锁的问题
说明:同步锁只能解决tomcat内部的问题,不能解决多个tomcat并发问题

2.1.3 分布式锁机制
思想:
1.锁应该使用第三方操作 ,锁应该公用.
2.原则:如果锁被人正在使用时,其他的用户不能操作.
3.策略: 用户向redis中保存一个key,如果redis中有key表示有人正在使用这把锁 其他用户不允许操作.如果redis中没有key ,则表示我可以使用这把锁.
4.风险: 如何解决死锁问题. 设定超时时间.

- SpringBoot整合Redis
=====================
3.1 编辑配置文件 redis.pro
说明:由于该配置被其他的项目共同使用,则应该写到jt-common中.

3.2 编辑配置类
说明: 编辑redis配置类.将Jedis对象交给Spring容器进行管理.
`@Configuration
@PropertySource("classpath:/properties/redis.properties")
public class JedisConfig {
@Value("${redis.host}")
private String host;
@Value("${redis.port}")
private Integer port;
@Bean
public Jedis jedis(){
return new Jedis(host,port);
}
}`
3.3 对象与JSON转化 ObjectMapper介绍
3.3.1 简单对象转化
`/**
* 测试简单对象的转化
*/
@Test
public void test01() throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
ItemDesc itemDesc = new ItemDesc();
itemDesc.setItemId(100L).setItemDesc("商品详情信息")
.setCreated(new Date()).setUpdated(new Date());
//对象转化为json
String json = objectMapper.writeValueAsString(itemDesc);
System.out.println(json);
//json转化为对象
ItemDesc itemDesc2 = objectMapper.readValue(json, ItemDesc.class);
System.out.println(itemDesc2.getItemDesc());
}`
3.3.2 集合对象转化
`/**
* 测试集合对象的转化
*/
@Test
public void test02() throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
ItemDesc itemDesc = new ItemDesc();
itemDesc.setItemId(100L).setItemDesc("商品详情信息1")
.setCreated(new Date()).setUpdated(new Date());
ItemDesc itemDesc2 = new ItemDesc();
itemDesc2.setItemId(100L).setItemDesc("商品详情信息2")
.setCreated(new Date()).setUpdated(new Date());
List<ItemDesc> lists = new ArrayList<>();
lists.add(itemDesc);
lists.add(itemDesc2);
//[{key:value},{}]
String json = objectMapper.writeValueAsString(lists);
System.out.println(json);
//将json串转化为对象
List<ItemDesc> list2 = objectMapper.readValue(json, lists.getClass());
System.out.println(list2);
}`
3.4 编辑工具API
`package com.jt.util;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.jt.pojo.ItemDesc;
import org.springframework.util.StringUtils;
public class ObjectMapperUtil {
/**
* 1.将用户传递的数据转化为json串
* 2.将用户传递的json串转化为对象
*/
private static final ObjectMapper MAPPER = new ObjectMapper();
//1.将用户传递的数据转化为json串
public static String toJSON(Object object){
if(object == null) {
throw new RuntimeException("传递的数据为null.请检查");
}
try {
String json = MAPPER.writeValueAsString(object);
return json;
} catch (JsonProcessingException e) {
//将检查异常,转化为运行时异常
e.printStackTrace();
throw new RuntimeException(e);
}
}
//需求: 要求用户传递什么样的类型,我返回什么样的对象 泛型的知识
public static <T> T toObj(String json,Class<T> target){
if(StringUtils.isEmpty(json) || target ==null){
throw new RuntimeException("参数不能为null");
}
try {
return MAPPER.readValue(json, target);
} catch (JsonProcessingException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}`
3.5 商品分类的缓存实现
3.5.1 实现步骤
1.定义Redis中的key key必须唯一不能重复. 存 取 key = “ITEM_CAT_PARENTID::70”
2.根据key 去redis中进行查询 有数据 没有数据
3.没有数据 则查询数据库获取记录 之后将数据保存到redis中 方便后续使用.
4.有数据 表示用户不是第一次查询 可以将缓存数据直接返回即可.
3.5.2 编辑ItemCatController

3.5.3 编辑ItemCatService
`@Override
public List<EasyUITree> findItemCatListCache(Long parentId) {
//0.定义公共的返回值对象
List<EasyUITree> treeList = new ArrayList<>();
//1.定义key
String key = "ITEM_CAT_PARENTID::"+parentId;
//2.检索redis服务器,是否含有该key
//记录时间
Long startTime = System.currentTimeMillis();
if(jedis.exists(key)){
//数据存在
String json = jedis.get(key);
Long endTime = System.currentTimeMillis();
//需要将json串转化为对象
treeList = ObjectMapperUtil.toObj(json,treeList.getClass());
System.out.println("从redis中获取数据 耗时:"+(endTime-startTime)+"毫秒");
}else{
//3.数据不存在 查询数据库
treeList = findItemCatList(parentId);
Long endTime = System.currentTimeMillis();
//3.将数据保存到缓存中
String json = ObjectMapperUtil.toJSON(treeList);
jedis.set(key, json);
System.out.println("查询数据库 耗时:"+(endTime-startTime)+"毫秒");
}
return treeList;
}`
3.5.4 使用Redis的速度差
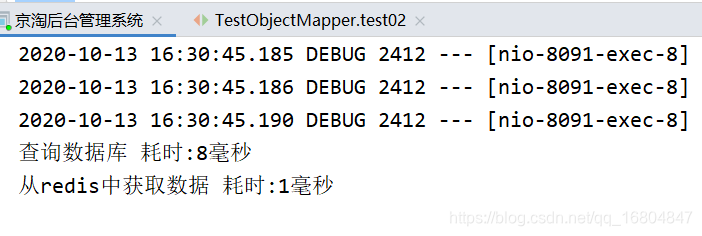
- AOP实现Redis缓存
================
4.1 如何理解AOP
名称: 面向切面编程
作用: 降低系统中代码的耦合性,并且在不改变原有代码的条件下对原有的方法进行功能的扩展.
公式: AOP = 切入点表达式 + 通知方法
4.2 通知类型
1.前置通知 目标方法执行之前执行
2.后置通知 目标方法执行之后执行
3.异常通知 目标方法执行过程中抛出异常时执行
4.最终通知 无论什么时候都要执行的通知
特点: 上述的四大通知类型 不能干预目标方法是否执行.一般用来做程序运行状态的记录.监控
5.环绕通知 在目标方法执行前后都要执行的通知方法 该方法可以控制目标方法是否运行.joinPoint.proceed(); 功能作为强大的.
4.3 切入点表达式
理解: 切入点表达式就是一个程序是否进入通知的一个判断(IF)
作用: 当程序运行过程中 ,**满足了切入点表达式时才会去执行通知方法,**实现业务的扩展.
种类(写法):
- bean(bean的名称 bean的ID) 只能拦截具体的某个bean对象 只能匹配一个对象
lg: bean(“itemServiceImpl”) - within(包名.类名) within(“com.jt.service.*”) 可以匹配多个对象
粗粒度的匹配原则 按类匹配
3. execution(返回值类型 包名.类名.方法名(参数列表)) 最为强大的用法
lg : execution(* com.jt.service..*.*(..))
返回值类型任意 com.jt.service包下的所有的类的所有的方法都会被拦截.
4.@annotation(包名.注解名称) 按照注解匹配.
总结:1.setex是实现原子型的方法;2.setnx是实现果发现key已经存在时 不修改数据.如果key不存在时才会修改数据.3.SetParams setParams = new SetParams();可以调用setex和setnx来实现原子性;4.redis事务控制+list集合练习;5.同步锁只能适用于单个tomcat服务器的操作,所以要通过分布式锁机制;6.因为redis是c语言编辑,我在操作Java代码,可以将对象转化为Json格式,创建工具API;编辑controller和业务层;7.利用AOP实现redis缓存;
4.4 AOP入门案例
`package com.jt.aop;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.*;
import org.springframework.stereotype.Component;
import org.springframework.stereotype.Service;
import java.util.Arrays;
@Aspect //我是一个AOP切面类
@Component //将类交给spring容器管理
public class CacheAOP {
//公式 = 切入点表达式 + 通知方法
/**
* 关于切入点表达式的使用说明
* 粗粒度:
* 1.bean(bean的Id) 一个类
* 2.within(包名.类名) 多个类
* 细粒度
*/
//@Pointcut("bean(itemCatServiceImpl)")
//@Pointcut("within(com.jt.service..*)") //匹配多级目录
@Pointcut("execution(* com.jt.service..*.*(..))") //方法参数级别
public void pointCut(){
//定义切入点表达式 只为了占位
}
//区别: pointCut() 表示切入点表达式的引用 适用于多个通知 共用切入点的情况
// @Before("bean(itemCatServiceImpl)") 适用于单个通知.不需要复用的
// 定义前置通知,与切入点表达式进行绑定. 注意绑定的是方法
/**
* 需求:获取目标对象的相关信息.
* 1.获取目标方法的路径 包名.类名.方法名
* 2.获取目标方法的类型 class
* 3.获取传递的参数
* 4.记录当前的执行时间
*/
@Before("pointCut()")
//@Before("bean(itemCatServiceImpl)")
public void before(JoinPoint joinPoint){
String className = joinPoint.getSignature().getDeclaringTypeName();
String methodName = joinPoint.getSignature().getName();
Class targetClass = joinPoint.getTarget().getClass();
Object[] args = joinPoint.getArgs();
Long runTime = System.currentTimeMillis();
System.out.println("方法路径:" +className+"."+methodName);
System.out.println("目标对象类型:" + targetClass);
System.out.println("参数:" + Arrays.toString(args));
System.out.println("执行时间:" + runTime+"毫秒");
}
/* @AfterReturning("pointCut()")
public void afterReturn(){
System.out.println("我是后置通知");
}
@After("pointCut()")
public void after(){
System.out.println("我是最终通知");
}*/
/**
* 环绕通知说明
* 注意事项:
* 1.环绕通知中必须添加参数ProceedingJoinPoint
* 2.ProceedingJoinPoint只能环绕通知使用
* 3.ProceedingJoinPoint如果当做参数 则必须位于参数的第一位
*/
@Around("pointCut()")
public Object around(ProceedingJoinPoint joinPoint){
System.out.println("环绕通知开始!!!");
Object result = null;
try {
result = joinPoint.proceed(); //执行下一个通知或者目标方法
} catch (Throwable throwable) {
throwable.printStackTrace();
}
System.out.println("环绕通知结束");
return result;
}
}
2 关于AOP实现Redis缓存
2.1 自定义缓存注解
问题: 如何控制 哪些方法需要使用缓存? cacheFind()
解决方案: 采用自定义注解的形式 进行定义,如果 方法执行需要使用缓存,则标识注解即可.
关于注解的说明:
1.注解名称 : cacheFind
2.属性参数 :
2.1 key: 应该由用户自己手动添加 一般添加业务名称 之后动态拼接形成唯一的key
2.2 seconds: 用户可以指定数据的超时的时间
`@Target(ElementType.METHOD) //注解对方法有效
@Retention(RetentionPolicy.RUNTIME) //运行期有效
public @interface CacheFind {
public String preKey(); //用户标识key的前缀.
public int seconds() default 0; //如果用户不写表示不需要超时. 如果写了以用户为准.
}

2.2 编辑CacheAOP
package com.jt.aop;
import com.jt.anno.CacheFind;
import com.jt.config.JedisConfig;
import com.jt.util.ObjectMapperUtil;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.*;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.stereotype.Service;
import redis.clients.jedis.Jedis;
import java.lang.reflect.Method;
import java.util.Arrays;
@Aspect //我是一个AOP切面类
@Component //将类交给spring容器管理
public class CacheAOP {
@Autowired
private Jedis jedis;
/**
* 切面 = 切入点 + 通知方法
* 注解相关 + 环绕通知 控制目标方法是否执行
*
* 难点:
* 1.如何获取注解对象
* 2.动态生成key prekey + 用户参数数组
* 3.如何获取方法的返回值类型
*/
@Around("@annotation(cacheFind)")
public Object around(ProceedingJoinPoint joinPoint,CacheFind cacheFind){
Object result = null;
try {
//1.拼接redis存储数据的key
Object[] args = joinPoint.getArgs();
String key = cacheFind.preKey() +"::" + Arrays.toString(args);
//2. 查询redis 之后判断是否有数据
if(jedis.exists(key)){
//redis中有记录,无需执行目标方法
String json = jedis.get(key);
//动态获取方法的返回值类型 向上造型 向下造型
MethodSignature methodSignature = (MethodSignature) joinPoint.getSignature();
Class returnType = methodSignature.getReturnType();
result = ObjectMapperUtil.toObj(json,returnType);
System.out.println("AOP查询redis缓存");
}else{
//表示数据不存在,需要查询数据库
result = joinPoint.proceed(); //执行目标方法及通知
//将查询的结果保存到redis中去
String json = ObjectMapperUtil.toJSON(result);
//判断数据是否需要超时时间
if(cacheFind.seconds()>0){
jedis.setex(key,cacheFind.seconds(),json);
}else {
jedis.set(key, json);
}
System.out.println("aop执行目标方法查询数据库");
}
} catch (Throwable throwable) {
throwable.printStackTrace();
}
return result;
}
}
总结:AOP实现:1.安装redis,修改redis配置,window里面导入架包;2.编辑公共的common配置文件,并创建配置类(提取host和port);3.创建API工具类(将用户传递的数据转化为json串,将用户传递的json串转化为对象);4.商品分类的实现缓存(编辑controller,service,serviceimpl类);5.开始用AOP 实现缓存策略:创建cacheFind注解类;6.把注解放在指定的查询方法上面(把之前更改过的三个方法的名字更改过来,重新来操作);7.创建CacheAOP类,利用切面实现redis缓存;
3 关于Redis 配置说明
3.1 关于Redis持久化的说明
redis默认条件下支持数据的持久化操作. 当redis中有数据时会定期将数据保存到磁盘中.当Redis服务器重启时 会根据配置文件读取指定的持久化文件.实现内存数据的恢复.
3.2持久化方式介绍
3.2.1 RDB模式
特点:
1.RDB模式是redis的默认的持久化策略.
2.RDB模式记录的是Redis 内存数据的快照. 最新的快照会覆盖之前的内容 所有RDB持久化文件占用空间更小 持久化的效率更高.
3.RDB模式由于是定期持久化 所以可能导致数据的丢失.
命令:
- save 要求立即马上持久化 同步的操作 其他的redis操作会陷入阻塞的状态.
- bgsave 开启后台运行 异步的操作 由于是异步操作,所以无法保证rdb文件一定是最新的需要等待.
配置:
1.持久化文件名称:

2.持久化文件位置
dir ./ 相对路径的写法
dir /usr/local/src/redis 绝对路径写法

3.RDB模式持久化策略

3.2.2 AOF模式
特点:
1.AOF模式默认条件下是关闭的,需要用户手动的开启

2. AOF模式是异步的操作 记录的是用户的操作的过程 可以防止用户的数据丢失
3. 由于AOF模式记录的是程序的运行状态 所以持久化文件相对较大,恢复数据的时间长.需要人为的优化持久化文件
配置:

3.2.2 关于持久化操作的总结
1.如果不允许数据丢失 使用AOF方式
2.如果追求效率 运行少量数据丢失 采用RDB模式
3.如果既要保证效率 又要保证数据 则应该配置redis的集群 主机使用RDB 从机使用AOF
3.3 关于Redis内存策略
3.3.1 关于内存策略的说明
说明:Redis数据的存储都在内存中.如果一直想内存中存储数据 必然会导致内存数据的溢出.
解决方式:
- 尽可能为保存在redis中的数据添加超时时间.
- 利用算法优化旧的数据.
3.3.2 LRU算法
特点: 最好用的内存优化算法.
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
维度: 时间 T
3.3.3 LFU算法
LFU(least frequently used (LFU) page-replacement algorithm)。即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
维度: 使用次数
3.3.4 RANDOM算法
随机删除数据
3.3.5 TTL算法
把设定了超时时间的数据将要移除的提前删除的算法.
3.3.6 Redis内存数据优化
- volatile-lru 设定了超时时间的数据采用lru算法
2.allkeys-lru 所有的数据采用LRU算法
3.volatile-lfu 设定了超时时间的数据采用lfu算法删除
4.allkeys-lfu 所有数据采用lfu算法删除
5.volatile-random 设定超时时间的数据采用随机算法
6.allkeys-random 所有数据的随机算法
7.volatile-ttl 设定超时时间的数据的TTL算法
8.noeviction 如果内存溢出了 则报错返回. 不做任何操作. 默认值

4 关于Redis 缓存面试题
问题描述: 由于海量的用户的请求 如果这时redis服务器出现问题 则可能导致整个系统崩溃.
运行速度:
- tomcat服务器 150-250 之间 JVM调优 1000/秒
- NGINX 3-5万/秒
- REDIS 读 11.2万/秒 写 8.6万/秒 平均 10万/秒
4.1 缓存穿透
问题描述: 由于用户高并发环境下访问 数据库中不存在的数据时 ,容易导致缓存穿透.
如何解决: 设定IP限流的操作 nginx中 或者微软服务机制 API网关实现.
4.2 缓存击穿
问题描述: 由于用户高并发环境下, 由于某个数据之前存在于内存中,但是由于特殊原因(数据超时/数据意外删除)导致redis缓存失效. 而使大量的用户的请求直接访问数据库.
俗语: 趁他病 要他命
如何解决:
1.设定超时时间时 不要设定相同的时间.
2.设定多级缓存

4.3 缓存雪崩
说明: 由于高并发条件下 有大量的数据失效.导致redis的命中率太低.而使得用户直接访问数据库(服务器)导致奔溃,称之为缓存雪崩.
解决方案:
1.不要设定相同的超时时间 随机数
2.设定多级缓存.
3.提高redis缓存的命中率 调整redis内存优化策略 采用LRU等算法.
