1. keras官网介绍
目前keras已被tensorflow收购,keras在和tensorflow进行融合后,速度明显提升。tensorflow推出2版本后大推keras,因此,建议使用tensorflow版的keras。以下为tensorflow官网keras的结构:
本节主要讲述Input和Model
2. Input
一般Input需要搭配Model使用。使用Input和Model是keras搭建网络结构的方式之一。(keras搭建网络结构一共有三种方式,Input、Model为其中一个)。
以下为网络搭配的案例:
# this is a logistic regression in Keras
x = Input(shape=(32,)) # Input需要指明输入的shape,一般不需要写batch
y = Dense(16, activation='softmax')(x) # 全连接层
model = Model(x, y) # 使用Model,传入输入的x和最后的输出y
下面再来看一个复杂的案例
def bi_lstm(max_len, max_cnt, embed_size, embedding_matrix):
_input = Input(shape=(max_len,), dtype='int32') # 规定输入的shape,max_len为nlp中一句话中词语的个数
_embed = Embedding(max_cnt, embed_size, input_length=max_len, weights=[embedding_matrix], trainable=False)(_input) # embedding层:加载预训练的词向量矩阵作为权重,max_cnt语料库词的总数,embed_size词向量维度
_embed = SpatialDropout1D(0.1)(_embed) # 词向量专用dropout
lstm_result = Bidirectional(CuDNNLSTM(100, return_sequences=False), merge_mode='sum')(_embed) # 双向lstm层,CuDNNLSTM本质还是lstm,只不过是gpu版本,速度提升特别快,但是准确率会有所下降
fc = Dropout(0.1)(lstm_result) # drop
fc = Dense(13)(fc) # 全连接层
preds = Activation('softmax')(fc) # softmax层,获得每个类别的概率值
model = Model(inputs=_input, outputs=preds) # 使用Model,传入输入的_input和最后的输出preds
return model
# 直接调用函数,就可得到model
model = bi_lstm(max_len, max_cnt, embed_size, embedding_matrix)
# 定义好损失函数等就可以使用model.fit进行模型的拟合了
Input除了上述用到的shape参数外,还有很多其他参数,具体见下:

以下是官网提供的可能错误:

一般我们需要指定shape,因为模型要想复用,tensor不可能是固定的。
3. Model
3.1 与Input搭配使用
具体详见上一章,当input有多个,可以使用列表,如下:
model = Model(input=[a, b], output=c)
3.2 继承Model创建网络结构
这是keras构建网络结构的第二种方式,和pytroch类似,以下为案例解析
import tensorflow as tf
class MyModel(tf.keras.Model): # 继承Model
def __init__(self): # 在__init__中定义图层
super(MyModel, self).__init__()
self.dense1 = tf.keras.layers.Dense(4, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(5, activation=tf.nn.softmax)
def call(self, inputs): # 类似于pytroch的forward,实现前向调用
x = self.dense1(inputs)
return self.dense2(x)
model = MyModel() # 实例化
如果使用该方法,也可以在call中指定training参数(True or False),来决定训练和预测的不同行为
import tensorflow as tf
class MyModel(tf.keras.Model):
def __init__(self):
super(MyModel, self).__init__()
self.dense1 = tf.keras.layers.Dense(4, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(5, activation=tf.nn.softmax)
self.dropout = tf.keras.layers.Dropout(0.5)
def call(self, inputs, training=False):
x = self.dense1(inputs)
if training:
x = self.dropout(x, training=training)
return self.dense2(x)
model = MyModel()
本案例中如果是训练,就使用dropout,预测不使用。实际上不加if training下面的代码,模型也只是在训练时使用dropout,预测时未使用。在此只是举一个简单的例子。
3.3 方法
接3.2第一个案例的代码(构建模型)。keras中,深度模型的完整流程如下:
model = MyModel() # 实例化,MyModel负责搭建网络结构
model.compile() # 编译,在此需要指定损失函数,优化器
model.fit() # 模型的拟合(训练集)
model.evaluate() # 模型的评估(验证集)
model.predict() # 模型的预测(测试集)
因此Model继承后实例化后的model具有以下方法:
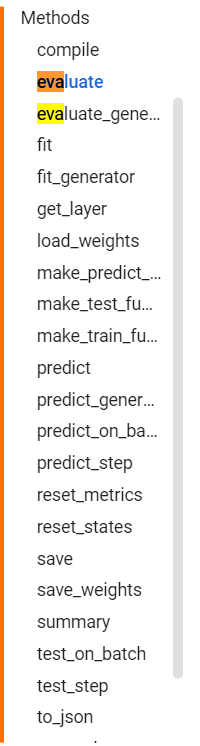

3.3.1 compile
compile就是编译的意思,在这里需要指定优化器,损失函数等,具体参数见下: