1. 什么是kafka
1.1 基本概述
提前说明,以下主要涉及kafka、topic、partition、broker、offset、replica、leader、follower、Consumer Group等概念
首先kafka是用来存储数据的,就像sql等数据库一样。
向kafka中放数据的人叫做生产者(Producer),从kafka取数据的人叫做消费者。(Consumer )
打个比方,假设kafka就是一张excel工作簿。最开始这个工作簿(数据库)是没有数据的,需要有人在excel工作簿里填写数据,这个填写excel工作簿的人就是生产者。当生产者填好数据后,需要给别人看,那么看这张数据表,从而获取数据(比如复制数据到自己的电脑)的那个人就是生产者。
为了将数据进行分类,如有的数据是支出,有的是收入,kafka引进topic的概念。一个topic就像一个excel工作薄(数据库)中的一张工作表(如收入表)
还是假设把kafka数据库假设成一张excel表,如下图收入表:
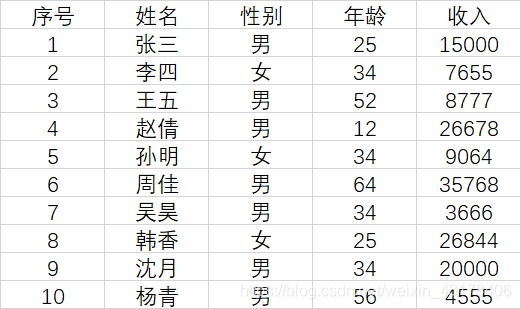
现在我将表中的数据分成2部分,前5条数据为第一部分,称为partition0,后五条为第二部分,称为partition1
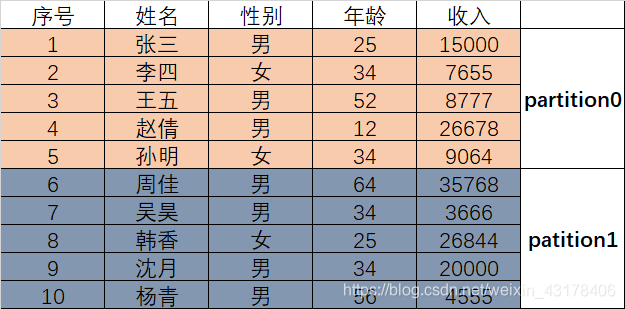
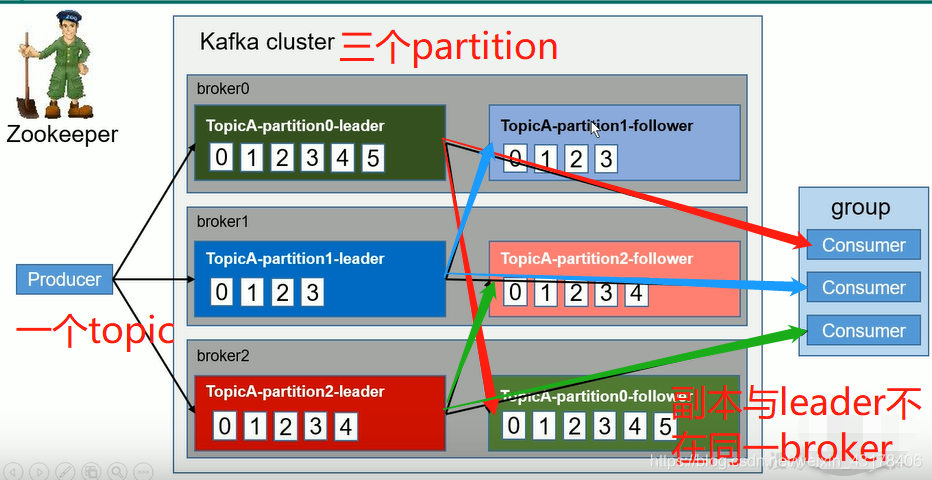
在kafka中,对于一个topic的数据,会切分成不同的partition(不同部分),一般一个partition的数据会放到一台服务器上(如果服务器的个数少于partition的个数,一台服务器可能放多个partition),因此部署kafka需要多台服务器,一般至少需要三台。当然服务器数量不够,一台也是可以的。每一台服务器都叫做一个broker,全部服务器的集合叫做kafka 集群(kafka cluster)。ps:一台服务器(broker)可以容纳多个topic
一个topic的每个partition内部的数据是有序的,但是partition间的数据是无序的,如果想要保证所有数据的有序性,可以将partition的个数设成1。
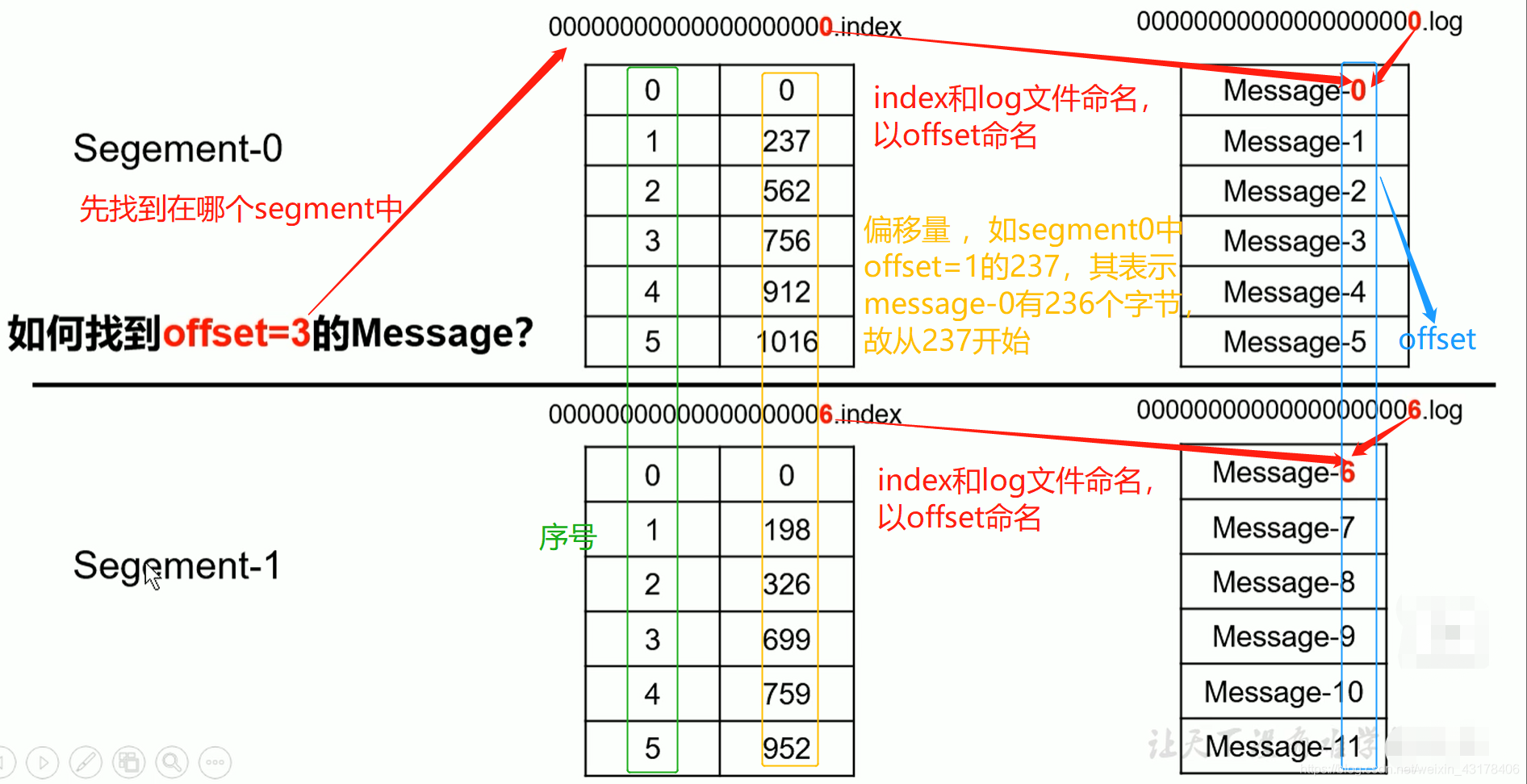
kafka中每个partition的每条数据都有一个offset,用来标识该条数据开始的位置,如下图所示:
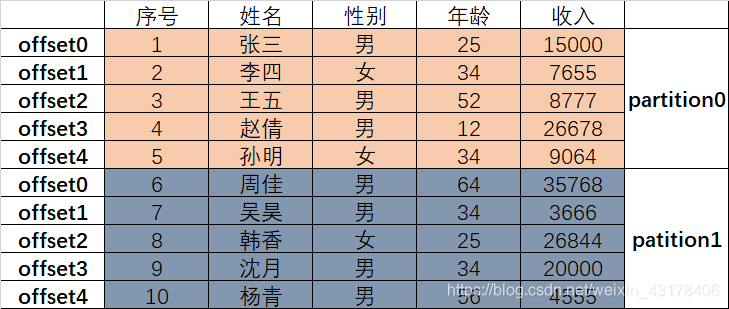
为了防止数据丢失,每个partition都有多个副本(replica)。每个副本放到一台服务器上。
在一个partition的多个副本中,有一个是leader,负责数据的读写,其余为follower,主要作用是备份
kafka中的数据可以供多个消费者消费,如果多个消费者在一个消费者组里,那么这个消费者组的多个消费者只能消费不同的数据,不能消费同一份数据。
kafka的数据结构图如下图所示:
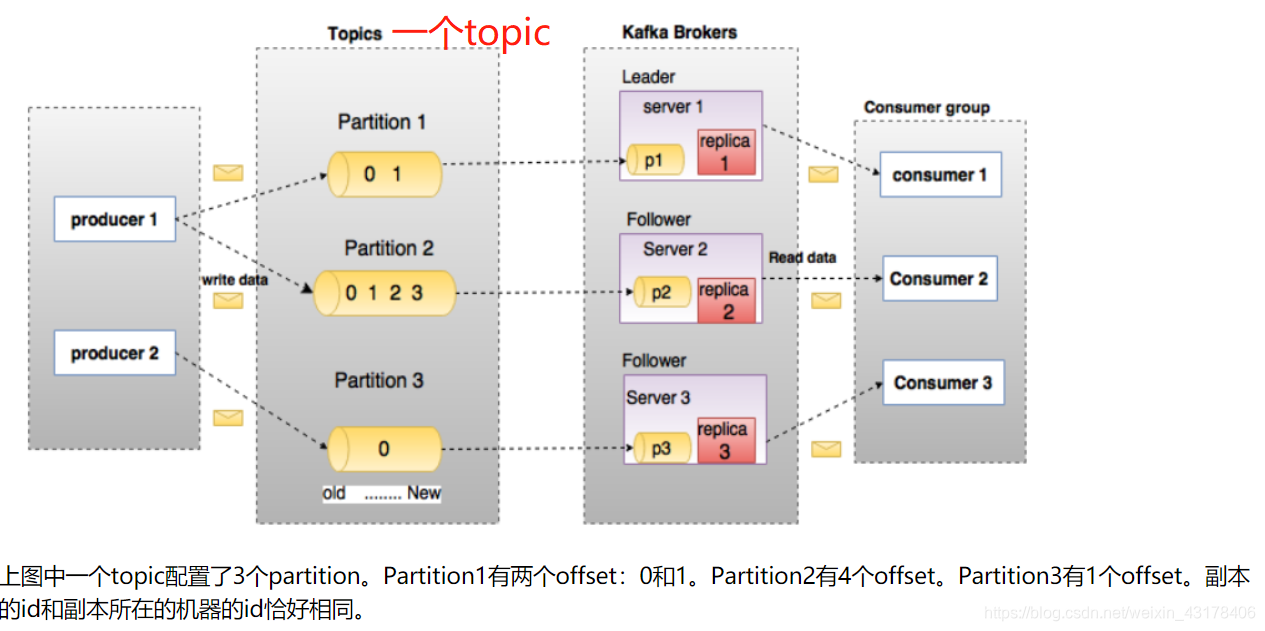
消息的流程如下图:
此外,kafka中还有一个zookeeper:

上述各个broker是分布式的,因此Zookeeper负责维护和协调broker。当Kafka系统中新增了broker或者某个broker发生故障失效时,由ZooKeeper通知生产者和消费者。生产者和消费者依据Zookeeper的broker状态信息与broker协调数据的发布和订阅任务。consumer的offset(这里的offset是指消费者消费到哪条数据了)存储在Zookeeper中。
1.2 深度讲解
- partiton数据存储
上述讲了topic、partition,但是每个 partition是如何存储数据呢?如下图所示:
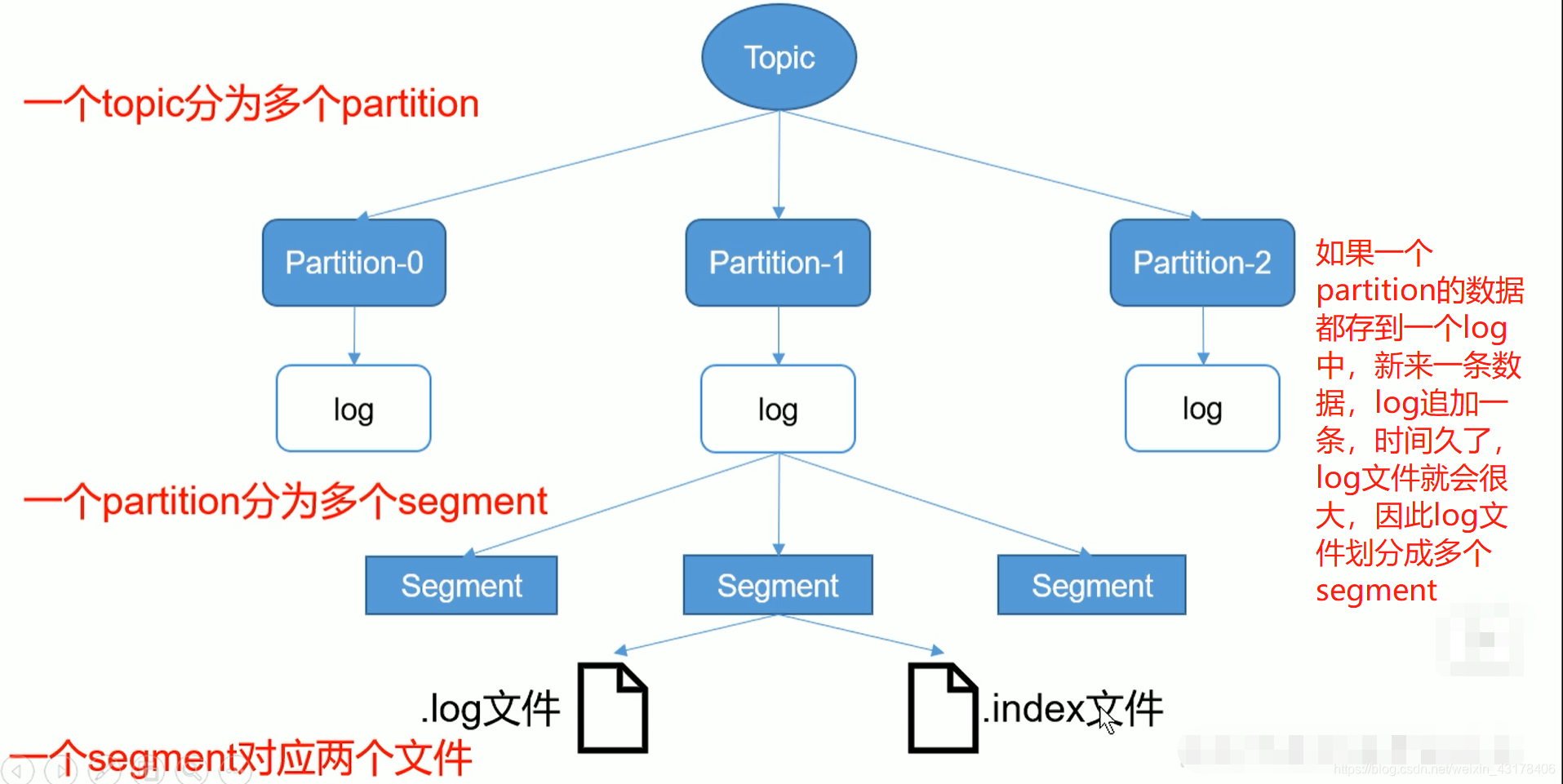
注意,partition虽然有多个segment,但是这多个segment的offset肯定都不同,因为这多个segment都属于一个partition,kafka中,一个partition的每条数据都有不同的offset(一般从0开始)
下图是.log文件和.index文件的数据存储方式:
- 分区原则
当生产者同时生产多条数据时,多条数据需要存到不同的partition下,kafka可以通过指定key和partition的方式进行分区,具体如下:
- 在没有说明partition和key时,kafka采用round-robin算法随机分区,即第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与tipic可用的partition总数取余得到partition值(存放数据的partition)
- 指明partition的情况下,直接将指明的值最为partition值
- 没有指定partition,但指明了key ,将key的hash值与topic的 partition总数进行取余得到partition值(存放数据的partition)
在java中,需要将生产者发送的数据封装成一个ProducerRecord对象,其中有一个value参数,即向kafak中存放的数据。
- acks
acks就是
2. kafka的安全机制
目前,kafka有四种安全机制:
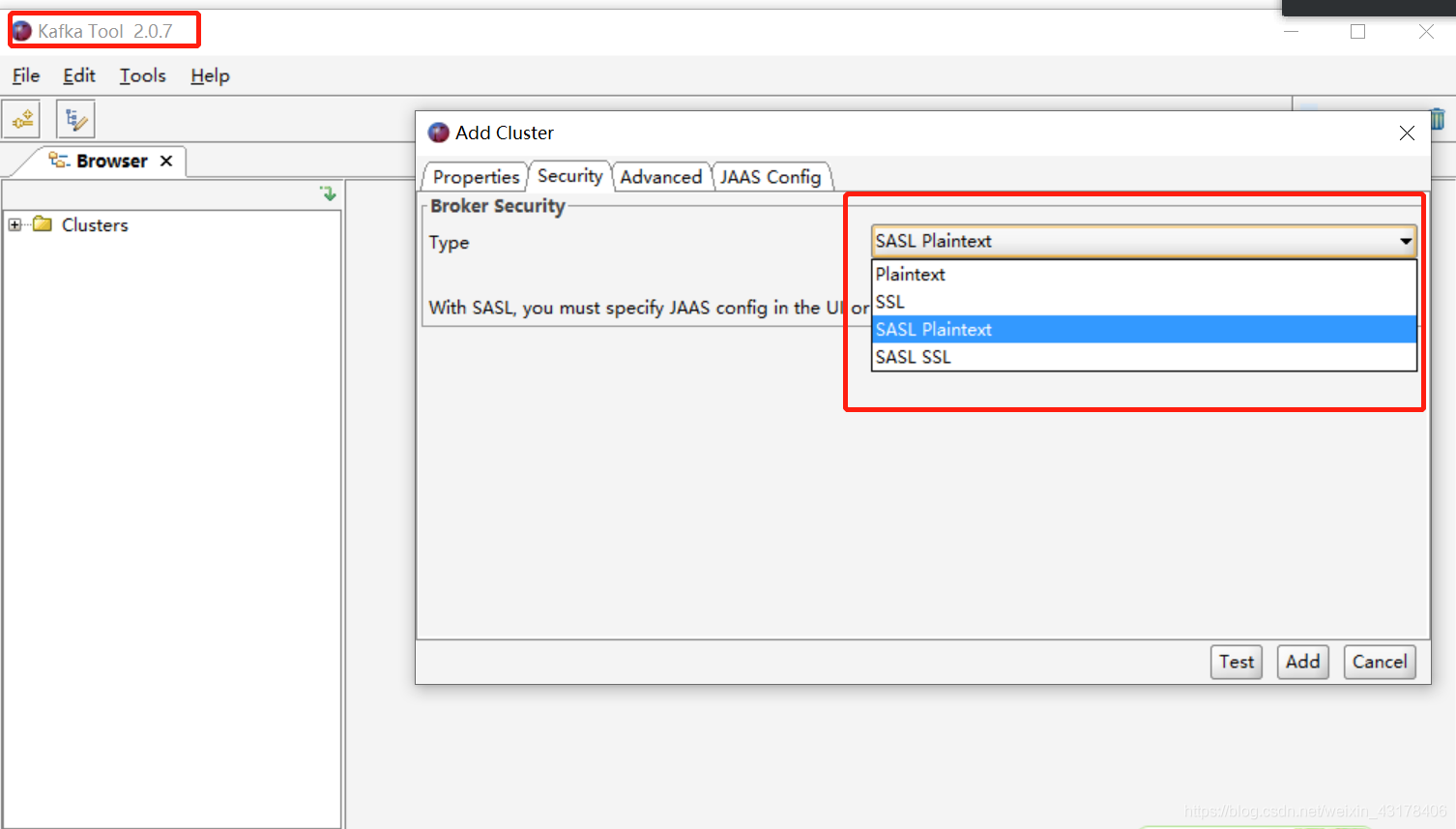
该图来自kafka tool这个软件,可以使用UI界面展示kafka数据。
这四种安全机制都是什么,由于我不是搞大数据的,不做部署,故省略
3. python_API
3.1 作为生产者连接kafka并发送数据
# 此代码是plaintext安全机制
import json
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='218.88.86.99:9096', api_version = (0, 10)) # 连接kafka
msg = {"inputValue": '192.143.145.25',
"dataType":"botnetDetection"}
msg = json.dumps(msg) # 将数据变成json形式
msg = msg.encode("utf-8") # 将数据编码
producer.send('info_lost_assets', value=msg) # 生产者生产数据
上述中KafkaProducer是用来连接kafka的,其参数包含以下:
- bootstrap_servers:部署kafka服务器的ip及端口号。如果kafka只部署在一台服务器上,则形如:“192.183.164.45:9092”。如果部署在多台服务器上,则形如:"192.183.164.45:9092,198.134.39.49:8888"或者[“192.183.164.45:9092”,“198.134.39.49:8888”]
- api_version:指定使用的Kafka API版本。 如果设置为None,则客户端将尝试通过探查各种API来推断代理版本。 示例:(0,10,2)。 默认值:None,这个参数一定要设置,否则可能报错
NoBrokersAvailable - security_protocol:安全机制,默认值为"PLAINTEXT",其他可选项为:“SSL”、“SASL_PLAINTEXT”、“SASL_SSL”
- sasl_mechanism:str,当安全机制(security_protocol)为"SASL_PLAINTEXT"或"SASL_SSL"时的身份验证机制:PLAIN,GSSAPI,OAUTHBEARER,SCRAM-SHA-256,SCRAM-SHA-512
- sasl_plain_username:如果sasl_mechanism的身份验证机制为PLAIN或SCRAM中的任何一个,需要填写PLAIN或SCRAM的用户名
- sasl_plain_password:如果sasl_mechanism的身份验证机制为PLAIN或SCRAM中的任何一个,需要填写PLAIN或SCRAM的密码
- value_serializer:用来指定序列化的方式。如value_serializer=lambda m: json.dumps(m).encode(),其作用是向kafka中传入一个字典类型的数据,kafka自动将其value转化为json并编码成utf-8(编码方式可以更改),如果设置,最终必须是字节数据
- key_serializer:类似于value_serializer,将字典类型数据的key转化为字节数据