时间复杂度、空间复杂度是算法中十分重要的概念.
一. 时间复杂度:
一个算法的时间效率(执行时间).
1. 大 O 表示法
「数量级」函数用来描述当规模 n 增加时,T(n) 函数中增长最快的部分,这个数量级函数我们一般用「大 O」表示,记做 O(f(n))。它提供了计算过程中实际步数的近似值,函数 f(n) 是原始函数 T(n) 中主导部分的简化表示。
在上面的求和函数的那个例子中,T(n) = n + 1,当 n 增大时,常数 1 对于最后的结果来说越来不越没存在感,如果我们需要 T(n) 的近似值的话,我们要做的就是把 1 给忽略掉,直接认为 T(n) 的运行时间就是 O(n)。这里你一定要搞明白,这里不是说 1 对 T(n) 不重要,而是当 n 增到很大时,丢掉 1 所得到的近似值同样很精确。
再举个例子,比如有一个算法的 T(n) = 2n^2 +2n +1000,
当 n 为 10 或者 20 的时候,常数 1000 看起来对 T(n) 起着决定性的作用。但是当 n 为 1000 或者 10000 或者更大呢?n^2
起到了主要的作用。实际上,当 n 非常大时,后面两项对于最终的结果来说已经是无足轻重了。与上面求和函数的例子很相似,当 n 越来越大的时候,我们就可以忽略其它项,只关注用 2n^2
来代表 T(n) 的近似值。同样的是,系数 2 的作用也会随着 n 的增大,作用变得越来越小,从而也可以忽略。我们这时候就会说 T(n) 的数量级 f(n) = n^2,
即 O(n^2)。
2. 最好情况、最坏情况和平均情况
尽管前面的两个例子中没有体现,但是我们还是应该注意到有时候算法的运行时间还取决于「具体数据」而不仅仅是「问题的规模大小」。对于这样的算法,我们把它们的执行情况分为「最优情况」、「最坏情况」和「平均情况」。
某个特定的数据集能让算法的执行情况极好,这就是最「最好情况」,而另一个不同的数据会让算法的执行情况变得极差,这就是「最坏情况」。不过在大多数情况下,算法的执行情况都介于这两种极端情况之间,也就是「平均情况」。因此一定要理解好不同情况之间的差别,不要被极端情况给带了节奏。
对于「最优情况」,没有什么大的价值,因为它没有提供什么有用信息,反应的只是最乐观最理想的情况,没有参考价值。「平均情况」是对算法的一个全面评价,因为它完整全面的反映了这个算法的性质,但从另一方面来说,这种衡量并没有什么保证,并不是每个运算都能在这种情况内完成。而对于「最坏情况」,它提供了一种保证,这个保证运行时间将不会再坏了,所以一般我们所算的时间复杂度是最坏情况下的时间复杂度,这和我们平时做事要考虑到最坏的情况是一个道理。
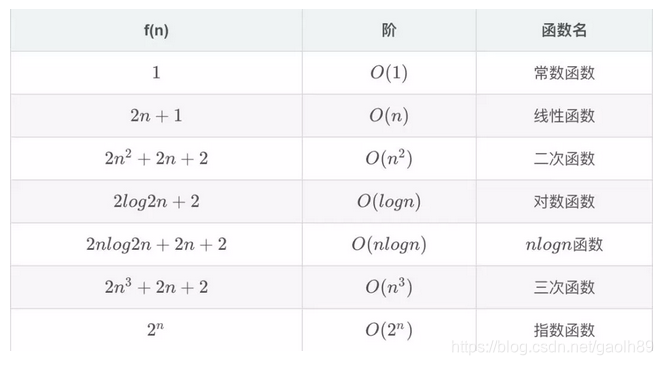
在我们之后的算法学习过程中,会遇到各种各样的数量级函数,下面我给大家列举几种常见的数量级函数:
二.空间复杂度
一个算法的空间复杂度是指该算法所耗费的存储空间,计算公式计作:S(n) = O(f(n))。其中 n 也为数据的规模,f(n) 在这里指的是 n 所占存储空间的函数。
目前,空间复杂度其实在这里更多的是说一下这个概念,因为当今硬件的存储量级比较大,一般不会为了稍微减少一点儿空间复杂度而大动干戈,更多的是去想怎么优化算法的时间复杂度。所以我们在日常写代码的时候就衍生出了用"空间换时间"的做法,并且成为常态。