一、语言
语言是其句子的集合。
- 汉语–所有符合汉语语法的句子的全体
- 英语–所有符合英语语法的句子的全体
- 程序设计语言–所有该语言的程序的全体
研 究 语 言 = { 每 个 句 子 构 成 的 规 律 每 个 句 子 的 含 义 每 个 句 子 和 使 用 者 的 关 系 研究语言=\left\{ \begin{aligned} 每个句子构成的规律 \\ 每个句子的含义\\ 每个句子和使用者的关系 \\ \end{aligned} \right. 研究语言=⎩⎪⎨⎪⎧每个句子构成的规律每个句子的含义每个句子和使用者的关系
三个方面:
- 语法 Syntax
表示构成语言句子的各个记号之间的组合规律 - 语义 Semantics
表示各个记号及其组合的特定含义(各个记号和记号所表示对象之间的关系) - 语用 Pragmatics
表示在各个记号所出现的行为中,它们的来源、使用和影响
1、形式语言
可用于形式化地描述程序设计语言,包括它由哪些符号串构成,这些符号串的表示、结构和特性
2、符号和符号串
任何一种语言都是由该语言的基本符号组成的符号串集合
一些基本概念:
- 符号:
一个抽象实体,我们不再形式地定义它(就象几何中的”点”一样).例如字母是符号,数字也是符号。 - 字母表:
字母表是元素的非空有穷集合,我们把字母表中的元素称为符号,因此字母表也称为符号集。不同的语言可以有不同的字母表,例如:汉语的字母表中包括汉字、数字及标点符号等,PASCAL语言的字母表是由字母、数字、若干专用符号及BEGIN、IF之类的保留字组成。 - 符号串:
- 由字母表中的符号组成的任何有穷序列称为符号串,例如00 11 10 是字母表 ∑ ={0,1}上的符号串。
- 字母表A={a,b,c}上的一些符号串有:a,b,c,ab,aaca。在符号串中,符号的顺序是很重要的,符号串ab就 不同于ba,abca和aabc也不同。
- 可以使用字母表示符号串,如x=STR表示 x 是由符号S、T和R,并按此顺序组成的符号串。
- 符号串的长度:
如果某符号串x中有m个符号,则称其长度为m,表示为|x|=m,如001110的长度是6。 - 空符号串:
即不包含任何符号的符号串,用ε表示,其长度为0,即|ε|=0。 - 符号串的头、尾,固有头和固有尾:
- 如果z=xy是一符号串,那么x是z的头,y是z的尾;
- 如果x是非空的,那么y是固有尾;
- 如果y非空,那么x是固有头。
例如:设z=abc,那么z的头是ε,a,ab,abc,除abc外, 其它都是固有头;z的尾是ε,c,bc,abc,z的固有尾是
ε,c,bc。当对符号串z=xy的头感兴趣而对其余部分不感兴趣时,采用省略写法:z=x…;
如果只是为了强调x在符号串z中的某处出现,则可表示为:z=…x…;符号t是符号串z的第一个符号,则表示为z=t…。
-
符号串的连接:
设x和y是符号串,它们的连接xy 是把y的符号写在x的符号之后得到的符号串. 由于ε的含义,显然有ε x=x,x ε =x
例如:x=ST,y=abu,则它们的连接xy=STabu,看出
|x|=2,|y|=3,|xy|=5 -
符号串的方幂:
符号串自身连接n次得到的符号串,an 定义为 aa…aa n个a,a1=a, a2=aa且a0=ε- 例:若x=AB,则:
x0 = ε
x1 =AB
x2 = ABAB
x3 = ABABAB
xn = xxn-1 = xn-1 x (n>0)
- 例:若x=AB,则:
-
符号串集合:
若集合A中所有元素都是某字母表 ∑ 上的符号串,则称A为字母表上的符号串集合。 -
两个符号串集合A和B的乘积:
定义为 AB = {xy|x∈A且y∈B}
若集合A={ab,cde} 集合B = {0,1},则
AB ={ab1,ab0,cde0,cde1}
使用 ∑* 表示 ∑ 上的一切符号串(包括 ε )组成的集合。Σ* 称为 Σ 的闭包。
∑ 上的除ε外的所有符号串组成的集合记为∑+。 ∑+称为Σ的正闭包。
编译原理的闭包:
V是一个符号集合,假设V指的是三个符号a, b, c的集合,记为 V = {a, b, c } V*
读作“V的闭包”,它的数学定义是V自身的任意多次自身连接(乘法)运算的积,也是一个集合。
也就是说,用V中的任意符号进行任意多次(包括0次)连接,得到的符号串,都是V*这个集合中的元素。 0次连接的结果是不含任何符号的空串,记为
ε 1次连接就是只有一个符号的符号串,比如,a,b, c 2次连接是两个符号构成的符号串,比如,aa, ab, ac, ba, bb,
bc,等等
二、文法
符号 − > -> −>符号串 − > -> −>句子 − > -> −>语言
并非所有符号串都能形成句子
文法G定义为一个四元组 ( V N , V T , P , S ) (V_N,V_T,P,S ) (VN,VT,P,S),其中:
-
V N V_N VN为非终结符号(或语法实体,或变量)集;
非终结符(nonterminal) 是用来表示语法成分的符号,有时也称为语法变量
例: V N = { < 句 子 > , < 名 词 短 语 > , < 动 词 短 语 > , < 名 词 > , … } V_N = \{ <句子>, <名词短语>, <动词短语>,<名词>, … \} VN={ <句子>,<名词短语>,<动词短语>,<名词>,…}
-
V T V_T VT为终结符号集;
终结符(terminal symbol)是文法所定义的语言的基本符号,有时也称为 t o k e n token token
例: V T = { a p p l e , b o y , e a t , l i t t l e } V_T=\{ apple, boy, eat, little\} VT={ apple,boy,eat,little}
-
P P P为产生式(也称规则)的集合; V N V_N VN, V T V_T VT和 P P P是非空有穷集;
产生式(production)描述了将终结符和非终结符组合成串的方法产生式的一般形式:
α→β 读作:α定义为β
-
α ∈ ( V T ∪ V N ) + α∈(V_T∪V_N)^+ α∈(VT∪VN)+,且α中至少包含 V N V_N VN中的一个元素:称为产生式的头(head)或左部(left side)
-
β ∈ ( V T ∪ V N ) ∗ β∈(V_T∪V_N)^* β∈(VT∪VN)∗:称为产生式的体(body)或右部(right side)
例:
P = { < 句 子 > → < 名 词 短 语 > → < 动 词 短 > , < 名 词 短 语 > → < 形 容 词 > → < 名 词 短 语 > , … P=\left\{ \begin{aligned} <句子>\rightarrow<名词短语>\rightarrow<动词短>, \\ <名词短语>\rightarrow<形容词>\rightarrow<名词短语>, \\ …\end{aligned} \right. P=⎩⎪⎨⎪⎧<句子>→<名词短语>→<动词短>,<名词短语>→<形容词>→<名词短语>,…
-
-
S S S为识别符号或开始符号,它是一个非终结符。
S ∈ V N S∈V_N S∈VN。开始符号(start symbol ) 表示的是该文法中最大的语法成分
➢例: S = < 句 子 > S = <句子> S=<句子>
V N V_N VN和 V T V_T VT不含公共的元素,即 V N V_N VN ∩ V T V_T VT = φ φ φ
用 V V V表示 V N V_N VN ∪ V T V_T VT ,称为文法 G G G的字母表或字汇表规则,也称重写规则、产生式或生成式,
是形如α→β或α∷=β的 ( α , β ) (α,β) (α,β)有序对,其中 α 是字母表 V V V的正闭包 V + V^+ V+中的一个符号,β 是 V ∗ V^* V∗中的一个符号。
α 称为规则的左部,β称作规则的右部。
 |
 |
 |
 |
1、推导
直接推导:“ = > => =>”
α→β 是文法G的产生式,若有 δ1, δ2 满足:δ1 =γ1αγ2, δ2 = γ1βγ2, 其中γ1,γ2∈V
- 则称δ1直接推导到δ2,记作δ1 = > => =>δ2
- 也称δ2直接归约到δ1
例:
G:S→0S1, S→01
-
0S1 => 00S11
-
00S11 => 000S111
-
000S111 => 00001111
-
S => 0S1
 |
 |
规范推导:最右推导
 |

|
句型、句子的定义
-
句型:
有文法G,若S =>* x,则称x是文法G的句型。 -
句子:
有文法G,若S =>*x,且x∈ V T {V_T} VT*,则称x是文法G的句子。
例:
G: S→0S1, S→01
- S = > => => 0S1 = > => => 00S11 = > => => 000S111 = > => => 00001111
- G的句型S, 0S1, 00S11,000S111, 00001111
- G的句子00001111, 01
2、语言的定义
由文法G生成的语言记为L(G),它是文法G的一切句子的集合:
L ( G ) = { x ∣ S = > ∗ x , 其 中 S 为 文 法 的 开 始 符 号 , 且 x ∈ V ∗ } L(G)=\{x|S =>^*x,其中S为文法的开始符号,且x ∈V*\} L(G)={ x∣S=>∗x,其中S为文法的开始符号,且x∈V∗}
例:G: S→0S1, S→01
L ( G ) = { 0 n 1 n ∣ n ≥ 1 } L(G)=\{0^n1^n|n≥1\} L(G)={ 0n1n∣n≥1}
 |
 |

3、文法等价
若 L ( G 1 ) = L ( G 2 ) L(G1)=L(G2) L(G1)=L(G2), 则称文法 G 1 G1 G1和 G 2 G2 G2是等价的。
如文法 G 1 [ A ] : A → 0 R G1[A]:A→0R G1[A]:A→0R 与 G 2 [ S ] : S → 0 S 1 G2[S]:S→0S1 G2[S]:S→0S1 等价
A→01 S→01 R→A1
4、语法树
文法G[Z]的语法树:
-
每个结点都是G的符号
-
树根是文法的开始符号
-
若某个结点至少有一个从它出来的分支,则该结点一定是非终结符
-
若某个结点A有n个分支,假设其分支结点为B1,B2,…Bn,则A::=B1B2B3…Bn一定是文法的一条规则
语法树可以从推导过程产生。
凡使用一条规则推导,则可以从规则左部符号结点长出若干分支。
 |
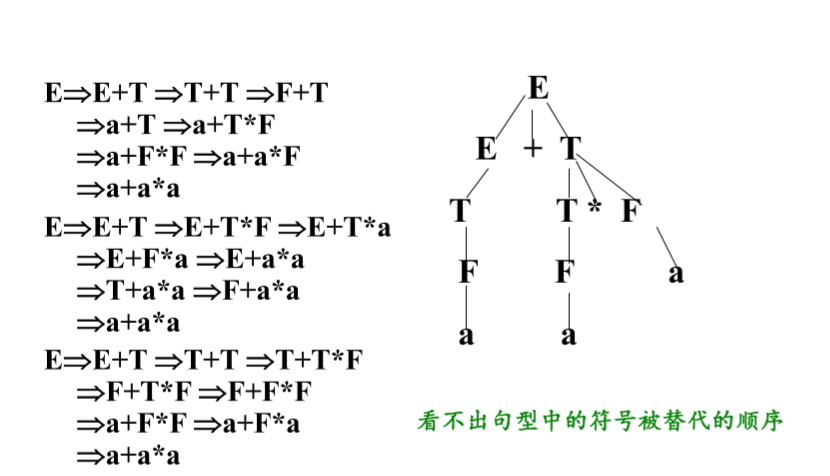 |
5、句型分析
句型分析就是识别一个符号串是否为某文法的句型,是某个推导的构造过程。
在语言的编译实现中,把完成句型分析的程序称为分析程序或识别程序,分析算法又称识别算法。
从左到右的分析算法,即总是从左到右地识别输入符号串,首先识别符号串中的最左符号,进而依次识别右边的一个符号,直到分析结束。
句型分析分析算法可分为:
- 自上而下分析法:
从文法的开始符号出发,反复使用文法的产生式,寻找与输入符号串匹配的推导。 - 自下而上分析法:
从输入符号串开始,逐步进行归约,直至归约到文法的开始符号。
两种方法反映了两种语法树的构造过程:
-
自上而下方法是从文法符号开始,将它做为语法树的根,向下逐步建立语法树,使语法树的结果正好是输入符号串
-
自下而上方法则是从输入符号串开始,以它做为语法树的结果,自底向上地构造语法树
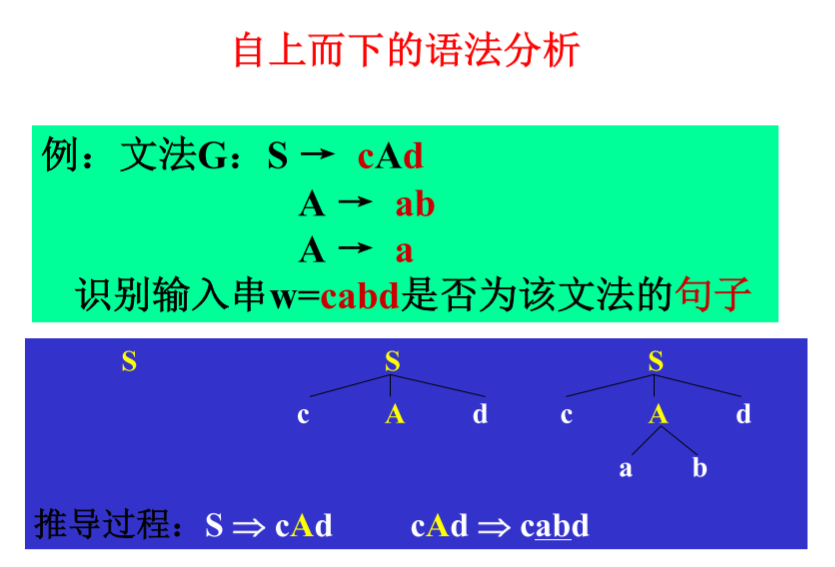 |
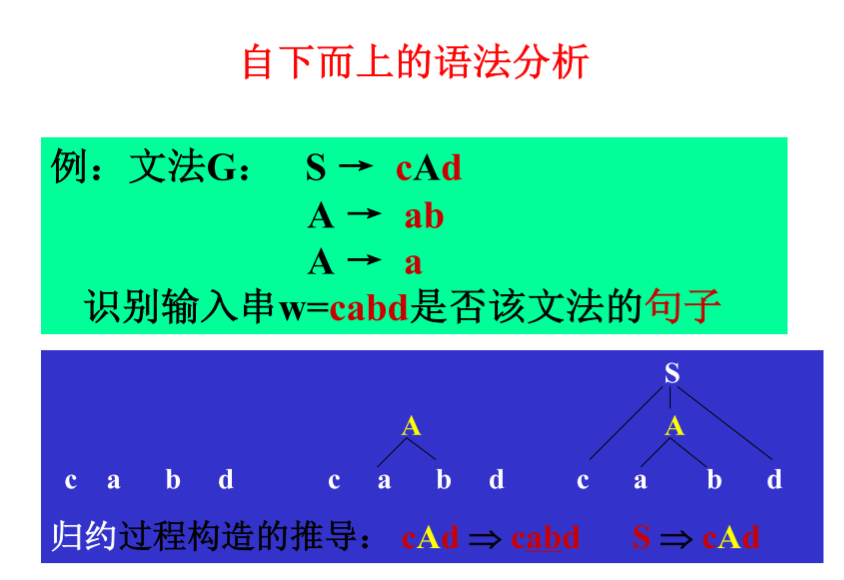 |
 |
 |
句型分析的有关问题
- 1)在自上而下的分析方法中如何选择使用哪个产生式进行推导?
假定要被代换的最左非终结符号是A,且有n条规则:A→B1|B2|…|Bn,那么如何确定用哪个右部去替代A? - 2)在自下而上的分析方法中如何识别可归约的串?
在分析程序工作的每一步,都是从当前串中选择一个子串,将它归约到某个非终结符号,该子串称为“可归约串”
刻画“可归约串”

-
短语是句型中某非终结符号通过若干步推导出的子串
-
归约:如果每次都从当前句型的句柄进行归约,则可以归约到文法的开始符号

6、文法二义性
-
文法二义性:两棵语法树对应同一句子
-
根据语法树,可以发现文法的二义性二义文法
若一个文法存在某个句子对应两棵不同的语法树,则称这个文法是二义的或者,若一个文法存在某个句子有两个不同的最左(右)推导,则称这个文法是二义的。
判定任给的一个上下文无关文法是否二义,或它是否产生一个先天二义的上下文无关语言,
这两个问题是递归不可解的,但可以为无二义性寻找一组充分条件。
文法的二义性和语言的二义性是两个不同的概念:
可能有两个不同的文法G和G′,其中G是二义的,但是却有:L(G)=L(G′),
即,这两个文法所产生的语言是相同的。

7、文法分类
通过对产生式施加不同的限制,Chomsky将文法分为四种类型:
- 0型文法:对任一产生式 α → β α→β α→β,都有 α ∈ ( V N ∪ V T ) + α∈(V_N∪V_T)^+ α∈(VN∪VT)+, β ∈ ( V N ∪ V T ) ∗ β∈(V_N∪V_T)^* β∈(VN∪VT)∗
- 1型文法:对任一产生式 α → β α→β α→β,都有 ∣ β ∣ ≥ ∣ α ∣ |β|≥|α| ∣β∣≥∣α∣ ,仅 S → ε S→ε S→ε 除外, S为文法初始符号且不出现在任何产生式右边
- 2型文法:对任一产生式 α → β α→β α→β,都有 α ∈ V N α∈V_N α∈VN, β ∈ ( V N ∪ V T ) ∗ β∈(V_N∪V_T)^* β∈(VN∪VT)∗
- 3型文法:任一产生式 α → β α→β α→β的形式都为 A → a B A→aB A→aB或 A → a A→a A→a, 其中 A ∈ V N A∈V_N A∈VN, B ∈ V N B∈V_N B∈VN, a ∈ V T a∈V_T a∈VT
| 类型 | 例子 |
|---|---|
| 1型文法 |  |
| 2型文法 |  |
| 3型文法 |  |
文法的实用限制:

ε 规则:

关于区分上下文是否相关,引入知乎大佬的解释:
