
系列开篇语
写深度学习博客有两年多了,从最初的做记录备忘到现在经验总结分享,积累了一些读者,也结识了不少想入门研究深度学习的朋友。有不少朋友私聊问小宋如何快速入门深度学习,我发现大部分小伙伴都是对这方面有兴趣面对网上丰富的资料却不知道如何选择与操作。从而让我萌发了写一个一步步手把手带大家如何从零开始学习,使得基础薄弱的人员能以更简单易懂的方式入门深度学习与实战开发系列教程——《带你学AI与TensorFlow2实战》。

系列教程将分为以十一个部分:
1. 章节一:初探AI(《带你学AI与TensorFlow2实战一之深度学习初探》):(已完成)
2. 章节二:环境搭建(《带你学AI与TensorFlow2实战二之多系统开发环境与工具搭建》):(Windows10篇完成;Ubuntu18进行中)
3. 章节三:CV项目分类实战(《带你学AI与TensorFlow2实战三之交通标志分类项目》):
4. 章节四:CV项目目标检测实战(《带你学AI与TensorFlow2实战四之口罩检测项目》):
5. 章节五:CV项目像素分割实战(《带你学AI与TensorFlow2实战五之人体抠图分割》):
6. 章节六:CV项目基于GAN实战图像生成(《带你学AI与TensorFlow2实战六之基于GAN生成卡通形象》):
7. NLP项目基于RNN+Attention文本分类(《带你学AI与TensorFlow2实战七之影评分类》):
8.章节八:NLP项目基于Transformer中英翻译(《带你学AI与TensorFlow2实战八之Transformer中英翻译》):
9.章节九:NLP项目基于BERT预训练模型实战(《带你学AI与TensorFlow2实战九之Bert中文文本摘要》):
10.章节十:强化学习DQN实战走迷宫(《带你学AI与TensorFlow2实战十之基于DQN实战走迷宫》):
11.章节十一:算法模型应用的部署(《带你学AI与TensorFlow2实战十一之算法模型工程化应用部署》):
旨在通过对原理的通俗讲解、学习方法的介绍培养、开发环境的手把手搭建、深度学习案例开发讲解以及算法模型应用部署使用。
这是一个开源免费的教程,希望能和更多朋友一起分享贡献,不断完善。代码与文档将同步在GitHub
关注小宋公众号“极简AI”,回复“源码”,来获取源码与Github链接。。
现在正式开始AI学习之旅喽...
引子
在上篇文章中《『带你学AI』带你学AI与TensorFlow2实战之入门初探:如何速成深度学习开发》,通过对深度学习的简单介绍,分享了如何入门深度学习的方法,也介绍了一些学习资料与开发工具。在本文中将讲解开发环境配置,由于是图解流程会有很多图片,故将分为上下两篇,分别讲解 Windows 10 与 Ubuntu 18 。
工欲善其事必先利其器,在本篇文章中,将详细讲解 Windows 系统开发环境配置,包括 CPU 与 GPU 深度学习环境的配置与 VSCode 开发 Python 方法及 Python 简单使用。最后通过对一个深度学习案例运行与讲解,一步步带大家使用 Windows10 平台搭建出深度学习开发环境,能让大家开始动手实践。
小宋说:在本篇中,主要内容主要是实际动手操作内容,因此添加了许多操作截图,同时也在截图上进行了步骤标注与说明。所以强烈建议小伙伴们一起来动手实践,也欢迎点赞收藏并转发给需要的朋友。大家的支持是小宋继续做下去的动力。
正式开始实践动手了,建议先收藏,再一步步跟着实践,遇到问题欢迎在评论区讨论。下面多图预警。
深度学习环境配置说明
深度学习环境的配置包括以下内容:
- GPU 支持(如果硬件支持的话,可以实现加速训练)
- Python 环境(用于开发深度学习的语言)
- 深度学习框架(成熟的网络模型以及训练接口)
- VSCode 编辑器(用于编程与运行)
对于 GPU 支持部分安装与配置,这里是比较麻烦繁琐的,也较容易出问题,所以在本文中用一个简单的方式来安装配置。通过安装 NVIDIA 驱动,配合“conda”来安装“cudatoolkit”与“cudnn”,实现对 AI 运算加速的效果。在简单便捷的同时,“conda”也支持“Python”的管理与使用。

首先将带大家展示如何检测电脑是否有英伟达 GPU 以及如何安装使用。
Windows 10 英伟达 GPU 驱动安装
查看是否有 GPU 及其型号
首先要判断自己电脑是否拥有英伟达 GPU,可以通过使用“百度”搜索自身电脑型号来查看。
也可以通过“任务管理器”界面查看,具体方法如下图所示:点击下方“搜索”按钮,搜索“任务管理器”进入即可。

进入“任务管理器”后选择“性能”,如果有 GPU1(GPU0 为集成显卡)则代表是拥有独显,此时再来查看 GPU 型号即可:可以看到笔者的 GPU 为“NVIDIA GeForce RTX 2070”,先记录下来后面会用到。如果没有“NVIDIA”的前缀则不能使用。
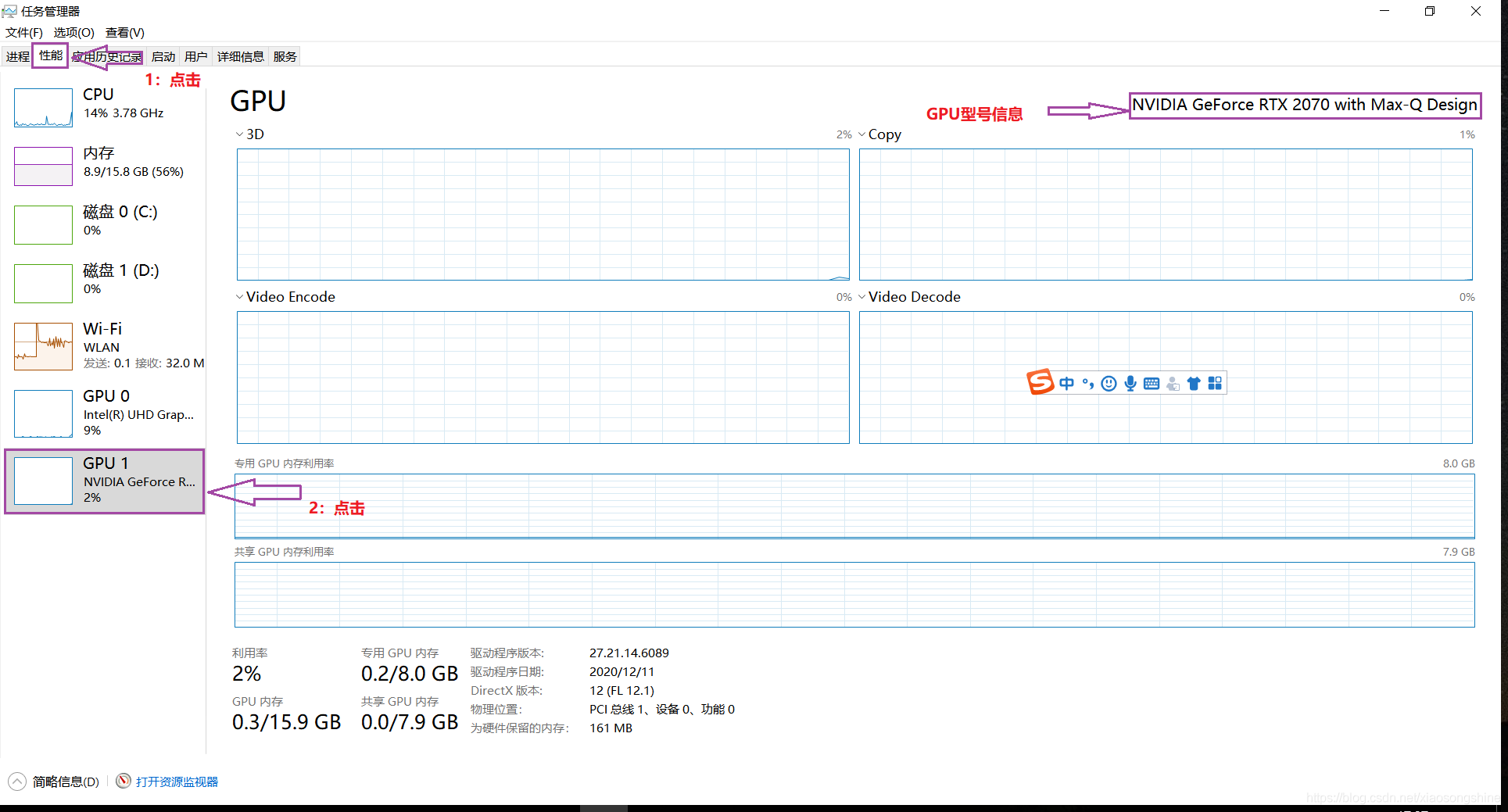
小宋说:通过上述步骤,我们就可以判断是自己电脑是否有英伟达 GPU,这里会有些容易让初学者疑惑的地方,并非 GPU 都可以用来加速 AI 训练的,目前普遍支持好的仅有英伟达 GPU。而 Intel 的集成显卡(上图GPU 0)与 AMD 显卡暂时不能使用,期待后面这些框架支持能越来越好。
通过上述步骤,我们就可以判断是电脑是否拥有英伟达 GPU,可用于加速。如果没有的话就可以不用进行“英伟达驱动的下载与安装”,直接进行“基于 Conda 的 Python 安装”,来安装 CPU 版本的深度学习环境。
英伟达驱动的下载与安装
首先是Windows 10 英伟达驱动安装,驱动下载地址:
https://www.nvidia.com/Download/index.aspx?lang=cn#
安装如下方式搜索驱动,根据 GPU 显卡型号进行选择,“操作系统”与“下载类型”与下方一致即可,点击搜索按钮(其实 Linux 系统的驱动下载也类似,操作系统选择 Linux 即可
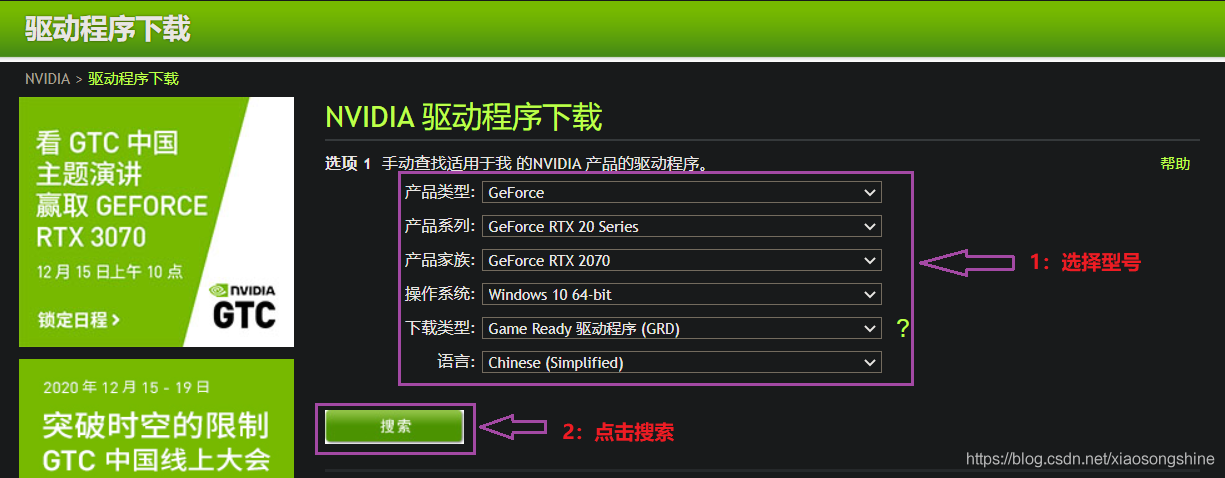
后会出现如下界面,再点击下载。

下载完成后打开安装即可。
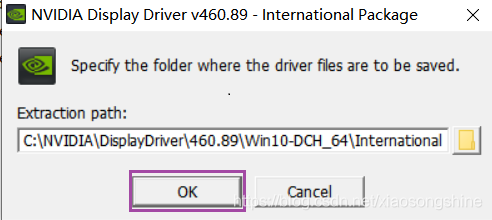
进行安装时界面如下。

随后会进入安装选择,按以下操作即可。
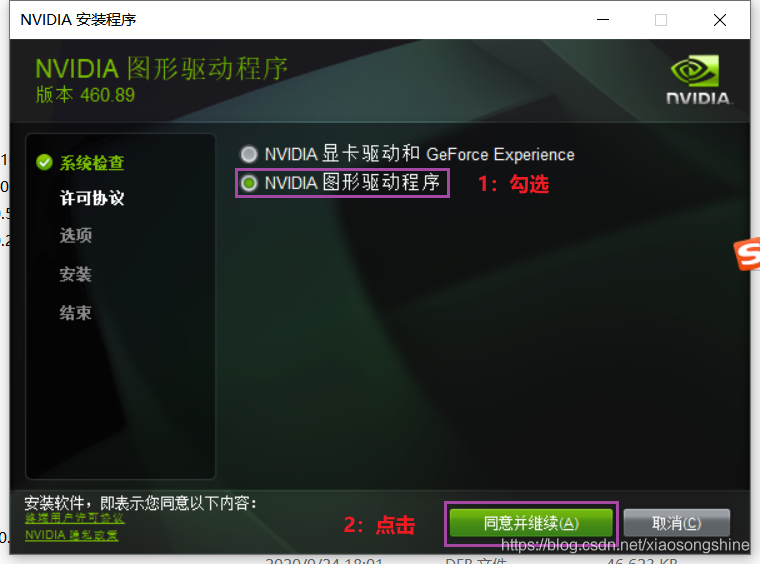
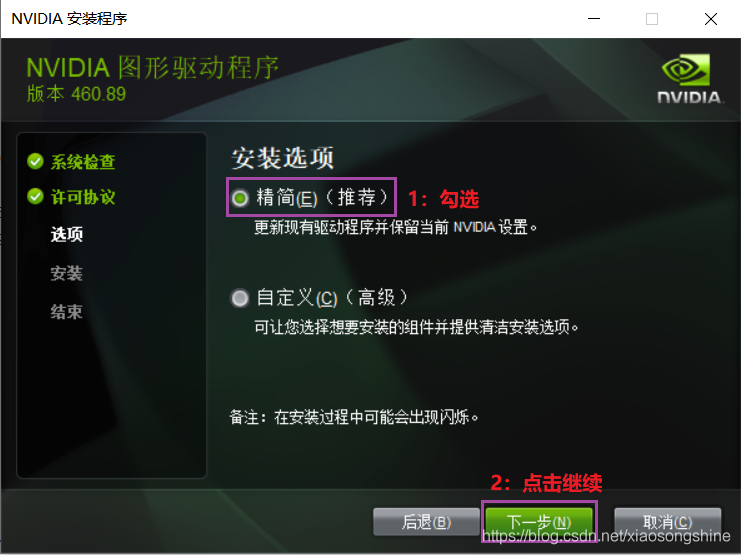
建议安装上述步骤来选择安装,这样安装很快速使用也没问题。安装结束后关闭窗口。
下面就可以测试是否安装成功,点击下方搜索按钮,输入“cmd”,再选择“命令控制符”
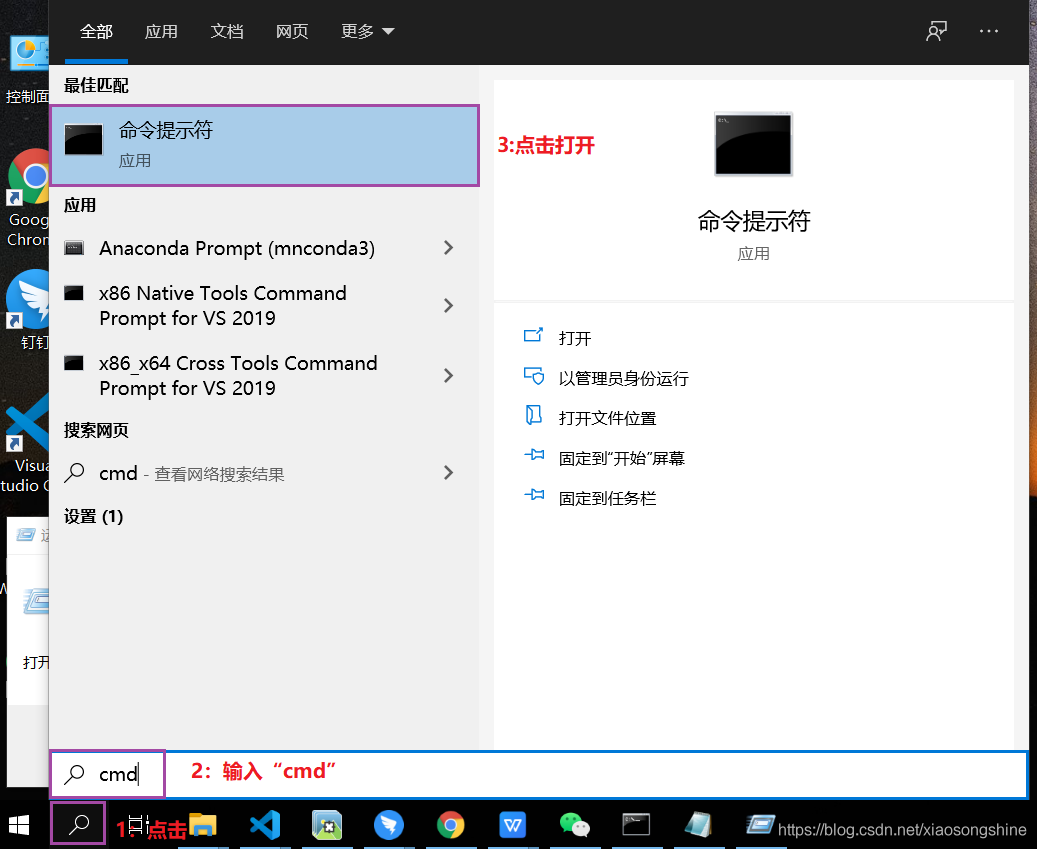
进入“cmd”命令控制符窗口,输入“nvidia-smi”,成功安装后会输出以下内容:
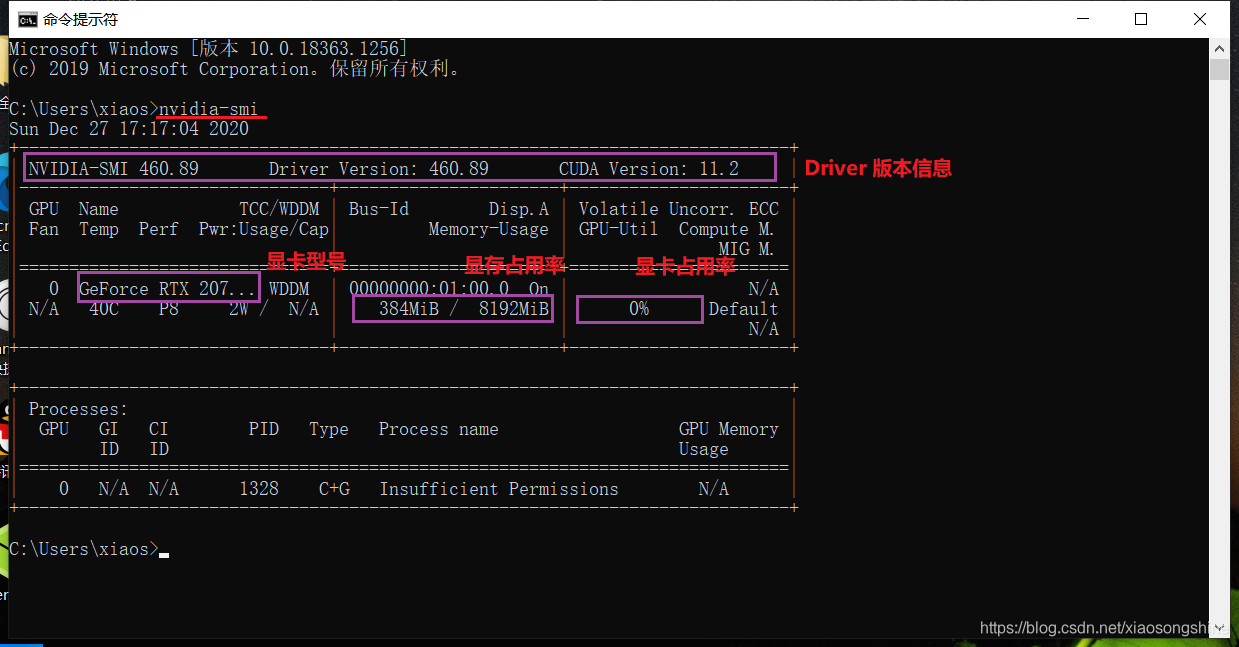
此时 NVIDIA 驱动就已经安装成功了。
后面就可以进行 CUDA 的安装,但是这个对使用 TensorFlow2 的 GPU 版本开发并不是必须的。为了简化安装流程,减轻小伙伴负担,这里就不安装 CUDA。
小宋说:“通过安装NVIDIA驱动,配合“conda”来安装“cudatoolkit”与“cudnn”,实现对AI运算加速的效果。”的原理部分可以参考这个文章:《显卡,显卡驱动,nvcc, cuda driver,cudatoolkit,cudnn到底是什么?》。通过上述方式简化了安装与使用,无需手动安装cuda与cudnn软件与配置路径,推荐大家使用。
基于 Conda 的 Python 安装
Python 的安装基于的 Conda,Conda 用来管理安装 Python 环境非常方便。
这里使用的是MiniConda。Miniconda 是一个 Anaconda 的轻量级替代,默认只包含了 python 和 conda,但是可以通过 pip 和 conda 来安装所需要的包。
Miniconda 安装包可以到 https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/ 下载。
进入链接后,界面拉到最下面,选择是“Windows-x86_64.exe”后缀下载安装即可。
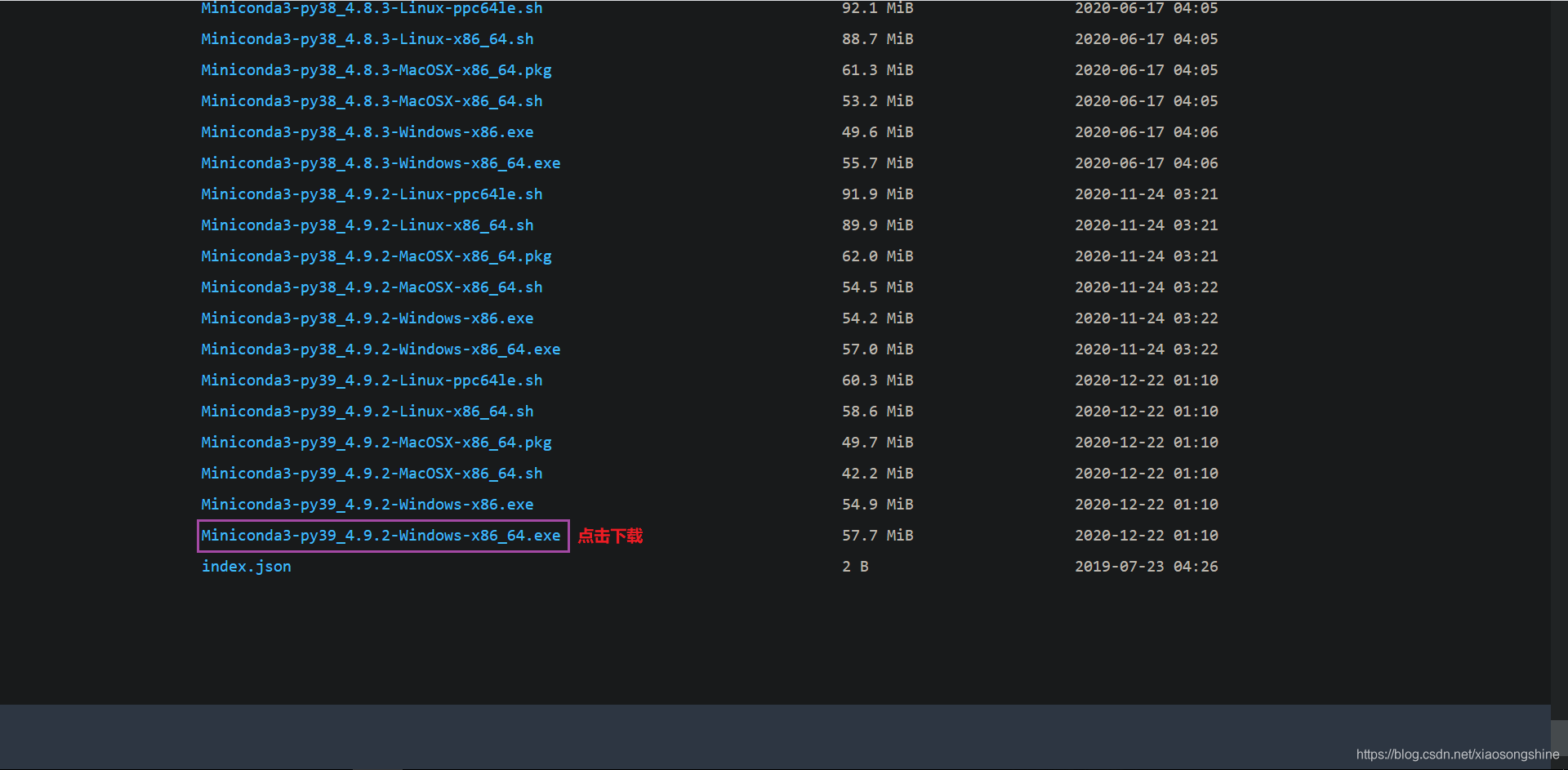
这里笔者使用的是Miniconda3-py39_4.9.2-Windows-x86_64.exe,下载链接:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-py39_4.9.2-Windows-x86_64.exe
下载完成后进行安装即可,这里注意“Add Miniconda to my PATH environment variable”要勾选上,这是设置环境变量,之后就可以直接在“CMD”界面使用“conda”指令。
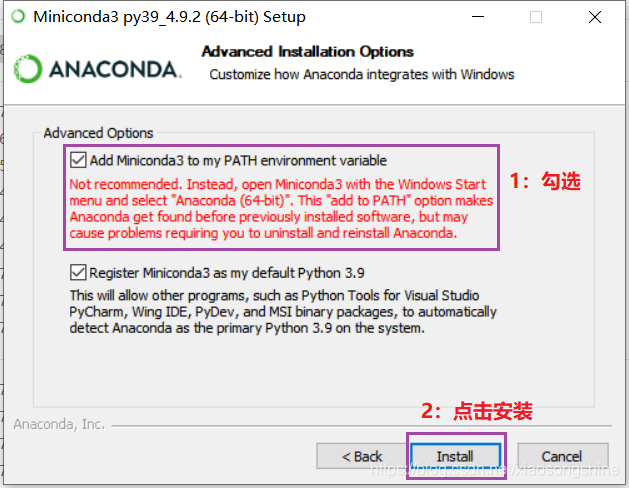
下面测试一下“conda”指令,打开“cmd”,输入“conda”
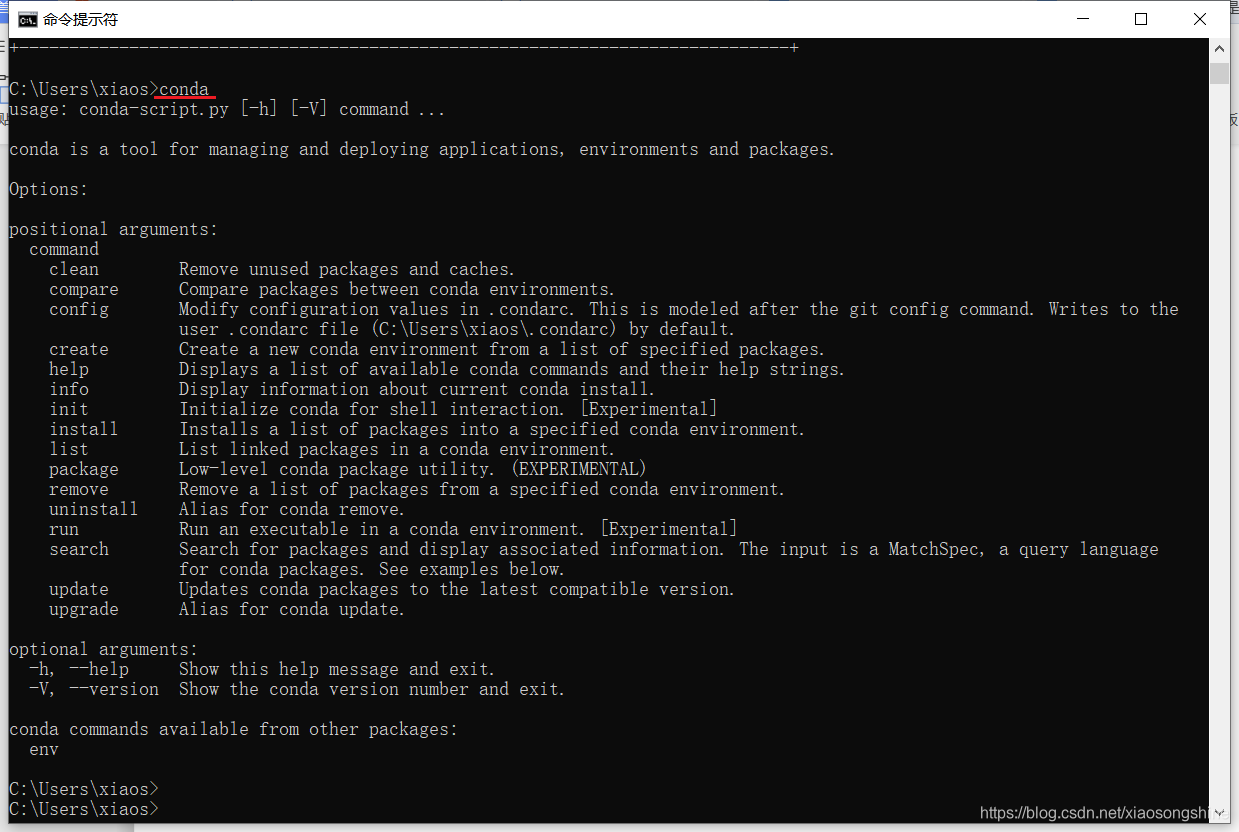
出现以上内容就表示安装已完成。
下面改下“conda”源,换为清华源用以下载加速,在“cmd”中复制粘贴以下指令,并回车:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --append channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/fastai/
conda config --append channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
conda config --set show_channel_urls yes同时我们也将“pip”换为清华源用以加速,在“cmd”中复制粘贴以下指令,并回车:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple上面说到的“conda”与“pip”是用于管理Python包的工具。
下面介绍些cmd conda指令(env_name代表环境名称):
- 查看所有conda环境:conda env list
- 新建conda环境(env_name就是创建的环境名,可以自定义):conda create -n env_name
- 激活conda环境:conda activate env_name
- 退出当前conda环境(返回base环境):conda deactivate
- 安装和卸载python包:conda install numpy # conda uninstall numpy
- 查看已安装python包列表:conda list -n env_name
下面也介绍些pip指令(以numpy举例):
- 安装包:pip install numpy
- 卸载包:pip uninstall numpy
- 更新包:pip install --upgrade numpy
- 列举所有包:pip list
注意一点,由于conda与pip都是通过网络下载包进行安装,所以电脑应当保持连接状态。如果出现了“HTTP 000”错误,则代表是网络连接错误。可能的原因有二:
- 电脑未连接网络
- 网络连接不稳定
可以先检查本机网络是否连接,如果已成功连接,则是连接不稳定多尝试几次即可。
随后我们可以新建一个新建一个 Python 环境,命名(-n)为“tf23”,指定Python版本为3.7(python==3.7):
conda create -n tf23 python=3.7出现一下界面,输入“y”,回车继续:
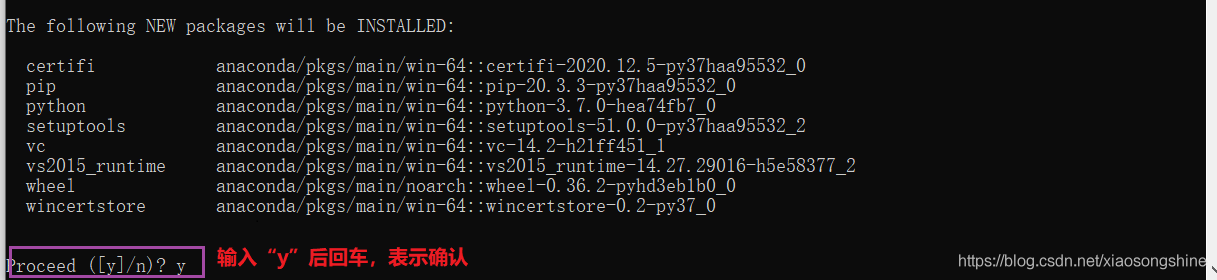
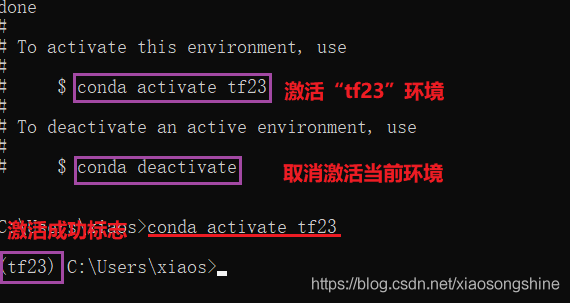
完成后输入:conda activate tf23 进入此环境,进入后可以看到前面了多了“tf23”,表示激活了此Python环境。
TensorFlow 的 CPU 与 GPU 版本安装
首先可以通过这个链接,看看 TensorFlow 版本对应的依赖项:
https://tensorflow.google.cn/install/pip
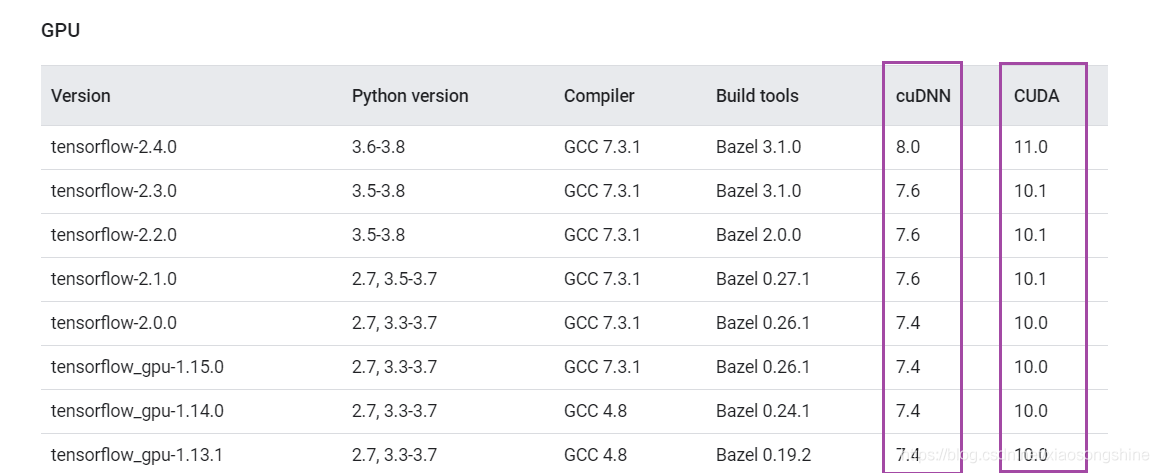
可以看出,如果是安装 TensorFlow 2.4 则对应 CUDA=11.0,cuDNN=8.0;TensorFlow 2.1-2.3 则对应CUDA=10.1,cuDNN=7.6;TensorFlow 2.0,对应CUDA=10.0,cuDNN=7.6;TensorFlow 1.13.1-1.15.0,对应CUDA=10.0,cuDNN=7.6。
这个需要注意,错了版本就会导致安装GPU失败。
下面针对不同版本 TensorFlow,分别说明。
从 TensorFlow 2.1 开始,pip 包 tensorflow 即同时包含 GPU 支持,无需通过特定的 pip 包 tensorflow-gpu 安装 GPU 版本。如果对 pip 包的大小敏感,可使用 tensorflow-cpu 包安装仅支持 CPU 的 TensorFlow 版本。
- TensorFlow 2.4/2.3/2.2/2.1 cpu版本安装
pip install tensorflow-cpu==2.4- TensorFlow2.4 gpu版本
conda install cudatoolkit=11.0 cudnn=8
pip install tensorflow==2.4- TensorFlow 2.3/2.2/2.1 gpu版本安装
conda install cudatoolkit=10.1 cudnn=7
pip install tensorflow==2.3- TensorFlow 2.0/1.15/1.14/1.13.1 gpu版本安装
conda install cudatoolkit=10.0 cudnn=7
pip install tensorflow-gpu==2.0- TensorFlow 2.0/1.15/1.14/1.13.1 cpu版本安装
pip install tensorflow==2.0
通过上述指令,就可以完成对应版本安装。下面就可以对其进行测试,以 TensorFlow 2.3 的 gpu 版本举例,在“cmd”中输入:
conda activate tf23
python然后在 Python 命令行内以此输入:
import tensorflow as tf
print(tf.__version__) # TensorFlow版本信息
print(tf.test.is_gpu_available()) # TensorFlow GPU支持
exit() #退出python命令行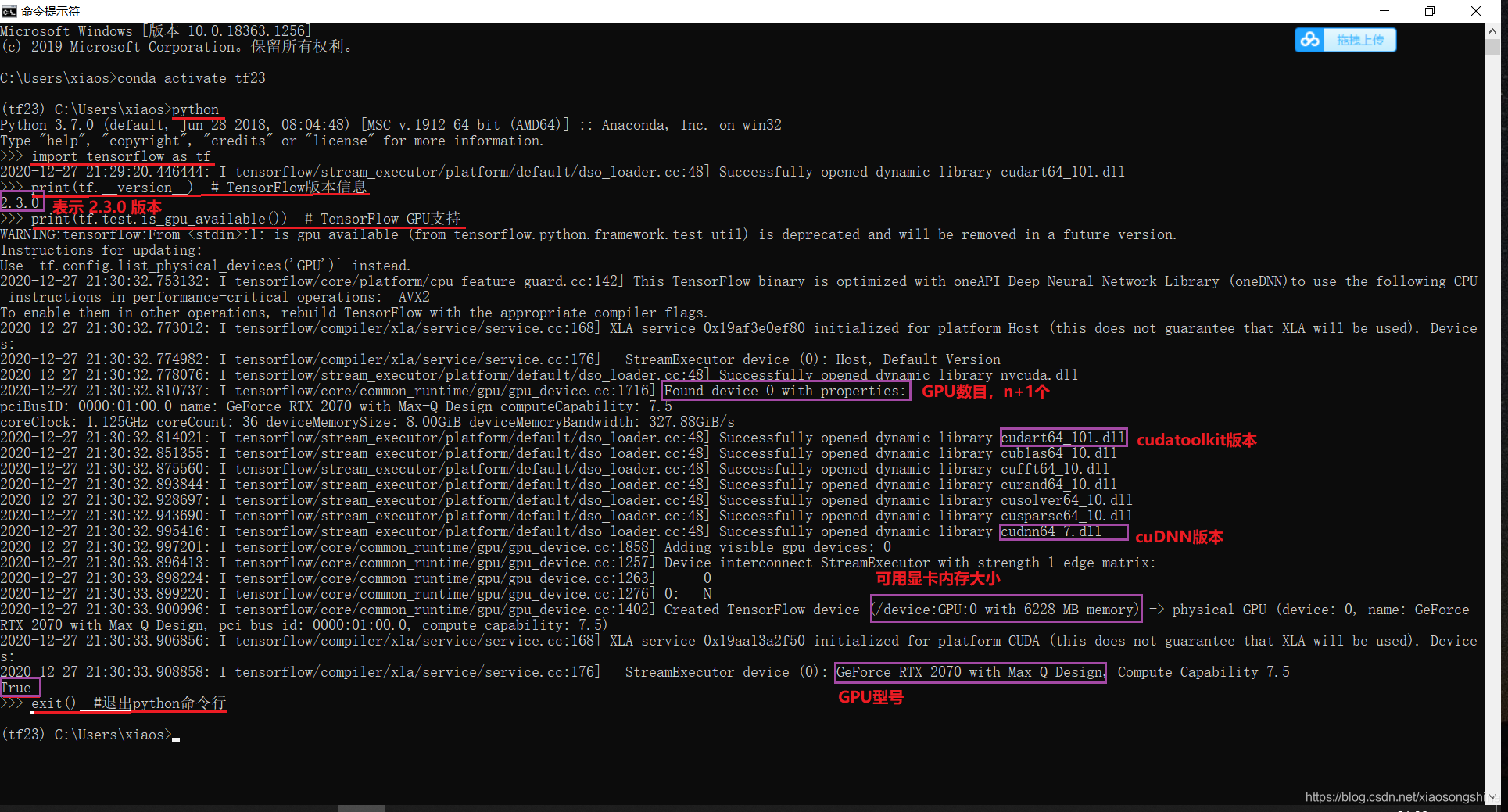
结果如上图所示,TensorFlow 版本信息为 2.3,TensorFlow GPU支持为 True。同时我们也可以在看到其他 GPU 输出信息。
Windows 10 下 VSCode 安装使用
VSCode 的 Windows 10 版本下载地址:
https://code.visualstudio.com/sha/download?build=stable&os=win32-x64-user
下载完成后双击安装即可,安装界面如下所示,一步步默认设置即可。
安装完成后打开界面如下:
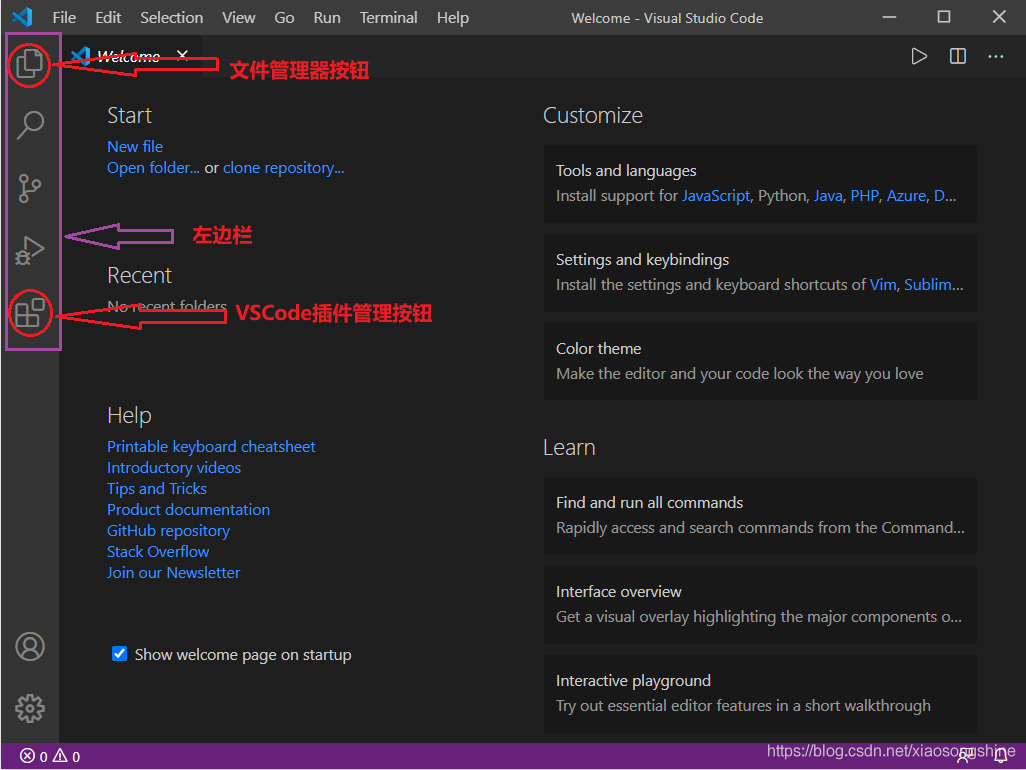
在上图左边栏中,从上到下依次为:“文件管理管理按钮”、“搜索按钮”、“代码管理按钮”、“运行与调试按钮”以及“插件管理按钮”。开发 Python 需要大家会用“文件管理管理按钮”与“插件管理按钮”功能。
插件管理按钮使用介绍:
VSCode定位是一个代码编辑器与集成开发环境(IDE)比更加轻量与灵活,需要用户自行安装一些插件来开发使用。需要我们安装对 Python 的支持插件,然后就可以愉快地使用 VSCode 开发 Python 了。
安装 Python 插件可以分为一下三个步骤,如下图所示:
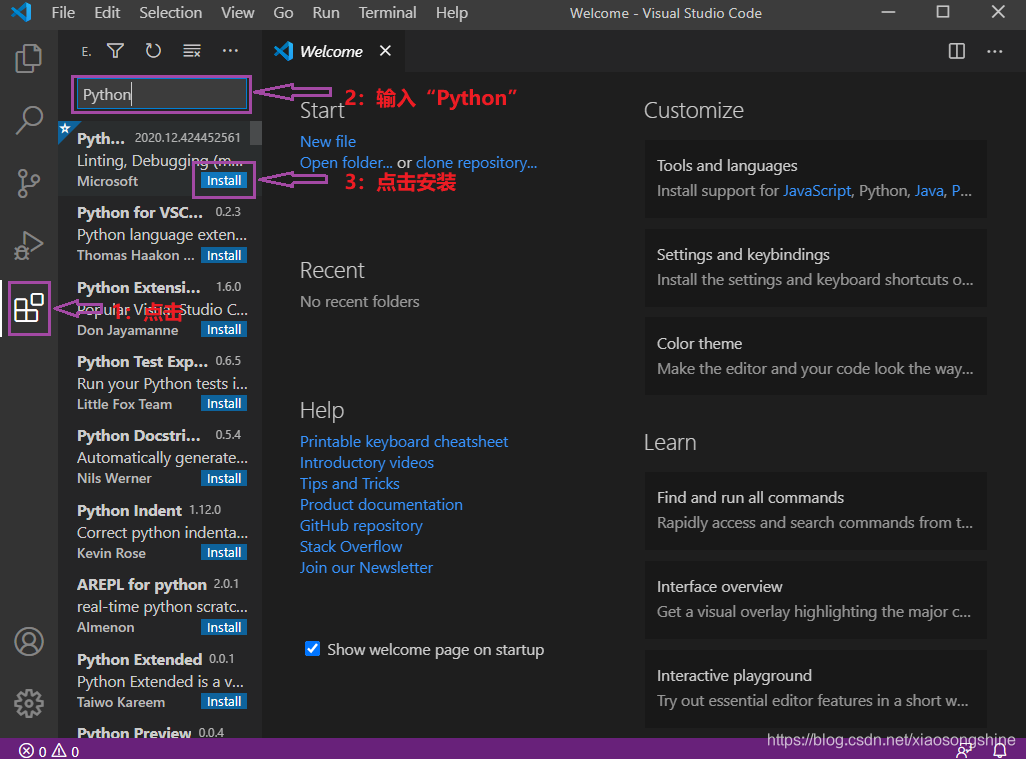
还可以用类似方法安装中文支持,输入“Chinese”,搜索安装。安装完成后重启就会准换为中文菜单了。现在 VSCode 就设置好,下面可以正式开发 Python 啦。
首先我们要搞清楚三个问题:
- VSCode 如何管理项目文件
- VSCode 如何切换使用 Python
- VSCode 如何执行 Python 文件
VSCode 如何管理项目文件
VSCode 管理项目文件是通过文件夹来管理的,下面来通过演示来说明下:可以新建一个文件夹,名称叫“demo_code”。然后通过 VSCode “打开文件夹”功能打开这个文件夹:
小宋说:当然这个文件名可以随意起,原则别用中文,因为可能导致。类似的路径也不应有中文。
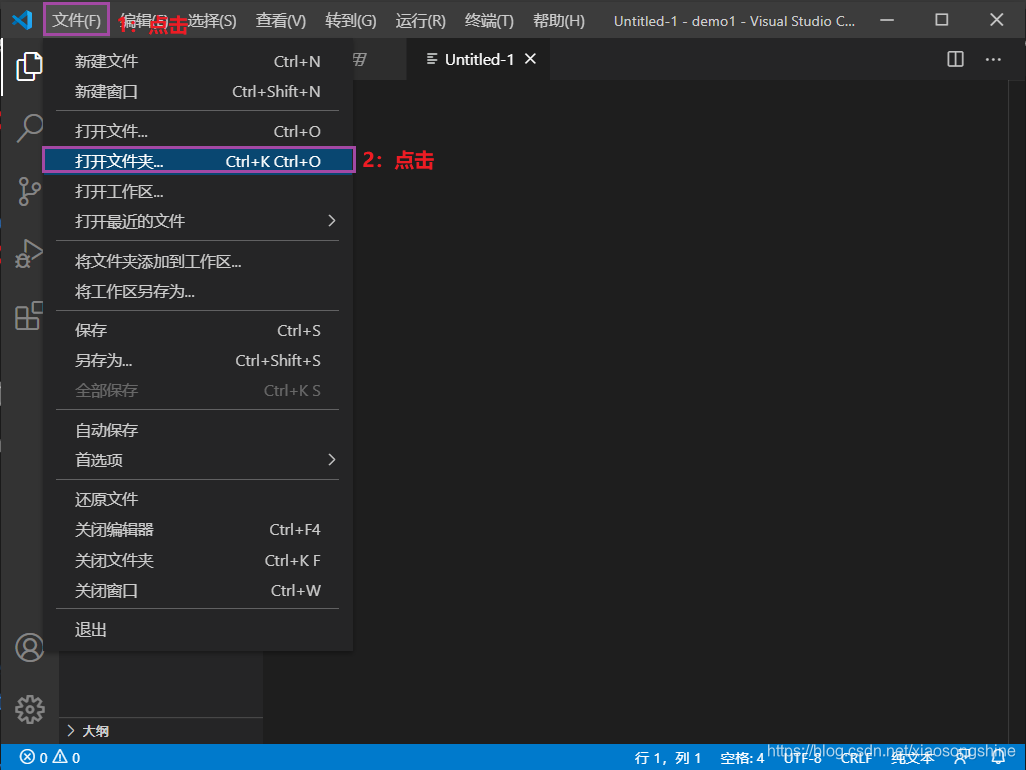
在弹出的窗口中,找到那个文件夹,选择打开即可。
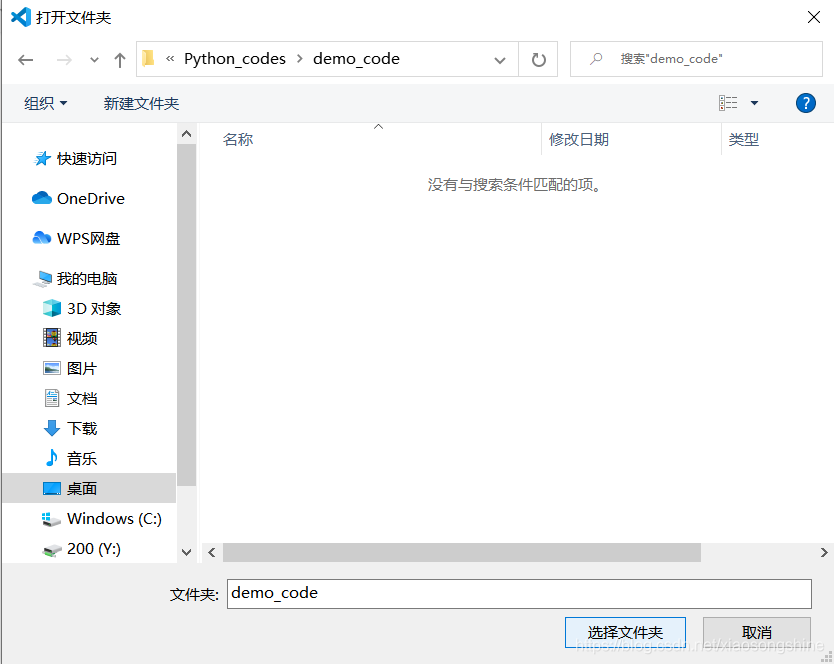
打开后,我们就可以在 VSCode 的资源管理器看到这个目录了,只是还没有文件,我们可以通过资源管理器的“新建文件”与“新建文件夹”按钮新建资源。按照下图所示,新建一个“hello.py”文件。
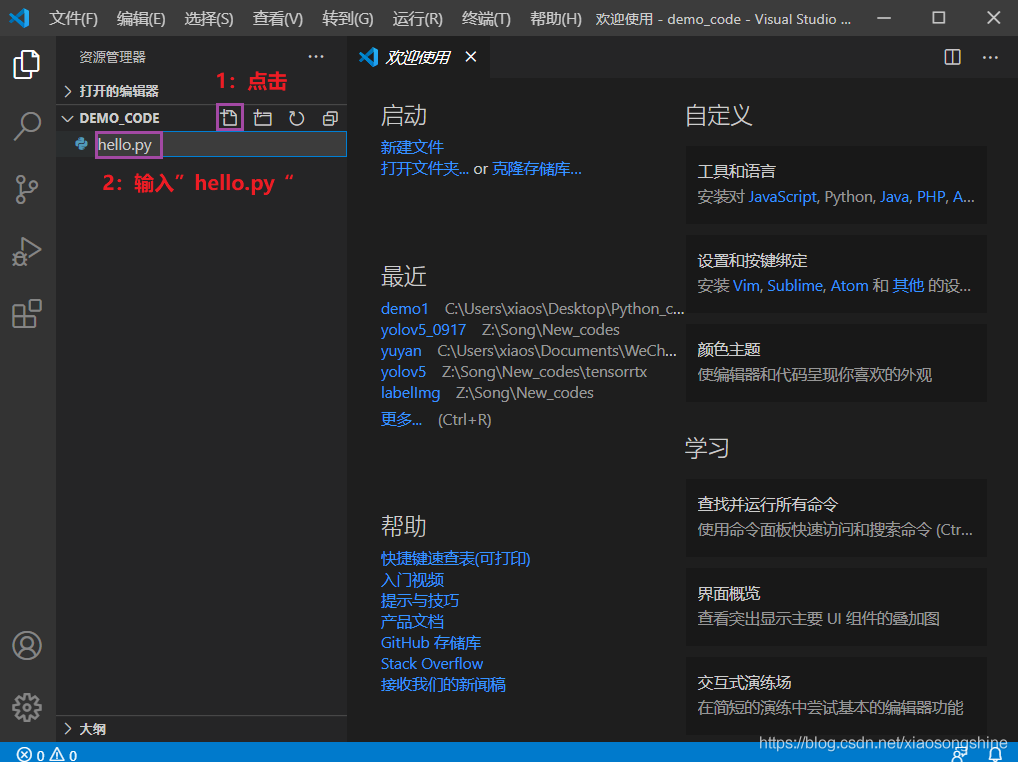
单击“hello.py”,就可以在右侧进行编辑代码了。输入第一行代码(要注意里面双引号要使用英语的符号,可以通过“Shift”键切换中英文符号):
print(“Hello Python”)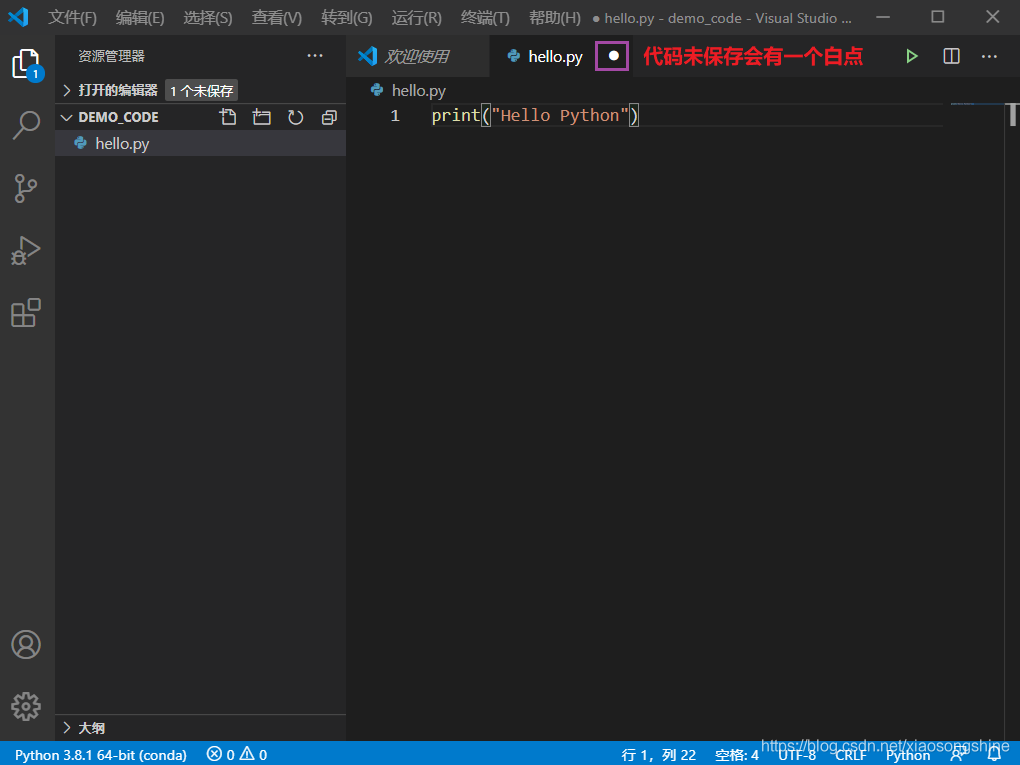
输入完成后按“Ctrl”+“s”键,保存代码。
VSCode 如何切换使用 Python
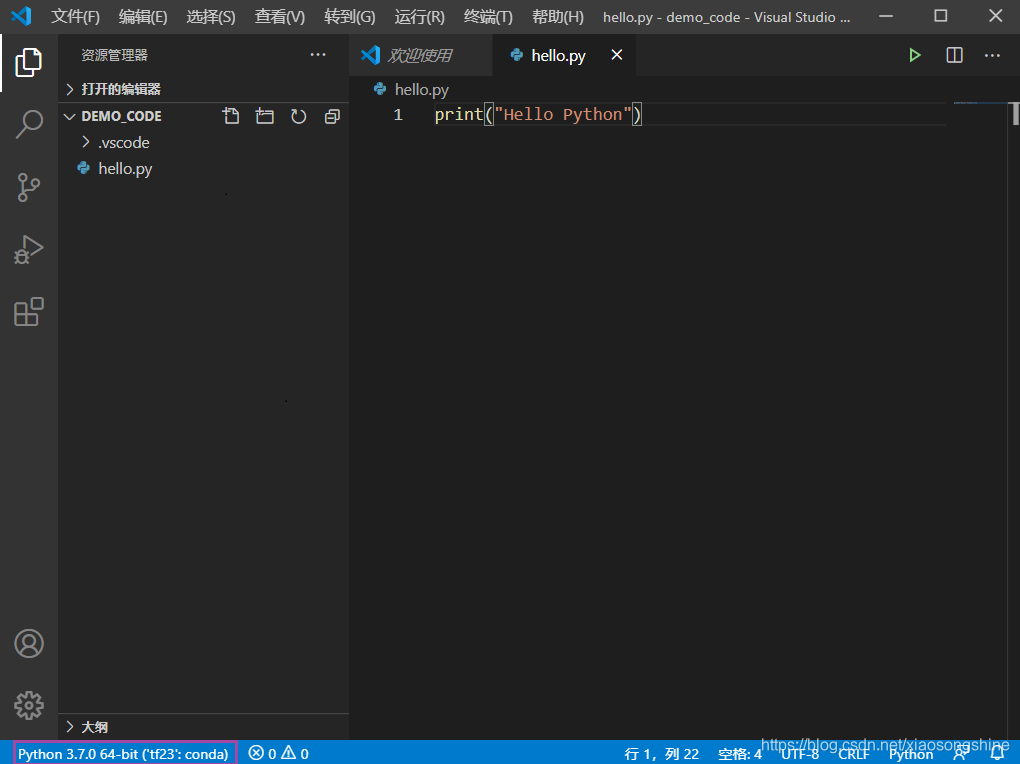
细心的小伙伴已经发现在上图界面左下角有了“Python 3.8.1 64-bit(conda)”提示,其实这个就是当前 Python 的环境,这个只有文件文件夹存在.py文件(我们新建了“hello.py”),而且安装 Python 插件后才能出现(上面已安装)。
此时就可以点击那个提示,进行 Python 环境选择与切换。
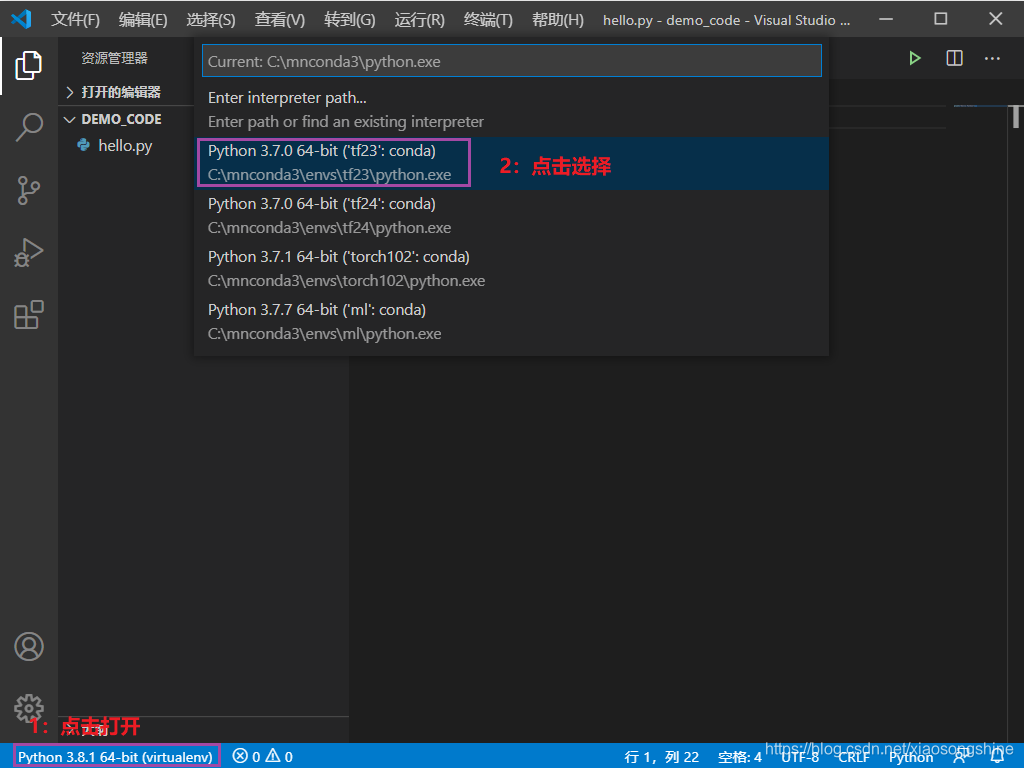
如下所示,就完成了 Python 环境切换(切换为了“tf23”):
VSCode 如何执行 Python 文件
VSCode如何管理项目文件与切换Python环境已经介绍完了,下面就是如何执行Python文件。
之前有介绍,VSCode 是编辑器,并无Python 集成开发环境,其实运行还是调用的系统安装的 Python(这里就是我们用conda安装的Python)。而Python执行的原理就是在“cmd”中python 某个.py文件。
首先我们在VSCode打开“cmd”终端,如下图所示:
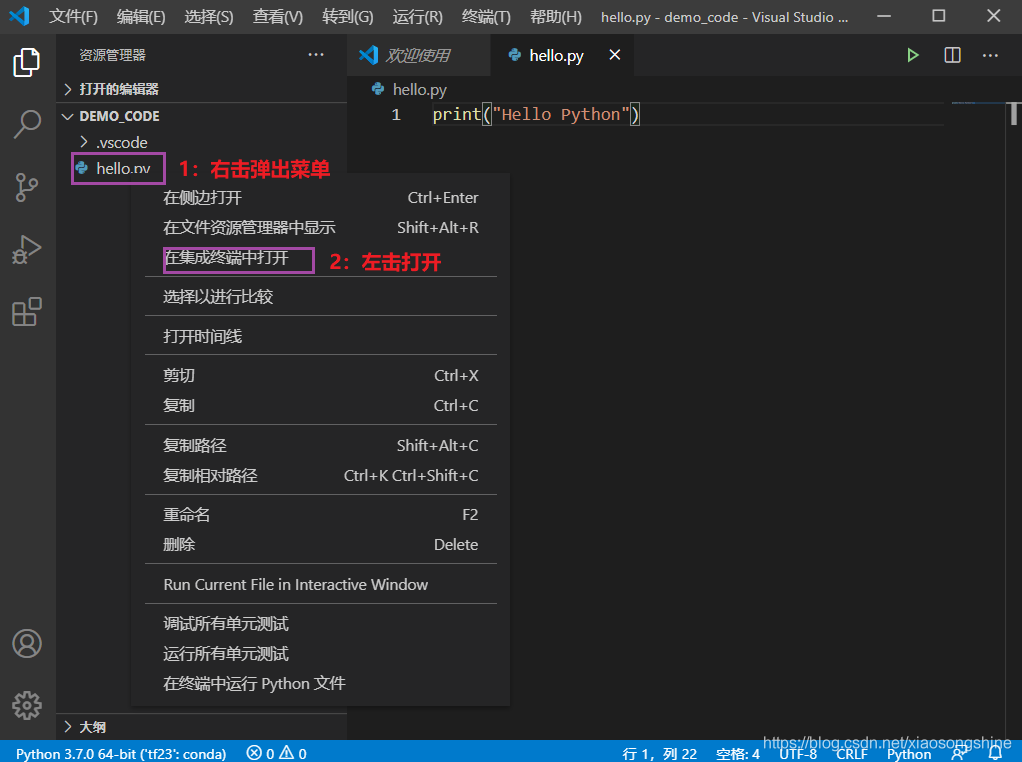
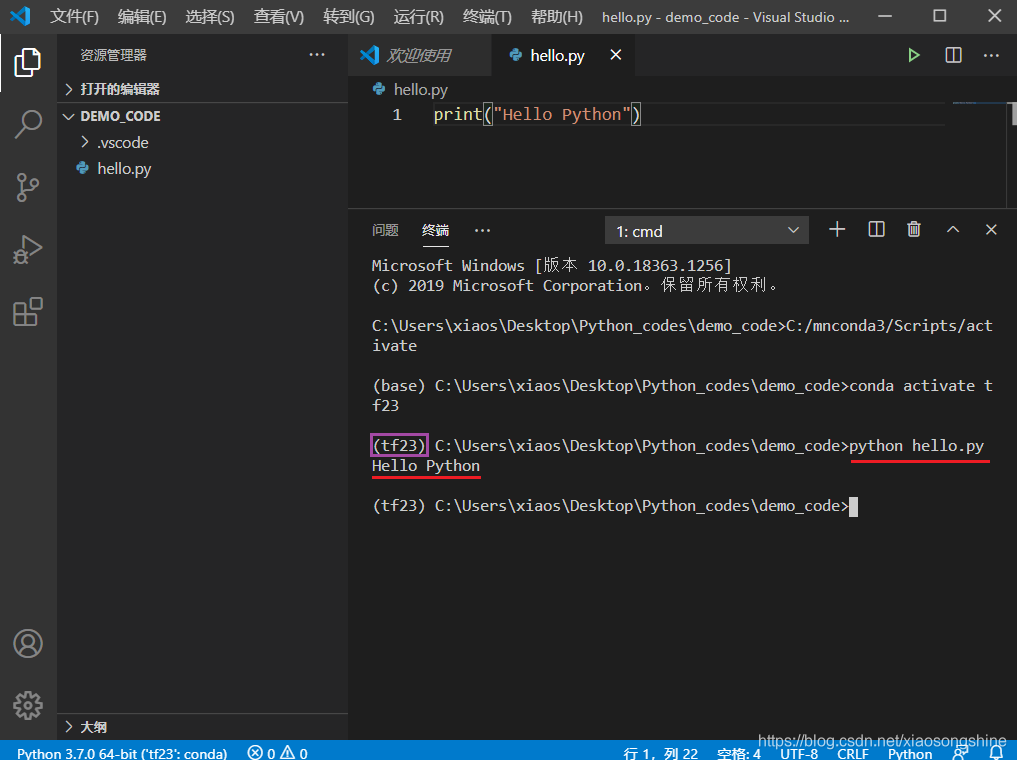
在终端中输入(如果未激活“tf23”,需要在前面加一句conda activate tf23):
python hello.py此时输出为“Hello Python”,则表示运行成功,以后再运行某个代码在此终端输入:
python x.py取消或终止运行使用“Ctrl”+“c”。
这里在对 VSCode 开发 Python 做个步骤总结:
- 用 VSCode 打开某个文件夹
- 新建 x.py 文件
- 编辑代码保存
- 选择 Python 环境,在 VSCode 终端打开并激活此环境
- 运行文件:python x.py
第一个深度学习案例运行与讲解
在上面完成了环境配置及 VSCode 使用介绍,下面将通过一个简单的深度学习案例,来引入深度学习的开发介绍。
代码参考自:《简单粗暴 TensorFlow 2》:https://mp.weixin.qq.com/mp/appmsgalbum?action=getalbum&__biz=MzU1OTMyNDcxMQ==&scene=1&album_id=1338132220393111552&count=3#wechat_redirect
数据和代码也会开源在《带你学 AI》Github中:
https://github.com/xiaosongshine/Learn2Ai4TensorFlow2
方便大家下载使用。
深度学习训练流程如下:
- 读取数据:读取数据与标签到内存中
- 数据处理迭代:将数据进行转换为网络能接受方式
- 网络搭建:构建网络模型
- 训练网络:对模型进行训练,优化参数
- 测试网络:训练完成后测试模型效果
下面就实际代码进行解释说明:
这里是做一个简单流程介绍,在第三章CNN分类项目中将做详细讲解。
读取数据:读取数据与标签到内存中
这里调用的是numpy读取mnist数据集,将文件读取到内存中。
import os
import tensorflow as tf
import numpy as np
def load_mnist_data(path='mnist.npz'):
with np.load(path, allow_pickle=True) as f:
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test']
return (x_train, y_train), (x_test, y_test)数据处理迭代:将数据进行转换为网络能接受方式
将读取到内存的训练数据进行预处理,MNIST中的图像默认为uint8(0-255的数字)。以下代码将其归一化到0-1之间的浮点数,并在最后增加一维作为颜色通道。最后通过一个随机的索引,从数据集中随机取出batch_size个元素并返回。
class MNISTLoader():
def __init__(self):
(self.train_data, self.train_label), (self.test_data, self.test_label) = load_mnist_data(path='data/mnist.npz')
# MNIST中的图像默认为uint8(0-255的数字)。以下代码将其归一化到0-1之间的浮点数,并在最后增加一维作为颜色通道
self.train_data = np.expand_dims(self.train_data.astype(np.float32) / 255.0, axis=-1) # [60000, 28, 28, 1]
self.test_data = np.expand_dims(self.test_data.astype(np.float32) / 255.0, axis=-1) # [10000, 28, 28, 1]
self.train_label = self.train_label.astype(np.int32) # [60000]
self.test_label = self.test_label.astype(np.int32) # [10000]
self.num_train_data, self.num_test_data = self.train_data.shape[0], self.test_data.shape[0]
def get_batch(self, batch_size):
# 从数据集中随机取出batch_size个元素并返回
index = np.random.randint(0, self.num_train_data, batch_size)
return self.train_data[index, :], self.train_label[index]网络搭建:构建网络模型
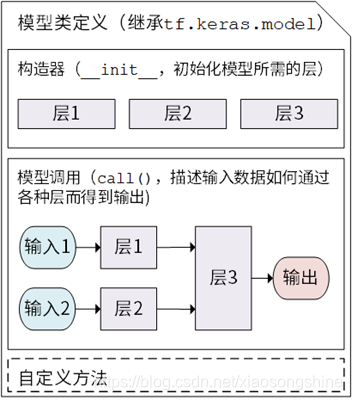
构建网络这里使用的方法是继承tf.keras.Model,可以通过继承 tf.keras.Model 这个 Python 类来定义自己的模型。在继承类中,我们需要重写 __init__() (构造函数,初始化)和 call(input) (模型调用)两个方法,同时也可以根据需要增加自定义的方法。
class MLP(tf.keras.Model):
def __init__(self):
super().__init__()
self.flatten = tf.keras.layers.Flatten() # Flatten层将除第一维(batch_size)以外的维度展平
self.dense1 = tf.keras.layers.Dense(units=100, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs): # [batch_size, 28, 28, 1]
#print("input shape: ",inputs.shape)
x = self.flatten(inputs) # [batch_size, 784]
#print("flatten shape: ",x.shape)
x = self.dense1(x) # [batch_size, 100]
#print("dense1 shape: ",x.shape)
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output可以看到,最后这里使用的是softmax激活函数,这是因为我们希望输出 “输入图片分别属于 0 到 9 的概率”,也就是一个 10 维的离散概率分布,所以我们希望这个 10 维向量至少满足两个条件:
1. 该向量中的每个元素均在 [0, 1] 之间;
2. 该向量的所有元素之和为 1。
为了使得模型的输出能始终满足这两个条件,我们使用 Softmax 函数 (归一化指数函数, tf.nn.softmax )对模型的原始输出进行归一化。softmax 函数能够凸显原始向量中最大的值,并抑制远低于最大值的其他分量,这也是该函数被称作 softmax 函数的原因(即平滑化的 argmax 函数)。
训练网络:对模型进行训练,优化参数
这里的功能是设置一些超参数与实例化模型、数据迭代器和优化器。然后按照以下步骤进行迭代优化:
1. 从 DataLoader 中随机取一批训练数据;
2. 将这批数据送入模型,计算出模型的预测值;
3. 将模型预测值与真实值进行比较,计算损失函数(loss)。这里使用 tf.keras.losses 中的交叉熵函数作为损失函数;
4. 计算损失函数关于模型变量的导数;
5. 将求出的导数值传入优化器,使用优化器的 apply_gradients 方法更新模型参数以最小化损失函数
num_epochs = 5
batch_size = 50
learning_rate = 0.001
model = MLP()
data_loader = MNISTLoader()
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
num_batches = int(data_loader.num_train_data // batch_size * num_epochs)
for batch_index in range(num_batches):
X, y = data_loader.get_batch(batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
测试网络:训练完成后测试模型效果
最后是对模型进行评估,使用测试集评估模型的性能:
使用 tf.keras.metrics 中的 SparseCategoricalAccuracy 评估器来评估模型在测试集上的性能,该评估器能够对模型预测的结果与真实结果进行比较,并输出预测正确的样本数占总样本数的比例。我们迭代测试数据集,每次通过 update_state() 方法向评估器输入两个参数: y_pred 和 y_true ,即模型预测出的结果和真实结果。评估器具有内部变量来保存当前评估指标相关的参数数值(例如当前已传入的累计样本数和当前预测正确的样本数)。迭代结束后,我们使用 result() 方法输出最终的评估指标值(预测正确的样本数占总样本数的比例)。
在以下代码中,我们实例化了一个 tf.keras.metrics.SparseCategoricalAccuracy 评估器,并使用 For 循环迭代分批次传入了测试集数据的预测结果与真实结果,并输出训练后的模型在测试数据集上的准确率。
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
num_batches = int(data_loader.num_test_data // batch_size)
for batch_index in range(num_batches):
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model.predict(data_loader.test_data[start_index: end_index])
sparse_categorical_accuracy.update_state(y_true=data_loader.test_label[start_index: end_index], y_pred=y_pred)
print("test accuracy: %f" % sparse_categorical_accuracy.result())
训练输入结果:
...
batch 5990: loss 0.025840
batch 5991: loss 0.056399
batch 5992: loss 0.037003
batch 5993: loss 0.064870
batch 5994: loss 0.033622
batch 5995: loss 0.034460
batch 5996: loss 0.112375
batch 5997: loss 0.030268
batch 5998: loss 0.050687
batch 5999: loss 0.080279
test accuracy: 0.971800
附加内容:Github简单使用方法
小宋说:在上篇文章中,读者反响还是很热烈的。其中有一个评论“技术扶贫”,虽然不一定准确,的确挺贴切的。大家的支持也是是我继续坚持做下去的动力。随意小宋会继续以接地气的方法与带大家分析经验与技术。
为了让大家顺利使用上面示例代码,这里简单演示一下Github的使用,一步步带大家跑起来代码。其他Github开源代码也可以类似使用。
这里的演示使用下载的方式,不用下载“git”软件整体步骤也很简单:
- 打开Github链接
- 下载代码与数据
- 使用VSCode打开运行
打开开源链接
在浏览器打开开源链接:https://github.com/xiaosongshine/Learn2Ai4TensorFlow2

打开界面如上,右上角有三个小按钮:“Watch”、“Star”、“Fork”。
- “Watch”:可以理解为关注这个项目,打开选择“All Activity”有什么更新内容会通知。
- “Star”:就是收藏这个项目,方便以后查找使用
- “Fork”:这个功能就是把项目复制到自己Github账号下,可以自由修改使用
在用这些功能时必须要登录Github账号,没有的话需要注册一下很简单这里就不介绍了。
小宋说:小宋感觉这里挺像B站“一键三连”呢,觉得小宋的这个项目有用记得三连支持一下啦(“Watch”、“Star”、“Fork”:)
下载项目
下面介绍一个重要功能:如何下载项目
如下图所示,1:点击“Code”,2:点击“Download ZIP”。

此时整个项目就会打包下载 。
小宋说:由于Github网路不稳定,可能会导致下载失败。大家也可以关注小宋公众号“极简AI”,回复“源码”,我会把源码发给大家。
运行项目
下载完成后,进行解压,解压后用VSCode打开此文件夹:
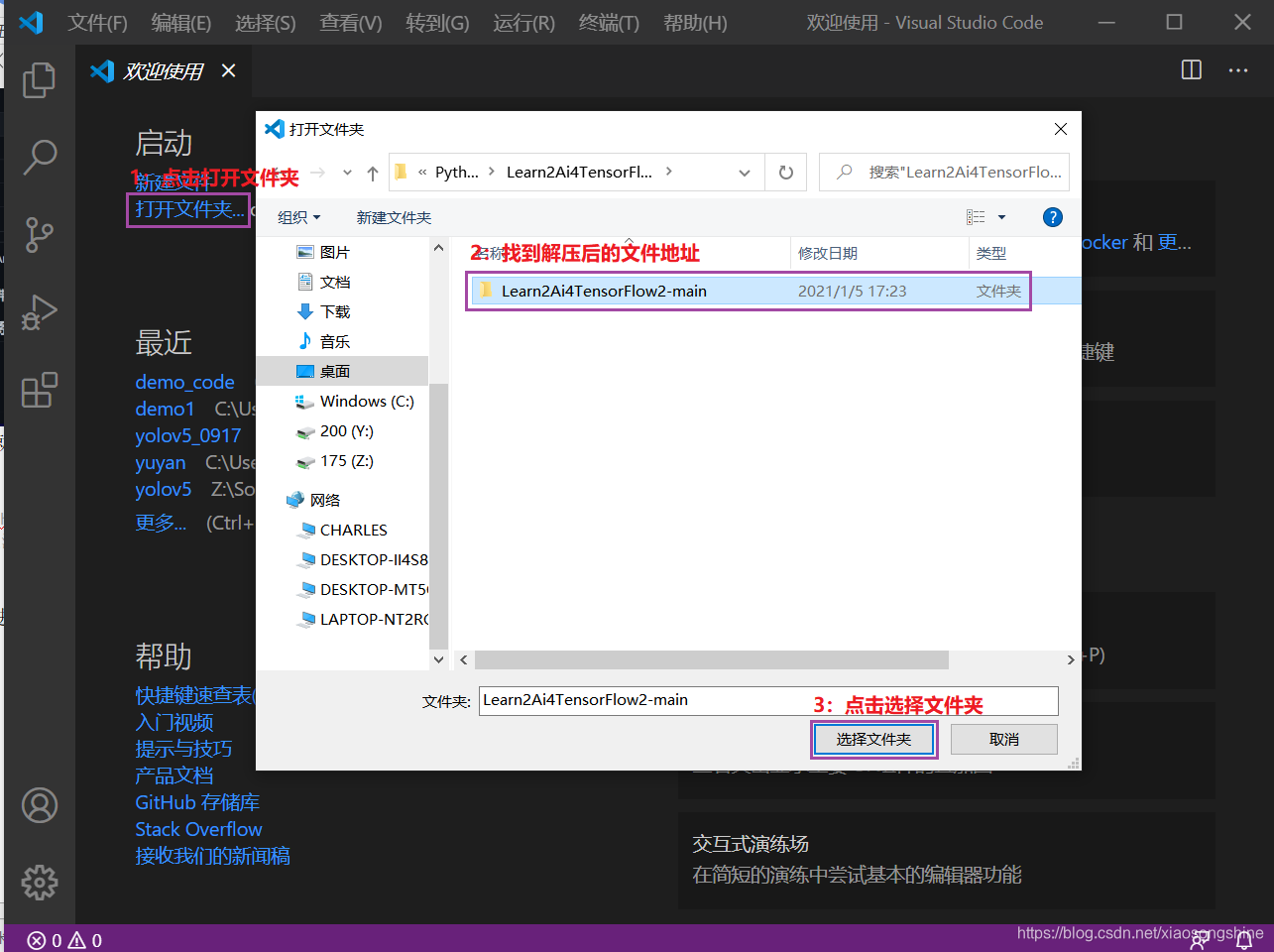
然后就是选择Python,在选择Python时,需要打开一个.py文件,出现下方Python环境信息:
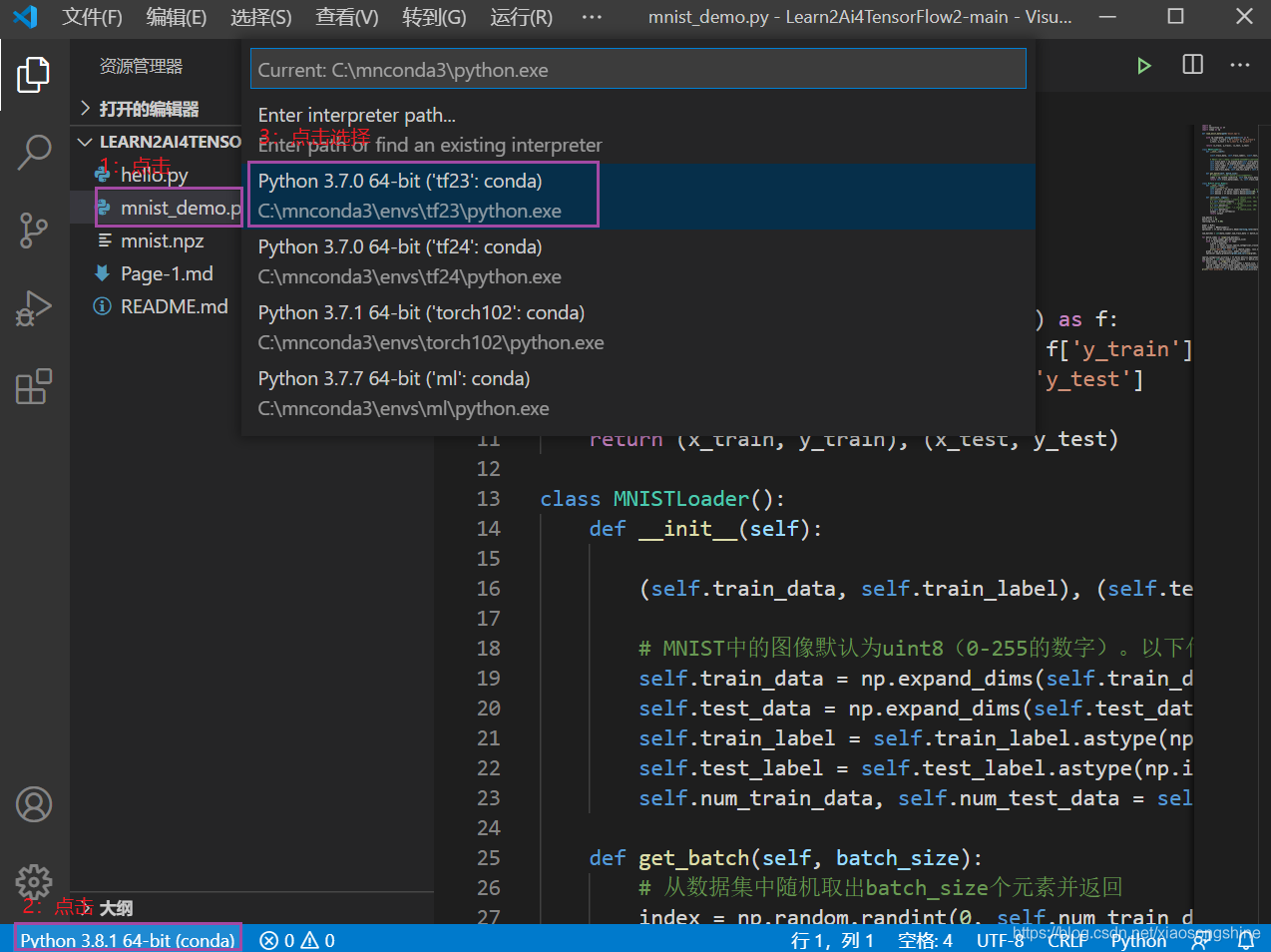
最后一步就是运行(忘记了的同学翻一下上面对VSCode使用介绍):
运行结果如下:

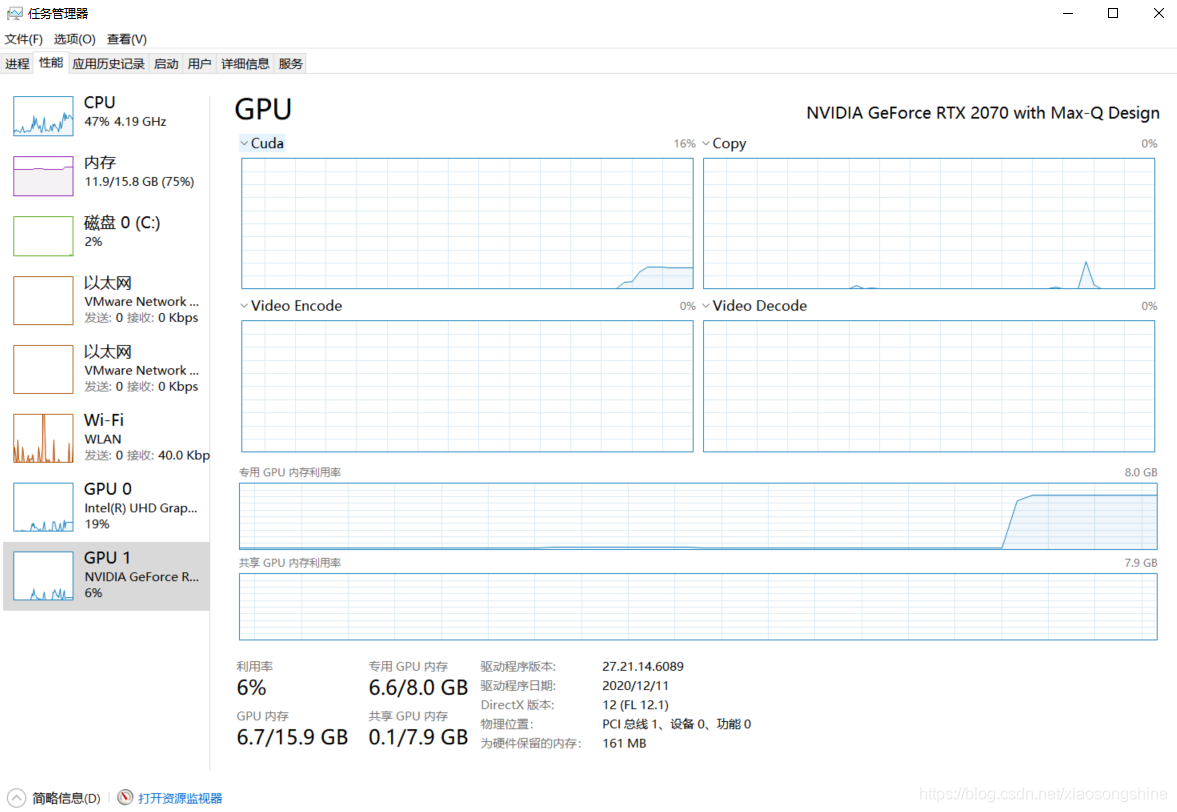
运行过程,我们可以使用“资源管理器”里的“性能”功能,监控运行GPU与CPU及内存占用率。
尾巴
在本文中讲解了开发环境配置,由于是图解流程会有很多图片,故将分为上下两篇,分别讲解Windows10与Ubuntu18。在本篇文章中,详细讲解 Windows 系统开发环境配置,包括 CPU 与 GPU 深度学习环境的配置与 VSCode 开发 Python 方法及 Python 简单使用。最后通过对一个深度学习案例运行与讲解,一步步带大家使用 Windows 10 平台搭建出深度学习开发环境,能让大家开始动手实践。
在下篇中将分享在 Ubuntu 18 中环境的配置与使用说明,不见不散。
Keep Fighting。。。
留言与问题回复
小宋说:这个模块汇总了一些小伙伴的留言与问题,小宋在这里统一回复下。
留言一:“想问下m1芯片Mac电脑的tensorflow好像有buf加成,就是安装麻烦,有教学吗?”
回复一:这个问题小宋简单去查了一下,TensorFlow2.4版本针对Mac电脑做了优化,相较于TensorFlow2.3或者Intel版本Mac都有大幅提升,参考:
https://mp.weixin.qq.com/s/fX5GpVKM6dOJECwhDTe06Q
由于这个功能还未在TensorFlow正式版发布,安装会有些麻烦。后面如果具备这个功能正式版发布后,小宋会在第一时间更新一个针对m1芯片Mac安装教程分享(挖个小坑:)。
针对想要尝鲜的小伙伴,小宋找到了一个解决方法,可以尝试下:
https://www.jianshu.com/p/7d27a53e3a5e
留言二:“大佬,我想请教个问题哈,30系列显卡不能安装TensorFlow GPU版本的么?有没有想过的教程,我的是3070显卡,一直安装TensorFlow GPU版本不成功?【安装之后无法使用】”
回复二:答案是肯定的,刚好我本人最近配置了一个3090显卡的深度学习环境,区别就是最开始选择NVIDIA驱动时需要选择对应的30系列显卡:
https://www.nvidia.com/Download/index.aspx?lang=cn#,进行下载和安装。其实安装cudatoolkit、cudnn与TensorFlowGPU步骤和本文上面都类似的。

如果是Ubuntu版本安装,可以等一下系列下一篇文章:一步步带你在Ubuntu18平台开发深度学习,也会很本文一样细致入微。已经完成了试验和素材部分周末会完善所有内容。
欢迎大家关注小宋公众号《极简AI》带你学深度学习:关注后回复“源码”,我会把源码与Github链接发给大家。
这里收集了一些比较适合入门实战的PDF书籍,《简单粗暴TensorFlow2最新中文版》
关注后,回复:书籍,领取。
基于深度学习的理论学习与应用开发技术分享,笔者会经常分享深度学习干货内容,大家在学习或者应用深度学习时,遇到什么问题也可以与我在上面交流知无不答。
出自CSDN博客专家&知乎深度学习专栏作家@小宋是呢

——————————————————————————————————
本文由 TensorFlow 社区作者创作,文章已入选 “TensorFlow 开发者出道计划” 精选推荐,关注 TensorFlow 社区,参与社区共建,点击这里了解更多。 全能社区,一起建设!