目录

1. Hadoop HDFS:(Hadoop Distribute File System )
HADOOP框架
大数据技术解决的是什什么问题?
大数据技术解决的主要是海海量量数据的存储和计算。
Hadoop的⼴广义和狭义之分
狭义的Hadoop: 指的是⼀一个框架,Hadoop是由三部分组成:
HDFS:分布式⽂文件系统--》存储;
MapReduce: 分布式离线计算框架--》计算;
Yarn: 资源调度框架
广义的Hadoop: 广义Hadoop是不不仅仅包含Hadoop框架,除了了Hadoop框架之外还有⼀一些辅助框架。
Flume:日志数据采集,
Sqoop:关系型数据库数据的采集;
Hive: 深度依赖Hadoop框架完成计算(sql),
Hbase: 大数据领域的数据库(mysql)
Sqoop:数据的导出
广义Hadoop指的是⼀一个生态圈。
第一部分 大数据简介
第 1 节 大数据的定义
大数据是指无法在⼀一定时间范围内用常规软件工具进⾏行行捕捉、管理理和处理理的数据集合,是需要新处理理模式才能具有更更强的决策力、洞洞察发现⼒力力和流程优化能⼒力力的海海量量、⾼高增⻓长率和多样化的信息资产。
第 2 节 ⼤大数据的特点
大数据的特点可以⽤用 IBM 曾经提出的 “5V” 来描述,如下:

⼤量
采集、存储和计算的数据量都⾮常⼤。
计算机存储单位⼀般⽤B,KB,MB,GB,TB,PB,EB,ZB,YB,BB、NB、DB来表示,它们之间的关系是
1GB = 1024 MB 1TB = 1024 GB
1PB = 1024 TB 1EB = 1024 PB
1ZB = 1024 EB 1YB = 1024 ZB 1BB = 1024 YB
1NB = 1024 BB
1DB = 1024 NB
以PB为例,PB级数据量有多⼤?是怎样的⼀个概念?
假如⼿机播放MP3的速度为平均每分钟1MB,⽽1⾸歌曲的平均时⻓为4分钟,那么1PB存量的歌曲可以连续播放2000年。
1PB 也相当于50%的全美学术研究图书馆藏书咨询内容。
(1)1986年,全球只有0.02EB也就是约21000TB的数据量
(2)2007年,全球就是280EB也就是约300000000TB的数据量,翻了14000倍
(3)近些年,由于移动互联⽹及物联⽹的出现,各种终端设备的接⼊,各种业务形式的普及,平均每40个⽉,全球的数据量就会翻倍!2012年,每天会产⽣2.5EB的数据量
(4)基于IDC的报告预测,从2013年到2020年,全球数据量会从4.4ZB猛增到44ZB!⽽到了2025年,全球会有163ZB的数据量!
全球的数据量已经⼤到爆了!⽽传统的关系型数据库根本处理不了如此海量的数据!
⾼速
在⼤数据时代,数据的创建、存储、分析都要求被⾼速处理,⽐如电商⽹站的个性化推荐尽可能要
求实时完成推荐,这也是⼤数据区别于传统数据挖掘的显著特征。
多样
数据形式和来源多样化。包括结构化、半结构化和⾮结构化数据,具体表现为⽹络⽇志、⾳频、视
频、图⽚、地理位置信息等等,多类型的数据对数据的处理能⼒提出了更⾼的要求。
真实
确保数据的真实性,才能保证数据分析的正确性
低价值
数据价值密度相对较低,或者说是浪⾥淘沙却⼜弥⾜珍贵。互联⽹发展催⽣了⼤量数据,信息海
量,但价值密度较低,如何结合业务逻辑并通过强⼤的机器算法来挖掘数据价值,是⼤数据时代最
需要解决的问题,也是⼀个有难度的课题。
第 3 节 ⼤数据的应⽤场景
随着⼤数据的发展,⼤数据技术已经⼴泛应⽤在众多⾏业,⽐如仓储物流、电商零售、汽⻋、电信、⽣物医学、⼈⼯智能、智慧城市等等领域,包括在疫情防控战中,⼤数据技术也发挥了重要的作⽤。
仓储物流
⼤数据技术驱动了仓储物流领域的智能化发展,以苏宁为例,苏宁物流可在全国的各级仓库间实现智能分仓、就近备货和预测式调拨,实现”客户需要的商品就在离客户最近的配送中⼼“。

电商零售
零售业 ” 啤酒+纸尿裤 “ 案例

个性推荐

” 双11购物节 “ 实时销售额⼤屏

汽⻋
利⽤了⼤数据和物联⽹技术的⽆⼈驾驶汽⻋,在不远的未来将⾛⼊我们的⽇常

电信
移动联通根据⽤户年龄、职业、消费情况,分析统计哪种套餐适合哪类⼈群,对市场⼈群精准定位
⽣物医学
⼤数据可以帮助我们实现流⾏病预测、智慧医疗、健康管理,同时还可以帮助我们解读DNA,了解更多的⽣命奥秘。⽐如影像⼤数据⽀撑下的早期肺癌⽀撑平台,基于⼤量病例数据样本,制定早期肺癌⾼危⼈群预警指
⼈⼯智能
智慧城市
⼤数据有效⽀撑智慧城市发展,成为城市的”数据⼤脑“。⽐如,在智慧城市建设上,杭州始终⾛在全国前列。如覆盖⾯⼴的移动⽀付、新颖的在线医疗模式、创新的物流运输模式,都受到较⼤关注。2016年,杭州被《中国新型智慧城市》⽩⽪书评为“中国最智慧的城市”。
⼤数据的价值,远远不⽌于此,⼤数据对各⾏各业的渗透,⼤⼤推动了社会⽣产和⽣活,未来必将产⽣重⼤⽽深远的影响。
第 4 节 ⼤数据的发展趋势及职业路线
4.1 ⼤数据发展趋势
1)2015年党的⼗⼋届五中全会提出“实施国家⼤数据战略”,国务院印发《促进⼤数据发展⾏动纲要》,⼤数据技术和应⽤处于创新突破期,国内市场需求处于爆发期,我国⼤数据产业⾯临重要的发展机遇。
2)2017年⼗九⼤报告明确 "推动互联⽹、⼤数据、⼈⼯智能和实体经济深度融合"。
3)2020年全国政协⼗三届三次会议新闻发布会上,更进⼀步强调:⼤数据、⼈⼯智能、5G是引领未来发展的战略性技术。
显然,发展⼤数据是我国的战略性决策,前景⾃然不⾔⽽喻。
另外
4)2017年北京⼤学、中国⼈⺠⼤学、北京邮电⼤学等25所⾼校成功申请开设⼤数据课程
5)⼤数据属于⾼新技术,⼤⽜少,升职竞争⼩
6)2020年5⽉6⽇,⼈⼒资源和社会保障部发布《新职业—⼤数据⼯程技术⼈员就业景⽓现状分析报告》,报告显示:预计2020年中国⼤数据⾏业⼈才需求规模将达210万,2025年前⼤数据⼈才需求仍将保持30%~40%的增速,需求总量在2000万⼈左右
7)在北京⼤数据开发⼯程师的平均薪⽔已经超越 1.5w 直逼2w,⽽且⽬前还保持强劲的发展势头4.2 ⼤数据职业发展路⽬前⼤数据⾼、中、低三个档次的⼈才都很缺。 现在我们谈⼤数据,就像当年谈电商⼀样,未来前景已经很明确,接下来就是优胜劣汰,竞争上岗。不想当架构师的程序员不是好架构师!但是,⼤数据发展到现阶段,涉及⼤数据相关的职业岗位也越来越精细。从职业发展来看,由⼤数据开发、挖掘、算法、到架构。从级别来看,从⼯程师、⾼级⼯程师,再到架构师,甚⾄到科学家。⽽且,契合不同的⾏业领域,⼜有专属于这些⾏业的岗位衍⽣,如涉及⾦融领域的数据分析师等。⼤数据的相关⼯作岗位有很多,有数据分析师、数据挖掘⼯程师、⼤数据开发⼯程师、⼤数据产品经理、可视化⼯程师、爬⾍⼯程师、⼤数据运营经理、⼤数据架构师、数据科学家等等。
从事岗位:ETL⼯程师,数据仓库⼯程师,实时流处理⼯程师,⽤户画像⼯程师,数据挖掘,算法⼯程师,推荐系统⼯程。
第⼆部分 Hadoop简介
第 1 节 什么是Hadoop
Hadoop 是⼀个适合⼤数据的分布式存储和计算平台。
如前所述,ሀ义上说Hadoop就是⼀个框架平台,⼴义上讲Hadoop代表⼤数据的⼀个技术⽣态圈,包括很多其他软件框架

第 2 节 Hadoop的起源
Hadoop 的发展历程可以⽤如下过程概述:
Nutch —> Google论⽂(GFS、MapReduce)—> Hadoop产⽣—> 成为Apache顶级项⽬
—> Cloudera公司成⽴(Hadoop快速发展)
Hadoop最早起源于Nutch,Nutch 的创始⼈是Doug Cutting
Nutch 是⼀个开源 Java 实现的搜索引擎。它提供了我们运⾏⾃⼰的搜索引擎所需的全部⼯具。包括全⽂搜索和Web爬⾍,但随着抓取⽹⻚数量的增加,遇到了严重的可扩展性问题——如何解决数⼗亿⽹⻚的存储和索引问题
2003年、2004年⾕歌发表的两篇论⽂为该问题提供了可⾏的解决⽅案。GFS,可⽤于处理海量⽹⻚的存储;MapReduce,可⽤于处理海量⽹⻚的索引计算问题。
Google的三篇论⽂(三驾⻢⻋)
GFS:Google的分布式⽂件系统(Google File System)
MapReduce:Google的分布式计算框架
BigTable:⼤型分布式数据库
发展演变关系:
GFS —> HDFS
Google MapReduce —> Hadoop MapReduce
BigTable —> HBase
随后,Google公布了部分GFS和MapReduce思想的细节,Doug Cutting等⼈⽤2年的业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。
2005年,Hadoop 作为Lucene的⼦项⽬Nutch的⼀部分引⼊Apache
2006年,Hadoop从Nutch剥离出独⽴
2008年,Hadoop成为Apache的顶级项⽬
Hadoop这个名字来源于Hadoop之⽗Doug Cutting⼉⼦的⽑绒玩具

第 3 节 Hadoop的特点

第 4 节 Hadoop的发⾏版本
⽬前Hadoop发⾏版⾮常多,有Cloudera发⾏版(CDH)、Hortonworks发⾏版、华为发⾏版、Intel发⾏版等,所有这些发⾏版均是基于Apache Hadoop衍⽣出来的,之所以有这么多的版本,是由Apache Hadoop的开源协议决定的(任何⼈可以对其进⾏修改,并作为开源或商业产品发布/销售)。
企业中主要⽤到的三个版本分别是:
Apache Hadoop版本(最原始的,所有发⾏版均基于这个版本进⾏改进)、
Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称“CDH”)、
Hortonworks版本(Hortonworks Data Platform,简称“HDP”)。
Apache Hadoop 原始版本
官⽹地址:http://hadoop.apache.org/
优点:拥有全世界的开源贡献,代码更新版本⽐较快
缺点:版本的升级,版本的维护,以及版本之间的兼容性,学习⾮常⽅便
Apache所有软件的下载地址(包括各种历史版本):http://archive.apache.org/dist/
软件收费版本ClouderaManager CDH版本 --⽣产环境使⽤
官⽹地址:https://www.cloudera.com/
Cloudera主要是美国⼀家⼤数据公司在Apache开源Hadoop的版本上,通过⾃⼰公司内部的各种补丁,实现版本之间的稳定运⾏,⼤数据⽣态圈的各个版本的软件都提供了对应的版本,解决了版本的升级困难,版本兼容性等各种问题,⽣产环境强烈推荐使⽤
免费开源版本HortonWorks HDP版本--⽣产环境使⽤
官⽹地址:https://hortonworks.com/ hortonworks主要是雅⻁主导Hadoop开发的副总裁,带领⼆⼗⼏个核⼼成员成⽴Hortonworks,核⼼产品软件HDP(ambari),HDF免费开源,并且提供⼀整套的web管理界⾯,供我们可以通过web界⾯管理我们的集群状态,web管理界⾯软件HDF⽹址(http://ambari.apache.org/)
第 5 节 Apache Hadoop版本更迭
0.x 系列版本:Hadoop当中最早的⼀个开源版本,在此基础上演变⽽来的1.x以及2.x的版本
1.x 版本系列:Hadoop版本当中的第⼆代开源版本,主要修复0.x版本的⼀些bug等
2.x 版本系列:架构产⽣重⼤变化,引⼊了yarn平台等许多新特性
3.x 版本系列:EC技术、YARN的时间轴服务等新

第 6 节 Hadoop的优缺点
Hadoop的优点
Hadoop具有存储和处理数据能⼒的⾼可靠性。
Hadoop通过可⽤的计算机集群分配数据,完成存储和计算任务,这些集群可以⽅便地扩展到数以千计的节点中,具有⾼扩展性。
Hadoop能够在节点之间进⾏动态地移动数据,并保证各个节点的动态平衡,处理速度⾮常快,具有⾼效性。
Hadoop能够⾃动保存数据的多个副本,并且能够⾃动将失败的任务重新分配,具有⾼容错性。
Hadoop的缺点
Hadoop不适⽤于低延迟数据访问。
Hadoop不能⾼效存储⼤量⼩⽂件。
Hadoop不⽀持多⽤户写⼊并任意修改⽂件。
第三部分 Apache Hadoop的重要组成
Hadoop=HDFS(分布式⽂件系统)+MapReduce(分布式计算框架)+Yarn(资源协调框架)+Common模块
1. Hadoop HDFS:(Hadoop Distribute File System )
⼀个⾼可靠、⾼吞吐量的分布式⽂件系统
⽐如:100T数据存储,
“分⽽治之”
分:拆分--》数据切割,100T数据拆分为10G⼀个数据块由⼀个电脑节点存储这个数据块。数据切割、制作副本、分散储存

图中涉及到⼏个⻆⾊
NameNode(nn):存储⽂件的元数据,⽐如⽂件名、⽂件⽬录结构、⽂件属性(⽣成时间、副本数、⽂件权限),以及每个⽂件的块列表和块所在的DataNode等。
SecondaryNameNode(2nn):辅助NameNode更好的⼯作,⽤来监控HDFS状态的辅助后台程序,每隔⼀段时间获取HDFS元数据快照。
DataNode(dn):在本地⽂件系统存储⽂件块数据,以及块数据的校验
注意:NN,2NN,DN这些既是⻆⾊名称,进程名称,代指电脑节点名称!!
2. Hadoop MapReduce:
⼀个分布式的离线并⾏计算框架
拆解任务、分散处理、汇整结果
MapReduce计算 = Map阶段 + Reduce阶段
Map阶段就是“分”的阶段,并⾏处理输⼊数据;
Reduce阶段就是“合”的阶段,对Map阶段结果进⾏汇总

3. Hadoop YARN:
作业调度与集群资源管理的框架
计算资源协调

Yarn中有如下⼏个主要⻆⾊,同样,既是⻆⾊名、也是进程名,也指代所在计算机节点名称。
ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
NodeManager(nm):单个节点上的资源管理、处理来⾃ResourceManager的命令、处理来⾃ApplicationMaster的命令;
ApplicationMaster(am):数据切分、为应⽤程序申请资源,并分配给内部任务、任务监控与容错。
Container:对任务运⾏环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运⾏相关的信息。
ResourceManager是⽼⼤,NodeManager是⼩弟,ApplicationMaster是计算任务专员

4. Hadoop Common:
⽀持其他模块的⼯具模块(Configuration、RPC、序列化机制、⽇志操作)
第四部分 Apache Hadoop 完全分布式集群搭
搭建软件和操作系统版本
Hadoop框架是采⽤Java语⾔编写,需要java环境(jvm)
JDK版本:JDK8版本
集群:
知识点学习:统⼀使⽤vmware虚拟机虚拟三台linux节点,linux操作系统:Centos7
项⽬阶段:统⼀使⽤云服务器,5台云服务器节点
Hadoop搭建⽅式
单机模式:单节点模式,⾮集群,⽣产不会使⽤这种⽅式
单机伪分布式模式:单节点,多线程模拟集群的效果,⽣产不会使⽤这种⽅式
完全分布式模式:多台节点,真正的分布式Hadoop集群的搭建(⽣产环境建议使⽤这种⽅式)
第 1 节 虚拟机环境准备
1. 三台虚拟机(静态IP,关闭防⽕墙,修改主机名,配置免密登录,集群时间同步)
2. 在/opt⽬录下创建⽂件夹
mkdir -p /opt/lagou/software --软件安装包存放⽬录
mkdir -p /opt/lagou/servers --软件安装⽬录3. Hadoop下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-2.9.2/
Hadoop官⽹地址:http://hadoop.apache.org
4. 上传hadoop安装⽂件到 /opt/lagou/software
第 2 节 集群规划

第 3 节 安装Hadoop
- 登录linux121节点;进⼊/opt/lagou/software,解压安装⽂件到/opt/lagou/servers
tar -zxvf hadoop-2.9.2.tar.gz -C /opt/lagou/servers
- 查看是否解压成功
ll /opt/lagou/servers/hadoop-2.9.2
- 添加Hadoop到环境变量 vim /etc/profile
##HADOOP_HOME
export HADOOP_HOME=/opt/lagou/servers/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 使环境变量⽣效
source /etc/profile
- 验证hadoop
hadoop version
- 校验结果:

- hadoop⽬录
drwxr-xr-x. 2 root root 194 Nov 13 2018 bin
drwxr-xr-x. 3 root root 20 Nov 13 2018 etc
drwxr-xr-x. 2 root root 106 Nov 13 2018 include
drwxr-xr-x. 3 root root 20 Nov 13 2018 lib
drwxr-xr-x. 2 root root 239 Nov 13 2018 libexec
-rw-r--r--. 1 root root 106210 Nov 13 2018 LICENSE.txt
-rw-r--r--. 1 root root 15917 Nov 13 2018 NOTICE.txt
-rw-r--r--. 1 root root 1366 Nov 13 2018 README.txt
drwxr-xr-x. 3 root root 4096 Nov 13 2018 sbindrwxr-xr-x. 4 root root 31 Nov 13 2018 share
1. bin⽬录:对Hadoop进⾏操作的相关命令,如hadoop,hdfs等
2. etc⽬录:Hadoop的配置⽂件⽬录,⼊hdfs-site.xml,core-site.xml等
3. lib⽬录:Hadoop本地库(解压缩的依赖)
4. sbin⽬录:存放的是Hadoop集群启动停⽌相关脚本,命令
5. share⽬录:Hadoop的⼀些jar,官⽅案例jar,⽂档等
3.1 集群配置
Hadoop集群配置 = HDFS集群配置 + MapReduce集群配置 + Yarn集群配置
HDFS集群配置
1. 将JDK路径明确配置给HDFS(修改hadoop-env.sh)
2. 指定NameNode节点以及数据存储⽬录(修改core-site.xml)
3. 指定SecondaryNameNode节点(修改hdfs-site.xml)
4. 指定DataNode从节点(修改etc/hadoop/slaves⽂件,每个节点配置信息占⼀⾏)
MapReduce集群配置
1. 将JDK路径明确配置给MapReduce(修改mapred-env.sh)
2. 指定MapReduce计算框架运⾏Yarn资源调度框架(修改mapred-site.xml)
Yarn集群配置
1. 将JDK路径明确配置给Yarn(修改yarn-env.sh)
2. 指定ResourceManager⽼⼤节点所在计算机节点(修改yarn-site.xml)
3. 指定NodeManager节点(会通过slaves⽂件内容确定)
集群配置具体步骤:
HDFS集群配置
cd /opt/lagou/servers/hadoop-2.9.2/etc/hadoop
配置:hadoop-env.sh
将JDK路径明确配置给HDFS
vim hadoop-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231
指定NameNode节点以及数据存储⽬录(修改core-site.xml)
vim core-site.xml
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://linux121:9000</value> </property> <!-- 指定Hadoop运⾏时产⽣⽂件的存储⽬录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/lagou/servers/hadoop-2.9.2/data/tmp</value> </property>
core-site.xml的默认配置:
https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-common/core-default.xml
指定secondarynamenode节点(修改hdfs-site.xml)
vim hdfs-site.xml
<!-- 指定Hadoop辅助名称节点主机配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>linux123:50090</value> </property> <!--副本数量 --> <property> <name>dfs.replication</name> <value>3</value> </property>
官⽅默认配置
https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.x
指定datanode从节点(修改slaves⽂件,每个节点配置信息占⼀⾏)
vim slaves
linux121
linux122
linux123
注意:该⽂件中添加的内容结尾不允许有空格,⽂件中不允许有空⾏。
MapReduce集群配置
指定MapReduce使⽤的jdk路径(修改mapred-env.sh)
vim mapred-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231
指定MapReduce计算框架运⾏Yarn资源调度框架(修改mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml<!-- 指定MR运⾏在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
mapred-site.xml默认配置
Yarn集群配置
指定JDK路径
vim yarn-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231
指定ResourceMnager的master节点信息(修改yarn-site.xml)
vim yarn-site.xml
<!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>linux123</value> </property> <!-- Reducer获取数据的⽅式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
yarn-site.xml的默认配置
https://hadoop.apache.org/docs/r2.9.2/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
指定NodeManager节点(slaves⽂件已修改, 这里就不用修改)
注意:
Hadoop安装⽬录所属⽤户和所属⽤户组信息,默认是501 dialout,⽽我们操作Hadoop集群的⽤户使⽤的是虚拟机的root⽤户,
所以为了避免出现信息混乱,修改Hadoop安装⽬录所属⽤户和⽤户组!!
chown -R root:root /opt/lagou/servers/hadoop-2.9.2
3.2 分发配置
编写集群分发脚本rsync-script
rsync 远程同步⼯具
rsync主要⽤于备份和镜像。具有速度快、避免复制相同内容和⽀持符号链接的优点。
rsync和scp区别:⽤rsync做⽂件的复制要⽐scp的速度快,rsync只对差异⽂件做更新。scp是把所有⽂件都复制过去。
1. 基本语法
rsync -rvl $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷⻉的⽂件路径/名称 ⽬的⽤户@主机:⽬的路径/名称
2. 选项参数说明
表2-2
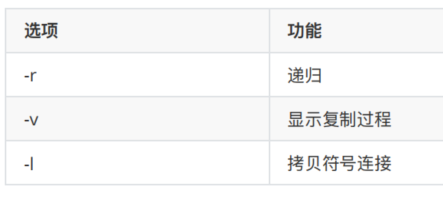
rsync案例
1. 三台虚拟机安装rsync (执⾏安装需要保证机器联⽹)
[root@linux121 ~]# yum install -y rsync
2.把linux121机器上的/opt/lagou/software⽬录同步到linux122服务器的root⽤户下的/opt/⽬录
[root@linux121 opt]$ rsync -rvl /opt/lagou/software/root@linux122:/opt/lagou/software
集群分发脚本编写
1. 需求:循环复制⽂件到集群所有节点的相同⽬录下
rsync命令原始拷⻉:
rsync -rvl /opt/module root@linux123:/opt/
2. 期望脚本
脚本+要同步的⽂件名称
3. 说明:在/usr/local/bin这个⽬录下存放的脚本,root⽤户可以在系统任何地⽅直接执⾏。
4. 脚本实现
1)在/usr/local/bin⽬录下创建⽂件rsync-script,⽂件内容如下:
[root@linux121 bin]$ touch rsync-script
[root@linux121 bin]$ vim rsync-script
在⽂件中编写shell代码
#!/bin/bash
# 需求: 循环复制文件到集群所有节点的相同目录下
# 使用方式: 脚本+需要复制的文件名称
#
#脚本编写步骤:
# 1, 获取传入脚本的参数, 参数个数
paramnum=$#
if((paramnum==0))
then
echo no args;
exit;
fi
# 2, 获取文件名称
p1=$1
file_name=`basename $p1` #basename 获取最后一级文件/夹名
echo fname=${file_name}
# 3, 获取文件绝对路径, 获取文件目录信息
dir_name=`cd -P $(dirname $p1);pwd`
# 下面的可能会获取相对路径, 无效
#dir_name=`dirname $p1` # dirname 获取最后一级之前的路径名
echo dirname=${dir_name}
# 4, 获取到当前用户信息
user=`whoami`
# 5, 执行 rsync命令 循环执行, 把数据发送到集群中所有的其他节点上
for((host=121;host<124;host++));
do
echo --------------target hostname=linux$host----------------
rsync -rvl ${dir_name}/${file_name} ${user}@linux${host}:${dir_name}
done2)修改脚本 rsync-script 具有执⾏权限
[root@linux121 bin]$ chmod 777 rsync-script
3)调⽤脚本形式:rsync-script ⽂件名称
[root@linux121 bin]$ rsync-script rsync-script
4) 调⽤脚本分发Hadoop安装⽬录到其它节点
[root@linux121 bin]$ rsync-script /opt/lagou/servers/hadoop-2.9.2
shell脚本的编写不要求掌握,看到别⼈编写的脚本要能读懂!!
如果出现下面的错误
./rsync-script: /bin/bash^M: bad interpreter: No such file or directory

一般是由于Windows和Linux环境下的编码方式不同 使用vim 打开任意文件, 在 :命令行中输入 : set ff? 查看编码方式
如果是 dos 方式, 则修改成 : set ff=unix
第 4 节 启动集群
注意:如果集群是第⼀次启动,需要在Namenode所在节点格式化NameNode,⾮第⼀次不⽤执⾏格式化Namenode操作!!
4.1 单节点启动
[root@linux121 hadoop-2.9.2]$ hadoop namenode -format
格式化命令执⾏效果:

格式化后创建的⽂件:/opt/lagou/servers/hadoop-2.9.2/data/tmp/dfs/name/current

1. 在linux121上启动NameNode
[root@linux121 hadoop-2.9.2]$ hadoop-daemon.sh start namenode
[root@linux121 hadoop-2.9.2]$ jps
2. 在linux121、linux122以及linux123上分别启动DataNode
[root@linux121 hadoop-2.9.2]$ hadoop-daemon.sh start datanode
[root@linux121 hadoop-2.9.2]$ jps
3461 NameNode
3608 Jps
3561 DataNode
[root@linux122 hadoop-2.9.2]$ hadoop-daemon.sh start datanode
[root@linux122 hadoop-2.9.2]$ jps
3190 DataNode
3279 Jps
[root@linux123 hadoop-2.9.2]$ hadoop-daemon.sh start datanode
[root@linux123 hadoop-2.9.2]$ jps
3237 Jps
3163 DataNode
3. web端查看Hdfs界⾯

查看HDFS集群正常节点:

1. Yarn集群单节点启动
[root@linux123 servers]# yarn-daemon.sh start resourcemanager
[root@linux123 servers]# jps
7881 ResourceManager
8094 Jps
[root@linux122 servers]# yarn-daemon.sh start nodemanager[root@linux122 servers]# jps
8166 NodeManager
8223 Jps
[root@linux121 servers]# yarn-daemon.sh start nodemanager
[root@linux121 servers]# jps
8166 NodeManager
8223 Jps
2. 思考:Hadoop集群每次需要⼀个⼀个节点的启动,如果节点数增加到成千上万个怎么办?
4.2 集群群起
1. 如果已经单节点⽅式启动了Hadoop,可以先停⽌之前的启动的Namenode与Datanode进程,如果之前Namenode没有执⾏格式化,这⾥需要执⾏格式化!!!!
hadoop namenode -format
2. 启动HDFS
[root@linux121 hadoop-2.9.2]$ sbin/start-dfs.sh
[root@linux121 hadoop-2.9.2]$ jps
4166 NameNode
4482 Jps
4263 DataNode
[root@linux122 hadoop-2.9.2]$ jps
3218 DataNode
3288 Jps
[root@linux123 hadoop-2.9.2]$ jps
3221 DataNode
3283 SecondaryNameNode
3364 Jps
3. 启动YARN
[root@linux122 hadoop-2.9.2]$ sbin/start-yarn.sh
注意:NameNode和ResourceManger不是在同⼀台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
4.3 Hadoop集群启动停⽌命令汇总
1. 各个服务组件逐⼀启动/停⽌
(1)分别启动/停⽌HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
(2)启动/停⽌YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
2. 各个模块分开启动/停⽌(配置ssh是前提)常⽤
(1)整体启动/停⽌HDFS
start-dfs.sh / stop-dfs.sh
(2)整体启动/停⽌YARN
start-yarn.sh / stop-yarn.sh
第 5 节 集群测试
1. HDFS 分布式存储初体验
从linux本地⽂件系统上传下载⽂件验证HDFS集群⼯作正常
hdfs dfs -mkdir -p /test/input
#本地hoome⽬录创建⼀个⽂件
cd /rootvim test.txt
hello hdfs
#上传linxu⽂件到Hdfs
hdfs dfs -put /root/test.txt /test/input#从Hdfs下载⽂件到linux本地
hdfs dfs -get /test/input/test.txt
2. MapReduce 分布式计算初体验
在HDFS⽂件系统根⽬录下⾯创建⼀个wcinput⽂件夹
[root@linux121 hadoop-2.9.2]$ hdfs dfs -mkdir /wcinput
在/root/⽬录下创建⼀个wc.txt⽂件(本地⽂件系统)
[root@linux121 hadoop-2.9.2]$ cd /root/
[root@linux121 wcinput]$ touch wc.txt
编辑wc.txt⽂件
[root@linux121 wcinput]$ vi wc.txt
在⽂件中输⼊如下内容
hadoop mapreduce yarn
hdfs hadoop mapreduce
mapreduce yarn lagou
lagou
lagou
保存退出
: wq!
上传wc.txt到Hdfs⽬录/wcinput下
hdfs dfs -put wc.txt /wcinput
回到Hadoop⽬录/opt/lagou/servers/hadoop-2.9.2
执⾏程序
[root@linux121 hadoop-2.9.2]$ hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput/wcoutput
查看结果
[root@linux121 hadoop-2.9.2]$ hdfs dfs -cat /wcoutput/part-r-00000
hadoop 2
hdfs 1
lagou 3
mapreduce 3
yarn 2
第 6 节 配置历史服务器
在Yarn中运⾏的任务产⽣的⽇志数据不能查看,为了查看程序的历史运⾏情况,需要配置⼀下历史⽇志服务器。具体配置步骤如下:
1. 配置mapred-site.xml
[root@linux121 hadoop]$ vi mapred-site.xml
在该⽂件⾥⾯增加如下配置。
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>linux121:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>linux121:19888</value>
</property>2. 分发mapred-site.xml到其它节点
rsync-script mapred-site.xml
3. 启动历史服务器
[root@linux121 hadoop-2.9.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
4. 查看历史服务器是否启动
[root@linux121 hadoop-2.9.2]$ jps
5. 查看JobHistory
6.1 配置⽇志的聚集
⽇志聚集:应⽤(Job)运⾏完成以后,将应⽤运⾏⽇志信息从各个task汇总上传到HDFS系统上。
⽇志聚集功能好处:可以⽅便的查看到程序运⾏详情,⽅便开发调试。
注意:开启⽇志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启⽇志聚集功能具体步骤如下:
1. 配置yarn-site.xml
[root@linux121 hadoop]$ vi yarn-site.xml
在该⽂件⾥⾯增加如下配置。
<!-- ⽇志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- ⽇志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>2. 分发yarn-site.xml到集群其它节点
rsync-script yarn-site.xml
3. 关闭NodeManager 、ResourceManager和HistoryManager
[root@linux121 hadoop-2.9.2]$ sbin/yarn-daemon.sh stop resourcemanage
[root@linux121 hadoop-2.9.2]$ sbin/yarn-daemon.sh stop nodemanage
[root@linux121 hadoop-2.9.2]$ sbin/mr-jobhistory-daemon.sh stop historyserver
4. 启动NodeManager 、ResourceManager和HistoryManager
[root@linux121 hadoop-2.9.2]$ sbin/yarn-daemon.sh start resourcemanage
[root@linux121 hadoop-2.9.2]$ sbin/yarn-daemon.sh start nodemanage
[root@linux121 hadoop-2.9.2]$ sbin/mr-jobhistory-daemon.sh start historyserv
5. 删除HDFS上已经存在的输出⽂件
[root@linux121 hadoop-2.9.2]$ bin/hdfs dfs -rm -R /wcoutpu
6. 执⾏WordCount程序
[root@linux121 hadoop-2.9.2]$ hadoop jar share/hadoop/mapreduce/hadoopmapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutp
7. 查看⽇志,如图所示
http://linux121:19888/jobhistory

