UA MATH567 高维统计 专题0 为什么需要高维统计理论?——协方差估计的高维效应与Marcenko-Pastur规则
上一讲我们介绍了在实验中,线性判别分析的判别误差会随着维度的上升而上升,而经典多元统计理论则认为理论误差是与维数无关的常数,于是我们得到启发是我们需要建立适应于高维统计问题的理论。这一讲我们从线性判别分析中的协方差估计的角度,讨论在高维问题中协方差估计会发生什么与经典多元统计理论不同的现象。
我们假设 x 1 , ⋯ , x n x_1,\cdots,x_n x1,⋯,xn是某个 d d d维零均值分布的样本,则样本协方差为
Σ ^ = 1 n ∑ i = 1 n x i x i T \hat \Sigma = \frac{1}{n} \sum_{i=1}^n x_ix_i^T Σ^=n1i=1∑nxixiT
它是总体协方差的无偏估计。但对于non-asymptotic情形,我们希望知道这个估计的误差。在随机矩阵理论中,我们介绍了一些常用的矩阵范数,可以用它们来表示误差,比如在这个协方差估计的问题中,我们定义估计误差为样本协方差与总体协方差之差的算子范数,即
∥ Σ ^ − Σ ∥ = λ 1 ( Σ ^ − Σ ) \left\| \hat \Sigma - \Sigma \right\| = \lambda_{1}(\hat \Sigma - \Sigma) ∥∥∥Σ^−Σ∥∥∥=λ1(Σ^−Σ)
考虑最简单的一种情况,如果 Σ = I d \Sigma=I_d Σ=Id,那么根据弱大数定律, Σ ^ \hat \Sigma Σ^会依概率趋近于 I d I_d Id,那么 Σ ^ \hat \Sigma Σ^的所有特征值会依概率收敛到1。
Marcenko-Pastur规则
假设 d / n → α ∈ ( 0 , 1 ) d/n \to \alpha \in (0,1) d/n→α∈(0,1),也就是在维数非常高的时候,Marcenko-Pastur规则认为 Σ ^ \hat \Sigma Σ^的特征值的密度满足:
f M P ( λ ) ∝ ( t m a x ( α ) − λ ) ( λ − t m i n ( α ) ) λ f_{MP}(\lambda) \propto \sqrt{\frac{(t_{max}(\alpha)-\lambda)(\lambda-t_{min}(\alpha))}{\lambda}} fMP(λ)∝λ(tmax(α)−λ)(λ−tmin(α))
其中
t m i n ( α ) = ( 1 − α ) 2 , t m a x = ( 1 + α ) 2 t_{min}(\alpha)=(1-\sqrt{\alpha})^2,\ t_{max}=(1+\sqrt{\alpha})^2 tmin(α)=(1−α)2, tmax=(1+α)2
这两个阈值的来源是我们在随机矩阵部分介绍过的不等式
P ( λ 1 ( Σ ^ ) ≥ ( 1 + d / n + δ ) 2 ) ≤ e − n δ 2 2 , ∀ δ ≥ 0 P(\lambda_{1}(\hat \Sigma) \ge (1+\sqrt{d/n}+\delta)^2) \le e^{-\frac{n\delta^2}{2}},\forall \delta \ge 0 P(λ1(Σ^)≥(1+d/n+δ)2)≤e−2nδ2,∀δ≥0
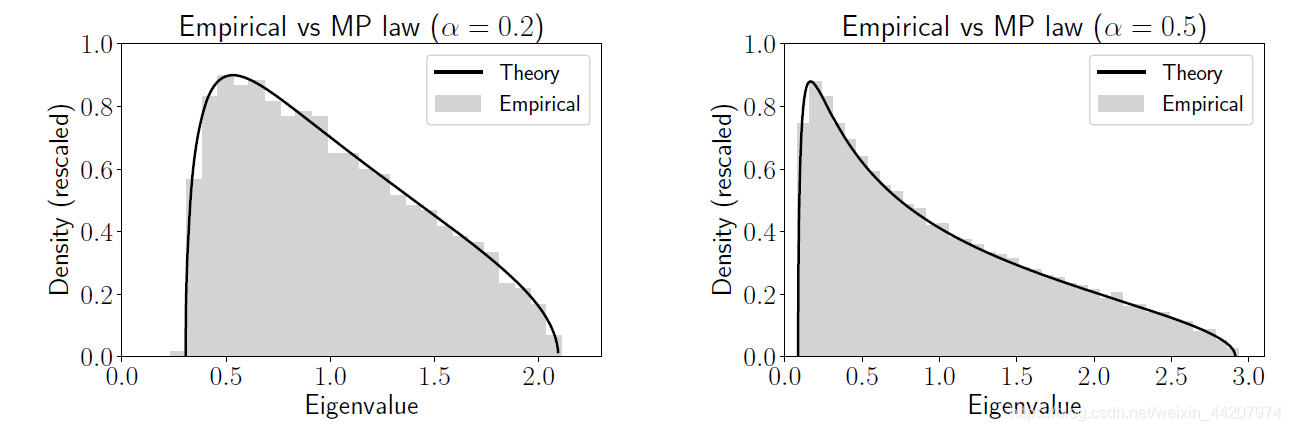
这幅图是基于这个简单情形的模拟,左图参数是 α = 0.2 , n = 4000 \alpha=0.2,n=4000 α=0.2,n=4000;右图的参数是 α = 0.5 , n = 4000 \alpha=0.5,n=4000 α=0.5,n=4000;灰色部分是特征值的频率直方图,黑色实线是Marcenko-Pastur规则的密度。从这个图可以看出,模拟结果,也就是灰色部分并没有贴近经典多元统计的结果(收敛到1)反而是与Marcenko-Pastur规则基本相符的,而Marcenko-Pastur规则是一个典型的高维统计理论结果。
作为专题0的结尾,我简单阐述一下我对经典多元统计理论与高维统计理论的理解。首先这二者作为统计理论,研究的问题其实是一样的,估计量的一致性、误差、收敛速率等。但经典多元统计理论假设 d < < n d<<n d<<n,也就是在做asymptotic analysis的时候,经典统计认为特征的维数 d d d关于样本量 n n n是无穷小量,即 d / n → 0 d/n \to 0 d/n→0,因此经典统计理论的误差、concentration inequality等结果与维数是无关的。在高维统计理论中,假设 d / n → α ∈ ( 0 , 1 ) d/n \to \alpha \in (0,1) d/n→α∈(0,1),这个比例会出现在误差、concentration inequality等结果中,也就是维数对概率分布、对误差等都是有影响的。
除此之外,经典统计与高维统计还有一个很重要的区别,就是在高维统计中,information is sparse in features,即并不是 d d d个特征都是一样重要的,重要的特征占比非常小,这种特性被称为sparsity,通常认为重要的特征数目是 o ( d ) o(d) o(d),也就是关于 d d d是无穷小量,所以我们总是需要一些技术来做dimensional reduction/feature selection以去除冗余信息提高计算效率。