永丰金证券是一家在台湾经济业务市占率排行第四的大型券商,外部用户和内部员工都是通过各类电子平台接入到系统来提交服务需求,例如 Web、手机 App、Windows Application 以及 B2B、B2C API 等等。
目前,永丰金证券各个电子平台的服务需求处理与回应都是由资讯部门来完成的,据了解平台最高同时在线人数可以达到 12000 人,其中行情数据资料的查询、处理、落地和再应用是最繁重的业务。
2020 年 3 月 23 日,台湾证券交易所改变了交易撮合机制,从原本 5 秒集中撮合制度改为微秒 (百万分之一秒) 逐笔撮合制度,总体数据量增加为原先的 2-4 倍,峰值期间数据量增加为原本 4-6 倍。面对行情数据的增加,永丰金证券原来的行业处理系统出现了瓶颈,需要寻求新的解决方案。
经过对性能、扩展性、成熟度、综合拥有成本等方面的综合考量,永丰金证券放弃了 kdb+、InfluxDB 和 Kafka,最终选择了 DolphinDB 作为行情系统的基础平台。
1. 面临的业务痛点
为了给用户提供相应的服务,永丰金证券的服务架构需要提供行情的 Tick 留存、查询,即时性的时序查询 (分 K、日 K),各项行情的资讯快照,以及技术分析的资料库。但之前的行情数据服务架构存在很多问题,例如功能扩充不易、效能不佳、系统整合成本高以及异常排除不易等。
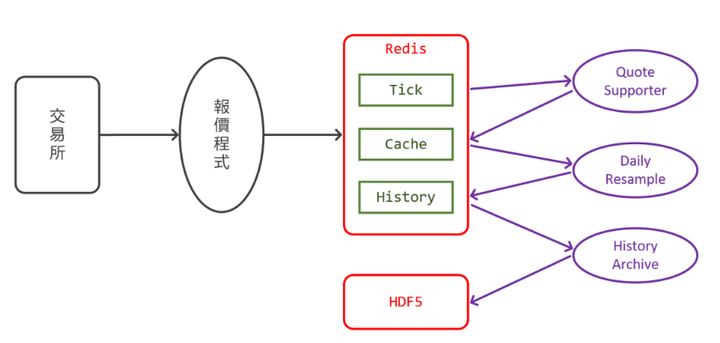
过往行情数据的服务架构图
- 功能扩充不易
之前,永丰金证券是采用 C-ISAM/HDF5 档案格式来进行行情数据的落地与再应用,但其对开发系统的支持不佳(只有 C/C++ API),同时也会受到服务器版本 (Solaris 32bit) 的限制,每一档案的 Size 最大为 2GB,在行情数据的落地时,产生了留存时间区段的限制。另外,档案形式的资料库表在扩展时,会遇到弹性不足的问题,同时由于是档案形式,所以每台服务器上都需要有一份历史行情数据备份,从而增加了存储成本,也增加了资料不一致的风险。
- 效能不佳
永丰金证券是通过 pandas 来进行行情资料的计算与应用,在高并发的客户查询之下,将 Redis Tick 通过 resample 方式转置成分 K,这个过程大约需要 1 秒。
对于公司来说,这样的效能实在是太差了。公司尝试将不同业务分布在不同的服务器上,但遗憾的是,仍然无法提供高效的服务和很好的客户体验。
- 系统整合成本高
每一笔行情数据都要经历收集、处理、落地等多个过程,但是永丰金证券在技术选型的时候,每个阶段都选择了不同的解决方案,例如通过 Redis 来收集即时行情数据,利用 pandas 进行处理应用,C-ISAM/HDF5 来服务行情数据的落地保存。
基于此,如果要对各个服务架构进行整合开发,那么就需要了解各服务层的使用,进而整合出系统所需提供的服务。例如,将行情数据降维(把 tick 级别高频数据转化为分钟级别或日级 K 线),以及将不同月份期货拼接为连续合约等任务,对系统整合的成本与技术的要求是极高的。
- 排除异常情况
在开放架构上搭建出来的服务会面临各种各样的异常,例如在资料面会出现异常,无法进行有效、精准的锁定。为了排除这样的异常,我们得投入相当多的人力物力来对开发架构的代码进行二次开发,导致开发人员无法集中在业务。
2. 技术平台的选择
针对以上的业务痛点和团队特性,我们希望能够找到一个技术平台来兼顾历史数据和实时数据的处理,同时满足金融市场行情服务的计算要求,开箱即用,性能优异且学习、开发成本较低。
2019 年 6 月,我们先后评估了 kdb+,InfluxDB,Kafka 和 DolphinDB 等系统。
- kdb+
kdb+ 是华尔街广泛应用于行情服务的时序资料库,以速度快著称。因为原本的行情系统存在的主要问题是进行逐笔撮合业务时效能不足,所以很多人都推荐使用 kdb+ 来解决效能问题。
经过初步评估之后,我们决定放弃 kdb+,主要的原因有两个:一是团队成员的技术背景主要是 Python,跨越到 kdb+ 的 Q 语言和 K 语言难度太大,而且如果围绕 kdb+ 来构建行情系统,就需要额外招募昂贵的 kdb+ 顾问。二是 kdb+ 是单机单任务系统,虽然 kdb 的单个节点可以支撑当前的行情数据量和用户访问,但是后续若需要水平扩展存储和计算能力,就需要大量的开发和集成工作。
- Kafka
行情服务系统的很多任务需要实时流计算,这促使我们考虑以 Kafka 为中心来构建系统。
经过简单尝试之后,我们发现 Kafka 是一个通用且可以定制的消息系统,但若要应用于金融行情这样专业的领域,特别是要达到稳定高效的运行状态,还需要大量的开发、集成和校调优化的技术工作。对于专注于业务而不是技术本身的小型开发团队来说,Kafka 可能不是最佳的选择。
另外,Kafka 的优势在于高吞吐量,而不在低延迟。在金融市场交易高峰期间,Kafka 可能会有几秒钟的延迟,这对时效要求很高的行情服务系统来说是一个很大的问题。
- InfluxDB
行情服务是典型的时序数据应用场景,所以我们也测试了目前最为流行的开源时序资料库 InfluxDB。
我们发现 InfluxDB 是按照指标(metrics)来组织数据,一组 tag 的组合在某个指标上的时间序列值会构成一个序列。这些不同的序列无论在逻辑上还是物理存储上几乎相互独立,这是为物联网传感器的数据采集和查询设计的,而在面对行情服务中的很多问题时,可能会缺乏表达能力:例如处理股票期权数据时,我们需要关联股票的行情价格;计算技术指标时,我们关心同一个股票的 high、low 和 close 之间的关系,或者不同股票的收益率之间的关系。
既然 InfluxDB 本身不能满足金融市场行情服务中复杂计算的要求,能否把 InfluxDB 作为一个纯粹的存储引擎来使用,将复杂的计算转移到第三方(譬如 pandas)处理?我们对比了 InfluxDB-pandas 的处理模式和 DolphinDB 库内计算模式,后者在性能上领先前者 100 倍以上。
这个优势来自三个方面:
- DolphinDB 数据存取速度比 InfluxDB 更快。
- DolphinDB 提供的库内计算能力省去了数据转移的成本。
- DolphinDB 的计算速度比 pandas 更快。
- DolphinDB
DolphinDB 是在评估 kdb+ 的过程中意外发现的一个产品。经过测试后发现其各方面的表现都很突出,非常符合金融市场行情服务的要求。
与 kdb+ 相比,DolphinDB 是一个分布式的时序资料库,水平扩展无需额外的工作。DolphinDB 的语言像是 SQL 和 Python 的合体,新人可以快速上手;与 Kafka 相比,DolphinDB 自带的流数据系统不但与数据库紧密集成,而且内置的流计算引擎开箱即用,通过简单的配置和脚本编写就可以完成行情服务 95% 以上的工作;与 InfluxDB 相比,性能更好。
再结合硬件资源、开发和维护成本、产品交付周期等多个维度,我们发现 DolphinDB 的综合成本是最低的。
3. 引入 DolphinDB 后的现况
2019 年 8 月,我们开始测试 DolphinDB, 10 月决定采用 DolphinDB 作为技术平台,2020 年 3 月,新的行情服务系统正式上线。
- 使用函数视图快速扩展服务
DolphinDB 的函数视图(function view) 是对数据服务的抽象。原本功能服务需要在客户端取得资料后,自行计算其所需的处理,但现在完全可以转移至数据库集中处理,客户端只需使用 API 调用函数视图。当其它业务部门提出新的行情数据服务请求时,只要用类 SQL 语言开发一个函数视图并授权其使用即可,无需暴露所有原始数据的结构和权限。
这种方式不但加快了数据服务的开发,也简化了对数据的治理和管控。函数视图对系统面的管理、功能面的扩展,同样具有加速开发简化管理的效果。
以 Web 端显示行情资讯为例,原先是需要在 Web 后端进行计算处理。现在利用函数视图,将原本后端处理的逻辑通过 DolphinDB 进行更简洁高效的封装,将原本 Web 后端大量开发的代码缩减至一行函数,就可以得到一样的结果。之前跨市场的商品获取,也需要 Web 端通过多次重复的查询,拼凑出各市场的商品列表资讯,因为 DolphinDB 本身已收集各市场的行情,所以通过简单的 SQL 语法,向量式的获取,整体效能与开发得到了大幅度的优化。同时,还会将资料细节封装在 DolphinDB 之中,Web 后端的其它同事只需要定义好资料介面,就可以解决掉以往资料与系统强耦合的难题。
DolphinDB 的函数视图与关系数据库的存储过程在概念上有相似之处。但它克服了存储过程的诸多局限:
- 不适合处理复杂的业务逻辑;
- 代码的可读性不佳;
- 无法实现并行计算和分布式计算。
使用 DolphinDB 开发一个函数视图,与使用 Python 开发一个业务逻辑函数,没有实质区别。只不过 DolphinDB 的脚本语言原生支持函数式、向量式、分布式的多范式编程,代码更简洁,运行更高效。
- 便捷的流数据处理
导入 DolphinDB 过程中,最令人激动的核心功能就是其流数据引擎 (Streaming Engine) 处理能力。针对每一个业务需求,不同的流数据引擎会提供所需的处理能力,使得以往的计算负载能够即时获取到资料数据,实时处理,客户端一次查询的返回耗时由 1~2 秒缩短到 10 毫秒。
目前使用到的流数据处理引擎包括:
- 通过 Time Series Aggregator 即时产生 K 线数据。
- 通过 Cross Section Aggregator 产生行情汇总、各项行情条件排序。
- 使用 Anomaly Detection Engine 即时分析每一笔行情数据,进行交易规则过滤并示警。
DolphinDB 高效方便的脚本结合各种插件和 API,能快速创建 Dashboard。数据监控及示警资料能有效与 Grafana、NetData 等 Dashboard 框架进行整合,进而快速的建立系统监控机制。
- 高效的历史数据查询与分析
台湾股票目前每天数据量约为 60,000,000 笔行情数据,原始资料大小约 10G。导入 DolphinDB 之后,约需 2GB 硬碟空间,压缩率约为 20%。在同样的系统资源下,能够留存更多更久的数据。
DolphinDB 是一个分布式时序资料库,可以对数据进行合理的分区,从而提高系统性能。与其它时序资料库根据数据量大小,自动在时间维度上分区的做法不同,DolphinDB 提供了丰富的分区方法(包括值分区,范围分区,哈希分区,列表分区和组合分区),并允许用户根据业务特点和数据分布,自主选择合理的分区策略。抛开性能优化的考虑,这也非常符合行情服务的业务需要。行情服务对历史资料的处理,通常是以天为单位,并不能按任意时间窗口进行分割处理。
针对台湾的行情资料,Tick 部分目前采用每天一个分区的方式进行留存,OrderBook 部分,由于数量极高,所以采用了双重分区 (Symbol+Date),在存取方面都能满足现行系统需求。而 OrderBook 之前是架构无法落地的资料,现在通过 DolphinDB 已开始进行保存,进而增加了永丰金证券提供客户行情资料的内容项目。
另外由于 DolphinDB 的设计,在使用上可以将同一种行情视为一个完整的资料表,通过简单的 SQL 语句就可以查询特定条件的资料。而过去自行定义查询介面存取 HDF5/Redis 的方式,常常因为新的查询条件,就得额外开发查询的参数。
DolphinDB 有丰富且开放的 API,以及高效的服务能力,所以永丰金证券构建了一组 DolphinDB 且采用 Single mode 的状态,就可以满足查询类的 AP 端所需,无需建置多台的服务器来满足所需效能与功能。
- 大幅降低开发成本
之前永丰金证券的产品是通过堆叠各式开放系统架构构建而成的,其中个别并非针对金融行业的设计,使得我们必须花费大量的时间和精力去整合。导入 DolphinDB 之后,原先分散在各个不同 Service 的处理,都已全数转移至 DolphinDB 完成,包括即时性流数据、缓冲数据资料、历史数据、报表数据,通过统一的计算引擎进行处理,在提高了整体服务效能的同时,也减少了开发难度与整合的困难,以及硬体管理的复杂度。
各电子平台有了 DolphinDB 的服务,就可以 DolphinDB 内置的程式设计语言进行相关功能的开发,原本需要使用上百行的 Python 代码,现在可能通过十几行的 DolphinDB 代码就可以完成,提升了开发的速度,更省下许多侦错的时间与复杂度。
导入过程中,DolphinDB 原厂也针对我们的特殊使用场景,开发了新的功能,大大降低了技术上的成本与门槛。
小结
在处理行情数据时,除了保证资料的正确性之外,我们面临的更大挑战是效能要求与功能的弹性扩展。
导入 DolphinDB 之后,我们实际部署的开发团队从之前的 2-3 人减少至 1 人 (非专职),服务器从 6 台减少至 2 台 (其中 1 台为备份异地容灾)。但是却得到了更快的开发速度、更好的性能提升、更好的用户体验。