DolphinDB支持动态加载外部插件,以扩展系统功能。插件用C++编写,需要编译成".so"或".dll"共享库文件。本文着重介绍开发插件的方法和注意事项,并详细介绍以下几个具体场景的插件开发流程:
- 如何开发支持时间序列数据处理的插件函数
- 如何开发用于处理分布式SQL的聚合函数
- 如何开发支持新的分布式算法的插件函数
- 如何开发支持流数据处理的插件函数
- 如何开发支持外部数据源的插件函数
1. 如何开发插件
1.1 基本概念
DolphinDB的插件实现了能在脚本中调用的函数。一个插件函数可能是运算符函数(Operator function),也可能是系统函数(System function),它们的区别在于,前者接受的参数个数小于等于2,而后者的函数可以接受任意个参数,并支持会话的访问操作。
开发一个运算符函数,需要编写一个原型为ConstantSP (const ConstantSP& a, const ConstantSP& b)的C++函数。当函数参数个数为2时,a和b分别为插件函数的第一和第二个参数;当参数个数为1时,b是一个占位符,没有实际用途;当没有参数时,a和b均为占位符。
开发一个系统函数,需要编写一个原型为ConstantSP (Heap* heap, vector<ConstantSP>& args)的C++函数。用户在DolphinDB中调用插件函数时传入的参数,都按顺序保存在C++的向量args中。heap参数不需要用户传入。
函数原型中的ConstantSP可以表示绝大多数DolphinDB对象(标量、向量、矩阵、表,等等)。其他常用的派生自它的变量类型有VectorSP(向量)、TableSP(表)等。
1.2 创建变量
创建标量,可以直接用new语句创建头文件ScalarImp.h中声明的类型对象,并将它赋值给一个ConstantSP。ConstantSP是一个经过封装的智能指针,会在变量的引用计数为0时自动释放内存,因此,用户不需要手动delete已经创建的变量:
ConstantSP i = new Int(1); // 相当于1i
ConstantSP d = new Date(2019, 3, 14); // 相当于2019.03.14
ConstantSP s = new String("DolphinDB"); // 相当于"DolphinDB"
ConstantSP voidConstant = new Void(); // 创建一个void类型变量,常用于表示空的函数参数头文件Util.h声明了一系列函数,用于快速创建某个类型和格式的变量:
VectorSP v = Util::createVector(DT_INT, 10); // 创建一个初始长度为10的int类型向量
v->setInt(0, 60); // 相当于v[0] = 60
VectorSP t = Util::createVector(DT_ANY, 0); // 创建一个初始长度为0的any类型向量(元组)
t->append(new Int(3)); // 相当于t.append!(3)
t->get(0)->setInt(4); // 相当于t[0] = 4
// 这里不能用t->setInt(0, 4),因为t是一个元组,setInt(0, 4)只对int类型的向量有效
ConstantSP seq = Util::createIndexVector(5, 10); // 相当于5..14
int seq0 = seq->getInt(0); // 相当于seq[0]
ConstantSP mat = Util::createDoubleMatrix(5, 10);// 创建一个10行5列的double类型矩阵
mat->setColumn(3, seq); // 相当于mat[3] = seq1.3 异常处理和参数校验
1.3.1 异常处理
插件开发时的异常抛出和处理,和一般C++开发中一样,都通过throw关键字抛出异常,try语句块处理异常。DolphinDB在头文件Exceptions.h中声明了异常类型。
插件函数若遇到运行时错误,一般抛出RuntimeException。
在插件开发时,通常会校验函数参数,如果参数不符合要求,抛出一个IllegalArgumentException。常用的参数校验函数有:
ConstantSP->getType():返回变量的类型(int, char, date等等),DolphinDB的类型定义在头文件Types.h中。ConstantSP->getCategory():返回变量的类别,常用的类别有INTEGRAL(整数类型,包括int, char, short, long等)、FLOATING(浮点数类型,包括float, double等)、TEMPORAL(时间类型,包括time, date, datetime等)、LITERAL(字符串类型,包括string, symbol等),都定义在头文件Types.h中。ConstantSP->getForm():返回变量的格式(标量、向量、表等等),DolphinDB的格式定义在头文件Types.h中。ConstantSP->isVector():判断变量是否为向量。ConstantSP->isScalar():判断变量是否为标量。ConstantSP->isTable():判断变量是否为表。ConstantSP->isNumber():判断变量是否为数字类型。ConstantSP->isNull():判断变量是否为空值。ConstantSP->getInt():获得变量对应的整数值,常用于判断边界。ConstantSP->getString():获得变量对应的字符串。ConstantSP->size():获得变量的长度。
更多参数校验函数一般在头文件CoreConcept.h的Constant类方法中。
1.3.2 参数校验的范例
本节将开发一个插件函数用于求非负整数的阶乘,返回一个long类型变量。
DolphinDB中long类型的最大值为2^63 - 1,能表示的阶乘最大为25!,因此只有0~25范围内的参数是合法的。
#include "CoreConcept.h"
#include "Exceptions.h"
#include "ScalarImp.h"
ConstantSP factorial(const ConstantSP &n, const ConstantSP &placeholder) {
string syntax = "Usage: factorial(n). ";
if (!n->isScalar() || n->getCategory() != INTEGRAL)
throw IllegalArgumentException("factorial", syntax + "n must be an integral scalar.");
int nValue = n->getInt();
if (nValue < 0 || nValue > 25)
throw IllegalArgumentException("factorial", syntax + "n must be a non-negative integer less than 26.");
long long fact = 1;
for (int i = nValue; i > 0; i--)
fact *= i;
return new Long(fact);
}1.4 调用DolphinDB内置函数
有时会需要调用DolphinDB的内置函数对数据进行处理。有些类已经定义了一些常用的内置函数作为方法:
VectorSP v = Util::createIndexVector(1, 100);
ConstantSP avg = v->avg(); // 相当于avg(v)
ConstantSP sum2 = v->sum2(); // 相当于sum2(v)
v->sort(false); // 相当于sort(v, false)如果需要调用其它内置函数,插件函数的类型必须是系统函数。通过heap->currentSession()->getFunctionDef函数获得一个内置函数,然后用call方法调用它。如果该内置函数是运算符函数,应调用原型call(Heap, const ConstantSP&, const ConstantSP&);如果是系统函数,应调用原型call(Heap, vector<ConstantSP>&)。以下是调用内置函数cumsum的一个例子:
ConstantSP v = Util::createIndexVector(1, 100);
v->setTemporary(false); // v的值可能在内置函数调用时被修改。如果不希望它被修改,应先调用setTemporary(false)
FunctionDefSP cumsum = heap->currentSession()->getFunctionDef("cumsum");
ConstantSP result = cumsum->call(heap, v, new Void()); // 相当于cumsum(v),这里的new Void()是一个占位符,没有实际用途2. 如何开发支持时间序列数据处理的插件函数
DolphinDB的特色之一在于它对时间序列有良好支持。
本章以编写一个msum函数的插件为例,介绍如何开发插件函数支持时间序列数据处理。
时间序列处理函数通常接受向量作为参数,并对向量中的每个元素进行计算处理。在本例中,msum函数接受两个参数:一个向量和一个窗口大小。它的原型是:
ConstantSP msum(const ConstantSP &X, const ConstantSP &window);msum函数的返回值是一个和输入向量同样长度的向量。本例为简便起见,假定返回值是一个double类型的向量。可以通过Util::createVector函数预先为返回值分配空间:
int size = X->size();
int windowSize = window->getInt();
ConstantSP result = Util::createVector(DT_DOUBLE, size);在DolphinDB插件编写时处理向量,可以循环使用getDoubleConst,getIntConst等函数,批量获得一定长度的只读数据,保存在相应类型的缓冲区中,从缓冲区中取得数据进行计算。这样做的效率比循环使用getDouble,getInt等函数要高。本例为简便起见,统一使用getDoubleConst,每次获得长度为Util::BUF_SIZE的数据。这个函数返回一个const double*,指向缓冲区头部:
double buf[Util::BUF_SIZE];
INDEX start = 0;
while (start < size) {
int len = std::min(Util::BUF_SIZE, size - start);
const double *p = X->getDoubleConst(start, len, buf);
for (int i = 0; i < len; i++) {
double val = p[i];
// ...
}
start += len;
}在本例中,msum将计算X中长度为windowSize的窗口中所有数据的和。可以用一个临时变量tmpSum记录当前窗口的和,每当窗口移动时,只要给tmpSum增加新窗口尾部的值,减去旧窗口头部的值,就能计算得到当前窗口中数据的和。为了将计算值写入result,可以循环用result->getDoubleBuffer获取一个可读写的缓冲区,写完后使用result->setDouble函数将缓冲区写回数组。setDouble函数会检查给定的缓冲区地址和变量底层储存的地址是否一致,如果一致就不会发生数据拷贝。在多数情况下,用getDoubleBuffer获得的缓冲区就是变量实际的存储区域,这样能减少数据拷贝,提高性能。
需要注意的是,DolphinDB用double类型的最小值(已经定义为宏DBL_NMIN)表示double类型的NULL值,要专门判断。
返回值的前windowSize - 1个元素为NULL。可以对X中的前windowSize个元素和之后的元素用两个循环分别处理,前一个循环只计算累加,后一个循环执行加和减的操作。最终的实现如下:
ConstantSP msum(const ConstantSP &X, const ConstantSP &window) {
INDEX size = X->size();
int windowSize = window->getInt();
ConstantSP result = Util::createVector(DT_DOUBLE, size);
double buf[Util::BUF_SIZE];
double windowHeadBuf[Util::BUF_SIZE];
double resultBuf[Util::BUF_SIZE];
double tmpSum = 0.0;
INDEX start = 0;
while (start < windowSize) {
int len = std::min(Util::BUF_SIZE, windowSize - start);
const double *p = X->getDoubleConst(start, len, buf);
double *r = result->getDoubleBuffer(start, len, resultBuf);
for (int i = 0; i < len; i++) {
if (p[i] != DBL_NMIN) // p[i] is not NULL
tmpSum += p[i];
r[i] = DBL_NMIN;
}
result->setDouble(start, len, r);
start += len;
}
result->setDouble(windowSize - 1, tmpSum); // 上一个循环多设置了一个NULL,填充为tmpSum
while (start < size) {
int len = std::min(Util::BUF_SIZE, size - start);
const double *p = X->getDoubleConst(start, len, buf);
const double *q = X->getDoubleConst(start - windowSize, len, windowHeadBuf);
double *r = result->getDoubleBuffer(start, len, resultBuf);
for (int i = 0; i < len; i++) {
if (p[i] != DBL_NMIN)
tmpSum += p[i];
if (q[i] != DBL_NMIN)
tmpSum -= q[i];
r[i] = tmpSum;
}
result->setDouble(start, len, r);
start += len;
}
return result;
}3. 如何开发用于处理分布式SQL的聚合函数
在DolphinDB中,SQL的聚合函数通常接受一个或多个向量作为参数,最终返回一个标量。在开发聚合函数的插件时,需要了解如何访问向量中的元素。
DolphinDB中的向量有两种存储方式。一种是常规数组,数据在内存中连续存储;另一种是大数组,其中的数据分块存储。
本章将以编写一个求几何平均数的函数为例,介绍如何开发聚合函数,重点关注数组中元素的访问。
3.1 聚合函数范例
几何平均数geometricMean函数接受一个向量作为参数。为了防止溢出,一般采用其对数形式计算,即
geometricMean([x1, x2, ..., xn])
= exp((log(x1) + log(x2) + log(x3) + ... + log(xn))/n)为了实现这个函数的分布式版本,可以先开发聚合函数插件logSum,用以计算某个分区上的数据的对数和,然后用defg关键字定义一个Reduce函数,用mapr关键字定义一个MapReduce函数。
在DolphinDB插件开发中,对数组的操作通常要考虑它是常规数组还是大数组。可以用isFastMode函数判断:
ConstantSP logSum(const ConstantSP &x, const ConstantSP &placeholder) {
if (((VectorSP) x)->isFastMode()) {
// ...
}
else {
// ...
}
}如果数组是常规数组,它在内存中连续存储。可以用getDataArray函数获得它数据的指针。假定数据是以double类型存储的:
if (((VectorSP) x)->isFastMode()) {
int size = x->size();
double *data = (double *) x->getDataArray();
double logSum = 0;
for (int i = 0; i < size; i++) {
if (data[i] != DBL_NMIN) // is not NULL
logSum += std::log(data[i]);
}
return new Double(logSum);
}如果数据是大数组,它在内存中分块存储。可以用getSegmentSize获得每个块的大小,用getDataSegment获得首个块的地址。它返回一个二级指针,指向一个指针数组,这个数组中的每个元素指向每个块的数据数组:
// ...
else {
int size = x->size();
int segmentSize = x->getSegmentSize();
double **segments = (double **) x->getDataSegment();
INDEX start = 0;
int segmentId = 0;
double logSum = 0;
while (start < size) {
double *block = segments[segmentId];
int blockSize = std::min(segmentSize, size - start);
for (int i = 0; i < blockSize; i++) {
if (block[i] != DBL_NMIN) // is not NULL
logSum += std::log(block[i]);
}
start += blockSize;
segmentId++;
}
return new Double(logSum);
}在实际开发中,数组的底层存储不一定是double类型。用户需要考虑具体类型。本例采用了泛型编程统一处理不同类型,具体代码参见附件。
3.2 在DolphinDB中调用函数
通常需要实现一个聚合函数的非分布式版本和分布式版本,系统会基于哪个版本更高效来选择调用这个版本。
在DolphinDB中定义非分布式的geometricMean函数:
def geometricMean(x) {
return exp(logSum::logSum(x) \ count(x))
}然后通过定义Map和Reduce函数,最终用mapr定义分布式的版本:
def geometricMeanMap(x) {
return logSum::logSum(x)
}
defg geometricMeanReduce(myLogSum, myCount) {
return exp(sum(myLogSum) \ sum(myCount))
}
mapr geometricMean(x) { geometricMeanMap(x), count(x) -> geometricMeanReduce }这样就实现了geometricMean函数。
如果是在单机环境中执行这个函数,只需要在执行的节点上加载插件。如果有数据位于远程节点,需要在每一个远程节点加载插件。可以手动在每个节点执行loadPlugin函数,也可以用以下脚本快速在每个节点上加载插件:
each(rpc{, loadPlugin, pathToPlugin}, getDataNodes())通过以下脚本创建一个分区表,验证函数:
db = database("", VALUE, 1 2 3 4)
t = table(take(1..4, 100) as id, rand(1.0, 100) as val)
t0 = db.createPartitionedTable(t, `tb, `id)
t0.append!(t)
select geometricMean(val) from t0 group by id3.3 随机访问大数组
可以对大数组进行随机访问,但要经过下标计算。用getSegmentSizeInBit函数获得块大小的二进制位数,通过位运算获得块的偏移量和块内偏移量:
int segmentSizeInBit = x->getSegmentSizeInBit();
int segmentMask = (1 << segmentSizeInBit) - 1;
double **segments = (double **) x->getDataSegment();
int index = 3000000; // 想要访问的下标
double result = segments[index >> segmentSizeInBit][index & segmentMask];
// ^ 块的偏移量 ^ 块内偏移量3.4 应该选择哪种方式访问向量
上一章介绍了通过getDoubleConst,getIntConst等一族方法获得只读缓冲区,以及通过getDoubleBuffer,getIntBuffer等一族方法获得可读写缓冲区,这两种访问向量的方法。本章介绍了通过getDataArray和getDataSegment方法直接访问向量的底层存储。在实际开发中,前一种方法更通用,一般应该选择前一种方法。但在某些特别的场合(例如明确知道数据存储在大数组中,且知道数据的类型),可以采用第二种方法。
4. 如何开发支持新的分布式算法的插件函数
在DolphinDB中,Map-Reduce是执行分布式算法的通用计算框架。DolphinDB提供了mr函数和imr函数,使用户能通过脚本实现分布式算法。而在编写分布式算法的插件时,使用的同样是这两个函数。本章主要介绍如何用C++语言编写自定义的map, reduce等函数,并调用mr和imr两个函数,最终实现分布式计算。
4.1 分布式算法范例
本章将以mr为例,实现一个函数,求分布式表中相应列名的所有列平均值,介绍编写DolphinDB 分布式算法插件的整体流程,及需要注意的技术细节。
在插件开发中,用户自定义的map, reduce, final, term函数,可以是运算符函数,也可以是系统函数。
本例的map函数,对表的一个分区内对应列名的列做计算,返回一个长度为2的元组,分别包含数据的和,及数据非空元素的个数。具体实现如下:
ConstantSP columnAvgMap(Heap *heap, vector<ConstantSP> &args) {
TableSP table = args[0];
ConstantSP colNames = args[1];
double sum = 0.0;
int count = 0;
for (int i = 0; i < colNames->size(); i++) {
string colName = colNames->getString(i);
VectorSP col = table->getColumn(colName);
sum += col->sum()->getDouble();
count += col->count();
}
ConstantSP result = Util::createVector(DT_ANY, 2);
result->set(0, new Double(sum));
result->set(1, new Int(count));
return result;
}本例的reduce函数,是对map结果的相加。DolphinDB的内置函数add就提供了这个功能,可以用heap->currentSession()->getFunctionDef("add")获得这个函数:
FunctionDefSP reduceFunc = heap->currentSession()->getFunctionDef("add");本例的final函数,是对reduce结果中的数据总和sum和非空元素个数count做除法,求得所有分区中对应列的平均数。具体实现如下:
ConstantSP columnAvgFinal(const ConstantSP &result, const ConstantSP &placeholder) {
double sum = result->get(0)->getDouble();
int count = result->get(1)->getInt();
return new Double(sum / count);
}定义了map, reduce, final等函数后,将它们导出为插件函数(在头文件的函数声明前加上extern "C",并在加载插件的文本文件中列出这些函数),然后通过heap->currentSession->getFunctionDef获取这些函数,就能以这些函数为参数调用mr函数。如:
FunctionDefSP mapFunc = Heap->currentSession()->getFunctionDef("columnAvg::columnAvgMap");在本例中,map函数接受两个参数table和colNames,但mr只允许map函数有一个参数,因此需要以部分应用的形式调用map函数,可以用Util::createPartialFunction将它包装为部分应用,实现如下:
vector<ConstantSP> mapWithColNamesArgs {new Void(), colNames};
FunctionDefSP mapWithColNames = Util::createPartitalFunction(mapFunc, mapWithColNamesArgs);用heap->currentSession()->getFunctionDef("mr")获得系统内置函数mr,调用mr->call方法,就相当于在DolphinDB脚本中调用mr函数。最后实现的columnAvg函数定义如下:
ConstantSP columnAvg(Heap *heap, vector<ConstantSP> &args) {
ConstantSP ds = args[0];
ConstantSP colNames = args[1];
FunctionDefSP mapFunc = heap->currentSession()->getFunctionDef("columnAvg::columnAvgMap");
vector<ConstantSP> mapWithColNamesArgs = {new Void(), colNames};
FunctionDefSP mapWithColNames = Util::createPartialFunction(mapFunc, mapWithColNamesArgs); // columnAvgMap{, colNames}
FunctionDefSP reduceFunc = heap->currentSession()->getFunctionDef("add");
FunctionDefSP finalFunc = heap->currentSession()->getFunctionDef("columnAvg::columnAvgFinal");
FunctionDefSP mr = heap->currentSession()->getFunctionDef("mr"); // mr(ds, columnAvgMap{, colNames}, add, columnAvgFinal)
vector<ConstantSP> mrArgs = {ds, mapWithColNames, reduceFunc, finalFunc};
return mr->call(heap, mrArgs);
}4.2 在DolphinDB中调用函数
如果是在单机环境中执行这个函数,只需要在执行的节点上加载插件。但如果有数据位于远程节点,需要在每一个远程节点加载插件。可以手动在每个节点执行loadPlugin函数,也可以用以下脚本快速在每个节点上加载插件:
each(rpc{, loadPlugin, pathToPlugin}, getDataNodes())加载插件后,用sqlDS函数生成数据源,并调用函数:
n = 100
db = database("dfs://testColumnAvg", VALUE, 1..4)
t = db.createPartitionedTable(table(10:0, `id`v1`v2, [INT,DOUBLE,DOUBLE]), `t, `id)
t.append!(table(take(1..4, n) as id, rand(10.0, n) as v1, rand(100.0, n) as v2))
ds = sqlDS(<select * from t>)
columnAvg::columnAvg(ds, `v1`v2)5.如何开发支持流数据处理的插件函数
在DolphinDB中,流数据订阅端可以通过一个handler函数处理收到的数据。订阅数据可以是一个数据表,或一个元组,由subsrciebeTable函数的msgAsTable参数决定。通常可以用handler函数对流数据进行过滤、插入另一张表等操作。
本章将编写一个handler函数。它接受的消息类型是元组。另外接受两个参数:一个是int类型的标量或向量indices,表示元组中元素的下标,另一个是一个表table。它将元组中对应下标的列插入到表中。
向表中添加数据的接口是bool append(vector<ConstantSP>& values, INDEX& insertedRows, string& errMsg),如果插入成功,返回true,并向insertedRows中写入插入的行数。否则返回false,并在errMsg中写入出错信息。插件的实现如下:
ConstantSP handler(Heap *heap, vector<ConstantSP> &args) {
ConstantSP indices = args[0];
TableSP table = args[1];
ConstantSP msg = args[2];
vector<ConstantSP> msgToAppend;
for (int i = 0; i < indices->size(); i++) {
int index = indices->get(i);
msgToAppend.push_back(msg->get(index));
}
INDEX insertedRows;
string errMsg;
table->append(msgToAppend, insertedRows, errMsg);
return new Void();
}在实际应用中,可能需要知道插入出错时的原因。可以引入头文件Logger.h,将出错信息写入日志中。注意需要在编译插件时加上宏定义-DLOGGING_LEVEL_2:
// ...
bool success = table->append(msgToAppend, insertedRows, errMsg);
if (!success)
LOG_ERR("Failed to append to table: ", errMsg);可以用以下脚本模拟流数据写入,验证handler函数:
loadPlugin("/path/to/PluginHandler.txt")
share streamTable(10:0, `id`sym`timestamp, [INT,SYMBOL,TIMESTAMP]) as t0
t1 = table(10:0, `sym`timestamp, [SYMBOL,TIMESTAMP])
subscribeTable(, `t0, , , handler::handler{[1,2], t1})
t0.append!(table(1..100 as id, take(`a`b`c`d, 100) as symbol, now() + 1..100 as timestamp))
select * from t16.如何开发支持外部数据源的插件函数
在为第三方数据设计可扩展的接口插件时,有几个需要关注的问题:
- 数据源(Data source)。数据源是一个特殊的数据对象,包含了数据实体的元描述,执行一个数据源能获得数据实体,可能是表、矩阵、向量等等。用户可以提供数据源调用
olsEx,randomForestClassifier等分布式计算函数,也可以调用mr,imr或ComputingModel.h中定义的更底层的计算模型做并行计算。DolphinDB的内置函数sqlDS就通过SQL表达式获取数据源。在设计第三方数据接口时,通常需要实现一个获取数据源的函数,它将大的文件分成若干个部分,每部分都表示数据的一个子集,最后返回一个数据源的元组。数据源一般用一个Code object表示,是一个函数调用,它的参数是元数据,返回一个表。 - 结构(Schema)。表的结构描述了表的列数,每一列的列名和数据类型。第三方接口通常需要实现一个函数,快速获得数据的表结构,以便用户在这个结构的基础上调整列名和列的数据类型。
- IO问题。在多核多CPU的环境中,IO可能成为瓶颈。DolphinDB提供了抽象的IO接口,
DataInputStream和DataOutputStream,这些接口封装了数据压缩,Endianness,IO类型(网络,磁盘,buffer等)等细节,方便开发。此外还特别实现了针对多线程的IO实现,BlockFileInputStream和BlockFileOutputStream。这个实现有两个优点:
- 实现计算和IO并行。A线程在处理数据的时候,后台线程在异步帮A线程预读取后面需要的数据。
- 避免了多线程的磁盘竞争。当线程个数增加的时候,如果并行往同一个磁盘上读写,性能会急剧下降。这个实现,会对同一个磁盘的读写串行化,从而提高吞吐量。
本章将介绍通常需要实现的几个函数,为设计第三方数据接口提供一个简单的范例。
6.1 数据格式描述
假定本例中的数据储存在平面文件数据库,以二进制格式按行存储,数据从文件头部直接开始存储。每行有四列,分别为id(按有符号64位长整型格式存储,8字节),symbol(按C字符串格式存储,8字节),date(按BCD码格式存储,8字节),value(按IEEE 754标准的双精度浮点数格式存储,8字节),每行共32字节。以下是一行的例子:
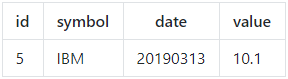
这一行的十六进制表示为:
0x 00 00 00 00 00 00 00 05
0x 49 42 4D 00 00 00 00 00
0x 02 00 01 09 00 03 01 03
0x 40 24 33 33 33 33 33 336.2 extractMyDataSchema函数
这个函数提取数据文件的表结构。在本例中,表结构是确定的,不需要实际读取文件。该函数提供了一个如何生成表结构的范例。它通过Util::createTable函数创建一张结构表:
ConstantSP extractMyDataSchema(const ConstantSP &placeholderA, const ConstantSP &placeholderB) {
ConstantSP colNames = Util::createVector(DT_STRING, 4);
ConstantSP colTypes = Util::createVector(DT_STRING, 4);
string names[] = {"id", "symbol", "date", "value"};
string types[] = {"LONG", "SYMBOL", "DATE", "DOUBLE"};
colNames->setString(0, 4, names);
colTypes->setString(0, 4, types);
vector<ConstantSP> schema = {colNames, colTypes};
vector<string> header = {"name", "type"};
return Util::createTable(header, schema);
}在实际开发中,可能需要以读取文件头等方式获得表结构。如何读文件将在后面介绍。
6.3 loadMyData函数
loadMyData函数读取文件,并输出一张DolphinDB表。给定一个文件的路径,可以通过Util::createBlockFileInputStream创建一个输入流,此后,可对这个流调用readBytes函数读取给定长度的字节,readBool读取下一个bool值,readInt读取下一个int值,等等。本例给loadMyData函数设计的语法为:loadMyData(path, [start], [length])。除了接受文件路径path,还接受两个int类型的参数start和length,分别表示开始读取的行数和需要读取的总行数。createBlockFileInputStream函数可以通过参数决定开始读取的字节数和需要读取的总字节数:
ConstantSP loadMyData(Heap *heap, vector<ConstantSP> &args) {
ConstantSP path = args[0];
long long fileLength = Util::getFileLength(path->getString());
size_t bytesPerRow = 32;
int start = args.size() >= 2 ? args[1]->getInt() : 0;
int length = args.size() >= 3 ? args[2]->getInt() : fileLength / bytesPerRow - start;
DataInputStreamSP inputStream = Util::createBlockFileInputStream(path->getString(), 0, fileLength, Util::BUF_SIZE, start * bytesPerRow, length * bytesPerRow);
char buf[Util::BUF_SIZE];
size_t actualLength;
while (true) {
inputStream->readBytes(buf, Util::BUF_SIZE, actualLength);
if (actualLength <= 0)
break;
// ...
}
}在读取数据时,通常将数据缓存到数组中,等待缓冲区满后批量插入。例如,假定要读取一个内容全为char类型字节的二进制文件,将它写入一个char类型的DolphinDB向量vec。最后返回只由vec一列组成的表:
char buf[Util::BUF_SIZE];
VectorSP vec = Util::createVector(DT_CHAR, 0);
size_t actualLength;
while (true) {
inputStream->readBytes(buf, Util::BUF_SIZE, actualLength);
if (actualLength <= 0)
break;
vec->appendChar(buf, actualLength);
}
vector<ConstantSP> cols = {vec};
vector<string> colNames = {"col0"};
return Util::createTable(colNames, cols);本节的完整代码请参考附件中的代码。在实际开发中,加载数据的函数可能还会接受表结构参数schema,按实际需要改变读取的数据类型。
6.4 loadMyDataEx函数
loadMyData函数总是将数据加载到内存,当数据文件非常庞大时,工作机的内存很容易成为瓶颈。所以设计loadMyDataEx函数解决这个问题。它通过边导入边保存的方式,把静态的二进制文件以较为平缓的数据流的方式保存为DolphinDB的分布式表,而不是采用全部导入内存再存为分区表的方式,从而降低内存的使用需求。
loadMyDataEx函数的参数可以参考DolphinDB内置函数loadTextEx。它的语法是:loadMyDataEx(dbHandle, tableName, partitionColumns, path, [start], [length])。如果数据库中的表存在,则将导入的数据添加到已有的表result中。如果表不存在,则创建一张表result,然后添加数据。最后返回这张表:
string dbPath = ((SystemHandleSP) db)->getDatabaseDir();
vector<ConstantSP> existsTableArgs = {new String(dbPath), tableName};
bool existsTable = heap->currentSession()->getFunctionDef("existsTable")->call(heap, existsTableArgs)->getBool(); // 相当于existsTable(dbPath, tableName)
ConstantSP result;
if (existsTable) { // 表存在,直接加载表
vector<ConstantSP> loadTableArgs = {db, tableName};
result = heap->currentSession()->getFunctionDef("loadTable")->call(heap, loadTableArgs); // 相当于loadTable(db, tableName)
}
else { // 表不存在,创建表
TableSP schema = extractMyDataSchema(new Void(), new Void());
ConstantSP dummyTable = DBFileIO::createEmptyTableFromSchema(schema);
vector<ConstantSP> createTableArgs = {db, dummyTable, tableName, partitionColumns};
result = heap->currentSession()->getFunctionDef("createPartitionedTable")->call(heap, createTableArgs); // 相当于createPartitionedTable(db, dummyTable, tableName, partitionColumns)
}读取数据并添加到表中的代码实现采用了Pipeline框架。它的初始任务是一系列具有不同start参数的loadMyData函数调用,pipeline的follower函数是一个部分应用append!{result},相当于把整个读取数据的任务分成若干份执行,调用loadMyData分块读取后,将相应的数据通过append!插入表中。核心部分的代码如下:
int sizePerPartition = 16 * 1024 * 1024;
int partitionNum = fileLength / sizePerPartition;
vector<DistributedCallSP> tasks;
FunctionDefSP func = Util::createSystemFunction("loadMyData", loadMyData, 1, 3, false);
int partitionStart = start;
int partitionLength = length / partitionNum;
for (int i = 0; i < partitionNum; i++) {
if (i == partitionNum - 1)
partitionLength = length - partitionLength * i;
vector<ConstantSP> partitionArgs = {path, new Int(partitionStart), new Int(partitionLength)};
ObjectSP call = Util::createRegularFunctionCall(func, partitionArgs); // 将会调用loadMyData(path, partitionStart, partitionLength)
tasks.push_back(new DistributedCall(call, true));
partitionStart += partitionLength;
}
vector<ConstantSP> appendToResultArgs = {result};
FunctionDefSP appendToResult = Util::createPartialFunction(heap->currentSession()->getFunctionDef("append!"), appendToResultArgs); // 相当于append!{result}
vector<FunctionDefSP> functors = {appendToResult};
PipelineStageExecutor executor(functors, false);
executor.execute(heap, tasks);本节的完整代码请参考附件中的代码。用Pipeline框架实现数据的分块导入,只是一种思路。在具体开发时,可以采用ComputingModel.h中声明的StaticStageExecutor,也可以使用Concurrent.h中声明的线程模型Thread。实现方法有很多种,需要根据实际场景选择。
6.5 myDataDS函数
myDataDS函数返回一个数据源的元组。每个数据源都是一个表示函数调用的Code object,可以通过Util::createRegularFunctionCall生成。执行这个对象可以取得对应的数据。以下是基于loadMyData函数产生数据源的一个例子:
ConstantSP myDataDS(Heap *heap, vector<ConstantSP> &args) {
ConstantSP path = args[0];
long long fileLength = Util::getFileLength(path->getString());
size_t bytesPerRow = 32;
int start = args.size() >= 2 ? args[1]->getInt() : 0;
int length = args.size() >= 3 ? args[2]->getInt() : fileLength / bytesPerRow - start;
int sizePerPartition = 16 * 1024 * 1024;
int partitionNum = fileLength / sizePerPartition;
int partitionStart = start;
int partitionLength = length / partitionNum;
FunctionDefSP func = Util::createSystemFunction("loadMyData", loadMyData, 1, 3, false);
ConstantSP dataSources = Util::createVector(DT_ANY, partitionNum);
for (int i = 0; i < partitionNum; i++) {
if (i == partitionNum - 1)
partitionLength = length - partitionLength * i;
vector<ConstantSP> partitionArgs = {path, new Int(partitionStart), new Int(partitionLength)};
ObjectSP code = Util::createRegularFunctionCall(func, partitionArgs); // 将会调用loadMyData(path, partitionStart, partitionLength)
dataSources->set(i, new DataSource(code));
}
return dataSources;
}教程中的完整代码见https://github.com/dolphindb/Tu