今天在尝试把BERT模型从单GPU训练转换到多GPU训练中,步骤如下:
原:
# Prepare model
model = BertForMultipleChoice.from_pretrained(args.bert_model,
cache_dir=PYTORCH_PRETRAINED_BERT_CACHE / 'distributed_{}'.format(args.local_rank),
num_choices=4)
model.to(device)
改后:
import torch.nn as nn
# Prepare model
model = BertForMultipleChoice.from_pretrained(args.bert_model,
cache_dir=PYTORCH_PRETRAINED_BERT_CACHE / 'distributed_{}'.format(args.local_rank),
num_choices=4)
if torch.cuda.device_count() > 1: # Returns the number of GPUs available
logger.info("***** GPUsnum *****")
logger.info("device: {} ({}) {}".format(device, torch.cuda.get_device_name(0), n_gpu))
logger.info(type(n_gpu))
model = nn.DataParallel(model)
model.to(device)
其实也没花多少功夫,但在找这个方法的时候花了不少时间,看了其他人的解决方案,如何进行单机多GPU训练,如上代码,主要是加入了并行nn.DataParallel。
但在训练时发现出现以下问题,之前也遇到这个问题,当时是修改了pytorch中的源码中的某行代码解决。
问题如下:
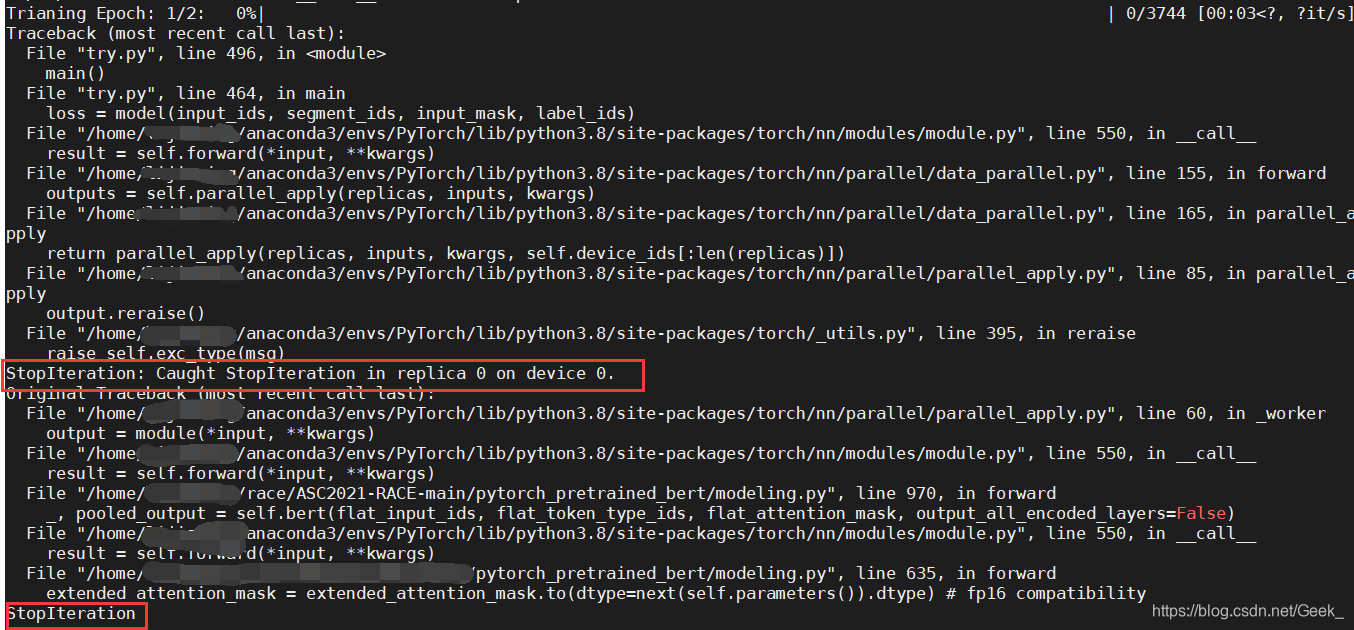
原因
问题是多gpu进行模型训练的时候产生的,具体为,不能够用多gpu加载预训练的bert。应该是torch版本的问题。其中torch1.5以上版本都可能会出现这个问题,据解决方案替换为torch1.4可以解决该问题。
解决办法
最后我采用的是将报错的那行代码进行修改,
进入到报错的最后一行,
将
extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility
改为
extended_attention_mask = extended_attention_mask.to(dtype=torch.float32)
暴力但有效。