寻找真命天子……
完成find()函数,用它过滤出ADS列表中所有运动迷,同时他们不能是
Bieber的粉丝。
#include <stdio.h>#include <stdlib.h>#include <string.h>int NUM_ADS = 7;char *ADS[] = {
"William: SBM GSOH likes sports, TV, dining", "Matt: SWM NS likes art, movies, theater", "Luis: SLM ND likes books, theater, art", "Mike: DWM DS likes trucks, sports and bieber", "Peter: SAM likes chess, working out and art", "Josh: SJM likes sports, movies and theater", "Jed: DBM likes theater, books and dining" };void find() {
int i; puts("Search results:"); puts("------------------------------------"); for (i = 0; i < NUM_ADS; i++) {
// if ( strstr(ADS[i],"sports")!=NULL && strstr(ADS[i],"bieber")==NULL) {
// 上面的可以简化为: if (strstr(ADS[i], "sports") && !strstr(ADS[i], "bieber")) {
printf("%s\n", ADS[i]); } } puts("------------------------------------");// printf("sizeof(ADS)=%i\n", sizeof(ADS)); // 结果是 sizeof(ADS)=56}int main() {
find(); return 0;}
运行结果:
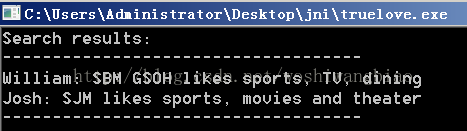
现在,加入需求改成过滤出ADS列表中所有戏剧迷,该怎么做?
你可能第一感觉就是复制函数然后修改一下。但是...
复制函数会产生很多重复代码
C程序经常会执行一些大同小异的任务,现在 find() 函数为了
搜索匹配字符串,会遍历数组中所有元素,并测试每个字符
串,
而这些测试会写死在代码中,也就是说函数永远只能做一
种测试。
当然也可以把字符串作为参数传递给函数,让函数搜索不同的子串,
但这样 find() 还是无法检查3个字符串,比如“arts”、“theater”
和“dining”。你需要的是一种截然不同的技术。
把代码传给函数
你需要把测试代码传给 find() 函数,如果有办法把代码打
包传给函数,就相当于传给 find() 函数一台测试机,函数
再用测试机测试所有数据。
这样一来 find() 函数中大部分代码可以原封不动。代码
还是要检查数组中所有元素,并显示相同的输出,只是测
试数组元素的代码是你传给它的。
要是把函数名告诉find(),find就可以执行该函数就好了。
函数名是指向函数的指针 …
在C语言中,函数名也是指针变量。当你创建了一个叫
go_to_warp_speed(int speed) 函数的同时也会创
建了一个叫 go_to_warp_speed 的指针变量,
变量中
保存了函数的地址。只要把函数指针类型的参数传给
find() ,就能调用它指向的函数了。
(注:
两者并不完全相同,函数名是L-value,而指针变量是R-value,因此函
数名不能像指针变量那样自加或自减。
)
如何创建函数指针
int go_to_warp_speed(int speed){
...}// 创建一个叫warp_fn的变量,用来保存go_to_warp_speed()函数的地址。int (*warp_fn)(int); // 第一个int是函数返回值,第二个是函数的参数,可以再加,中间的是函数指针名warp_fn = go_to_warp_speed;warp_fn(4); // 相当于调用go_to_warp_speed(4)。
一旦声明了函数指针变量,就可以
像其他变量一样使用它,可以对它赋值,也可以把它加
到数组中,还可以把它传给函数……
#include <stdio.h>#include <stdlib.h>#include <string.h>int NUM_ADS = 7;char *ADS[] = {
"William: SBM GSOH likes sports, TV, dining", "Matt: SWM NS likes art, movies, theater", "Luis: SLM ND likes books, theater, art", "Mike: DWM DS likes trucks, sports and bieber", "Peter: SAM likes chess, working out and art", "Josh: SJM likes sports, movies and theater", "Jed: DBM likes theater, books and dining" };int sports_no_bieber(char *s) {
return strstr(s, "sports") && !strstr(s, "bieber");}int sports_or_workout(char *s) {
return strstr(s, "sports") || strstr(s, "working out");}int ns_theater(char *s) {
return strstr(s, "theater") && strstr(s, "NS");}int arts_theater_or_dining(char *s) {
return strstr(s, "art") || strstr(s, "theater") || strstr(s, "dining");}// 调用函数指针变量,将函数名当参数传递进去//void find(int match(char *s)) { 这种竟然也可以,奇怪?---->可加也可不加void find(int (*match)(char *s)) {
int i; puts("Search results:"); puts("------------------------------------"); for (i = 0; i < NUM_ADS; i++) {
if ((*match)(ADS[i])) {
// 也可以这样写// if (match(ADS[i])) {
printf("%s\n", ADS[i]); } } puts("------------------------------------");}int main(void) {
// find(sports_no_bieber);- find(&sports_no_bieber); // 这样也可以
- find(*sports_no_bieber); // 也可以这样写,因为是指针
find(sports_or_workout); find(ns_theater); find(arts_theater_or_dining); return EXIT_SUCCESS;}
运行结果:
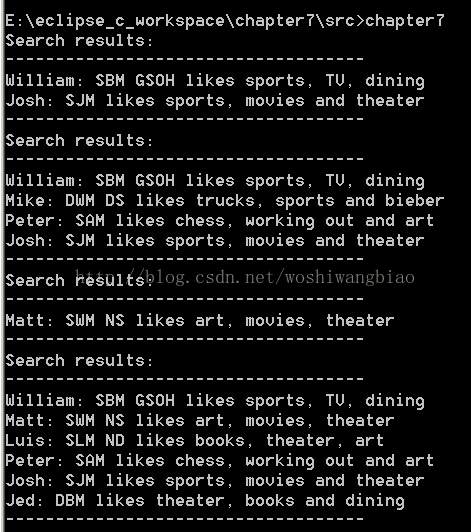
有了函数指针,就
能把函数传给函数,用更少的代码创建功能更强大的程序,
这就是为什么说函数指针是C语言最强大的特性之一。
问: 如果函数指针是指针,为什么调用函数时不需要在它们前面加*?
答 : 可 加 也 可 不 加 , 可 以
把代码中的match(ADS[i])换成
(*match)(ADS[i])。
问: 我可以用&取得函数的地址吗?
答: 当然,除了find(sports
_or_workout),还可以写find
(&sports_or_workout)。
问: 那为什么不这么写?
答: 即使省略*和&,C编译器也
能识别它们,这样代码更好读。
用C标准库中的函数指针排序
可能你已经猜到了答案:C标准库的排序函数会接收一个
比较器函数(comparator function)指针,用来判断两条数
据是大于、小于还是等于。
qsort() 函数看起来像这样:
qsort(void *array, // 数组指针 size_t length, // 数组长度 size_t item_size, // 数组中每个元素的长度 int (*compar)(const void *, const void *)) ; // compar是用来比较数组中两项数据大小的函数指针,void*指针可以指向任何数据类型
qsort() 函数会反复比较两个数据的大小,如果顺序颠倒,
计算机会交换它们。
这就是为什么要使用比较器函数。它会告诉 qsort() 两个
元素哪个排在前面,它会返回三种值:
1.如果第一个值比第二个值大,就返
回 正数。
2.如果第一个值比第二个值小,就返
回 负数。
3.如果两个值相等,就返
回 0。
怎么写一个比较器函数
假设有一个整型数组,你想升序排列它们
int scores[] = {
543,323,32,554,11,3,112};
你观察 qsort() 接收的比较器函数的签名,会发现它接收两个
void* ,也就是两个void指针。
void指针可以保存 任何 类型数据的地址,但使用前必须先把它
转换为具体类型。
qsort() 函数会两两比较数组元素,然后以正确的顺序排列它
们。 qsort() 通过调用传给它的比较器函数来比较两个元素的大
小:
int compare_scores(const void* score_a, const void* score_b){
...}
值以指针的形式传给函数,因此要做的第一件事就是从指针中提
取整型值。
int a = *(int*)score_a; // 先把void指针强转成int指针,然后用*取出指针存的值int b = *(int*)score_b;
如果 a 大于 b ,需要返回正数;如果 a 小于 b ,就返
回负数;如果相等,返回0值。对整型来讲这很简
单,只要将两数相减就行了:
return a - b;
下面是用 qsort() 排序这个数组的方法:
int qsort(scores, 7, sizeof(int), compare_scores);
代码示例:
#include <stdio.h>#include <string.h>//升序排列整型得分int compare_scores(const void* score_a, const void* score_b) {
int a = *(int*) score_a; int b = *(int*) score_b; return a - b;}//降序排列整型得分int compare_scores_desc(const void* score_a, const void* score_b) {
int a = *(int*) score_a; int b = *(int*) score_b; return b - a;}typedef struct {
int width; int height;} rectangle;//按面积从小到大排列矩形。int compare_areas(const void* rectangle_a, const void* rectangle_b) {
rectangle a = *(rectangle*) rectangle_a; rectangle b = *(rectangle*) rectangle_b; return (a.width * a.height) - (b.width * b.height);}//按字母序排列名字,区分大小写int compare_names(const void* name_a, const void* name_b) {
// char* a = *(char**) name_a;// char* b = *(char**) name_b;// return strcmp(a, b); // 或者像这样 char** a = (char**) name_a; char** b = (char**) name_b;// return strcmp(*a, *b); // 倒序 return strcmp(*b,*a);}int qsort(void *array, size_t length, size_t item_size, int (*compar)(const void *, const void *));int main() {
int scores[] = {
543, 323, 32, 554, 11, 3, 112 }; qsort(scores,7,sizeof(int),compare_scores); qsort(scores, 7, sizeof(int), compare_scores_desc); int i; for (i = 0; i < 7; i++) {
printf("scores[%i]=%i\n", i, scores[i]); } rectangle recs[] = {
{
10, 20 }, {
5, 5 } }; qsort(recs, 2, sizeof(rectangle), compare_areas); for (i = 0; i < 2; i++) {
printf("recs[%i]={%i,%i}\n", i, recs[i].width, recs[i].height); } char *names[] = {
"Karen", "Mark", "Brett", "molly" }; qsort(names, 4, sizeof(char*), compare_names); puts("These are the names in order:"); for (i = 0; i < 4; i++) {
printf("%s\n", names[i]); } // 漏了下面这个的话会报此警告: control reaches end of non-void function return 0;}
运行结果:
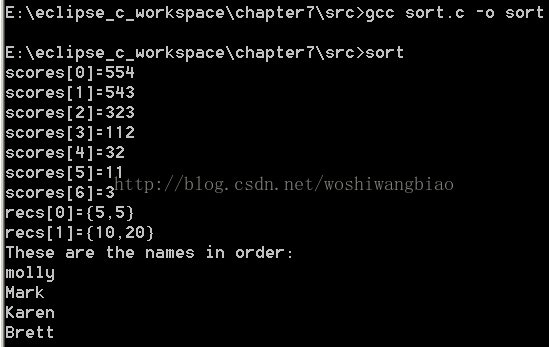
问: 用来给字符串数组排序的比较器函数使用了char**,它是什么意思?
答: 字符串数组中的每一项都
是字符指针(char*),当qsort()
调用比较器函数时,会发送两个指向
数组元素的指针,也就是说比较器函
数接收到的是指向字符指针的指针,
在C语言中就是char**。
问: qsort()会创建新数组吗?
答: 不会,qsort()在原数组上
进行改动。
分手信自动生成器
假设你在写一个群发邮件的程序,向不同人发送不同类型
的消息,一种创建回复数据的方法是使用结构:
enum response_type {
DUMP, SECOND_CHANCE, MARRIAGE}; // 回复类型枚举
typedef struct {
char *name; enum response_type type; // 在每条回复数据中记录回复类型} response;
在使用新数据类型 response 时需
要根据回复类型分别调用以下三个函数:
void dump(response r){
printf("Dear %s,\n", r.name); puts("Unfortunately your last date contacted us to"); puts("say that they will not be seeing you again");}void second_chance(response r){
printf("Dear %s,\n", r.name); puts("Good news: your last date has asked us to"); puts("arrange another meeting. Please call ASAP.");}void marriage(response r){
printf("Dear %s,\n", r.name); puts("Congratulations! Your last date has contacted"); puts("us with a proposal of marriage.");}
下面就来
看看如何根据 response 数组批量生成回复。
int main() {
//传统方式 response r[] = {
{
"Mike", DUMP }, {
"Luis", SECOND_CHANCE }, {
"Matt", SECOND_CHANCE }, {
"William", MARRIAGE } }; int i; for (i = 0; i < 4; i++) {
switch (r[i].type) {
case DUMP: dump(r[i]); break; case SECOND_CHANCE: second_chance(r[i]); break; default: marriage(r[i]); } }
运行结果:
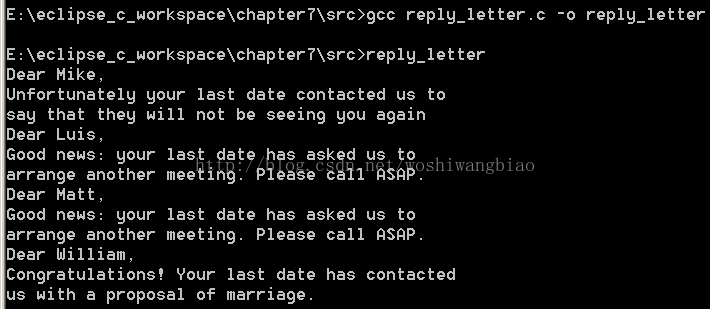
问题来了
程序正确运行了,但代码中充斥着大量函数调用,每次
都需要根据回复类型来调用函数,如果增加第四种回复类型,你就不得不修改程序
中每一个像这样的地方。很快,就有一大堆代码
需要维护,而且这样很容易出错。
创建函数指针数组
创建一个与回复类型一一对应的函数指针数组就可以解决上面的问题。
在此之前,我们先看看怎么创建函数指针数组
:
void (*replies[])(response) = {
dump, second_chance, marriage};// void--->函数返回类型// replies--->函数指针数组名// response--->函数的参数
如何用数组解决刚才的问题?
观察数组,函数名的顺序与枚举类型的顺序完全相同,这点很重要,因为当C语言在创建枚举时会给每个符号分配一个
从0开始的数字,
所以 DUMP == 0, SECOND_CHANCE == 1 , 而
MARRIAGE == 2 ,也就是说可以通过 response_type 当作数组角标来获取数
组中的函数指针。
//因为 replies[SECOND_CHANCE] == second_chance; // 所以可以这样来拿到数组中的函数
用指针数组形式修改之前的代码:
- #include <stdio.h>
#include <stdlib.h>#include <string.h>enum response_type {
DUMP, SECOND_CHANCE, MARRIAGE, LAW_SUIT};typedef struct {
char *name; enum response_type type;} response;// 抛弃void dump(response r) {
printf("Dear %s,\n", r.name); puts("Unfortunately your last date contacted us to"); puts("say that they will not be seeing you again");}void second_chance(response r) {
printf("Dear %s,\n", r.name); puts("Good news: your last date has asked us to"); puts("arrange another meeting. Please call ASAP.");}void marriage(response r) {
printf("Dear %s,\n", r.name); puts("Congratulations! Your last date has contacted"); puts("us with a proposal of marriage.");}void law_suit(response r) {
printf("Dear %s,\n", r.name); puts("Sorry,Sorry,Sorry,Sorry,Sorry,Sorry,Sorry,");}int main() {
- // 用函数指针数组的方式
puts("用函数指针数组的方式"); response r[] = {
{
"Mike", DUMP }, {
"Luis", SECOND_CHANCE }, {
"Matt", SECOND_CHANCE }, {
"William", MARRIAGE }, {
"Miky", LAW_SUIT } }; void (*fn_replies[])(response r) = {
dump, second_chance, marriage,law_suit }; int i; for (i = 0; i < 5; i++) {
// fn_replies[i](r[i]); 为什么这里用i运行报错,而用0,1,2,3等数字却可以// fn_replies[r[i].type](r[i]); // 下面这种也可以 (*fn_replies[r[i].type])(r[i]); } return 0;}
运行结果:
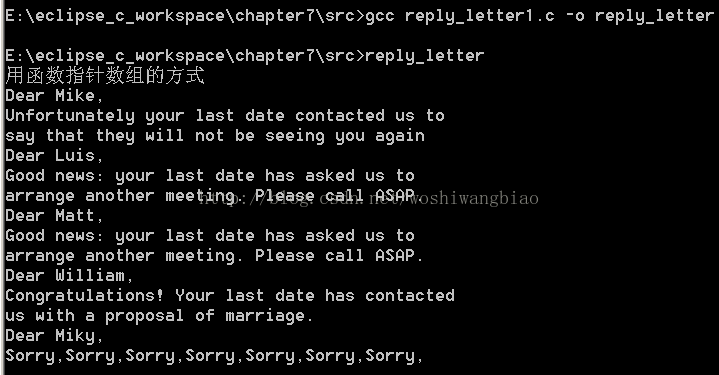
现在你用下面这行代码代替了整个 switch 语句:
(*fn_replies[r[i].type])(r[i]);
如果需要在程序中多次调用回复函数,你不必复制很多代
码,而当决定添加新的回复类型和函数时,只需要把它加
到数组中即可:
enum response_type {
DUMP, SECOND_CHANCE, MARRIAGE, LAW_SUIT};void (*replies[])(response) = {
dump, second_chance, marriage, law_suit};
函数指针数组让代码易于管理,它们让代码变得更短、更易于扩展,从而可以伸缩。
可变参数函数
参数数量可变的函数被称为可变参数函数(variadic
function)。C标准库中有一组宏(macro)可以帮助你
建立自己的可变参数函数。
为了弄清它是如何工作的,
你将创建一个函数打印一连串 int 的函数:(
可以把宏想象成一种特殊类型的
函数,它可以修改源代码
)
print_ints(3, 79, 101, 32); // 假如你想创建这么一个函数,3是要打印几个int,后面三个就是要打印的int值print_ints(4, 79, 101, 32,12); // 这里参数变成了4
那么你可以这样来写:
//必须包含stdarg.h头文件。所有处理可变参数函数的代码都在stdarg.h中。#include <stdarg.h>void print_ints(int args, ...) {
//va_list 用来保存传给函数的其他参数。 va_list ap; // va_start表示可变参数从哪里开始。省略号表示可变参数,不包括args ,args中保存了变量的数目。 va_start(ap, args); int i; //参数现在全保存在 va_list 中,可以用 va_arg 读取它 们。 va_arg 接收两个值: va_list 和要读取参数的类型。// 本例中所有参数都是 int 。 for (i = 0; i < args; i++) {
// args中保存了变量的数目。 printf("argument: %i\n", va_arg(ap, int)); // va_arg(ap, int) 表示依次从ap中拿出int类型的参数 }// 当读完了所有参数,要用 va_end 宏告诉C你做完了。 va_end(ap);}
宏与函数
宏(macro)用来在编译前重写代码,这里的几个宏va_start、va_arg和
va_end看起来很像函数,但实际上隐藏在它们背后的是一些神秘的
指令。在编译前,预处理器会根据这些指令在程序中插入巧妙的代
码。
简单来说,就是可以在编译之前修改源代码。
问: 等等,为什么va_end和va_start叫宏?它们不就是一般的函数吗?
答: 不是,它们只是设计成了
普通函数的样子,预处理会把它们替
换成其他代码。
问: 什么是预处理器?
答: 预处理器在编译阶段之前
运行,它会做很多事情,包括把头文
件包含进代码。
问: 可以只使用可变参数,而不用普通参数吗?
答: 不行,至少需要一个普通
参数,只有这样才能把它的名字传给
va_start。
问: 如果我从va_arg中读取比传给函数更多的参数会怎样?
答: 会发生不确定的错误。
代码示例
Head First酒吧的人想要创建一个函数,能够返回一巡酒的总价,
函数如下:
#include <stdarg.h>#include <stdio.h>// 各种酒enum drink {
MUDSLIDE, FUZZY_NAVEL, MONKEY_GLAND, ZOMBIE};double price(enum drink d) {
switch (d) {
case MUDSLIDE: return 6.79; case FUZZY_NAVEL: return 5.31; case MONKEY_GLAND: return 4.82; case ZOMBIE: return 5.89; } return 0;}double total(int args, ...) {
double total = 0; va_list list; va_start(list, args); int i; for (i = 0; i < args; i++) {
total = total + price(va_arg(list, enum drink)); } // 容易漏掉 // 当读完了所有参数,要用 va_end 宏告诉C你做完了。 va_end(list); return total;}int main() {
printf("Price is %.2f\n", total(3, MONKEY_GLAND, MUDSLIDE, FUZZY_NAVEL)); printf("Price is %.2f\n", total(2, MONKEY_GLAND, MUDSLIDE)); printf("Price is %.2f\n", total(1, ZOMBIE)); printf("Price is %.2f\n", total(0)); printf("Price is %.2f\n", total(1,1,2));}
运行结果:
