注:假设已经懂了简单神经网络
1. 卷积神经网络
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。
卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层(pooling layer)。这一结构使得卷积神经网络能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网络在图像和语音识别方面能够给出更好的结果。这一模型也可以使用反向传播算法进行训练。相比较其他深度、前馈神经网络,卷积神经网络需要考量的参数更少,使之成为一种颇具吸引力的深度学习结构。
2、为什么要进行使用卷积神经网络?
俗话说: “认人先认脸”, 是不是大概其中的含义了, 没理解的话不要紧.
先不用想计算机中是如何实现的,我们在生活中总会有这些场景, 看远处走来的人,总是先看脸识别人(看腿的都是老司机,呵呵!), 因为脸是一个人最明显的特征,在大脑进化过程中已经学到了这点先验知识,所以直接就看脸识别人了,但是计算机可就不这么聪明了,它要识别一个手写数字是几(1?,2?,3?,还是其他识别动物(猫,狗等)),它就会把整个图片做一次运算.
那么问题来了, 对于一张图片(手写数字),它的大小是28*28(像素), 那么识别一遍的过程中就要逐个像素进行计算,最终得到整个图片的特征,然后分出是具体的那个数字,或者是那种动物。那最终的问题就是:
识别图片就要 提取特征, 根据特征分类。放出一张总结图:
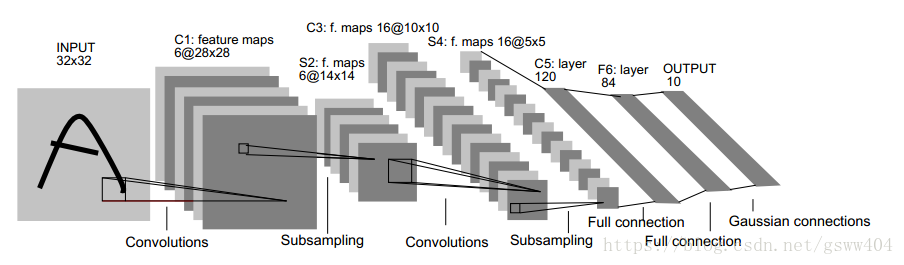
3、具体如何操作呢?
看了上面的图,第一感觉就是把一张图片最终变成了一个向量,然后经过神经网络进行了计算,最终分类,是的,就这样。
进行的第一步操作就是
3.1:卷积
卷积:通过两个函数 和 生成第三个函数的一种数学算子,表征函数f和g经过翻转和平移的重叠部分的面积,数学定义为:
比如,我们原图像是 , 那么我们的任务就是找到并利用 , 最终得到 , 而 就是我们所说的卷积核,该过程就是卷积。好,我们拿到了一张原始的28*28的图,那么首先要做的就是卷积,直接放一张动态图说明:
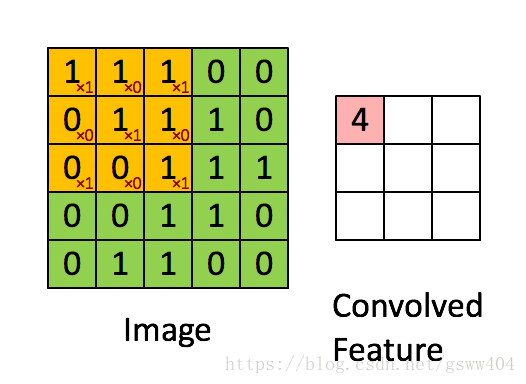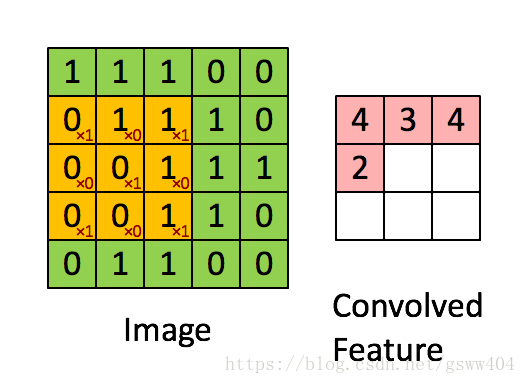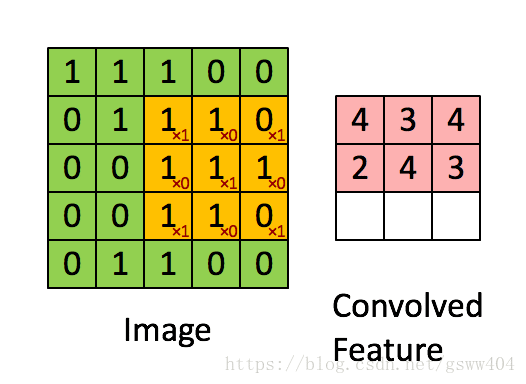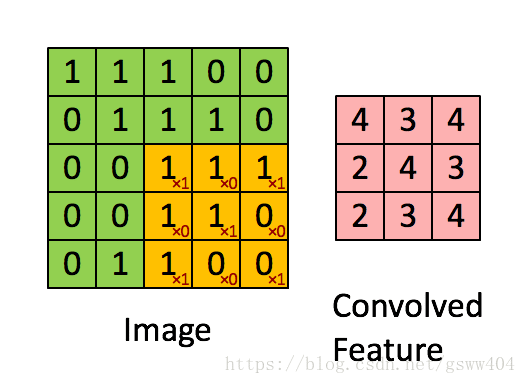
如图:我们看绿色,黄色,粉色三种颜色的矩阵。
绿色:我们的原始图像
黄色: 卷积核
卷积过程就是循环将整个图像与卷积核进行一次点积,得到粉色(我们发现原来的图像变小了?)
问题1: 图像变小了,是不是原来的图像损失了? 答案是肯定是肯定的,因为卷积是有损压缩,它的本质是做了一次聚类处理,对主要特征进行了提取。
注:
(1) 每次黄色框向右,向下都是移动一格,这个就是补步长(stride)
(2) 此处的Padding=0,没有padding的缺点就是中间的图像被多次扫描,但是边上的并没有,造成了边界上的信息的损失。另外加padding的原因就是对一些尺寸有差异的图片进行补齐操作。
3.2 池化过程
进行完卷积操作后,我们发现图片有了明显的缩小,那么为为什么还要进行池化呢?目的是进一步获取更加抽象的信息,防止过拟合,提高泛化能力。(其本质和卷积一样)
常用的池化包括max_pooling, mean_pooling等,一般池化都是(2×2,我也不知道为啥,但是就是效果好)
max_pooling,顾名思义就是找到最大的:例如
1 2
3 2
那么对于这个2×2的池化来说,max_pooling= 3, mean_pooling = 2[(1+2+3+2)/4]
下面我们借助tensorflow实现手写数字的识别!
使用MNIST数据集进行训练,识别图片中的手写数字(0到9共10类)。
思路: 使用一个简单的CNN网络结构如下,括号里边表示tensor经过本层后的输出shape:
输入层(28 * 28 * 1)
卷积层1(28 * 28 * 32)
pooling层1(14 * 14 * 32)
卷积层2(14 * 14 * 64)
pooling层2(7 * 7 * 64)
全连接层(1 * 1024)
softmax层(10)
注: 28×28×1,是指高宽为28×28, 1为通道,卷积层1(28 * 28 * 32) 中的32是指32个卷积核,即每次都是32特征,具体的多核多通道方面的知识参考博客:https://blog.csdn.net/u014114990/article/details/51125776,https://blog.csdn.net/dulingtingzi/article/details/79819513
4、Tesorflow基本函数讲解
1、tf.truncated_normal
tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
# 随机产生一个形状为shape的服从截断正态分布(均值为mean,标准差为stddev)的tensor。截断的方法根据官方API的定义为,如果单次随机生成的值偏离均值2倍标准差之外,就丢弃并重新随机生成一个新的数。2、Conv2d
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None)
"""
input: 是一个形状为[batch, in_height, in_width, in_channels]的tensor:
batch:每次batch数据的数量。
in_height,in_width: 输入矩阵的高和宽,如输入层的图片是28*28,则in_height和in_width就都为28。
in_channels: 输入通道数量。如输入层的图片经过了二值化,则通道为1,如果输入层的图片是RGB彩色的,则通道为3;再如卷积层1有32个通道,则pooling层1的输入(卷积层1的输出)即为32通道。
filter: 是一个形状为[filter_height, filter_width, in_channels, out_channels]的tensor,
filter_height, filter_width是卷积核的高与宽。如卷积层1中的卷积核,filter_height, filter_width都为28。
in_channels: 输入通道数量。
out_channels: 输出通道的数量。如输入数据经过卷积层1后,通道数量从1变为32。
strides
strides: 指滑动窗口(卷积核)的滑动规则,包含4个维度,分别对应input的4个维度,即每次在input tensor上滑动时的步长。其中batch和in_channels维度一般都设置为1,所以形状为[1, stride, stride, 1]。
padding
"""3、POOLing
tf.nn.max_pool(value, ksize, strides, padding, data_format='NHWC', name=None)
value
"""
以tf.nn.conv2d()函数的参数input理解即可。
ksize: 滑动窗口(pool)的大小尺寸,这里注意这个大小尺寸并不仅仅指2维上的高和宽,ksize的每个维度同样对应input的各个维度(只是大小,不是滑动步长),同样的,batch和in_channels维度多设置为1。如pooling层1的ksize即为[1, 2, 2, 1],即用一个2*2的窗口做pooling。
strides: 同tf.nn.conv2d()函数的参数strides。
"""接下来说的一个函数就是dropout,它是一个防止网络结构过拟合的方法,通常就是随机的将网络中的部分权重随机的失效(即,无法使用)
tf.nn.dropout(x, keep_prob, noise_shape=None, seed=None, name=None)5、代码实现
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @File : cnn.py
# @Author: J.Q.Wang
# @Date : 18-5-20
# @Desc :
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
import time
# initialize weight and bias
def weight_variable(shape):
return tf.Variable(tf.truncated_normal(shape, stddev=0.1))
def bias_variable(shape):
return tf.Variable(tf.constant(0.1, shape = shape))
"""
卷积和池化,使用卷积步长为1(stride size),0边距(padding size)
池化用简单传统的2x2大小的模板做max pooling
"""
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize = [1, 2, 2, 1],
strides = [1, 2, 2, 1], padding='SAME')
# 随机取batch个训练样本
def next_batch(train_data, train_target, batch_size):
idx = [ i for i in range(0,len(train_target)) ]
np.random.shuffle(idx);
batch_data = []; batch_target = [];
for i in range(0,batch_size):
batch_data.append(train_data[idx[i]]);
batch_target.append(train_target[idx[i]])
return batch_data, batch_target
start = time.clock() #计算开始时间
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) #MNIST数据输入
train_data = mnist.train.images #55000的数据量
train_target = mnist.train.labels
test_data = mnist.test.images #10000的数据量
test_target = mnist.test.labels
batch_size = 100 #分批次大小
"""
第一层 卷积层
x_image(batch, 28, 28, 1) -> h_pool1(batch, 14, 14, 32)
"""
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
x_image = tf.reshape(x, [-1, 28, 28, 1]) #最后一维代表通道数目,如果是rgb则为3
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
"""
第二层 卷积层
h_pool1(batch, 14, 14, 32) -> h_pool2(batch, 7, 7, 64)
"""
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
"""
第三层 全连接层
h_pool2(batch, 7, 7, 64) -> h_fc1(1, 1024)
"""
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
"""
Dropout
h_fc1 -> h_fc1_drop, 训练中启用,测试中关闭
"""
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
"""
第四层 Softmax输出层
"""
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
"""
训练和评估模型
ADAM优化器来做梯度最速下降,feed_dict中加入参数keep_prob控制dropout比例
"""
cross_entropy = -tf.reduce_sum(y * tf.log(y_conv)) # 计算交叉熵
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) # 使用adam优化器来以0.0001的学习率来进行微调
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y, 1)) # 判断预测标签和实际标签是否匹配
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(500):
batch_data, batch_target = next_batch(train_data, train_target, batch_size)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch_data, y: batch_target, keep_prob: 1.0})
print "step %d, training accuracy %.3f" % (i, train_accuracy)
train_step.run(feed_dict={x: batch_data, y: batch_target, keep_prob: 0.5})
print "Training finished"
for i in range(1):
t_data, t_target = next_batch(test_data, test_target, 5000)
print "test accuracy %.3f" % accuracy.eval(feed_dict={x: t_data, y: t_target, keep_prob: 1.0})
end = time.clock() #计算程序结束时间
print"running time is s: ", (end-start)
# 这里有个悲伤的故事,就是兄弟的卡是GTX1050,奈何空间不够,直接使用
# print "test accuracy %.3f" % accuracy.eval(feed_dict={x: t_data, y: t_target, keep_prob: 1.0})
# 就GG了,显示错误:
"""
ResourceExhaustedError (see above for traceback): OOM when allocating tensor with shape[10000,32,28,28]
[[Node: Conv2D = Conv2D[T=DT_FLOAT, data_format="NHWC", padding="SAME", strides=[1, 1, 1, 1], use_cudnn_on_gpu=true, _device="/job:localhost/replica:0/task:0/gpu:0"](Reshape, Variable/read)]]
"""
# 于是就做了一个骚操作
"""
for i in range(1):
t_data, t_target = next_batch(test_data, test_target, 5000)
print "test accuracy %.3f" % accuracy.eval(feed_dict={x: t_data, y: t_target, keep_prob: 1.0})
"""
# 于是就好了,后来发现10000不行,80000总可以吧,结果还是不行,看来要么花钱,要么学习技术,于是我选择了后者,正在路上.........有解决方法了再更新