参考书籍:《Python数据科学手册》
Pandas笔记精选

Pandas 是在 NumPy 基础上建立的新程序库(后者多是数组操作),提供了一种高效DataFrame数据结构。DataFrame 本质上是一种带行标签和列标签、支持相同类型数据和缺失值的多维数组。Pandas 不仅为带各种标签的数据提供了便利的存储界面,还实现了许多强大的操作。
Pandas 的三个基本数据结构:Series、DataFrame 和 Index。
pandas处理csv数据基本用法
1.Pandas对象简介
1.1 Pandas的Series对象
Pandas 的 Series 对象是一个带索引数据(out后可显示出)构成的一维数组。可以用一个数组创建 Series 对象。
Pandas 的 Series 对象比它模仿的一维 NumPy 数组更加通用、灵活:
-
两者间的本质差异其实是索引:NumPy 数组通过隐式定义的整数索引获取数值,而 Pandas 的Series 对象用一种显式定义的索引与数值关联。


-
Series是特殊的字典:
Pandas Series 的类型信息使得它在某些操作上比Python 的字典更高效。用字典创建 Series 对象时,其索引默认按照顺序排列。典型的字典数值获取方式仍然有效。
-
Series 对象还支持数组形式的操作,比如切片

-
创建:

需要注意的是,Series 对象只会保留显式定义的键值对。
 扫描二维码关注公众号,回复: 12557720 查看本文章
扫描二维码关注公众号,回复: 12557720 查看本文章
1.2 Pandas的DataFrame对象
Pandas 的另一个基础数据结构是 DataFrame。和Series 对象一样,DataFrame既可以作为一个通用型 NumPy 数组,也可以看作特殊的 Python 字典。
-
DataFrame是通用的NumPy数组:
如果将 Series 类比为带灵活索引的一维数组,那么 DataFrame 就可以看作是一种既有灵活的行索引,又有灵活列名的二维数组。
可以把 DataFrame 看成是有序排列的若干 Series 对象(基本对象为Series)。这里的“排列”指的是它们拥有共同的索引。
DataFrame 还有一个 columns 属性,是存放列标签的 Index 对象。
-
DataFrame是特殊的字典(这样理解比前者更全面):
与 Series 类似,我们也可以把 DataFrame 看成一种特殊的字典。字典是一个键映射一个值,而 DataFrame 是一列映射一个 Series 的数据。
-
创建:
1.通过单个 Series 对象创建。
2.通过字典列表创建。即使字典中有些键不存在,Pandas 也会用缺失值 NaN(非数字)来表示。

3.通过 Series 对象字典创建。
4.通过 NumPy 二维数组创建。假如有一个二维数组,就可以创建一个可以指定行列索引值的 DataFrame。如果不指定行列索引值,那么行列默认都是整数索引值。
5.通过 NumPy 结构化数组创建。(Pandas 的 DataFrame与结构化数组十分相似)
1.3 Pandas的index对象
-
将Index看作不可变数组:
许多操作与列表及NumPy数组相似,但Index 对象与 NumPy 数组之间的不同在于,Index 对象的索引是不可变的。
Index 对象的不可变特征使得多个 DataFrame 和数组之间进行索引共享时更加安全,尤其是可以避免因修改索引时粗心大意而导致的副作用。
-
将Index看作有序集合:
可使用&, |, ^(异或)。
2.数据取值与选择
(可类比NumPy、标准Python)
2.1 Series数据选择方法
-
看作字典:键值对的映射、字典的表达式和方法。
-
看作一维数组:索引、切片、掩码、花哨的索引等操作。
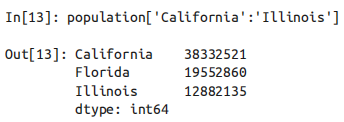
需要注意的是,当使用显式索引(如data[‘a’:‘c’])作切片时,结果包含最后一个索引;而当使用隐式索引(如 data[0:2])作切片时,结果不包含最后一个索引。
-
索引器:loc、iloc和ix。
上面提到的切片和取值的习惯用法经常会造成混乱。例如,如果你的 Series 是显式整数索引,那么 data[1] 这样的取值操作会使用显式索引,而 data[1:3] 这样的切片操作却会使用隐式索引。
In[11]: data = pd.Series(['a', 'b', 'c'], index=[1, 3, 5]) data Out[11]: 1 a 3 b 5 c dtype: object In[12]: # 取值操作是显式索引 data[1] Out[12]: 'a' In[13]: # 切片操作是隐式索引 data[1:3] Out[13]: 3 b 5 c dtype: object由于整数索引很容易造成混淆,所以 Pandas 提供了一些索引器(indexer)属性来作为取值的方法。
索引器不是 Series 对象的函数方法,而是暴露切片接口的属性。
loc 属性,表示取值和切片都是显式的。
iloc 属性,表示取值和切片都是 Python 形式的隐式索引。
ix,它是前两种索引器的混合形式。ix 索引器主要用于 DataFrame 对象,在 Series 对象中 ix 等价于标准的[](Python 列表)取值方式。

Python 代码的设计原则之一是“显式优于隐式”。 推荐使用 loc 和 iloc,可以让代码更容易维护,可读性更高。
2.2 DataFrame数据选择方法
-
看作字典:
建议使用键方法。 属性形式的数据选择方法很方便,但是它并不是通用的。如果列名不是纯字符串,或者列名与 DataFrame 的方法同名,那么就不能这么用。例如,DataFrame 有一个 pop()方法,如果用 data.pop 就不会获取 ‘pop’ 列,而是显示为方法。
-
看作二维数组:
values 属性按行查看数组数据。
.T进行行列转置。在进行数组形式的取值时,我们就需要用Pandas 索引器 loc、iloc 和 ix 了。通过 iloc 索引器,我们就可以像对待NumPy 数组一样索引 Pandas的底层数组(Python 的隐式索引),DataFrame 的行列标签会自动保留在结果中。
3.Pandas数值运算方法
-
保留信息和对齐:Pandas 实现了一些高效技巧:对于一元运算(像函数与三角函数),这些通用函数将在输出结果中保留索引和列标签;而对于二元运算(如加法和乘法),Pandas 在传递通用函数时会自动对齐索引进行计算。 这就意味着,保存数据内容与组合不同来源的数据——两处在 NumPy 数组中都容易出错的地方——变成了 Pandas 的杀手锏。
关于对齐:数组的索引是两个输入数组索引的并集。
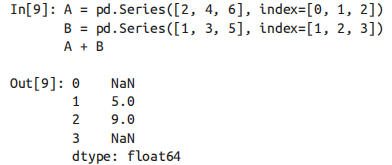

两个对象的行列索引可以是不同顺序的,结果的索引会自动按顺序排列。计算二维数组的均值需要用 stack 将二维数组压缩成一维数组
.stack().mean() -
通用函数:DataFrame与Series的运算:
根据 NumPy 的广播规则,让二维数组减自身的一行数据会按行计算。
如果想按列计算,那么就需要利用前面介绍过的运算符方法,通过 axis 参数设置。
4.处理缺失值
主要有三种形式:null、NaN 或 NA
4.1 选择处理缺失值的方法
在数据表或 DataFrame 中有很多识别缺失值的方法。一般情况下可以分为两种:一种方法是通过一个覆盖全局的掩码表示缺失值,另一种方法是用一个标签值(sentinel value)表示缺失值。
4.2 Pandas的缺失值
Pandas 里处理缺失值的方式延续了 NumPy 程序包的方式,并没有为浮点数据类型提供内置的 NA 作为缺失值。
NumPy 也是支持掩码数据的,也就是说可以用一个布尔掩码数组为原数组标注“无缺失值”或“有缺失值”。Pandas 也集成了这个功能,但是在存储、计算和编码维护方面都需要耗费不必要的资源,因此这种方式并不可取。
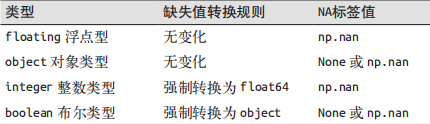
综合考虑各种方法的优缺点,Pandas 最终选择用标签方法表示缺失值,包括两种 Python 原有的缺失值:浮点数据类型的 NaN 值,以及 Python 的 None 对象。
None:Python对象类型的缺失值,不能作为任何 NumPy / Pandas 数组类型的缺失值,只能用于 ‘object’ 数组类型(即由 Python 对象构成的数组)。object类型在某些情景中非常有用,对数据的任何操作最终都会在Python 层面完成,但是在进行常见的快速操作时,这种类型比其他原生类型数组要消耗更多的资源。在 Python 中没有定义数字与 None 之间的加法运算。
NaN:数值类型的缺失值( Not a Number)(np.nan),是一种按照 IEEE 浮点数标准设计、在任何系统中都兼容的特殊浮点数。请注意,NumPy 会为这个数组选择一个原生浮点类型,这意味着和之前的 object 类型数组不同,这个数组会被编译成 C 代码从而实现快速操作。NaN 会将与它接触过的数据同化。无论和 NaN 进行何种操作,最终结果都是 NaN。
再次强调,NaN 是一种特殊的浮点数,不是整数、字符串以及其他数据类型。
# NumPy 也提供了一些特殊的累计函数,它们可以忽略缺失值的影响:
In[9]: np.nansum(arrayname), np.nanmin(arrayname), np.nanmax(arrayname)
Pandas中NaN与None的差异: NaN 与 None 各有各的用处,但是 Pandas 把它们看成是可以等价交换的,在适当的时候会将两者进行替换。Pandas 会将没有标签值的数据类型自动转换为 NA。
Pandas 中字符串类型的数据通常是用 object 类型存储的。
-
处理缺失值的方法:
isnull():创建一个布尔类型的掩码标签缺失值。
notnull():与 isnull() 操作相反。
dropna():返回一个剔除缺失值的数据。(比isnull方法建立掩码填充更专用)
fillna():返回一个填充了缺失值的数据副本。注意,Pandas 数据结构有两种有效的方法可以发现缺失值:isnull() 和 notnull()。每种方法都返回布尔类型的掩码数据。
5.层级索引
时机:遇到存储多维数据的需求,数据索引超过一两个键。
通过层级索引配合多个有不同等级(level)的一级索引一起使用,这样就可以将高维数组转换成类似一维 Series 和二维 DataFrame 对象的形式。
5.1 Pandas多级索引表示问题
-
用元组表示索引其实是多级索引的基础,Pandas的 MultiIndex 类型提供了更丰富的操作方法。我们可以用元组创建一个多级索引。
MultiIndex 里面的 levels 属性表示索引的等级。
索引重置:reindex
-
高维数据的多级索引:
unstack() 方法可以快速将一个多级索引的Series 转化为普通索引的 DataFrame。 stack() 方法实现相反的转化。
进一步看,如果我们可以用含多级索引的一维 Series 数据表示二维数据,那么我们就可以用 Series 或DataFrame 表示三维甚至更高维度的数据。
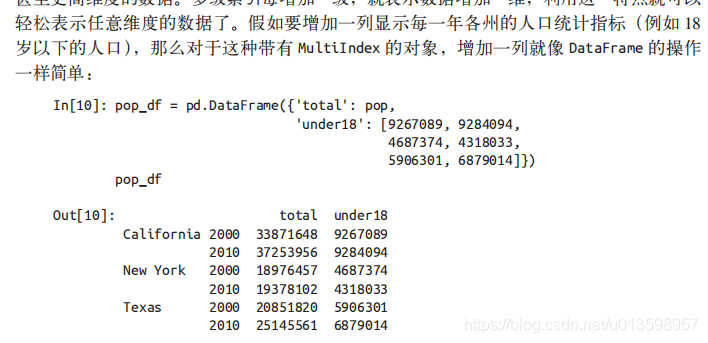
5.2 多级索引的创建方法
为 Series 或 DataFrame 创建多级索引最直接的办法就是将 index 参数设置为至少二维的索引数组。

这个过程中,MultiIndex 的创建工作将在后台完成。同理,如果你把将元组作为键的字典传递给 Pandas, Pandas 也会默认转换为 MultiIndex。
但是有时候显式地创建 MultiIndex 也是很有用的:***
MultiIndex 的等级加上名称会为一些操作提供便利。你可以在前面任何一个 MultiIndex构造器中通过 names 参数设置等级名称,也可以在创建之后通过索引的 names属性来修改名称。
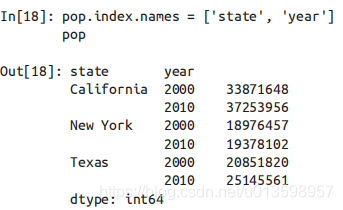
最后,有多级行索引,那么同样有多级列索引。
*5.3 多级索引的取值与切片
切片要求排序!!
-
Series多级索引:
MultiIndex 也支持局部取值(partial indexing),即只取索引的某一个层级。假如只取最高级的索引,获得的结果是一个新的 Series,未被选中的低层索引值会被保留。(注意区分高低级)
类似的还有局部切片,不过要求 MultiIndex 是按顺序排列的。
-
DataFrame多级索引(难):
由于 DataFrame 的基本索引是列索引,因此 Series 中多级索引的用法在DataFrame 中应用在列上。
5.4 多级索引行列转换
-
有序与无序:如果MultiIndex 不是有序的索引,那么大多数切片操作都会失败。 局部切片和许多其他相似的操作都要求 MultiIndex 的各级索引是有序的(即按照字典顺序由 A 至 Z)。为此,Pandas 提供了许多便捷的操作完成排序,如 sort_index() 和 sortlevel() 方法。
-
行列转换:
前面曾提到过索引stack和unstack。
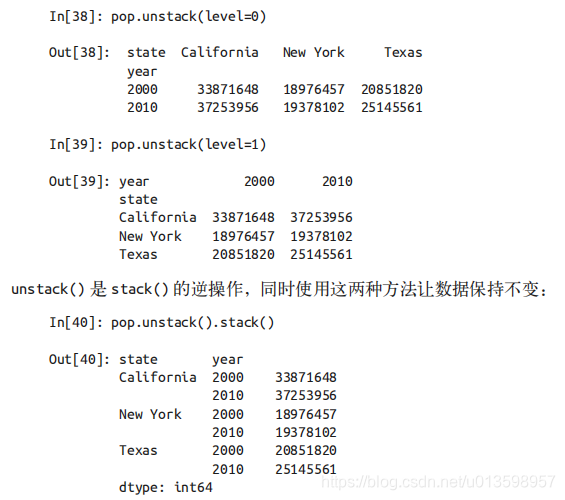
层级数据维度转换的另一种方法是行列标签转换(更推荐),可以通过 reset_index 方法实现。使用该方法,则会生成一个列标签中包含之前行索引标签的DataFrame。 也可以用数据的 name 属性为列设置名称。
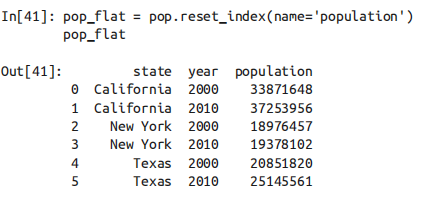
如果能将类似这样的原始输入数据的列直接转换成 MultiIndex,通常将大有裨益。其实可以通过 DataFrame 的 set_index 方法实现,返回结果就会是一个带多级索引的 DataFrame。
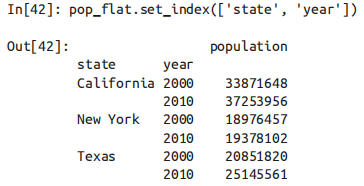
5.5 多级索引的数据累计方法
对于层级索引数据,可以设置参数 level 实现对数据子集的累计操作。
如果再设置 axis 参数,就可以对列索引进行类似的累计操作了。
(这种语法其实是GroupBy 功能的快捷方式)
6.合并数据集:Concat与Append操作
介绍:合并数据集,既包括将两个不同的数据集非常简单地拼接在一起,也包括用数据库那样的连接(join)与合并(merge)操作处理有重叠字段的数据集。
6.1 通过pd.concat实现简易合并
合并Series与DataFrame 与 合并NumPy数组基本相同。
pd.concat() 函数与 np.concatenate 语法类似,但是配置参数更多,功能也更强大。

默认情况下,DataFrame 的合并都是逐行进行的(默认设置axis=0)。
-
索引重复:
np.concatenate 与 pd.concat 最主要的差异之一就是 后者合并时会保留索引,即使索引是重复的。

捕捉索引重复的错误:可以设置pd.concat()中的verify_integrity 参数为 True,合并时若有索引重复就会触发异常。忽略索引:设置 ignore_index 参数来实现。如果将参数设置为 True,那么合并时将会创建一个新的整数索引。
增加多级索引:另一种处理索引重复的方法是通过 keys 参数为数据源设置多级索引标签,这样结果数据就会带上多级索引。

-
类似join(连接)的合并:
实际工作中,需要合并的数据往往带有不同的列名。

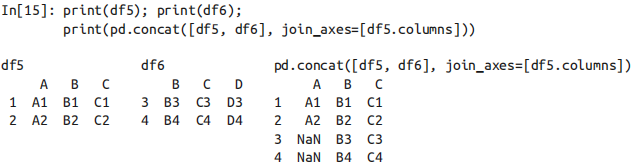
默认情况下,某个位置上缺失的数据会用 NaN 表示。如果不想这样,可以用 join 和 join_axes 参数设置合并方式。1-默认的合并方式是对所有输入列进行并集合并(join=‘outer’),当然也可以用 join=‘inner’ 实现对输入列的交集合并。
2-另一种合并方式是直接确定结果使用的列名,设置 join_axes 参数,里面是索引对象构成的列表(是列表的列表)。
6.2 append方法
append方法对应直接进行数组合并的需求。
需要注意的是,与 Python 列表中的 append() 和 extend() 方法不同,Pandas 的 append() 不直接更新原有对象的值,而是为合并后的数据创建一个新对象。 因此,它不能被称之为一个非常高效的解决方案,因为每次合并都需要重新创建索引和数据缓存。
7.合并数据集:合并与连接
(~ 似数据库的使用 ~)
主接口是 pd.merge 函数。
pd.merge() 实现的功能基于关系代数的一部分。关系代数是处理关系型数据的通用理论,绝大部分数据库的可用操作都以此为理论基础。
7.1 数据连接的类型
pd.merge() 函数实现了三种数据连接的类型:一对一、多对一和多对多。
-
一对一连接:
自动以共同作为键进行连接,共同列的位置可以是不一致的。需注意,pd.merge() 会默认丢弃原来的行索引,不过也可以自定义。
-
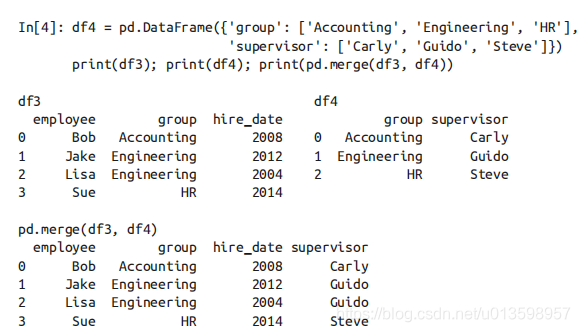
多对一连接:
多对一连接是指,在需要连接的两个列中,有一列的值有重复。通过多对一连接获得的结果 DataFrame 将会保留重复值。
-
多对多连接:
如果左右两个输入的共同列都包含重复值,那么合并的结果就是一种多对多连接。

7.2 设置数据合并的 键
因为两个输入要合并的列通常都不是同名的,所以pd.merge() 提供了一些参数处理这个问题。
-
参数on的用法:
最简单的方法就是直接将参数 on 设置为一个列名字符串或者一个包含多列名称的列表。
这个参数只能在两个 DataFrame 有共同列名的时候才可以使用。
-
left_on与right_on参数:
有时你也需要合并两个列名不同的数据集,在这种情况下,就可以用left_on 和 right_on 参数来指定列名。(双引号)
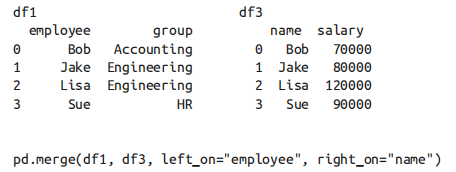
获取的结果中会有一个多余的列,可以通过 DataFrame 的 drop() 方法将这列去掉(注意axis=1) -
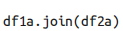
left_index与right_index参数:
除了合并列之外,你可能还需要合并索引。可以通过设置 pd.merge() 中的 left_index 和 / 或 right_index 参数将索引设置为键来实现合并。
为了方便考虑,DataFrame 实现了 join() 方法,它可以按照索引进行数据合并。
一个混合使用的例子:
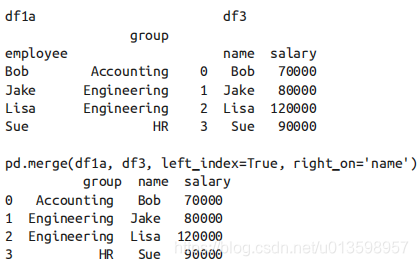
搭配:左引右列,右引左列。
7.3 设置数据连接的集合操作规则
当一个值出现在一列,却没有出现在另一列时,就需要考虑集合操作规则了。

默认情况下,结果中只会包含两个输入集合的交集,这种连接方式被称为内连接(inner join)(区分concat中的join参数默认设定)。我们可以用 how 参数设置连接方式,默认值为 ‘inner’。
how 参数支持的数据连接方式还有 ‘outer’、‘left’ 和 ‘right’。


(输出的行中只包含左边输入列的值)
7.4 重复列名:suffixes参数
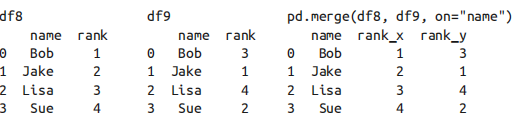
可以通过 suffixes 参数自定义后缀名。

7.5 实操中的其他笔记

8.累计与分组
8.1 简单累计功能
与一维 NumPy 数组相同,Pandas 的 Series 的累计函数也会返回一个统计值。
DataFrame 的累计函数默认对每列进行统计。设置 axis 参数,可以对每一行进行统计。
Pandas 的 Series 和 DataFrame 支持NumPy中介绍的常用累计函数。
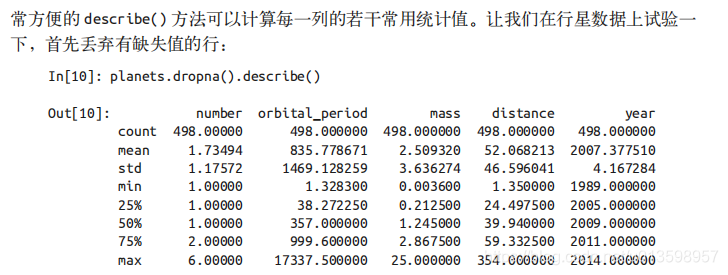
!这是一种理解数据集所有统计属性的有效方法.
8.2 GroupBy:分割、应用和组合(难)
问题背景:我们经常还需要对某些标签或索引的局部进行累计分析。
-
简单的分割、应用和组合:
一个经典的GroupBy实例过程图:
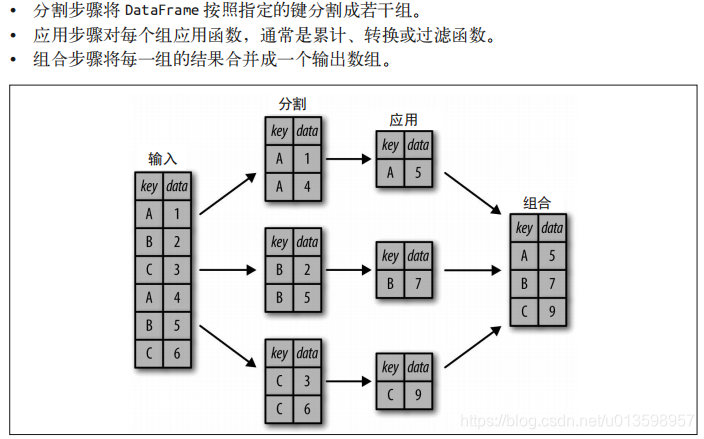
虽然我们也可以通过前面介绍的一系列的掩码、累计与合并操作来实现,但是意识到中间分割过程不需要显式地暴露出来这一点十分重要。而且,GroupBy(经常)只需要一行代码,简洁许多。GroupBy 的用处就是将这些步骤进行抽象:用户不需要知道在底层如何计算,只要把操作看成一个整体就足够。可以用 DataFrame 的 .groupby() 方法进行绝大多数常见的分割 - 应用 - 组合操作,将需要分组的列名传进去即可。
需要注意的是,上面方法的返回值不是一个 DataFrame 对象,而是一个 DataFrameGroupBy 对象。你可以将它看成是一种特殊形式的DataFrame,里面隐藏着若干组数据,但是在没有应用累计函数之前不会计算。 这种“延迟计算”(lazy evaluation)的方法使得大多数常见的累计操作可以通过一种对用户而言几乎是透明的(感觉操作仿佛不存在)方式非常高效地实现。
-
GroupBy对象:
GroupBy 对象是一种非常灵活的抽象类型。在大多数场景中,你可以将它看成是 DataFrame的集合,在底层解决所有难题。
GroupBy 中重要的操作包括 aggregate、filter、transform 和apply(累计、过滤、转换、应用)(后面会提到)。
(1) 按列取值:
GroupBy 对象与 DataFrame 一样,也支持按列取值,并返回一个修改过的GroupBy 对象,直到我们运行累计函数,才会开始计算。
(2)按组迭代:
GroupBy 对象支持直接按组进行迭代,返回的每一组都是 Series 或 DataFrame。尽管通常还是使用内置的 apply 功能速度更快,但这种方式在手动处理某些问题时非常有用。
-
高效操作之 累计、过滤、转换和应用:
讲解时的例用DataFrame:
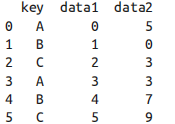
(1) 累计:aggregate() 其实可以支持更复杂的操作,比如字符串、函数或者函数列表,并且能一次性计算所有累计值。


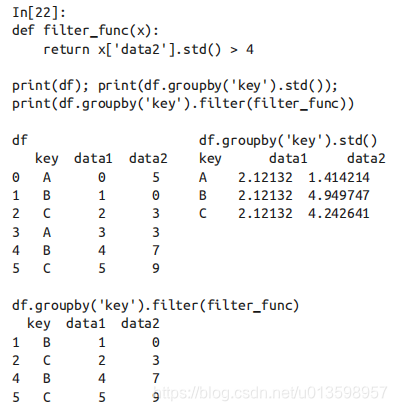
(2) 过滤:过滤操作可以让你按照分组的属性丢弃若干数据。
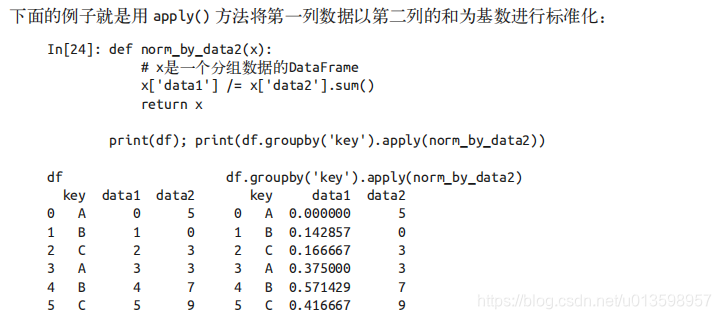
(3) 转换:累计操作返回的是对组内全量数据缩减过的结果,而转换操作会返回一个新的全量数据。数据经过转换之后,其形状与原来的输入数据是一样的。
常见的例子就是将每一组的样本数据减去各组的均值,实现数据标准化:

(4) apply() 方法:apply() 方法让你可以在每个组 (Group) 上应用任意方法。这个函数输入一个DataFrame,返回一个 Pandas 对象(DataFrame 或 Series)或一个标量(scalar,单个数值)。组合操作会适应返回结果类型。
-
设置分割的键(难):
前面的简单例子一直在用列名分割 DataFrame。这只是众多分组操作中的一种。
(1) 将列表、数组、Series 或索引作为分组键。分组键可以是长度与 DataFrame 匹配的任意Series 或列表。

如L中0的不同位置对应列中位置。(2)用字典或 Series 将索引映射到分组名称:

(3)任意 Python 函数。与前面的字典映射类似,你可以将任意 Python 函数传入 groupby,函数映射到索引,然后新的分组输出。
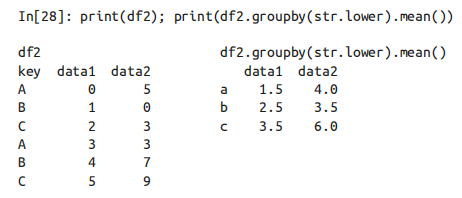
(4) 多个有效键构成的列表:此外,任意之前有效的键都可以组合起来进行分组,从而返回一个多级索引的分组结果。
