
正则表达式
概念
正则表达式作为计算机科学的一个概念,通常被用来检索、替换那些符合某个规则的文本。正则表达式是对字符串操作的一种逻辑公式,用事先定义好的规则字符串对字符串进行过滤逻辑处理。
正则表达式从本质上讲,是一种小型的、高度专业化的编程语言。在Python中,正则表达式通过re模块实现。正则表达式可以先给匹配的相应字符串集指定规则,再通过re模块一某些方式来修改或分隔字符串。
正则表达式模式先被编译成一系列的字节码,再由用C语言编写的匹配引擎执行,所以从某种程度上说比直接写Python字符串处理代码快。但是并非所有字符串匹配都能用正则表达式完成,即使可以处理单表达式也变得很复杂,可读性差,这是建议直接编写Python代码。
构成
正则表达式由2种字符构成,一种是在正则表达式中具有特殊意义的元字符,另一种是普
通字符。
字符及语法:
| 语法 | 说明 | 表达式示例 | 匹配举例 |
|---|---|---|---|
| 普通字符 | 匹配本身 | Abc | abc |
| . | 匹配除了换行符\n外任意字符 | a.c | abc |
| \ | 转义符 | a\.c | a.c |
| [abcd] | 匹配a或b或c或d | [abc] | a |
| [0-9] | 匹配0~9任一数字,相当于[0123456789] | [0-3] | 1 |
| [\u4e00-\u9fa5] | 匹配任一汉字 | [\u4e00-\u9fa5] | 汉 |
| [^a0=] | 匹配除了a、0、=外任意字符 | [^abc] | d |
| [^a-z] | 匹配除了小写字符外任意字符 | [^a-z] | A |
| \d | 匹配任意一个数字,相当于[0-9] | a\dc | a6c |
| \D | 匹配任意一个非数字字符,相当于[^0-9] | a\Dc | abc |
| \s | 匹配任意空白字符,相当于[\r\n\f\t\v] | a\sc | a c |
| \S | 匹配任意非空白字符,相当于[^\r\n\f\t\v] | a\Sc | aYc |
| \w | 匹配任意一个字母、数字或下划线,相当于[a-zA-Z0-9_] | a\wc | a_c |
| \W | 匹配任意一个非字母、数字或下划线,相当于[^a-zA-Z0-9_] | a\wc | a*c |
| * | 匹配前一个字符0次或无限次 | a*c | c |
| + | 匹配前一个字符1次或无限次 | a+c | aaaac |
| ? | 匹配前一个字符0次或1次 | a?c | ac |
| {m} | 匹配前一个字符m次 | a{3}c | aaac |
| {m,n} | 匹配前一个字符m到n次,mn可以省略,mn默认值分别是0次和无限次 | a{1,2}c | aac |
| ^ | 匹配字符串的开始位置,不匹配任何字符 | ^abc | abc |
| $ | 匹配字符串的结束位置,不匹配任何字符 | abc$ | abc |
| | | 子表达式或关系匹配 | abc|def | def |
| (…) | 匹配分组 | (abc){2} | abcabc |
| (?P<name>…) | 匹配分组,除了原有编号外再指定一个额外的别名 | (?P<id>abc){2} | abcabc |
| \<number> | 匹配引用编号为<number>的分组到字符串中 | (\d)abc\1 | 1abc1 |
| (?..) | 匹配不分组的(…),后接数量词 | (?:abc){2} | abcabc |
| (?iLmsux) | iLmsux的每一个字符代表一个匹配模式,只能用于字符串的开始位置,可选多个 | (?i)abc | AbC |
| (?#…) | #后的内容将被注释忽略掉 | a(?#test)bc | abc |
| (?(id/name)yes-pattern|no-pattern) | 匹配编号为id或别名为name的组需要匹配yes-pattern,否则需要匹配no-pattern,类似三目运算符 | (\d)abc(?(1)\d|abc) | 1abc2 |
以上规则只是单一针对字符串匹配,在实际应用中多会是多种单一匹配的组合,因此最好掌握以便Python开始时熟练应用。而直接记忆这些规则教枯燥,下文讲结合Python的re模块进行讲解,以便熟练掌握。
re模块应用
一、查看版本
Python从1.5版本后增加了re模块,提供了入Perl风格的正则表达式模式。
re模块内嵌在Python中,因此可以直接导入,使用方法__version__可查看版本,以及方法__all__查看属性方法:
import re
print(re.__version__)
print(re.__all__)
#输出结果如下:
2.2.1
['match', 'fullmatch', 'search', 'sub', 'subn', 'split', 'findall', 'finditer', 'compile', 'purge', 'template', 'escape', 'error', 'Pattern', 'Match', 'A', 'I', 'L', 'M', 'S', 'X', 'U', 'ASCII', 'IGNORECASE', 'LOCALE', 'MULTILINE', 'DOTALL', 'VERBOSE', 'UNICODE']
上述代码看出,re模块涉及函数并不多,功能一是查找文本中的模式,二是编译表达式,三是多层匹配,同时还定义了一些常量。
二、search()查找
查找文本中的模式主要使用search()函数。该函数有pattern、string、flags三个参数;
- pattern表示编译时用的表达式字符串
- string表示用于匹配的字符串
- flags表示编译标志为,用于修改正则表达式的匹配方式,如是否区分大小写、多行匹配等,默认值为0。
常用的flag值如下:
| 标志 | 含义 |
|---|---|
| re.S(DOTALL) | 使“.”匹配包括换行在内的所有字符 |
| re.I(IGNORECASE) | 使匹配对大小写不敏感 |
| re.L(LOCALE) | 做本地化识别匹配等 |
| re.M(MULTILINE) | 多行匹配,影响^和$ |
| re.X(VERBOSE) | 通过更灵活的格式以便正则表达式易于理解 |
| re.U | 根据Unicode字符集解析字符,影响\w、\W、\b、\B |
re.serach()函数通过模式和扫描的文本作为输入,返回匹配对象,若未找到匹配模式,则返回None:
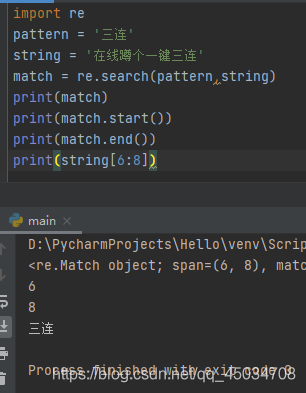
从上看出match为返回的匹配对象,包含了有关匹配性质的信息。使用正则表达式时,模式在原字符串中出现的位置,具有start()、end()、group()、span()、groups()等方法:
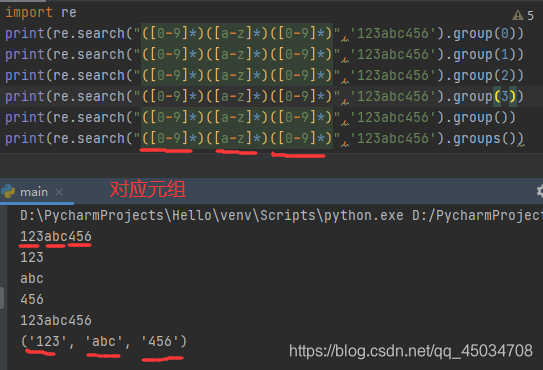
start()返回匹配开始位置end()返回匹配结束位置group()返回被匹配的字符串span()返回一个包含匹配(开始、结束)位置的元组groups()返回一个包含正则表达式中所有小组字符串的元组,从1到所含的小组号,通常不需要参数。除此之外,还有一个group(n,m)方法,返回组号为(n,m)所匹配的字符串。
三、compile()预编译
使用函数compile()将正则表达式编译成正则表达式对象,提高执行效率。该函数返回的是一个对象模式,有pattern、flags=0两个参数,含义和上文search()中提到一致。
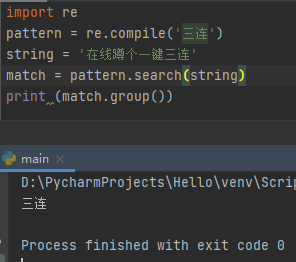
通常编译的表达式都是程序频繁使用的表达式,这样编译起来会更加高效,但也会开销一定缓存。使用已编译的表达式还有一个好处,即在加载模块是就编译所有表达式,而不是当程序响应用户动作时才进行编译。
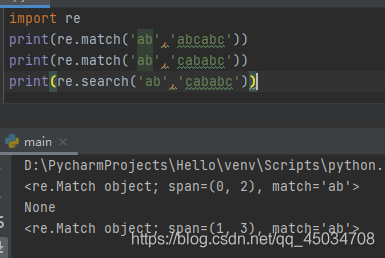
四、match()开始位置匹配
使用函数match()在文本字符串的开始位置匹配,这种方法并非完全匹配,只匹配字符串的开始位置/首部,无须在乎其后是否还有字符串,尽管后面可能匹配上,也全部忽略。
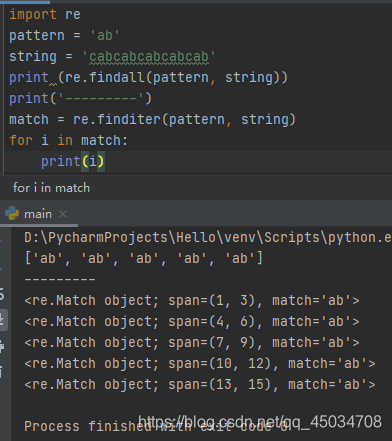
五、findall()及finditer()遍历匹配
使用函数findall()进行遍历匹配,获取字符串中所有匹配的字符串,返回一个列表。该函数的作用与参数跟search()函数一样,但它返回所有匹配且不重叠的子字符串。
函数finditer()的使用方式和findall()一样,只不过返回的是一个迭代器,而不是列表。它将生成Match实例。
(
插播反爬信息)博主CSDN地址:https://wzlodq.blog.csdn.net/
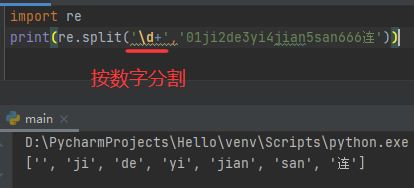
六、split()分割
函数split()能够俺在匹配的子字符串将需匹配的字符串进行分割,并返回一个列表。
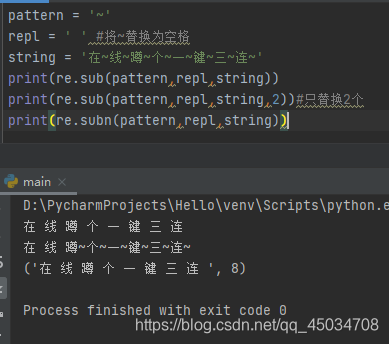
七、sub()及subn()替换
函数sub使用pattern替换string中每一个匹配的子串,并返回替换后的子串,格式为re.sub(pattern,repl,string,count,flag)。而函数subn()在此基础上多返回一个替换次数。
- pattern是表达式字符串
- repel是替换后的字符
- string是用于匹配的字符串
- count是最大替换次数,超出后不再替换
- flag同上文
常用正则表达式
数字
数字表达式校验主要针对文本中出现的数字进行正则表达式校的匹配,下面将讲解一些常用的表达式,并使用re模块对其进行处理演示。
-
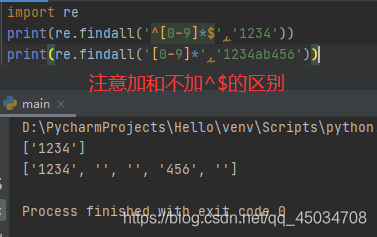
^[0-9]*$
和前文提到的^是匹配字符串开始位置;$是匹配字符的结束位置;[0-9]表示任一数字;*匹配前一个字符0次或无数次。下面的将不再赘述,不清楚请翻阅上文。
综上,该表达式用来匹配数字。
-
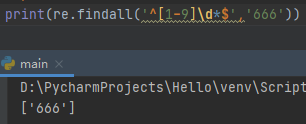
^[1-9]\d*$匹配非0正整数
-
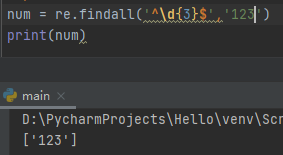
^\d{n}$匹配n位数字
-
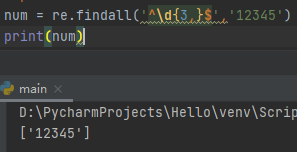
^\d{n,}$匹配的是至少n位数字
-
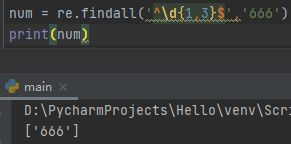
^\d{m,n}$匹配m位到n位的数字
-
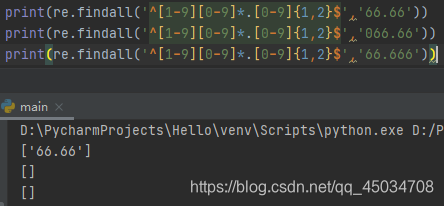
^[1-9][0-9]*.[0-9]{1,2}?$匹配非0开头的最多带两位小数的数字
字符
文本分析中,常常会涉及字符表达式的处理,比如提取汉字,对长度为多少的字符进行删除等。
-
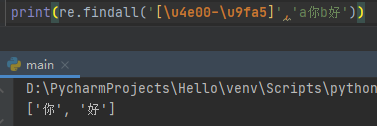
[\u4e00-\u9fa5]汉字匹配
-
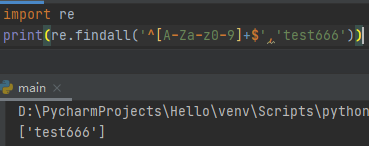
^[A-Za-z0-9]+$英文和数字的匹配
-
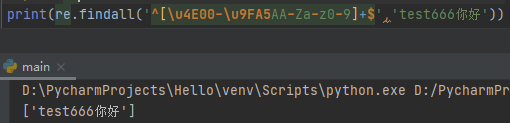
^[\u4E00-\u9FA5AA-Za-z0-9]+$中英文数字匹配
其他
-
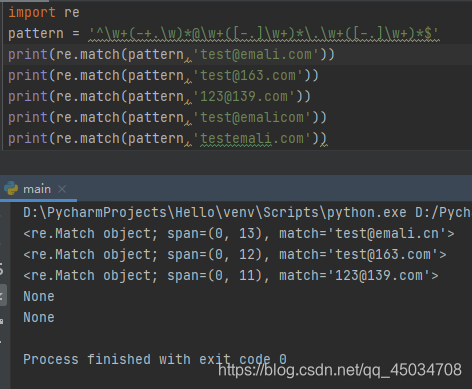
^\w+(-+.\w)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$E-mail地址校验
-
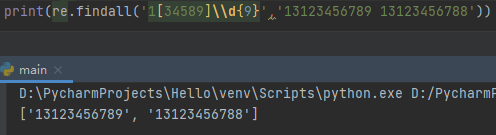
^1[34589]\\d{9}$手机号码
-
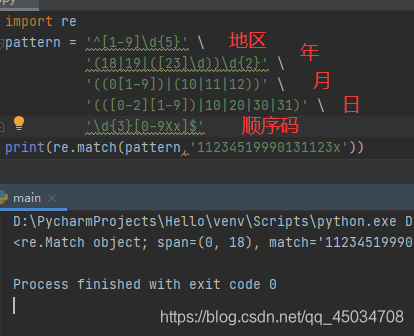
^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$身份证号
-
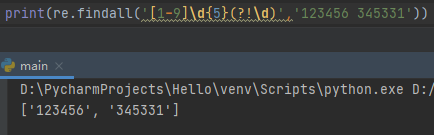
^[1-9]\d{5}(?!\d)$邮政编码
-
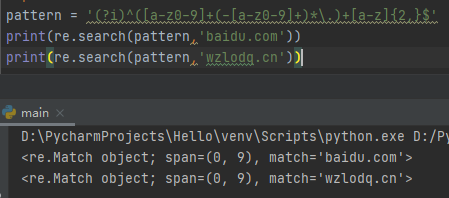
(?i)^([a-z0-9]+(-[a-z0-9]+)*\.)+[a-z]{2,}$域名
小结
正则表达式re模块最重要的功能就是过滤,从目标中过滤出所需的数据,然后再通过函数组合等,从字符串中过滤出任何特征的数据,是后续Python爬虫解析数据的基础。
原创不易,请勿转载(
本不富裕的访问量雪上加霜)
博主首页:https://wzlodq.blog.csdn.net/
微信公众号:唔仄lo咚锵
如果文章对你有帮助,记得一键三连❤