第五章 六大禁止
第一禁止 禁止外键
第二禁止 禁止视图
第三禁止 禁止触发器
第四禁止 禁止存储过程
第五禁止 禁止JOB
第六禁止 索引
这五大禁止会带来很多性能隐患的,其中触发器就是特例,视图也会影响性能的,你说可以做成物化视图。
自从应用程序从C/S架构发展到B/S架构,然后在是水平扩展成多机器分布式集群架构。而以上的外键,视图,触发器以及存储过程都是C/S架构中的数据库为了实现企业业务逻辑的工具。以前企业和工厂数据库服务器都采用的是小型机器,比如如今的AIX操作系统必须运行在IBM的小型机上。而ORACLE+AIX+小型机是标准搭配。如今的ORACLE EBS系统依旧运行上面平台中。以前个人电脑性能不咋地,什么586,686,奔腾1-5估计你都没有听说过,都是单核CPU。所以当时就把大量的计算工作和业务逻辑也放在了数据库服务器上跑。
如今的WEB,云化的B/S架构,已经把业务逻辑移到了 TOMCAT容器或者是IIS上运行。使用的编程语言要么JAVA,要么是C#.NET。而数据库就充当数据存储的角色。数据对象就是表和索引,而对它们的操作就是SQL。除了这三样外就别无其它了。
曾经面试被问到业务逻辑放在哪端?你怎么看待存储过程的?当初经验缺乏,不知道如何回答。虽然后来想了下,觉得业务逻辑放在JAVA层,而存储过程只处理数据逻辑。也就是说存储过程一点都不涉及业务逻辑,只是GROUP BY WHERE SUM 掉大量的数据,返回少量的数据给应用层。虽然一直觉得这是个完美的方案,各就其位,各尽所长,充分发挥各自的优点。然而现在想起这方案比较理想,你无法让开发人员又写JAVA中的业务逻辑,还要让他们写存储过程。那开发人员会无法区分业务逻辑写在哪里去了,或许那个实现方便,快捷就使用谁。或许两边都使用下,这样来业务就被拆分在两端了。

视图也是一段SQL代码,当初是为了屏蔽低下某些表给某些人看,或者是公共一段代码作为共享SQL。既然是SQL必然是业务逻辑的实现体,所以也要移植到应用层里去。
外键和触发器 如今JAVA开发人员已经取得了认识不在数据库端实现了。
关于JOB的禁止, JOB JAVA应用开发已经实现定时调度的功能,并且调度何时调度都是业务逻辑的考虑。
索引为什么也有要禁止呢? 这是因为禁止开发人员去建索引,索引也归DBA使用的。由DBA负责建立业务所需要的索引!
OK !! 我小仙并没有说真的在数据库上禁止这五个东西,而是说禁止开发人员去使用它们。这五个东西专属我们DBA的,我们DBA就可以使用这五个东西。因为我们不会把业务逻辑写在存储过程,视图里面啊!
很多人看到这里很多人就转不过弯来,他们想的是不让开发人员使用存储过程,难道叫DBA去写存储过程吗?这样不是累死了DBA吗? 有的人不认真仔细看上面的文字含义,或者他们大脑里先入为主的固有思维限制了,看了也白看。才会问这些愚蠢的问题!
在这里我声明下,本优化新常态是针对WEB性的数据库应用,而不是第二代 服务型数据库应用。是第三代的WEB型和第四代WEB集团化型数据库应用系统。
在这里没有数据库开发工程师这一个职位。WEB开发人员和DBA。 DBA不开发业务的存储过程,视图,触发器,外键,物化视图。这些东西归DBA做运维方便而已,毕竟DBA不懂PHP,JAVA.C#等WEB开发语言。DBA懂PL/SQL语言,做些运维,做些统计,做些优化,自然使用PL/SQL语言和对应的工具,JOB,存储过程,视图,触发器。
第六章 急诊法
当我们被数据库突然慢的时候,这个时候不该做AWR报表!好比你是医院的急诊科的值班医生,当120拉来一名患者,而你要做的是立即判断病情所在。AWR不太适合急诊模式,阅读完它就要花费30分钟!所以我们需要特殊的简单明确的方法,进行快速诊断,快速恢复生产,让用户继续完成业务,让老板有利润。
第一从系统上开始 TOP命令 如下
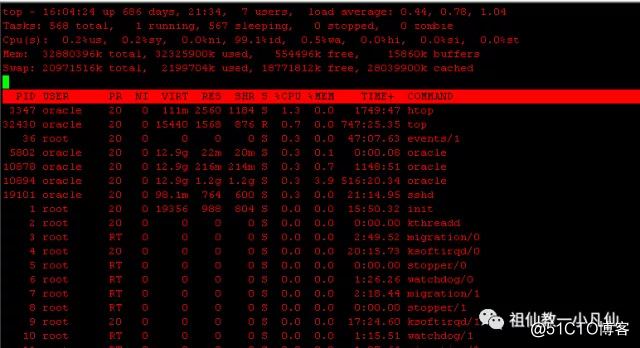
TOP命令很多LINUX都有,而且比较重要哦!读懂里面的意思是DBA必备良药。
第一 看第一行LOAD AVERAGE 超过1 就比较忙,越大越忙
第二 看第二行 TASKS 任务数 尤其是 RUNNING的数,一般平时的时候都1-2.恐怖的时候达到1000,说明并发量大,排队等候也大。
第三 看第三行 CPU 看目前的CPU消耗在哪个领域。US表示应用,SY表示系统,WA表示等待(IO或者是网络)。通过CPU消耗在什么位置可以确定哪里病了,是心脏还是胃,还脑袋瓜子呢?
第四 看第四和第五行 大致讲的是当前内存使用情况和SWAP内存使用的情况。
第五 下面的进程活动列表,动态变化的,一般都是按CPU使用率变化的。如果排在顶部的大部分是ORACLE进程,说明是数据库发生了问题。
从TOP命令不能精确判断出来, 不过能了解到是什么消耗比较严重 是IO还是CPU 尤其是第三行。大致判断出是系统出了问题还是数据库出了问题。
VMSTAT 命令
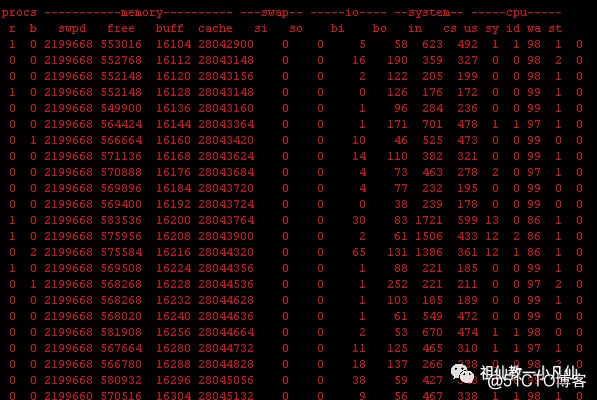
由于CENTOS 6带的VMSTA输出格式对齐不咋地,看起来有点不舒服。
重点是看PROCS 的R B两列和SWAP的SI SO两列。
R B 表示运行队列的进程数和阻塞的进程数。 R代表运行进程,B代表阻塞进程。SI SO表示交换内存的进出数量。
VMSTAT 主要用来判断是非发生了交换内存的频繁大量的交换。
下图是ORACLE LINUX 6 的DSTAT命令 大家看下友好性特别的好。
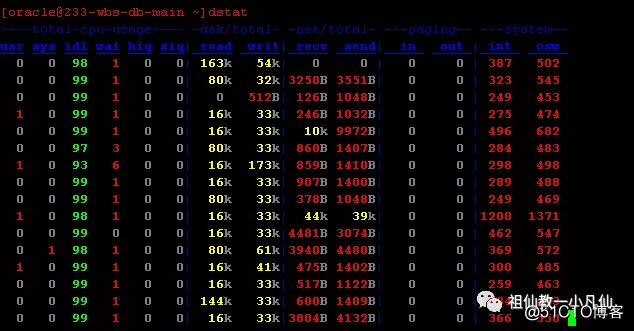
第一组代表的是CPU;
第二组代表的是磁盘IO情况;
第三组代表的是网络情况;
第四组代表交换内存情况;
第五组代表系统情况;Int 中断,CSW上下文切换
到这里我们结束了系统方面的急症了。从上面两个命令可以确定病情集中在CPU,内存还是IO方面。假如CPU 内存 IO 都很正常那就是说系统是没有问题的,问题在数据库上面,起码数据库慢的问题没有体现在系统指标上。说明病情不严重。
ORATOP命令
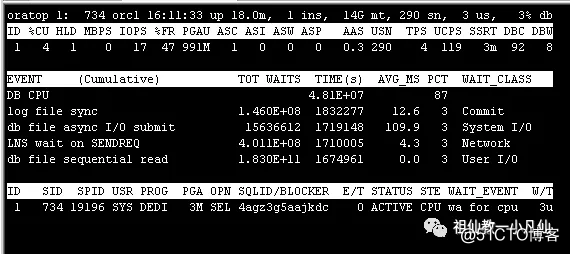
这个命令是ORACLE公司开发的小工具,变化挺大的。
第一行和第二行,有些我也不懂,主要是变化太大了,每个新版本都不一样,另外还是英文缩写,没有长格式的,都是80列的格式的。
重点看EVENT ,这个就是及时性的TOP五等待事件。这样我们就知道数据库是否发生了严重的等待。比如上图正常情况下是DB CPU占比较多的DBTIME。
如果是下面 LOG FILE SYNC和DB FILE SEQUENTIAL READ 等待事件排在第一或第二位 那就说明IO争用很厉害。
关于小工具看下面链接 ==》ORATOP小工具
接下来就是TOP-SQL了 一眼望过去大部分列都懂,除了E/T STE W/T外。
通过TOP-SQL 你可以心里有普了,知道这些家伙了。你可以KILL了它们。不过要在SQLPLUS里面发不KILL SESSION命令 另外还有手动去查出来。虽然给了SID 和SPID。
也可以在系统上KILL -9 命令,不过也要通过SQLPLUS查出系统ID来。还是有点不方便。
视图 V$SESSION_BLOCKERS
这是个回话阻塞视图里面包含了如下字段
SID
SESS_SERIAL#
WAIT_ID
WAIT_EVENT
WAIT_EVENT_TEXT
BLOCKER_INSTANCE_ID
BLOCKER_SID
BLOCKER_SESS_SERIAL#
分别意思是 回话ID,回话序号,等待ID,等待事件,等待事件文本,阻塞实列ID,阻塞回话ID,阻塞回话序号。
这个视图如果只有一两行还比较给力,如果是几百行的话,就不像话了,一点都不给力。尤其是急症下,上百行阻塞回话,它们之的上下级关系,阻塞连。我写个START WITH类似的树下结构的语句,发现也不行,反而产生更多的行,从原来几百行变成了几千行。也没有机会去调试SQL,毕竟发生阻塞的时候,你必须干掉它,所以就没有机会了。只有截图回来分析下。
另外该表只有这几列字段,显然信息量是不够的,尤其是在急症情况下。必须有等待者的SQL语句,阻塞者的SQL语句,阻塞者的等待事件。
为此我整了个大SQL,不过不太理想
SELECT LEVEL AS LEVEL_NUM,
B.SID AS "会话ID",
B.SESS_SERIAL# AS "会话序列",
B.BLOCKER_INSTANCE_ID AS "阻塞实列ID",
B.BLOCKER_SID AS "阻塞会话ID",
B.BLOCKER_SESS_SERIAL# AS "阻塞会话序列",
SS.EVENT AS "阻塞者等待事件",
S.SCHEMANAME AS "模式名",
S.OSUSER AS "操作系统用户",
S.PROCESS AS "进程ID",
S.MACHINE AS "机器",
S.PORT AS "端口",
S.TERMINAL AS "终端",
S.PROGRAM AS "程序",
S.TYPE AS "类型",
S.SQL_ID AS "当前SQLID",
(SELECT TXT.SQL_TEXT FROM V$SQLAREA TXT WHERE TXT.SQL_ID = S.SQL_ID) AS "当前SQL语句",
S.PREV_SQL_ID AS "上个SQLID",
(SELECT TXT.SQL_TEXT FROM V$SQLAREA TXT WHERE TXT.SQL_ID = S.PREV_SQL_ID) AS "上个SQL语句",
B.WAIT_EVENT_TEXT AS "等待事件",
S.WAIT_CLASS AS "等待类",
S.WAIT_TIME AS "等待时间秒",
'||' AS "阻塞者信息分隔",
SS.STATUS AS "阻塞者会话ID",
SS.STATE AS "阻塞者会话ID",
SS.SCHEMANAME AS "阻塞者模式名",
SS.OSUSER AS "阻塞者操作系统用户",
SS.PROCESS AS "阻塞者进程ID",
SS.MACHINE AS "阻塞者机器",
SS.PORT AS "阻塞者端口",
SS.TERMINAL AS "阻塞者终端",
SS.PROGRAM AS "阻塞者程序",
SS.TYPE AS "阻塞者类型",
SS.SQL_ID AS "阻塞者当前SQLID",
(SELECT TXT.SQL_TEXT FROM V$SQLAREA TXT WHERE TXT.SQL_ID = SS.SQL_ID) AS "当前SQL语句",
SS.PREV_SQL_ID AS "上个SQLID",
(SELECT TXT.SQL_TEXT FROM V$SQLAREA TXT WHERE TXT.SQL_ID = SS.PREV_SQL_ID) AS "上个SQL语句",
SS.WAIT_CLASS AS "等待类",
SS.WAIT_TIME AS "等待时间秒",
SS.EVENT AS "等待事件",
SS.P1TEXT AS "参数一名",
SS.P1 AS "参数一值",SS.P2TEXT AS "参数二名",
SS.P2 AS "参数二值",
SS.P3TEXT AS "参数三名",
SS.P3 AS "参数三值",
'alter system kill session ''' || TO_CHAR(SS.SID) || ',' || TO_CHAR(SS.SERIAL#) ||''';' KILLSESSION,
'kill -9 ' || P.SPID AS KILLSYSPROC
FROM V$SESSION_BLOCKERS B
LEFT JOIN V$SESSION S ON S.SID = B.SID AND S.SERIAL# = B.SESS_SERIAL#
LEFT JOIN V$SESSION SS ON SS.SID = B.BLOCKER_SID AND SS.SERIAL# =B.BLOCKER_SESS_SERIAL#
LEFT JOIN V$PROCESS P ON P.ADDR = SS.PADDR
START WITH SS.WAIT_CLASS='Idle'CONNECT BY PRIOR B.SID=B.BLOCKER_SID ;
ASH报表
急症情况下一般都使用ASH报表,它会帮你抓住你想要的东西,基本上能抓住问题所在。包含TOP 等待事件 等待事件所涉及到的SQL。
在SQLPLUS 里面执行
@?/rdbms/admin/ashrpt ;
连续回车就能生成该报表,默认是15分钟之内的。
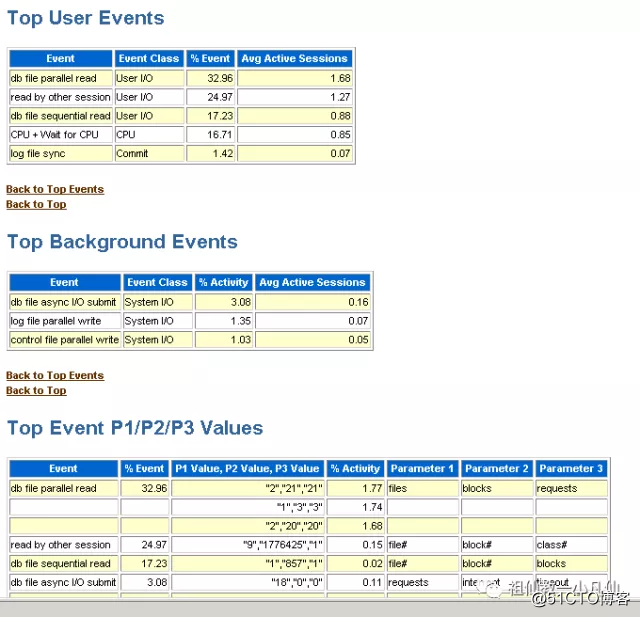
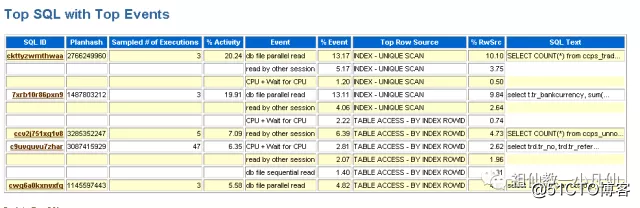
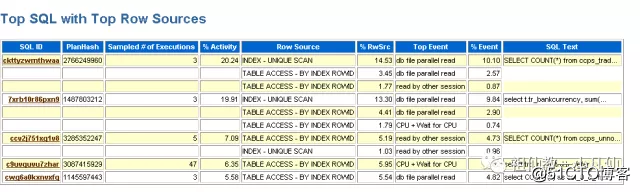
这样你就知道哪些SQL在捣蛋了
最后一招就是 重启大法
只要电脑慢,你会告诉别人重启下办公电脑就行,无论是WIN95,WIN98,WIN XP,WIN7,WIN10。这就是你的高招。
你觉得小仙会告诉你这个大招嘛? 重启数据库,不行就重启服务器。
因为重启了,你就是失去了AWR报表,也失去了ASH报表。因为数据库实列重启会造成快照断裂,断档了一切性能报表就失效了。因为性能报表存在内存中,或者说需要内存暂存及时的性能信息,而这个才是关键信息。
这样你两眼一抹黑啊! 你无法交代,也无法解释,心里没底。
那该怎么办啊?
就是杀死病毒啊! 把所有客户端链接统统杀掉,看下面杀人武器
[oracle@MKF-DB-56-10 dbscripts]cat kill_LOCAL_ORA.sh
ps -ef|grep LOCAL=NO|grep -v grep|awk '{print "kill -9",$2}' >> xxx.txt
ps -ef|grep "LOCAL=NO"|grep -v grep|awk '{print $2}'|xargs kill -9
如果系统还能用的话,或者SQLPLUS还能登上去操作的话,并且不慢。尽可能的先杀掉查询的链接。保证修改数据的链接,能继续下去。这样可以保证业务不丢失交易,让客户有个比较好的体验。
脚本是从V$SESSION SID+V$PROCESS 根据操作类型是SELECT的 并获得SPID ,然后在操作系统杀了它们。
第七章 SQL美化和规范化
SQL是应用程序发给数据库工作的基本单位!所以优化SQL是优化的重中之重。也是立杆见影,成效快,短平快,易出GDP成绩的。但是SQL优化又是个深奥,高深的技术,要充分理解数据库运行机制,也要了解业务特性,以及PL/SQL开发技术。是业务+开发+原理的三位一体!不是一般运维DBA能胜能的,不是会搭建个数据库,搭建个高可用DATAGUARD,搭建个集群RAC,搭建个数据同步OGG的运维DBA就可以优化的。也不是运维工程师能胜能的,虽然你会索引大法。如今SQL是有开发人员写的,自然他们写得好才叫奇迹,写得很垃圾那叫做正常。开发人员工作业绩就是出GDP,而不是出性能。他们连代码质量都无法保证,都要交给测试人员去完成,而且测试人员的数量都是开发人员的两倍。至于性能我就呵呵了! 你说对开发人员做培训,呵呵! 说深了他们又不懂,说潜了他们傲娇觉得鄙视你!
那我就说简单易用易懂而且见效快的SQL优化大法!
只要是个女人拍照照,必然要美化下自己,PS下自己,何况是个男人啊。所以作为男人写的SQL,也是要爱护自己的面子的,如今大男人主义盛行的年代,虽然IT男字写不好,可代码敲得也要漂亮的喊不要 不要啊!
其一 一段赏心悦目的SQL代码,会给人一种心情愉悦之感。
其二 可以很快判断出语法问题
其三 可以很快地了解到SQL性能问题所在
其四 见过丑的你才知道什么是美好的
SELECT GW.GW_NO, GW.GW_MER_NO, GW.GW_STATUS, (SELECT COUNT(1) FROM CCPS_TRADERECORD C WHERE C.TR_STATUS = 1 AND C.TR_DATETIME >= TO_DATE(:1, 'yyyy-mm-dd') AND C.TR_DATETIME <TO_DATE(:2, 'yyyy-mm-dd') AND GW.GW_NO = C.TR_GW_NO AND gw.gw_mer_no = c.tr_mer_no AND C.TR_CARDTYPE = :3 ) AS LAST_COUNT, (SELECT COUNT(1) FROM CCPS_TRADERECORD D WHERE D.TR_STATUS = 1 AND D.TR_DATETIME >= TO_DATE(:4, 'yyyy-mm-dd') AND D.TR_DATETIME < TO_DATE(:5, 'yyyy-mm-dd') AND GW.GW_NO = D.TR_GW_NO AND gw.gw_mer_no =
d.tr_mer_no AND D.TR_CARDTYPE = :6 ) TOTAL_CNT, (SELECT COUNT(DISTINCT UN.UP_TR_NO) FROM CCPS_UNNORMAL_PROCESS UN INNER JOIN CCPS_TRADERECORD UT ON UT.TR_NO = UN.UP_TR_NO WHERE UN.UP_CPD_TIME >= TO_DATE(:7, 'yyyy-mm-dd') AND UN.UP_CPD_TIME < TO_DATE(:8, 'yyyy-mm-dd') AND UN.UP_TYPE IN (2, 6) AND UT.TR_CARDTYPE = :9 AND GW.GW_NO = UT.TR_GW_NO AND GW.GW_MER_NO = UT.Tr_Mer_No ) PROTEST_CNT FROM CCPS_GATEWAY GW WHERE GW.GW_STATUS IN (-1, 1)
用PL/SQL格式化工具后这样
SELECT GW.GW_NO,
GW.GW_MER_NO,
GW.GW_STATUS,
(SELECT COUNT(1)
FROM CCPS_TRADERECORD C
WHERE C.TR_STATUS = 1
AND C.TR_DATETIME >= TO_DATE(:1, 'yyyy-mm-dd')
AND C.TR_DATETIME < TO_DATE(:2, 'yyyy-mm-dd')
AND GW.GW_NO = C.TR_GW_NO
AND gw.gw_mer_no = c.tr_mer_no
AND C.TR_CARDTYPE = :3) AS LAST_COUNT,
(SELECT COUNT(1)
FROM CCPS_TRADERECORD D
WHERE D.TR_STATUS = 1
AND D.TR_DATETIME >= TO_DATE(:4, 'yyyy-mm-dd')
AND D.TR_DATETIME < TO_DATE(:5, 'yyyy-mm-dd')
AND GW.GW_NO = D.TR_GW_NO
AND gw.gw_mer_no = d.tr_mer_no
AND D.TR_CARDTYPE = :6) TOTAL_CNT,
(SELECT COUNT(DISTINCT UN.UP_TR_NO)
FROM CCPS_UNNORMAL_PROCESS UN
INNER JOIN CCPS_TRADERECORD UT
ON UT.TR_NO = UN.UP_TR_NO
WHERE UN.UP_CPD_TIME >= TO_DATE(:7, 'yyyy-mm-dd')
AND UN.UP_CPD_TIME < TO_DATE(:8, 'yyyy-mm-dd')
AND UN.UP_TYPE IN (2, 6)
AND UT.TR_CARDTYPE = :9
AND GW.GW_NO = UT.TR_GW_NO
AND GW.GW_MER_NO = UT.Tr_Mer_No) PROTEST_CNTFROM CCPS_GATEWAY GW
WHERE GW.GW_STATUS IN (-1, 1)
当还是不漂亮,只是不丑了而已,人工化妆下。
SELECT GW.GW_NO,
GW.GW_MER_NO,
GW.GW_STATUS,
(
SELECT COUNT(1)
FROM CCPS_TRADERECORD C
WHERE C.TR_STATUS = 1
AND C.TR_DATETIME >= TO_DATE(:1, 'yyyy-mm-dd')
AND C.TR_DATETIME < TO_DATE(:2, 'yyyy-mm-dd')
AND GW.GW_NO = C.TR_GW_NO
AND gw.gw_mer_no = c.tr_mer_no
AND C.TR_CARDTYPE = :3
) AS LAST_COUNT,
(
SELECT COUNT(1)
FROM CCPS_TRADERECORD D
WHERE D.TR_STATUS = 1
AND D.TR_DATETIME >= TO_DATE(:4, 'yyyy-mm-dd')
AND D.TR_DATETIME < TO_DATE(:5, 'yyyy-mm-dd')
AND GW.GW_NO = D.TR_GW_NO
AND gw.gw_mer_no = d.tr_mer_no
AND D.TR_CARDTYPE = :6
) TOTAL_CNT,
(
SELECT COUNT(DISTINCT UN.UP_TR_NO)
FROM CCPS_UNNORMAL_PROCESS UN
INNER JOIN CCPS_TRADERECORD UT ON UT.TR_NO = UN.UP_TR_NO
WHERE UN.UP_CPD_TIME >= TO_DATE(:7, 'yyyy-mm-dd')
AND UN.UP_CPD_TIME < TO_DATE(:8, 'yyyy-mm-dd')
AND UN.UP_TYPE IN (2, 6)
AND UT.TR_CARDTYPE = :9
AND GW.GW_NO = UT.TR_GW_NO
AND GW.GW_MER_NO = UT.Tr_Mer_No
) PROTEST_CNTFROM CCPS_GATEWAY GW
WHERE GW.GW_STATUS IN (-1, 1);
再来个丑的
select name,
value,
unit,
(case
when unit = 'bytes' then
(value / 1024 / 1024 / 1024)
else
NULL
end) as UNIT_GBfrom V $PGASTAT;
select name,
value,
unit,case when unit = 'bytes' then (value/1024/1024/1024, 3) else NULL end as UNIT_GB
from V $PGASTAT;
人工美化原则:
1 select 字段 如果存在计算字段的话,或者对字段额外处理,则每个字段占一行
2 SQL 列长度由原来的80列改成120列,毕竟如今都是宽屏时代了
3 子查询的小挂号单独占一行,以显示出这里有个子查询
4 CASE 一般都是处理SELECT字段的,不能分成多行,必须独占一行,拥挤在一起,因为它们是个逻辑整体,拆多行,大脑无法把上下连在一起。
5 小挂号不要乱用,如上 CASE 前面加个小挂号 (case... ) as 小挂号是提高内部的运算优先级的。加不加小挂号都无法改变的优先级,那就不要加,会干扰视觉。
6 关键字都要右对齐
7 SQL语句应该小写,大写无法快速区分单词
8 请使用新的表连接法 inner join left join
9 inner join on x.id=y.id on与join 同在一行
10 FROM 后跟的是主表,紧接着是inner join 表,然后是 left join 最后是其他的
11 select 每个字段最好前面有表名前缀
12 尊重习惯把条件字段左边放 and (sysdate - :2 / (24 * 60)) >= trd.tr_datetime
select a.id,a.name,b.sex,b.btherday,c.country,c.address,d.email
from a
inner join b on a.id=b.id
left join c on a.id=c.id
right join d on a.id=d.id
where 1=1
and a.name='shark'第八 SQL简单优化大法
第一优化法 取消标量查询
SELECT GW.GW_NO,
GW.GW_MER_NO,
GW.GW_STATUS,
(
SELECT COUNT(1)
FROM CCPS_TRADERECORD C
WHERE C.TR_STATUS = 1
AND C.TR_DATETIME >= TO_DATE(:1, 'yyyy-mm-dd')
AND C.TR_DATETIME < TO_DATE(:2, 'yyyy-mm-dd')
AND GW.GW_NO = C.TR_GW_NO
AND gw.gw_mer_no = c.tr_mer_no
AND C.TR_CARDTYPE = :3
) AS LAST_COUNT,
(
SELECT COUNT(1)
FROM CCPS_TRADERECORD D
WHERE D.TR_STATUS = 1
AND D.TR_DATETIME >= TO_DATE(:4, 'yyyy-mm-dd')
AND D.TR_DATETIME < TO_DATE(:5, 'yyyy-mm-dd')
AND GW.GW_NO = D.TR_GW_NO
AND gw.gw_mer_no = d.tr_mer_no
AND D.TR_CARDTYPE = :6
) TOTAL_CNT,
(
SELECT COUNT(DISTINCT UN.UP_TR_NO)
FROM CCPS_UNNORMAL_PROCESS UN
INNER JOIN CCPS_TRADERECORD UT ON UT.TR_NO = UN.UP_TR_NO
WHERE UN.UP_CPD_TIME >= TO_DATE(:7, 'yyyy-mm-dd')
AND UN.UP_CPD_TIME < TO_DATE(:8, 'yyyy-mm-dd')
AND UN.UP_TYPE IN (2, 6)
AND UT.TR_CARDTYPE = :9
AND GW.GW_NO = UT.TR_GW_NO
AND GW.GW_MER_NO = UT.Tr_Mer_No
) PROTEST_CNTFROM CCPS_GATEWAY GW
WHERE GW.GW_STATUS IN (-1, 1);
所谓的标量查询是指在SELECT列表中带有查询语句,这样一来主表的每返回一行数据,都要经历一次子查询。这跟函数一个特性!如果主表本身返回大量的数据,好比100万那么子查询就要执行100万次。为此把标量子查询改写成表连接方式。
第二优化大法 条件字段不处理法
所谓条件字段不处理法 是说不对WHERE 后面的字段做任何处理。
select trd.tr_no,
trd.tr_reference,
trd.tr_status,
trd.tr_paystarttime,
trd.tr_datetime,
trd.tr_bankcurrency,
trd.tr_bankamout,
trd.tr_cha_code,
ch.cha_merno,
ch.cha_vpc_accesscode,
ch.cha_secure_secret,
trd.TR_SF_DATA,
trd.TR_CARDTYPEfrom ccps_traderecord trd
left join ccps_channel ch on trd.tr_cha_code = ch.cha_code
where trd.TR_MER_NO != :1
and trd.tr_checked = 0
and trd.tr_status != -2
and (sysdate - :2 / (24 * 60)) >= trd.tr_datetime
and upper(trd.tr_bank_code) = :3
and rownum <= :4
order by trd.tr_id asc
这语句的绿色部分对字段做了UPDATE处理。任务对字段做处理都无法利用上该字段的索引。
第三优化大法 隐身大法
所谓隐身 是指默认的优先级 比如字符和日期之间的转换
and a.name=12360
name 是字符类型的字段,而输入的是数字,默认情况下会对name做隐身转换。
第四优化大法 吸星大法
吸星 是指 星号 *
一般情况下 大家都喜欢 select from a 很省事 快捷,开发人员的最爱。至于会导致什么后果? 我就不说了,select 你真的需要全部字段吗? 或许你说是! 再问你 你需要这个表将来添加的字段吗? 哦 这个就不晓得了 那麻烦你 把你需要的字段一 一 写出来 好不?
星号确实很便利,当不是这样用的,星号必须远离真实表
如下星号远离 真实表
select *
from
(
select f.*,rownum as rn
from
(
select a.id,a.name,b.sex,b.btherday,c.country,c.address,d.email
from a
inner join b on a.id=b.id
left join c on a.id=c.id
right join d on a.id=d.id
where 1=1
and a.name='shark'
order by a.name desc) f
)
where rn <=10
第五优化大法 绑定变量法
此法只适应于 OLTP 和OLQP两种SQL请求类型
所谓的绑定变量,也就是开发人员常见的参数,定义个形参,真实运行的时候传递个实参。如下 JAVA一般是问号
select a.id,a.name,b.sex,b.btherday,c.country,c.address,d.email
from a
inner join b on a.id=b.id
left join c on a.id=c.id
right join d on a.id=d.id
where 1=1
and a.name=?为何要如此呢? 那是因为应用程序发给数据库的SQL 都是明文的字符编码,是我们人类看得懂的,机器看不懂的。机器只看得懂二进制的1010010。
因此数据库需要把传来的字符SQL命令翻译成二进制的1010,而这个工作叫做 编译或者是解释。搞过开发人都知道编译和解释都需要耗费CPU时间的。
虽然一个简单的SQL编译一次消耗不了多少CPU时间。如下图
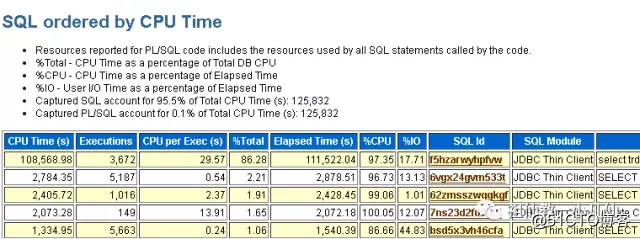
其中4个SELECT 执千次以上,一天时间内24小时中。还好目前这些语句都绑定了变量。
虽然小凡仙我觉得,这五条大法或许很多人看不上眼,或许也解决不了你目前的SQL性能问题。如果你结合强拆,分库分表,三大配置,已经本章的5大法。那么小仙认为你的数据库性能问题,基本上进一步缩小在可控的范围中。
第九章 WHO-IT 方法论
W (Waite Event)是等待事件
H (Hit rate) 是命中率
O (thrOughput)吞吐量
I (Inetractive) 交互式
T (Reponse Time) 响应时间
虽然如今Waite Event 等待事件很热门,从2005年热到现在,也没啥发展了!
ORACLE数据库优化除了优化SQL外,自然需要一套优化的方法。开始的时候7i和8i讲究的是优化命中率,就是各个缓存区的是使用效率的问题。虽然如今的等待事件被各位DBA放在嘴上津津乐道,当是并非命中率就没有用武之地了。
如果各个缓存池的命中率都比较低,低于90,是不是存在大量的问题呢?需要提高命中率来提高整个数据库的运行性能。
吞吐量:一个数据库服务器大家都知道有个IO的吞吐量,叫MBPS。另外还有个IOPS。而这里的吞吐量是指整个数据库系统。包含了内存,CPU已经ORACLE对象的锁资源。好比是一名员工的,在考核其工作任务是否繁重?是否达到了该员工的工作上限了? 因此需要量化该员工的工作能力。为此我们也是要压力测试数据库的上限值,一当任务量达到了一个阈值,那么数据库就出现了崩溃的迹象,也就是量化积累到一定程度后达到了质化的变化。此工作压力,不仅仅是单项工作任务的量上的增长,还指多项工作任务增加。
等待事件:是指完成了某个环节,在进入下个环节工作的时候,在等待条件的准备。比如说CPU在等待数据读入到内存中,这个等待过程就算做一个事件。
响应时间:这个是从用户角度来说,用户感觉快慢指的是时间尽量的短。从用户这里引申出对数据库内部所有都可以用时间来量化。DB TIME是我们常见的时间,这个时间是所有CPU内核工作的时间。等待事件也有时间叫等待时间。那么响应时间=工作时间+等待时间。自然工作时间和等待时间还可以细分。
交互式:这个是从应用角度来看,在BS架构中一个业务,一个页面,一个按钮它们的动作将会产生多少个SQL发给后端的数据库执行? 如果DBA不懂业务的话,自然无法优化业务,如果不懂JAVA的话,自然无法优化页面,如果不懂JAVA开发工具用来调试的话,自然不懂按钮的优化。
什么意思呢? 这样说吧! 一个按钮按下去,将执行1-N多个SQL 。那么你不懂的JAVA工具的话,就无法抓住这一些SQL。 而平时是在数据库角度来看每个SQL,查出最慢的SQL。而数据库看到慢的SQL不一定是按钮发出来的SQL。或许你说通过SESSION就能抓到,可惜的是应用程序使用的链接池,每个SQL会使用不同的链接线路,自然就分布在不同的SESSION中。
按钮和按钮之间 是否有重复的SQL呢? 比如说一个分页呈现出数据来,一个NEXT按钮。而这个NEXT按钮 执行的是重新查询所有的数据,然后在现在第2页呈现出来。
所以 SQL 与SQL 之间是有前后顺序的,这一串我们需要把它给抓起来的。
我们DBA 干到 页面内按钮与按钮之间是否有重复的,就非常不错了!
至于业务 小仙我想说懂些好装逼,与高层有沟通的语言! 剩下的只能踢给JAVA开发人员去优化吧!
为此我们需要建立一个表格,把SQL 关联到页面,按钮。这样下来我们就知道一个页面下有多少个SQL,一个按钮执行了多少SQL,前后顺序。自然反推也知道哪个SQL来自于哪个页面,哪个按钮。
page_id,page_name,page_wrl,EVENT_name,SQL_SETP,SQL_ID,sql_text;