第一章 前言
1.1 作者简介
本人小凡仙,真姓为曾凡坤,一个很普通的人。

于2004年去了东莞工作,在一家台湾工厂干程序员活。主要是用C++BUILDER工具和微软SQL SERVER数据库,开发工厂的信息系统。其实就是简化各个车间文员的工作,以及比较好的让各部门领导查看数据而已。虽然叫ERP系统,实际就是个MIS信息管理系统!2005年来到了深圳,开始在一家软件公司为证券信息公司开发个信息发布系统,使用C++BUILDER开发ORACLE数据库。后来再去了工厂里开发ERP系统,实际上是维护ERP系统,用的是DELPHI开发ORACLE。在这里主要是学到了PL/SQL,已经对ORACLE和LINUX系统有个基本了解,本来想学ERP整体思想,可时运不佳。ERP随着经济而萎缩,招聘职位越来越少。2007年转向了ORACLE管理,获得一份DBA工作,其实就是个运维DBA。2008年的金融危机使我失去了该DBA职位。然后3年内从事的数据库开发的工作,主要是ORACLE开发,开发什么经营分析系统和移动139邮箱的报表系统。因此对SQL写法,SQL执行,SQL优化是有深刻的体会的。
2013年再度回到了DBA岗位,虽然从事运维DBA,负责多个系统的集群和灾备数据库。
干了多年,或多或少遇到过性能问题,也尽力去优化了。感觉数据库最后端优化的空间是不大的!后来去了家物流公司,据说这家公司在淘宝物流的单量排在第10位,不过压力也挺大的,经常CPU飙高,负载指数达到500!
1.2数据库发展史
计算机的起源相信大部分大学计算机课本都有介绍,不管是科班和非科班以及职业中学都有介绍。
众所周知的第一台计算机是美国军方定制,专门为了计算弹道和射击特性表面而研制的,承担开发任务的“莫尔小组”由四位科学家和工程师埃克特、莫克利、戈尔斯坦、博克斯组成。1946年这台计算机主要元器件采用的是电子管。该机使用了1500

ENIAC
个继电器,18800个电子管,占地170m2,重量重达30多吨,耗电150KW,造价48万美元。开机时让周围居民暂时停电。这台计算机每秒能完成5000次加法运算,400次乘法运算,比当时最快的计算工具快300倍,是继电器计算机的1000倍、手工计算的20万倍。用今天的标准看,它是那样的“笨拙”和“低级”,其功能远不如一只掌上可编程计算器,但它使科学家们从复杂的计算中解脱出来,它的诞生标志着人类进入了一个崭新的信息革命时代。
然而,英国在二战期间研制的用于破解密电的电子计算机巨人(Colossus)却要比ENIAC早两年(1943年12 ),巨人计算机是第一部全然电子化的电脑器件,使用了数量庞大的真空管,以纸带作为输入器件,能够执行各种布林逻辑的运算,但仍未具备图灵完全的标准。巨人计算机建造到第9部“马克二号”4,但是其实体器件、设计图样和操作方法,直到1970年代都还是一个谜。后来温斯顿·丘吉尔亲自下达一项销毁命令,将巨人计算机全都拆解成巴掌大小的废铁,巨人计算机才因此在许多计算机历史里都未留下一纸纪录。英国布莱切利园目前展有巨人计算机的重建机种。
有专家说算盘也是计算机,如果从算数来说,这点不可否认! 当算盘依旧是算盘,不是计算机。计算机是用机器来计算, 算什么呢?自然是算古代应用数学。我国对数学的应用算盘就够了,没有继续发展下去。而在欧洲应用数学就有不断的提出高难度要求,促进了对计算数字的工具发展。计算机是从加密机和破密机发展而来的!
英国拍了部二战题材的电影叫《模拟游戏》

讲的是图灵用机器去破译密码的故事。图灵何许人?
艾伦·麦席森·图灵(Alan Mathison Turing,1912年6月23日-1954年6月7日),英国数学家、逻辑学家,被称为计算机科学之父,人工智能之父。[1]
1931年图灵进入剑桥大学国王学院,毕业后到美国普林斯顿大学攻读博士学位,二战爆发后回到剑桥,后曾协助军方破解德国的著名密码系统Enigma,帮助盟军取得了二战的胜利。
另外个人是冯·诺依曼[1] (John von Neumann,1903~1957),20世纪最重要的数学家之一,在现代计算机、博弈论、核武器和生化武器等诸多领域内有杰出建树的最伟大的科学全才之一,被后人称为“计算机之父”和“博弈论之父(涯杰)”。第二次世界大战期间为第一颗原子弹的研制作出了贡献。为研制电子数字计算机提供了基础性的方案。
这两个人奠定了现代计算机的基础,尤其是可存储的程序!
开始的第一代的计算机采用的是纸带串孔来表示01,表示程序和数据。要求计算机提供计算的结果。这样为第一代原子弹的诞生提高了速度。后来的发展就是把纸带编程了磁盘,里面不在存的是01,而是ASM编码,俗称汇编语言。因为大家认为每次人工在纸带上打孔,自定和修改都很不方便,而且学习0101也很费力和费时。自然也很少人用得起!后期计算机发展迅猛,计算速度越快,而人类编制计算任务相对来说很耗时间,计算机的计算能力被闲置了很多。这样一来一边硬件的发展,一边是编程的发展。硬件从大型机,到小型机,再到台式机,以及目前的手机!而且编程发展从汇编语言到C语言 后面就是DELPHI, JAVA,PYTHON语言。
而数据库是怎么来的呀?除了语言的发明外,还发明了操作系统这个东西,它是中介而已。
说白了就是社会分工,由操作系统负责硬件的交道和协调工作。既然有可以存储的程序,自然会有可以存储的数据。程序是二进制编码 10101这样的内容,后缀名字一般都是.EXE,linux一般都是bin 。而数据以文本文编码而保存,一般是TXT命名,自然还有其他结构的。
计算机除了科学计算外,还有一个用途是数据处理。程序操作数据文件,程序代码很少,而数据文件确很多,或者很大。程序操作这样的数据文件,就是我们的数据库初型!
这就是数据库的雏形,程序和文件!你也可以编写这样的数据库。我用C++BUILDER 使用结构数据类型把股票信息,在套个一维数组使用流化类保存在文件当中。可以新增,保存,查找,删除等操作。
这样的雏形数据库就大部分开始应用在企业领域当中,也就是企业请人来编程,听说是用的COBOL。
COBOL(CommonBusinessOrientedLanguage)是数据处理领域最为广泛的程序设计语言,是第一个广泛使用的高级编程语言。在企业管理中,数值计算并不复杂,但数据处理信息量却很大。为专门解决经企管理问题,美国的一些计算机用户于1959年组织设计了专用于商务处理的计算机语言COBOL,并于1961年美国数据系统语言协会公布。经不断修改、丰富完善和标准化,目前COBOL已发展为多种版本。
后来出现了商业软件,比如我们学校教过的基于DOS操作系统的FOXBASE,FOXPRO和基于WINDOWS系统的VISUAL FOXPRO 。这就是第一代数据库 是商业化的软件!大家是用的ACCESS也是这一类
第一代桌面数据库 在这本讲性能优化的书中,我重点看到的是它是个桌面型数据库,只供一个人操作,用户并发数是一!当然商业化第一代数据库提供了统计功能和数据文件的管理功能。
第二代是服务型数据库 主要代表是微软公司的SQLSERVER 和甲骨文公司的ORACLE 以及IBM 公司的DB2。 这代数据库完成了SQL统一接口,虽然在各家数据库当中有特色的SQL,比如微软的T-SQL,甲骨文公司的PL-SQL。同时也定义了关系理论,并在这代数据库得到了实现! 这代主要是C/S架构,可以同时接500个客户同时操作! 使用不同的锁解决用户并发问题。基于地第二代数据库有大量的ERP系统,包括SAP和EBS!
第三代是WEB集群据库,因为WEB的发展刺激了数据库的发展,代表是MYSQL。在工厂里SAP系统使用小型机做为数据库平台,因为它稳定,可靠,性能卓越。没有必要搞集群,没那个动力,支持百儿千的用户量没问题。然后在WEB世界里,万,百万,千万的用户量是一件很常见的量,并且是老板很开心的事情,是技术大牛值得追求的事情。为此IT技术再次出现了分层,出来了个应用服务器,比如说TOMCAT等。从C/S架构两层变成了三层,既是浏览器+应用服务器+数据库服务器。除了分层还有就是集群,应用服务器TOMCAT也集群,数据库MYSQL也集群,自然ORACLE也集群了!
第四代是集团化数据库。 因为互联网+和移动互联网出现!用户量从万的级别变成了亿的级别。淘宝平日PV量(页面浏览量)16亿到25亿之间,而且12306.cn也有10亿的量,而真实的UV量(用户量)也过亿。象如此大的用户,靠集群已经无法支撑了,需要各种不同特性的数据库组团打怪,形成集团化作战。列如使用 上千台MYSQL服务器承担查询任务,使用上百台ORACLE集群服务器来承担,库存,支付,结算的工作。 再用NOSQL数据库如今火爆的REDIS和MONGODB集群来完成非结构的查询.使用内存数据库完成缓存查询,列入memcache,用列式数据库完成消费账单的统计功能。
数据库的发展解决数据的共享和用户并发的控制!
1.3性能为什么会慢?
性能为什么会慢?原因有1,2,3,4,5等。主要是慢是个趋势,无可逆转,如同人总要衰老的!
也就是说当你的系统哪怕是上线后不曾修改,随着时间和业务的发展必然达到硬件上限能力!而现实有很多原因导致系统未必达到那个境界就开始慢起来了,如同我们希望人没有病没有痛的老化而死去!
慢的第一个原因是用户量多了!
这个原因是个开心的事,说明用的人多啊,只有增加硬件的投入
慢的第二个原因是数据量变多了!
这个或许也是开心的原因,除了追加硬件投入外,还可以减少数据来提高性能
慢的第三个原因是功能越来越多!
很显然这也是个开心的原因,除了硬件追加外,没别的法子
慢的第四个原因是设计师设计得不好!
这是个很重要的原因,因为设计的不好或导致很多很多问题出来,而且设计不好的原因会被深度掩藏起来。解决办法是重新设计新版本。
慢的第五个原因是开发人员SQL写的不好!
这个是目前市场上性能优化的重点,可开发人员都是充忙地加班加点赶紧度呢!解决之道是制定个规范,而且这个规范易用,然后再SQL审计把关下。后期只好请DBA参加优化。
慢的第六个原因是数据库和系统的参数配置不好!
这个也是目前市场优化的重点。招个有经验的DBA来配置。不要让开发人员去管理数据库!
慢的第七个原因是硬件问题
可能硬件某个环节坏掉了。
1.4性能优化新常态
新常态 就是说优化的重点不是在SQL的化和参数的配置。虽然这两项比较能立杆见影,性能突进。好像是个倚天剑和屠龙刀!采用SQL和参数两项优化外,时间过了还是会出现性能问题,只不过是其它方面的性能问题。
常态是 我们该从设计领域着手,从数据库发展史和计算机发展史获得灵感,就是分工和分层!依据JAVA编程的思想高内聚 低耦合!根据业务特性来配置硬件,设计系统,是系统各个子系统高内聚,低耦合。相互独立自主,又不互相影响!
本书主要谈的是ORACLE性能优化,主要是讲ORACLE在服务型数据库和WEB集群数据库领域的优化,比如工厂里的SAP,EBS和基于WEB的金融,云ERP,进销存等系统。在互联网+,移动互联网领域ORACLE基本上属于集团化中的子数据库系统,跟2,3代数据库差不多,不再是优化的重点,而且优化的方法依旧如此,没有特殊之处。
第二章强拆
以下强拆是基于WEB化的数据库应用系统,如果是工厂的ERP ORACLE EBS就飘过吧!
2.1 为什么要强拆?
本章读者群是,技术总监,系统架构师,数据库架构师,系统设计师,高级程序员。只有这样的角色才能起到强拆作用!没有领导的号召,城管才不去搞拆迁活动啊!因为我们的数据库大部分基本上,几乎是,90%都是混合型数据库。所有的系统,该系统所有的业务都在一个数据库里面实现。也就是说所有的表都同在一个用户下,集群多也是100%克隆式的扩展而已!为什么要混合在一起呢?那是因为数据库设计课程当中没有讲过,讲的是3N方式和冗余措施,讲的是逻辑关系ER图。而应用开发人员还有ROSE的时间图,状态图。
一般来说一个系统上线要2-3年的时间才出现数据库性能的问题。而此时留守来的只有高级开发人员和技术总监,以及招来少量的低级开发人员做维护性开发。慢起来就是突发的事件,要承担巨大的精神压力,轻则业务缓慢运行,重则业务中断。比如12306每到节假日不可开机!做为留守或者是半路而来接手的技术总监幸福指数直接下降!顶多都是临时优化,头疼吃感冒药,脚疼打麻醉药,应付过去了事。实在没办法立即采购硬件来顶。和尚敲钟,能顶一天算一天。假如你要在这家公司长期干下去,不想蹦来蹦去的,或许你接手这个系统已经优化很多次了,已经买了多次硬件来顶,到你手上已经没有了优化空间和余地了。
那么怎么办?老板会怎么看你?老板会会相信前几任把优化空间用完了吗?他只会认为前几任有本事,而且你是废物!
2.2 第一次拆按业务来拆
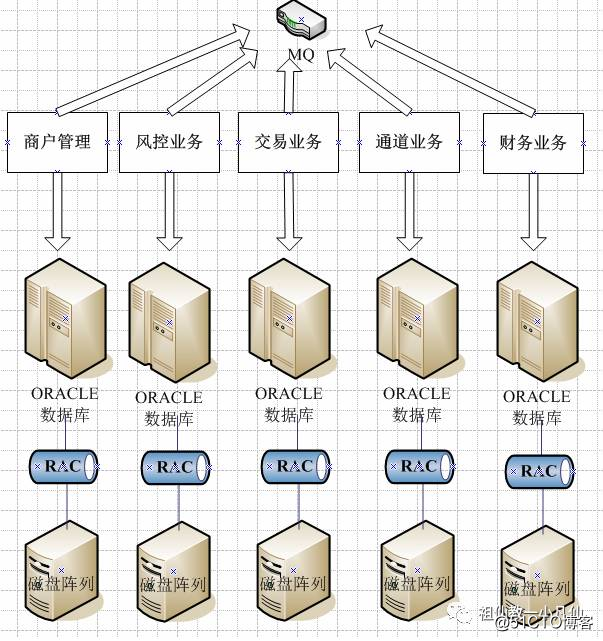
一个系统,可以细分多个子系统,或者说子业务,不同的业务。比如说我所在的第三方支付公司,公司业务主要流程如下,商户开户-,商户发来交易,过风控,发给银行,走银行通道,结算,划款,退款,拒付。那么大致来说有如下几个业务:
1 管理业务主要是商户管理,商户自身管理。
2 风空业务 这个业务涉及到很多规则。
3 交易业务 处理交易,接受银行交易返回信息,核对交易。
4 银行通道管理,银行通道有很多限制,比如说交易量,拒付指数
5 财务业务 涉及到结算,划款,退款。
那么就说可以分成5种业务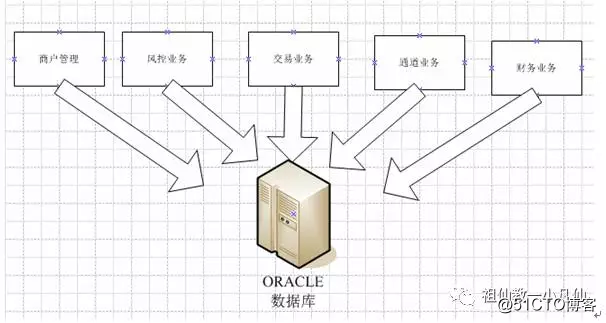
这里主要是根据业务来划分,也可以叫系统。接下来如果需要可以深度拆分,系统-》子系统-》模块
或者是业务-》子业务--》模块。这就根据用户数量级别,公司经济实力,以及开发实力来定。
做为技术总监,高级开发人员应该说是熟透业务,按业务来拆分是轻而一举的事情!
第一按业务来拆分的话,当其中一个业务发生了性能问题,不会影响到其它业务的正常运行。然后混合型数据库,当每月月底或者月初的时候,都要给商户做结算,有的是30天,有的60天,有的是90天,还有的是180天。另外还要给销售人员算提成,提成都是根据商户的交易量来算的。这将是个巨大的IO运算量,每到这个时候数据库就要卡好几次对吗?而且会影响到其他业务正常运行,比如通道不行了,很慢啊!商户打来电话抱怨很慢了。这要承受巨大的压力!
有了业务拆分,它好!你也好,何乐而不为呢?采用JAVA思想高内聚,低耦合,通过接口来完成业务之间的数据共享。那么设计接口呢?有以下几种方式
1 后端数据库DBLINK模式,没个业务都用一个用户名归纳子在一起,包含,表啊,存储过程啊,视图和函数啦!这里介绍下恒波手机卖场,用.NET开发的WEB进销存系统就是采用该方式完成业务拆分。
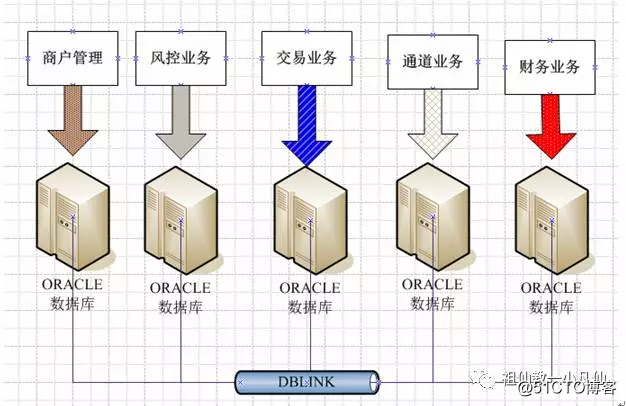
2 采用多数据源方式,NET和JAVA都支持多数据方式。比如财务当中的结算业务就要调用商户管理业务的数据库。那么财务业务要再多配个数据源就是商户的数据源。我们公司就采用这种方式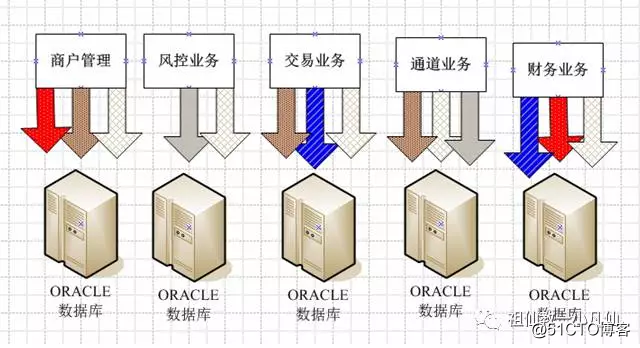
3 采用MQ消息机制,JAVA通过内部服务对象发消息给另外个对象要求某些数据。
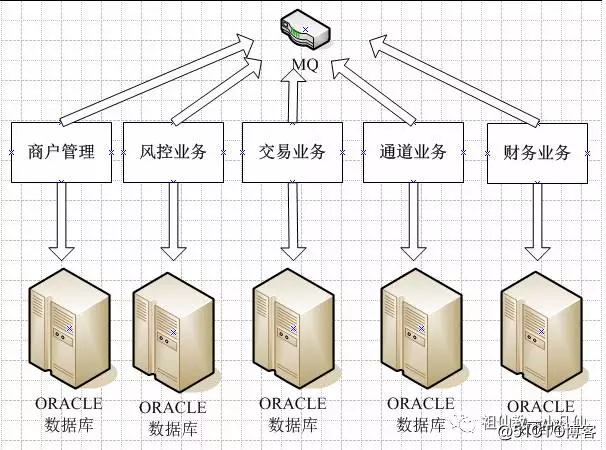
4 采用数据库中间件 MYCAT ,通过数据库中间件,mycat,myproxy,oneproxy等分析接手到的SQL语句来,分析用到的表名来路由具体的数据库。
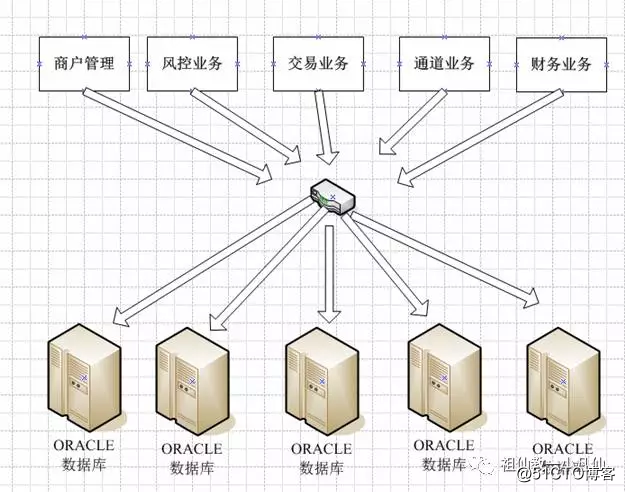
这四种方式最好的是第三种,在JAVA层完成数据接口。主要是清晰可控,并发能力也能提高,自然这涉及到了开发实力。不过一开始设计的时候考虑进去了的话,确实是一件不难的事情。其次是第二种采用多数据源方式,这方式NET会用得多。也比较容易实现。
再者是第一种方式,这方式适合把业务放在数据库端来实现的,而应用端只实现用户友好方式。
最后一种就是第四种,这是一种偷懒的方式,基本上应用层代码不用改,数据库层表可以不用分离。就靠数据库中间件来路由。
为什么这样排序呢?因为有利于开发人员进行SQL的分离,目前的SQL很多是多表的联合查询,这些表很多是跨业务系统的。开发人员依旧把过去混合模型中的习惯延续下去,自然对后续的机器扩展带来性能问题。
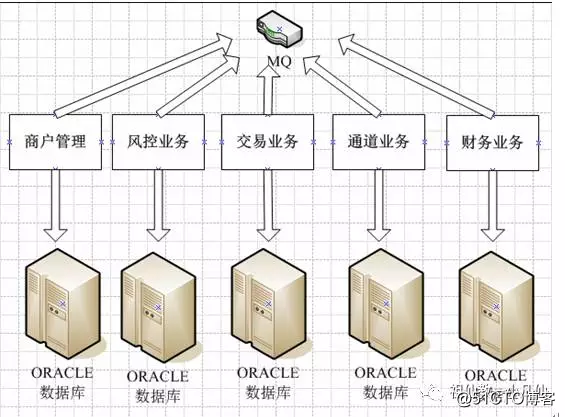
物理部署方案
1 单数据库模式
2 单集群模式
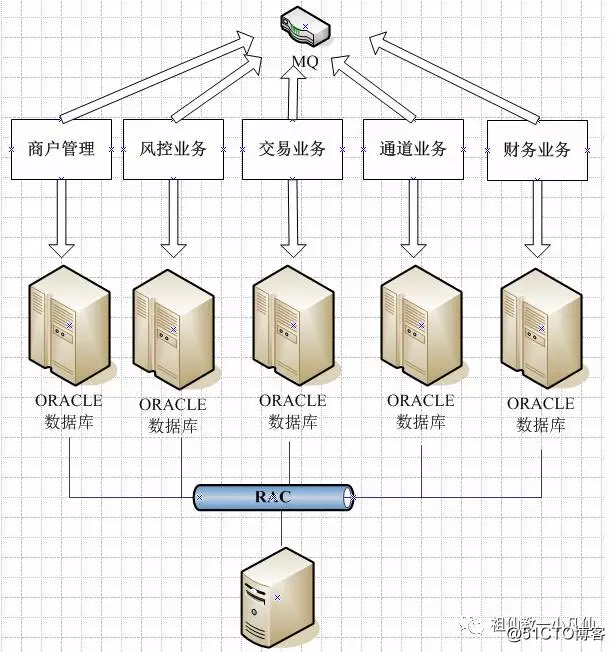
3 多集群模式
2.3 第二次拆读写分离 OLSPOLTP OLAP
。。。。。。。。。
SQL请求分离
2.3 第二次拆 SQL请求分离
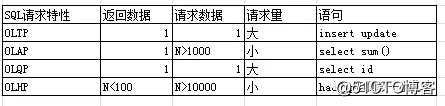
分离这个词组如今已经非常耳熟,熟到已经熟透了。在MYSQL领域经常听说到分库分表,读写分离之类的架构思想,依旧是3-4年前的事。这里分离要结合业务特性,就是SQL请求特性来分离。应用程序发往数据库的SQL是有不同的类型,虽然可以分为INSERT,SELECT,UPDATE,DELETE等,虽然这些类型的SQL,当它们的请求是不一样的。站在应用程序角度来看,它发往后台数据库的SQL频繁度,要求的响应时间,以及SQL所涉及访问数据的多少来划分,OLQP, OLTP,OLAP,OLHP 这四个类型就是小仙我的划分。什么是OLTP和OLAP呢?
OLTP是在线业务处理;
OLAP是在线分析(统计);
OLQP是在线业务查询;
OLHP是在线业务(大数据,分析,统计,挖掘);
详细介绍如下:
当今的数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果.
OLTP:
也称为面向交易的处理系统,其基本特征是顾客的原始数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果。
这样做的最大优点是可以即时地处理输入的数据,及时地回答。也称为实时系统(Real time System)。衡量联机事务处理系统的一个重要性能指标是系统性能,具体体现为实时响应时间(Response Time),即用户在终端上送入数据之后,到计算机对这个请求给出答复所需要的时间。OLTP是由数据库引擎负责完成的。
OLTP 数据库旨在使事务应用程序仅写入所需的数据,以便尽快处理单个事务。
OLAP:
简写为OLAP,随着数据库技术的发展和应用,数据库存储的数据量从20世纪80年代的兆(MB)字节及千兆(GB)字节过渡到现在的兆兆(TB)字节和千兆兆(PB)字节,同时,用户的查询需求也越来越复杂,涉及的已不仅是查询或操纵一张关系表中的一条或几条记录,而且要对多张表中千万条记录的数据进行数据分析和信息综合,关系数据库系统已不能全部满足这一要求。在国外,不少软件厂商采取了发展其前端产品来弥补关系数据库管理系统支持的不足,力图统一分散的公共应用逻辑,在短时间内响应非数据处理专业人员的复杂查询要求。
联机分析处理(OLAP)系统是数据仓库系统最主要的应用,专门设计用于支持复杂的分析操作,侧重对决策人员和高层管理人员的决策支持,可以根据分析人员的要求快速、灵活地进行大数据量的复杂查询处理,并且以一种直观而易懂的形式将查询结果提供给决策人员,以便他们准确掌握企业(公司)的经营状况,了解对象的需求,制定正确的方案。
不过在小仙这里明确定义为在线分析,类似于SELECT SUM() 之类的统计功能。
OLHP
真正的数据库仓库,我们使用大数据HADOOP 为操作系统平台,用HIVEHBASE做数据库。用SPARK来做分析。
OLQP的定义是读写分离中的读操作,在线查询功能!因为MYSQL来支持互联网,互联网有大量的查询简称QPS。而在一般数据库SELECT查询量也是很多的。
那么第二次拆分是 OLTP,OLQP,OLAP,OLHP了
目前来说OLHP是个独立的系统,往往与常规的交易系统隔离开了。比如说通过ETL程序把交易数据迁移到数据仓库中,同时经过清洗和转化。小仙认为将来可能每个业务都有可能独立的分析库。比如我公司的风控数据仓库,全球化的今天高官需要在线模式使用数据仓库。未来不会跟正常系统混合在一起,不过作为拆分思想,这里稍微预测下。
重点是OLTP,OLQP,OLAP
因为这三个特性非常不一样,OLTP是交易类型,是用户并发量大,要求时间非常短,事务要求一致性很高,要求数据安全度很高,不容许数据丢失。而且涉及数据比较少,涉及的表也非常少。
OLAP 在线统计用户量或许少,主要是查询的数据比较多,涉及多张表联合查询,主要消耗IO和内存。
而OLTP是消耗CPU和锁资源。完成一个付款交易,货架减库存的交易
OLQP 把它独立开来,从OLTP中分离出来,目的是不影响高并发OLTP. 因为用户查询量是非常大的。
比如物流当中,用户经常要查自己的快递,运输的情况,到达了哪个站点,以方便自己安排接货.
也就是说把INSETDELTET UPDATE语句放进指向OLTP数据源中;
把通过索引访问的SELECT 语句指向OLQP数据源中。比如说SELECT NAME FORM STUDENTS WHERE ID=? 这样根据ID查到学生的姓名可能要放进OLQP中。
简单来DML操作放进OLTP中,而把单索引访问的SELECT放进OLQP中,
把大数量的统计的SELECT 放进OLAP中。
这样拆分有利用ORACLE众多的参数调整。最明显的一点就是 OLAP可以创建好多好多的索引,而且不影响交易的速度,因为每次的数据插入,更新都有同步维护索引,如果索引多了话,维护索引的时间会更长,每个索引可能会发生索引分裂,从而导致每笔交易时间拉长,进而会造成更多的锁资源争用。而且OLTP中的表只需要两个索引。同时两种类型的表可以不同的形态,从而两种都得到了性能上的提高。
比如说OLTP除了设计到3N范式外,还可以进步提高到4-5N范式,而不用考虑什么数据冗余的问题。
数据冗余全部交给OLAP当中去设计。OLAP可以采用大数据块和压缩技术以及列式存储,ORACLE 11G 的结果集缓存,12C的IMO。什么是IMO呢?
2014年6月,在Oracle 12c的12.1.0.2版本中,Oracle正式发布和引入了基于内存和列式计算的In-Memory Option 简称IMO。这个特性有利统计单列。比如说统计全年的交易额,只涉及一个字段,
SELECTSUM(TR_AUMOUNT)
FORMTR_TRADE
WHERE TR_DATIME BETWEEN XXXX AND XXX;
在过去它要访问所有行的每个字段,要把每个字段读取到内存然后在筛选出来。而这个特性就是列转行地存储在数据块中。也就是说数据块只存一个字段的内容,相对行来说所需要的数据块数量非常少。而平时是通过联合索引方式达到该目的,比如建个(TR_DATIME,TR_AUMOUNT)
因此 OLTP,OLQP,OLAP 分别是事务量(TPS),查询量(QPS),吞吐量(OPS). 而OLHP 就是挖掘量!!
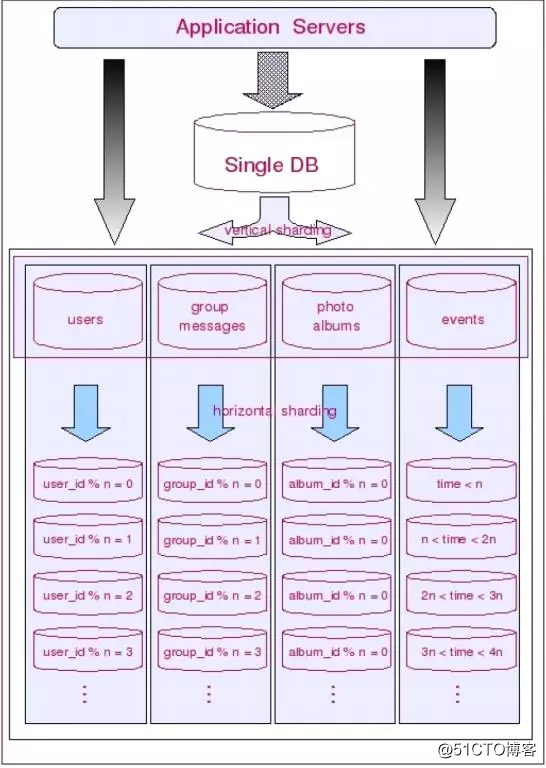
2.4 第三次拆数据的水平拆分
这个拆分已经接近了技术层面了,当然这个技术拆分必须结合第二层拆分才能发挥到最大性能。
一方面根据数据冷热程度,拆成热,温,凉,冷。把热的和温的放进OLTP当中,把温的,凉的,冷的放进OLAP中,把冷的放进OLHP当中。 这中间有个交叉重复,这主要考虑数据同步问题。另外市面上常有个叫法是叫当前表和历史表。差不多是以冷热程度来拆分的。 那么依据什么来判断冷热的程度呢?
小仙我认为根据修改频繁度来决定,比如说insert delete 和短时间内发生的UPDATE操作,以及实时查询单笔要求的数据,可以做为热表。而温表是查询比较多,同时只会发生UPDATE 一条或多条数据。凉表是数据不在发生变化了,不再发生UPDATE,更不能发生DELETE了。而且查询量大,主要是统计类型。所谓冷表就是基本没有什么查询了。这个要看业务界面上的设计了。我在工行可以查过去好几年前的美元购买记录。
为此每个表都必须带有两个必要的字段(创建时间,更改时间)
另外根据OLTP和OLAP的特性使用不同的分区技术,比如说OLTP常用是散列分区,而OLAP常用的是时间分区,数据量大的话用到双层分区,先时间分区,然后列举分区,比如说移动公司的时间加省份。
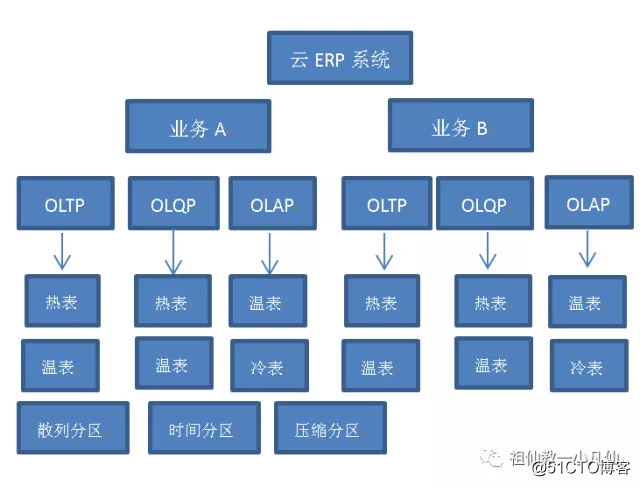
这个图代表了三次拆分,也可说是拆了三层。如果业务复杂,或者用户量超多。可以在业务层再细分模块成。如果使用JAVA对象MQ传递消息 完成数据共享的话,再采用多集群部署。应该达到非常高的性能,同时也是高扩展,高可用的三高典范设计。哪怕是真的出现了数据库性能慢的事,也是发生在局部当中,不影响全局整个系统运转。而且每个局部都是单纯化,为此针对该单纯可以非常个性的优化系统,数据库以及SQL语句。而不会象混合数据库样,为个SQL语句创建的索引,又导致其他SQL语句改变了执行路径,从而造成该SQL语句变慢的麻烦。
第三章 分库分表
市面上流行的分库分表的说法,其实都是来自MYSQL那伙人的.MYSQL DBA 太弱鸡了,毛办法,没有分区表,数量那么太,用户那么变态。什么根据水平拆表,USER_ID= 分到其他库中。
MYSQL DBA 爱拆法
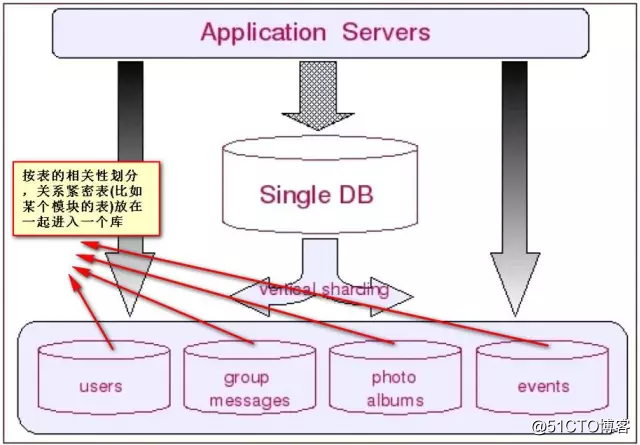
Sharding的基本思想就要把一个数据库切分成多个部分放到不同的数据库(server)上,从而缓解单一数据库的性能问题。不太严格的讲,对于海量数据的数据库,如果是因为表多而数据多,这时候适合使用垂直切分,即把关系紧密(比如同一模块)的表切分出来放在一个server上。如果表并不多,但每张表的数据非常多,这时候适合水平切分,即把表的数据按某种规则(比如按ID散列)切分到多个数据库(server)上。当然,现实中更多是这两种情况混杂在一起,这时候需要根据实际情况做出选择,也可能会综合使用垂直与水平切分,从而将原有数据库切分成类似矩阵一样可以无限扩充的数据库(server)阵列。下面分别详细地介绍一下垂直切分和水平切分.
垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。(这也就是所谓的”share nothing”)。
水平切分于垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库中,对于应用程序来说,拆分规则本身就较根据表名来拆分更为复杂,后期的数据维护也会更为复杂一些。
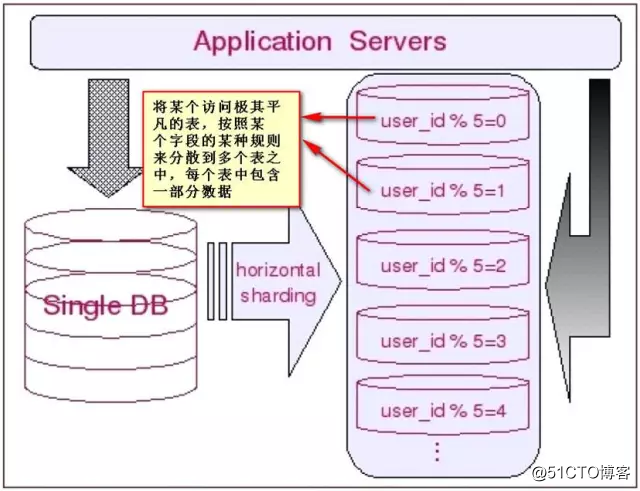
让我们从普遍的情况来考虑数据的切分:一方面,一个库的所有表通常不可能由某一张表全部串联起来,这句话暗含的意思是,水平切分几乎都是针对一小搓一小搓(实际上就是垂直切分出来的块)关系紧密的表进行的,而不可能是针对所有表进行的。另一方面,一些负载非常高的系统,即使仅仅只是单个表都无法通过单台数据库主机来承担其负载,这意味着单单是垂直切分也不能完全解决问明。因此多数系统会将垂直切分和水平切分联合使用,先对系统做垂直切分,再针对每一小搓表的情况选择性地做水平切分。从而将整个数据库切分成一个分布式矩阵。
ORACLE DBA 爱拆法
第一 业务拆分法 也就是前面两张讲的按业务,按功能业务拆分法
第二 就是按 SQL请求特性 拆分法 : OLAP OLTP OLQP OLHP
第三 分表法
3.0 在甲骨文公司没有开发SHARDING产品前,我们可采用如下方式,达到分库分表的效果
3.1 垂直拆分法:
根据字段使用频率拆分, 就是有些常用的字段放在一个表中,其他不常用的字段放在另外个表中。 垂直拆分叫法跟 MYSQL 不一样了3.2 水平拆分法:
一般使用分区技术。根据某个字段的值 把数据分在不同表中。 比如根据时间字段,状态字段, ID值。 时间字段采用范围分区,状态字段采用列表分区,ID采用散列分区。
3.3 根据生命周期拆分法:
根据用户对数据的使用频繁度来把表拆成,热表,温表,冷表或者是说 当前表 历史表。
第四 分表分库
这里说的是如何把分出来的表,迁移到其它数据库当中。使用其它数据库的服务器能力一起为应用程序提供服务
对于 按业务拆分的库, 一般都是独立的数据库,数据库之间的数据不做同步,减少耦合性。只是在应用程序上做个服务接口,为其他业务提供本库的数据服务。
对于 SQL请求特性拆库的话,就需要完成数据同步服务了!
比如OLTP 一般采用集群模式,或者是主备模式。小仙我一般建议RAC集群模式,表采用散列分区,每个数据库实列分别承担不同散列分区的SQL请求操作,这样扩大了用户的并发量,同时也提高了OLTP性能。
而OLAP 一般采用独立的数据库,通过OGG来或者简单的DBLINK来从OLTP里获得数据。
OLAP 主要是为了统计而重新设计的,可以在使用32KB空间,压缩技术,结果集缓存,创建N多索引,而不用当心影响OLTP插入性能。采用RAC集群模式多个分区表分别在多个数据库实列上,并开启并行操作。自然达到了MYSQL 多库同时完成统计的功效!
OLQP 一般可以同过 主备模式 从OLTP 及时同步数据到DG库上。 主库可以单独拿出一个实列完成DG的数据传输,使用LGWR +ASYNC 及时把数据传给到DG库上。log_archive_dest_30 可以支持30个DG。这样会对主数据库带来性能压力。毕竟太多了,需要LGWR进程工作。支持4-5台DG,还是可以的。 4-5台ORACLE DG性能完胜MYSQL 100台服务器。
应用程序可以通过 TNSNAME.ORA里面的配置进行负载均衡到不同的DG上。
说实在的MYSQL 分库分表技术难度很高,实现很麻烦,还需要数据库中间件来帮忙解决路由的问题,需要这个分区表是存在哪个库中。而ORACLE 就容易多了。只是数据冗余了些!
一般通过DG 就能很好完成分库分表的工作。20台ORACLE服务器就能跟100台MYSQL服务器一样出色。可以支持中小型电商网站的用户请求量。
关于费用! 基本上很多民营企业使用D版的,而且也没人去查。如果要买正版可以买一个CPU的LINCES 大约20-30万。 至于你日后装在多少台服务器上,它也不那么管。
分库分表是总结了第二章的强拆,也就是ORACLE的分库分表.与MYSQL的分库分表的区别.
从我所了解到的MYSQL分库分表,视野集中在表的身上,把不同的表放在不同的数据库中,这种拆分法跟我的按业务和功能拆分法,基本上类似,不过MYSQL是从下往上看.思维方式有点井底之蛙的感觉。视野集中在性能上,可能无法达到业务和功能上的隔离。
MYSQL拆表法,有两种,一种按字段,常用和不常用分别存在不同表中。另外一种是按某个字段的值,比如user_id=XXX 或者时间字段进行水平拆分。其实这个ORACLE分区技术是一个概念的。当这里有个问题,那就是水平拆分的表,如果放在不同的数据库中,就需要数据库中间件来完成路由工作。光从技术角度来看是无法理解这样的拆分需求的,只有OLQP的大量查询,把查询分别负载到不同的水平数据库中,比如登录的时候根据用户ID分散到不同的数据库中。 比如电商查询不同的商品,电脑和化妆品的查询,就通过水平拆分表的方法,分散到不同的数据库中。每个数据库就保存不同的数据。
把表水平拆分到不同的数据库后,再用MYCAT把请求同时分发到所有的数据库,一起完成工作。然后在MYCAT进行数据合并。这样的操作需求应该是统计类型的,比如说SELECT SUM() FROM USER_ID .需要全表扫描的工作。可表已经拆散了,分布在不同的数据库当中,自然要向全部数据发出命令一起合作完成工作。 这就是典型的OLAP。说白了大家都差不多,只不过MYSQL是从技术角度由下往上进行拆。 而我提的ORACLE分库分表是从业务角度由上而下地分。
如果你做成到了两级分库,那么日后的性能问题就比较单纯了
有朋友质疑20台ORACLE数据库与100台MYSQL数据库 分库分表性能是否一样? 其实这个嘛,主要是MYSQL是硬解析,不得不用机器来拼人力!ORACLE高效的共享池技术极大了降低了硬解析的CPU消耗。你说20台拼不过100台MYSQL服务器。假设同样的配置,同样的应用!
而电商WEB应用最大的是天量查询请求,也就是OLQP。 QPS量大!
QPS可以用多个备库来完成。把大表水平拆分多个分区,也不需要路由MYCAT的了。因为每个备库都有全量的数据,通过TNSNAME.ORA来负载均衡完成。所以实现起来非常简单明了!
物理实现的方式可以多种多样,考虑公司的经济实力而已。重点是要完成两级分库。日后爱咋折腾都方便了,就不用鸟应用开发啥事了。后台DBA根据性能轻松完成,数据库的部署,架构的调整,数据的迁移等等操作。
你看我啰嗦里八嗦的 好几章了! 不过我还是认为重要的事情说三遍!
第四章 三大配置
今天我们将重要的三大配置,分别应用程序端,系统端,数据库端。
因为这三大配置,经常导致性能问题,而且很重要的问题!
第一大配置 应用程序连接池配置
因为ORACLE链接是进程,每来个链接进来的话,ORACLE后台要生成一个服务进程SERVER PROCESS 提供服务,而系统也要有个客户端进程。
而在WEB应用的今天,大量的,而且是频繁的短链接。就是发生一个WEB请求后,需要操作后台数据库,则需要链接一次数据库。查询完了,立马翻脸不认人。下次要的时候,在狗脸乞讨。
这个时候LINUX 系统需要FORK()函数生成一个进程出来,用完后就销毁!
在以前工厂中这种情况也有,只是比较少,无所谓而已。毕竟一个工厂顶多255台链接,大部分都是长链接,而且就是在早上上班的时候发生登录风暴!
可如今WEB天下,动不动就云ERP,从工厂内部,扩展到全球其他工厂,或者支持异地上班,比如说销售人员,在家工作比如说老板。这样的话需要1千个链接。而且每次都是短时间连一下,连完后就丢丢掉!
这样的情况很显然对数据库所在的LINUX服务器来说,鸭梨山大!AIX 和SORILAS,都跑不掉! 你说升级小型机,还是大型机也是给不了多少力的。
不用说云ERP了,就是工行的WEB网银都很累!工行的客户远远多于全球化的工厂用户。
所以就要配置应用链接池!
JAVA 应用有好多链接池可以玩! TOMCAT也有,。。。。
Proxool是一个Java SQL Driver驱动程序,提供了对你选择的其它类型的驱动程序的连接池封装。可以非常简单的移植到现存的代码中。完全可配置。快速,成熟,健壮。可以透明地为你现存的JDBC驱动程序增加连接池功能。
DBCP (Database Connection Pool)是一个依赖Jakarta commons-pool对象池机制的数据库连接池,Tomcat的数据源使用的就是DBCP。目前 DBCP 有两个版本分别是 1.3 和 1.4。1.3 版本对应的是 JDK 1.4-1.5 和 JDBC 3,而1.4 版本对应 JDK 1.6 和 JDBC 4。因此在选择版本的时候要看看你用的是什么 JDK 版本了,功能上倒是没有什么区别。
(主页:http://commons.apache.org/dbcp/)
C3P0是一个开放源代码的JDBC连接池,它在lib目录中与Hibernate一起发布,包括了实现jdbc3和jdbc2扩展规范说明的Connection 和Statement 池的DataSources 对象。
(主页:http://sourceforge.net/projects/c3p0/)
商业中间件连接池 weblogic的连接池 websphere的连接池
NET IIS 容器也有, 小仙就配过。
string cs =
"server=.;uid=sa;pwd=tcaccp;database=pubs;pooling=true;min pool size=5;max pool size=10"
其中 pooling 表示是否打开连接池,默认为打开,关掉时需要 pooling = false;
min pool size 表示连接池最少保存几个连接对象;
max pool size 表示连接池最多保存几个连接对象。(最大值不能为 0,也不能小于最小值)
配置好以后,通过 SqlConnection con = new SqlConnection(cs); 即可得到一个属于连接池的连接对象。在做 ASP.Net 程序时,我们会发现,如果网站20分钟不访问,再次访问就会比较慢,这是因为IIS默认的 idle timeout 是20分钟,如果在20分钟内没有一个访问,IIS 将回收应用程序池,回收应用程序池的结果就相当于应用程序被重启,所有原来的全局变量,session, 物理连接都将清空。回收应用程序池后首次访问,相当于前面我们看到的程序启动后第一次访问数据库,连接的建立时间将比较长。所以如果网站在某些时段访问量很少的话,需要考虑 idle timeout 是否设置合理。
PHP 好像没有现成的连接池可以使用,不过PHP经常和MYSQL搭伙过日子,利用MYSQL的内置连接池功能。
链接池注意要点就是 最大链接数和最小链接数,不要太大的差距。而且不要很频繁地释放链接回操作系统!
目前来说链接池对ORACLE来说,有一项功能没有实现,就是尽可能地把同一条相似的语句,分配在同一个链接上。这样就重复利用了SESSION_CURSOR_CACHE的参数。
第二大配置 系统大页内存。
目前的PC服务器基本上都是4GB以上的64系统。AIX和SUNSOARLAS 基本上配置好了大页内存,而LINUX6系列默认都是小页内存。
关于内存可以参考如下
Linux 64 页表,进程内存,大页
Linux_x86_64BIT内存管理与分布
部分SWAP 内存知识
因为系统存在着程序逻辑内存和真实的物理内存的映射关系,而这个关系需要用部分内存来保存起来。
而且是每个进程都需要一部分内存。内存的多少取决于程序使用的逻辑内存量。
虽然内存映射关系进行了4层以上的映射。不过也抵不住程序使用内存的野心。
最终导致内存表的变态的肥肥!
比如说 你有张100MB的数据库表,经过一年的运行和积累达到了1GB。每个回话,也就是每个链接,有个语句,自然是SQL全表扫描该表的语句,扫描1GB。那么该进程需要1GB逻辑内存地址和物理内存地址映射。
假设下,原来100MB需要1MB内存地址来保存映射关系,现在需要10MB了。
比如说我们现在有1500个数据库连接,加上连接池不重用连接线路的话,1500*10MB=14GB内存保存映射关系表!
有点夸张了! 不过我现在有个11.2.0.1 JAVA开发高级人员,觉得自己很牛鸡巴,自己搭建了ORACLE数据库。
结果连接池也没配,大页内存也没有配。 大约230个应用程序连接数,占了3.2GB的映射表(内存表) 系统总共才32GB 。
默认情况下LINUX是4K内存页大小的。 也就是说3.2GB除以4KB,大约有多少个页。我就不算,你可以算算看! 这么多页,CPU需要把它掉入到CPU寄存器中。所以CPU处理这活的话,累死了!
而LINUX 可以开启2MB的大页内存。这样的话CPU也轻松了,页表大小也少了。
第三大配置 数据库内存自动分配!
只从ORACLE开始人性化来,从ORACLE 9I开始,到目前的ORACLE 12C。基本上免除了大家辛苦,而有细致调整各个功能池的大小。现在12C自动完成。
最小分配单位是64MB。
这样的人性化工作,非常适合JAVA开发人员了使用,以前需要专职DBA来完成的工作,现在要么JAVA开发人员搞,要么运维工程师来搞。基本上连上网,照着网络配置下,启动了图形界面后就一路向西去了!
终于不需要DBA了,老子天下第一! 十八武艺样样精通!
很显然做为专业DBA来说,这话就咽不下去了! 那也没办法,咽下去,等你的数据库慢了后,再高价请我吧!! 哈哈。
专业DBA 一来 就PASS掉自动内存调整参数。
设置PGA多少,SGA多少。
SGA 中 DB_CACHE多少, SHARD_POOL多少,LARGE_pool多少,JAVA_POOL,STREAM_POOL多少。剩下的就交给SGA自动调整吧!
具体调多少,要参考上图 OLTP,OLQP,OLAP类型! 单机还是RAC
一般来说OLAP 需要大大的DB_CACHE。 而OLTP SHARD_POOL 就要很多,起码要跟DB_CACHE平分秋色。RAC当中的SHARD_POOL要超过DB_CACHE。
至于PGA+SGA 在整个内存的分配,一般参考80%系统内存! OLTP SGA>PGA 而OLAP PGA=SGA。
另外 数据库系统内存除了装监控代理比如说ZABBIX AGENT 外,禁止装其他应用程序!
比如说OEM或者说EM!
第四配置! 超线程
一般我是禁用掉超线程的。 超线程在PC BIOS 里面禁止。
为什么呢?
因为超线程,不是真的CPU内核,是利用CPU暂时空闲时间,虚拟的内核。
也就是在CPU空闲当中。利用它的空闲做其他的事情。而且当主活回来后,再还给它! 这里面涉及到了上下文切换。切换就需要时间,内存调度嘛!本来主活的数据保留在寄存器,一级缓存,二级缓存,乃至内存中。这下好了,被超线程给赶跑了,再把数据调回来就麻烦了。
所以超线程适合计算类型的应用。至于数据库嘛!大家都懂的,密集型IO操作!