声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
Non-Parallel Sequence-to-Sequence Voice Conversion with Disentangled Linguistic and Speaker Representations
本文章是中国科学技术大学语音与语言信息处理国家工程实验室2019.12.13号更新的文章,主要的工作是做使用非并行数据做声音转换,具体链接为
https://arxiv.org/pdf/1906.10508.pdf
demo链接
https://jxzhanggg.github.io/nonparaSeq2seqVC/
(今天更新有点晚,最近试验太多,而且效果没达到预期的话感觉很急躁。最近也感觉有点疲惫,每次醒来都比以前晚半个钟头。涉及voice conversion这篇文章是研究vc的网友推荐,而且对解答我的疑惑,在此十分感谢)
1 研究背景
现有的声音转换(voice conversion)的解决方案主要分为:基于parallel data (转换双方的音频内容一样)和non-parallel data。其中non-parallel data的方案更有研究价值,一方面不需要parallel data,获取训练数据更容易。另一方面应用价值更高,灵活性更好,比如实现跨语言的转换。其中non-parallel data的方案比较常用的方法就是对训练的音频进行linguistic information和 speaker information进行解耦,然后组合解耦的信息。这里借用李宏毅老师的PPT内容更直观。其中进行语音信息提取的content encoder,很多方案使用单独训练的ASR来提取特征(PPG or Bottleneck feature),但该方案的效果受到ASR的影响。本文提出了一种基于seq2seq的声音转换方案,该方案的content encoder部分是和整个系统联合训练,实验证明该方案完胜voice conversion challenge 2018。


2 详细设计
文章讲述的很细,我在这里只讲解大概。该系统的训练和转换阶段如图1所示,其中(a)训练有text encoder 从文本中获取语言信息表征,recognition encoder从音频中提取语音信息表征,speaker encoder从音频中提取speaker信息,其中语音信息和说话者信息之间存在说话者判别,该部分对语音信息和说话者信息进行解耦。seq2seq decoder根据语音信息和说话者信息进行声学特征的合成。推理阶段则如(b)所示,只要输入音频即可。整个系统的结构如图2所示,其中图中的每部分的loss公式如公式1到公式7。另外本文提出训练分为两个阶段:预训练和微调。预训练是在大量数据上进行模型训练,微调步骤是在预训练模型基础上对要转换的目标接着训练,其中预训练的算法如算法1所示。(在此感谢网友解答,刚开始看图2中的text-to-speech decoder和auto-encoding decoder存在迷惑,后来明白,偶数进行text-to-speech,奇数进行auto-encoding decoder,使用同一个seq2seq decoder)


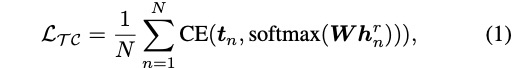







3 实验
本文实验的系统参数配置如table 1所示。本文的实验很多,先对比客观实验,然后主观对比,最后对系统的每个部分进行分别验证。对比的系统包括parallel data 的DNN, seq2seqVC和non-parallel 的cycleGAN, VCC2018以及本文系统。其中对比数据女性slt和男性rms。

首先看一下tabel 2的客观指标对比,男性和女性之间的对比,本文的提出的方案最接近parallel的seq2seqvc,但好于VC2018。其中主观的MOS评测也表现同样的结果(table 3)。
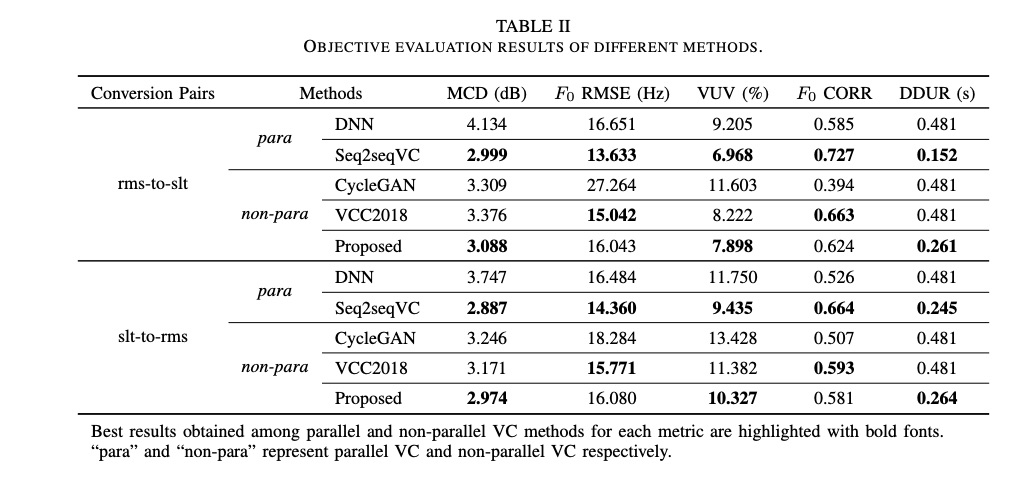
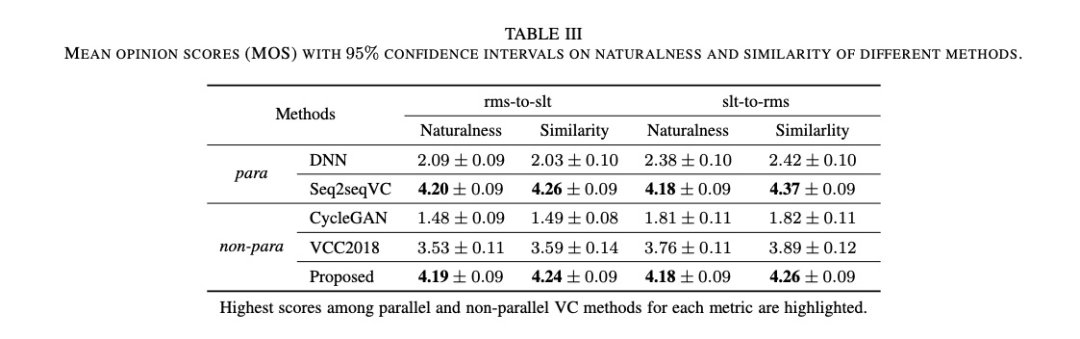
图3显示speaker embedding信息,可以看出同一个说话人的数据聚集,而且男女性分开。图4展示linguistic information,可以看出从recognition encoder 和text encoder内容重叠,gap比较低。


接下来,比较使用数据量多少对VC的影响,结果图table4显示,其中table5展示与vcc2018进行ab test,本文使用100句远好于vcc2018。table 6对比多人之间的声音转换。



最后分析本文的每部分的效果,结果如table 7所示,删掉的模块都造成效果降低。图6和图7显示去掉lct和text input的话,结果不在像图4聚集的那么好。




4 总结
本文提出了一种基于seq2seq的声音转换方案,该方案语言特征抽取,说话人信息抽取和整个系统是联合训练,实验证明该方案完胜voice conversion challenge 2018。