Hadoop入门(八)——本地运行模式+完全分布模式案例详解,实现WordCount和集群分发脚本xsync快速配置环境变量 (图文详解步骤2021)
系列文章传送门
Hadoop入门(一)——CentOS7下载+VM上安装(手动分区)图文步骤详解(2021)
Hadoop入门(二)——VMware虚拟网络设置+Windows10的IP地址配置+CentOS静态IP设置(图文详解步骤2021)
Hadoop入门(三)——XSHELL7远程访问工具+XFTP7文件传输(图文步骤详解2021)
Hadoop入门(四)——模板虚拟机环境准备(图文步骤详解2021)
Hadoop入门(五)——Hadoop集群搭建-克隆三台虚拟机(图文步骤详解2021)
Hadoop入门(六)——JDK安装(图文步骤详解2021)
Hadoop入门(七)——Hadoop安装(图文详解步骤2021)
Hadoop入门(八)——本地运行模式+完全分布模式案例详解,实现WordCount和集群分发脚本xsync快速配置环境变量 (图文详解步骤2021)
Hadoop入门(九)——SSH免密登录 配置(图文详解步骤2021)
文章目录
Hadoop 运行模式
1)Hadoop 官方网站:http://hadoop.apache.org/

2)Hadoop 运行模式包括: 本地模式、 伪分布式模式以及 完全分布式模式。
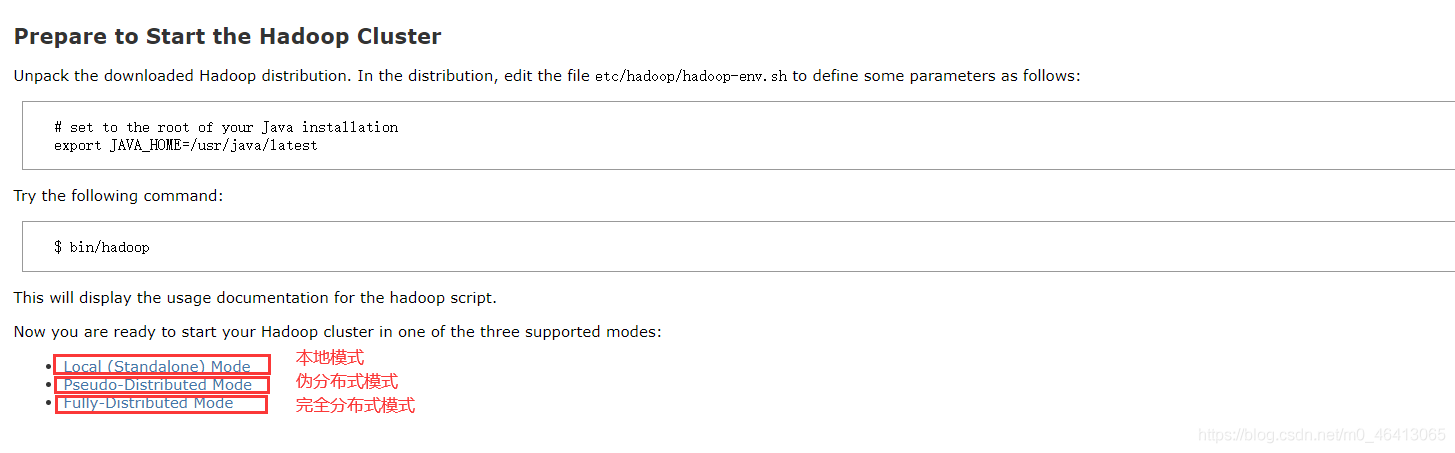
- 本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。
- 伪分布式模式:也是单机运行,但是具备 Hadoop 集群的所有功能,一台服务器模
拟一个分布式的环境。个别缺钱的公司用来测试,生产环境不用。 - 完全分布式模式:多台服务器组成分布式环境。生产环境使用。

本地运行模式 (官方 WordCount案例 )
1 ) 创建在 hadoop-3.1.3 文件下面创建一个 wcinput 文件夹
[leokadia@hadoop102 hadoop-3.1.3]$ mkdir wcinput
2 ) 在 wcinput 文件下创建一个 word.txt 文件
[leokadia@hadoop102 hadoop-3.1.3]$ cd wcinput
3 ) 编辑 word.txt 文件
[leokadia@hadoop102 wcinput]$ vim word.txt
➢ 在文件中随便输入一些内容
➢ 保存退出::wq

4 ) 回到 Hadoop 目录/opt/module/hadoop-3.1.3
[leokadia@hadoop102 ~]$ cd /opt/module/hadoop-3.1.3
5 ) 执行程序
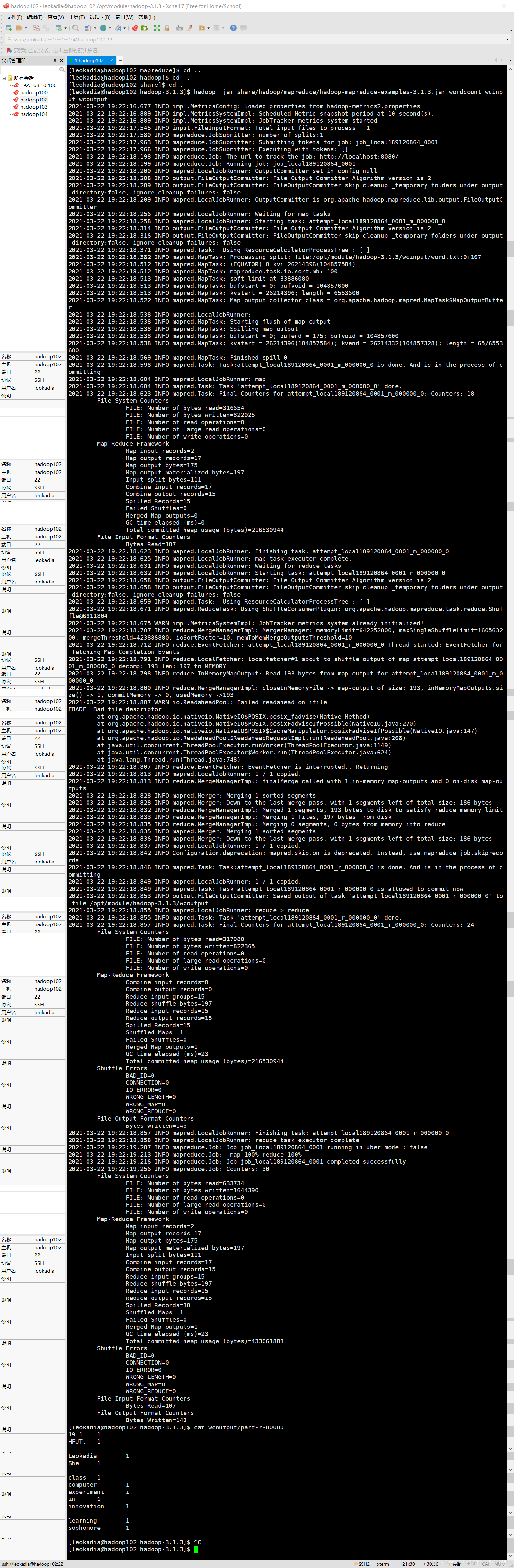
[leokadia@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput
当然,你要是不确定,不放心自己的程序中是否有hadoop-mapreduce-examples-3.1.3.jar,你可以依次进入文件夹查看,博主就做过这种事情。
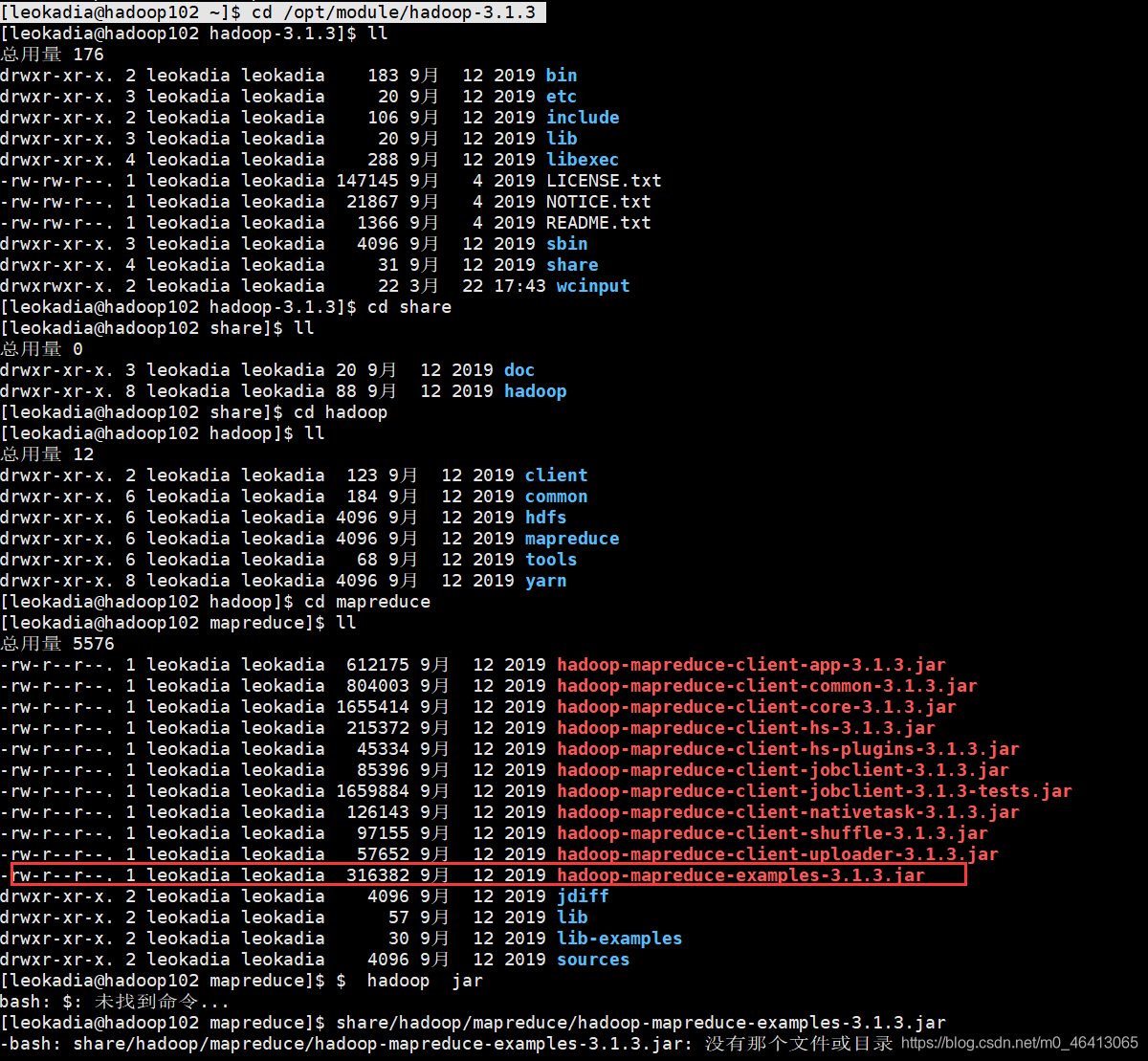
6 ) 查看结果
[leokadia@hadoop102 hadoop-3.1.3]$ cat wcoutput/part-r-00000
看到如下结果:
19-1 1
HFUT, 1
Hadoop 1
Leokadia 1
She 1
a 1
class 1
computer 1
experiment 1
in 1
innovation 1
is 3
learning 1
sophomore 1
whose 1
完全分布式 运行模式 (重点)
分析:
1)准备 3 台客户机(关闭防火墙、静态 IP、主机名称)
2)安装 JDK
3)配置环境变量
4)安装 Hadoop
5)配置环境变量
注,以上步骤我们均在hadoop102上搞定了
6)配置集群
7)单点启动
8)配置 ssh
9)群起并测试集群
步骤1,2,3,4,5之前我们均已经在102上搞定了
虚拟机准备
详见前几篇文章
编写集群分发脚本 xsync
1 )scp (secure copy ) 安全 拷贝
(1)scp 定义
scp 可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
(2)基本语法

(3)案例实操
前提:在 hadoop102、hadoop103、hadoop104 都已经创建好的/opt/module、
/opt/software 两个目录,并且已经把这两个目录修改为 leokadia:leokadia
[leokadia@hadoop102 ~]$sudo chown leokadia:leokadia -R /opt/module
注:前面完全按我来的这部分不需要做,之前103,104克隆的时候就存在了
(a)在 hadoop102 上,将 hadoop102 中/opt/module/jdk1.8.0_212 目录拷贝到hadoop103 上。
[leokadia@hadoop102 ~]$ scp -r /opt/module/jdk1.8.0_212 leokadia@hadoop103:/opt/module

输入yes
然后输入hadoop103的密码:
然后就开始拷贝了,经历一大串类似这样的
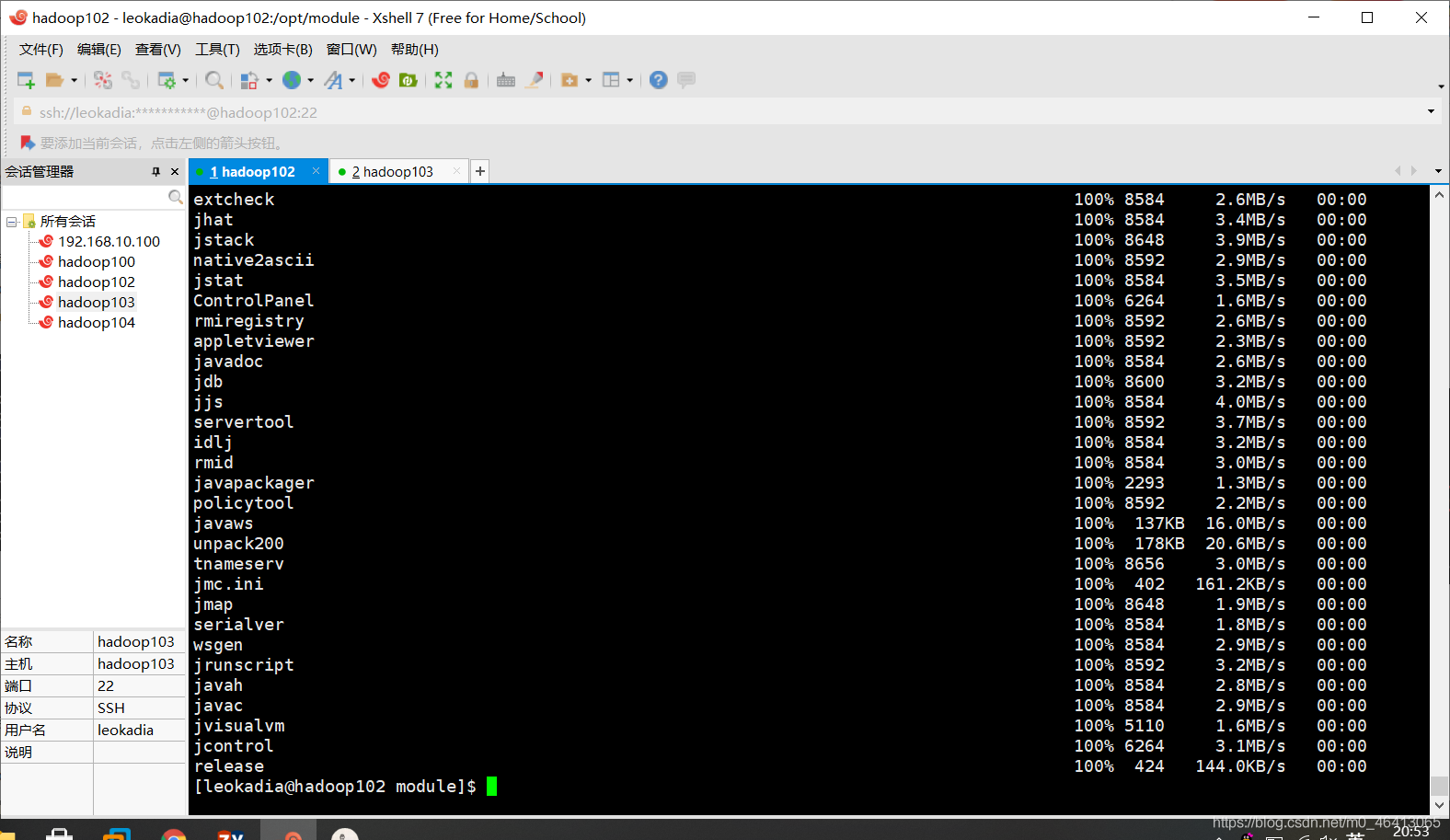
在hadoop103上即可看到jdk拷贝成功

刚刚我们的一通操作是将在 hadoop102 上,将 hadoop102 中/opt/module/jdk1.8.0_212 目录拷贝到hadoop103 上。简单点说就是把hadoop102上的东西强行塞给hadoop103。那能不能在hadoop103上将hadoop102的东西强行拿过来呢?下面拷贝hadoop-3.1.3的时候我们就试试这种方法。
(b)在 hadoop103 上,将 hadoop102 中/opt/module/hadoop-3.1.3 目录拷贝到hadoop103 上。
[leokadia@hadoop103 ~]$ scp -r leokadia@hadoop102:/opt/module/hadoop-3.1.3 /opt/module/

可以看到拷贝成功
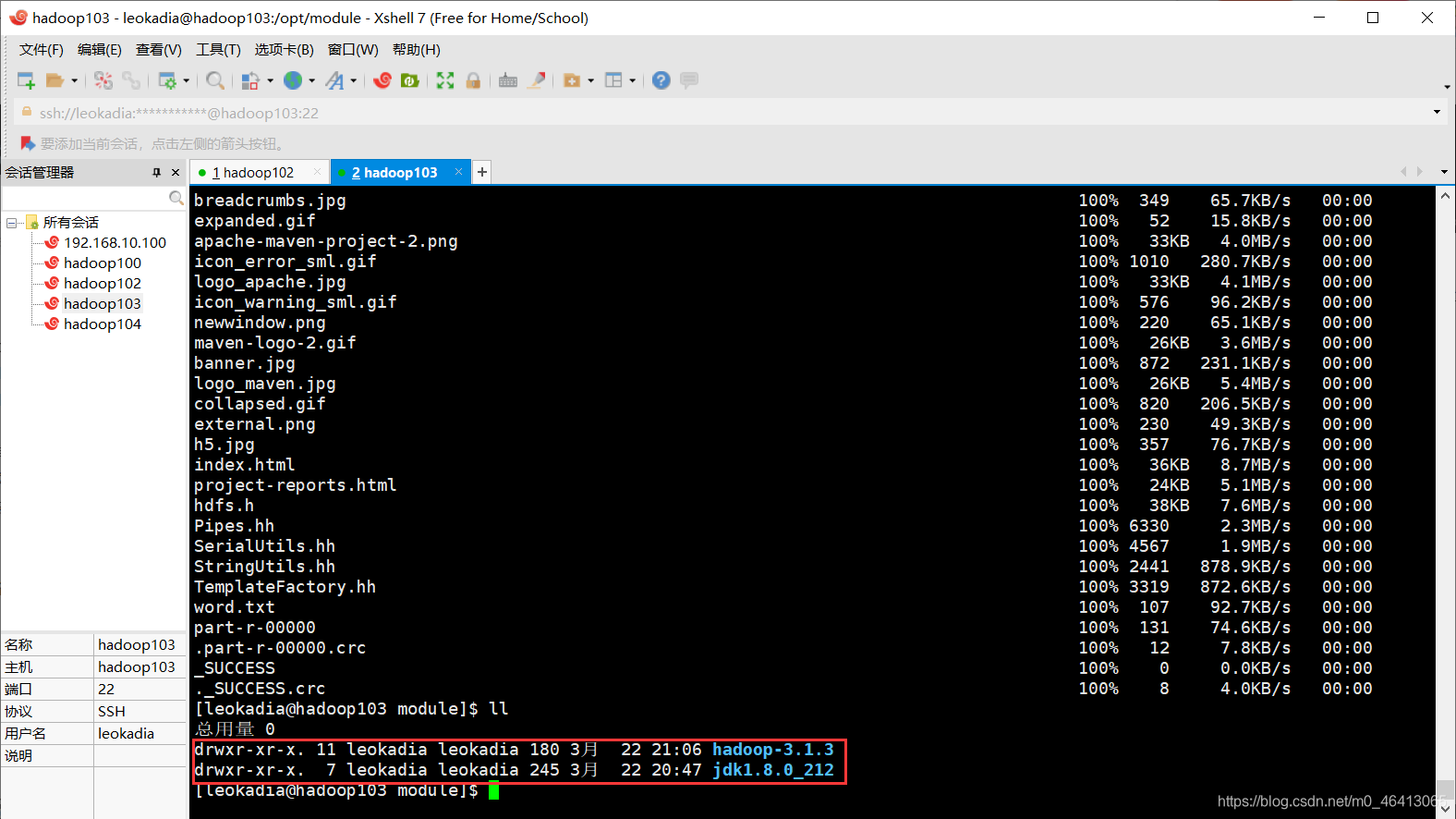
其实不仅可以把hadoop102上的东西强行塞给hadoop103
在hadoop103上将hadoop102的东西强行拿过来
还可以用在 hadoop103 上操作,将 hadoop102 的东西塞给hadoop104
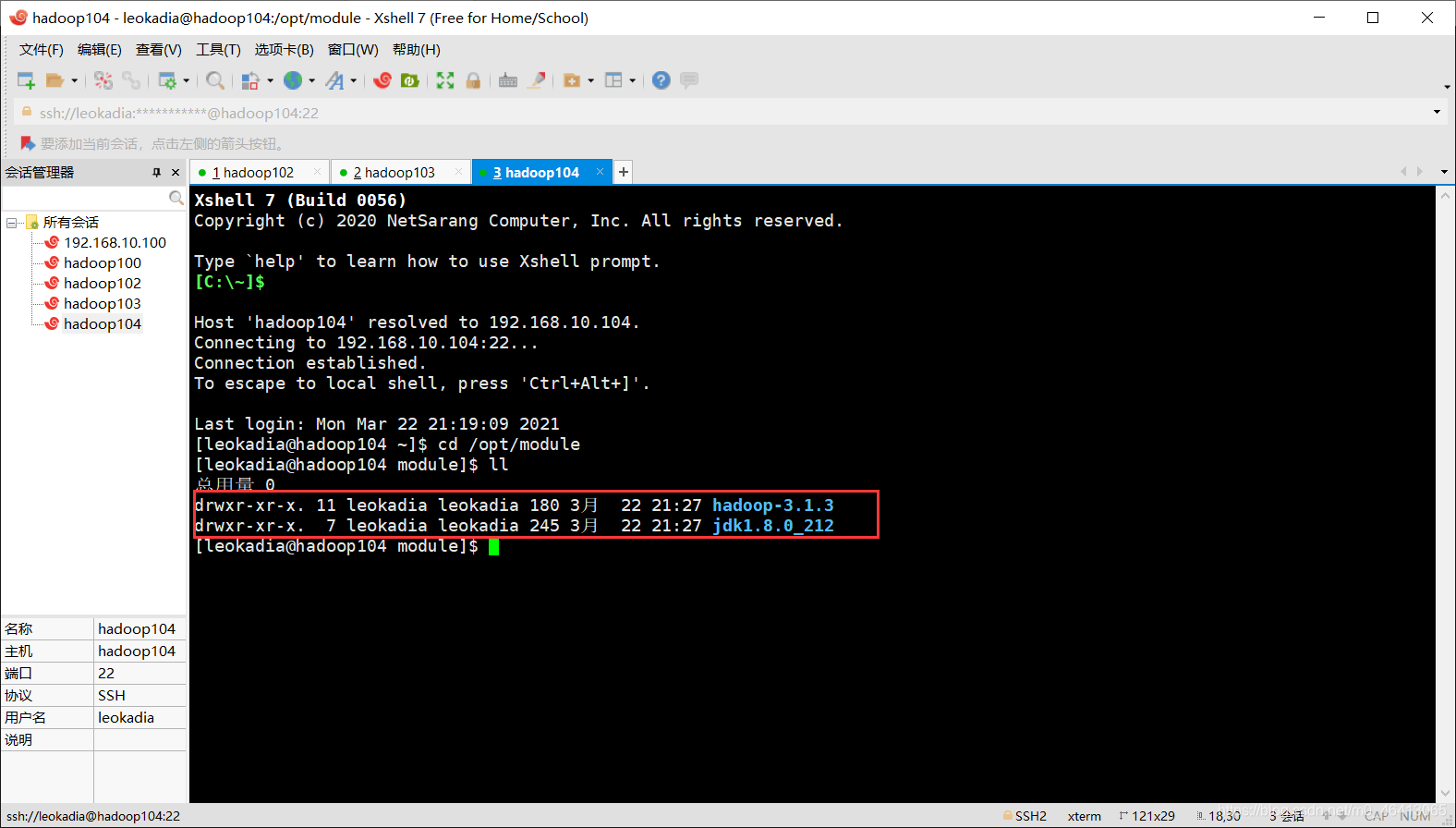
(c)在 hadoop103 上操作,将 hadoop102 中/opt/module 目录下所有目录拷贝到hadoop104 上。
[leokadia@hadoop103 opt]$ scp -r leokadia@hadoop102:/opt/module/* leokadia@hadoop104:/opt/module
过程同理

然后他会让你输入hadoop104的密码,输入后即可拷贝成功

不放心的话可以在hadoop104中验证一下
题外话——小Tip
由于博主之前为每台运行虚拟机预留的主机RAM( R )比较大
(不要喷,博主电脑是在转计算机之前瞎买的,比较垃圾)
因此同时开启三台虚拟机的时候,他会报出这样的错误:物理内存不足,无法使用配置的设置开启虚拟机
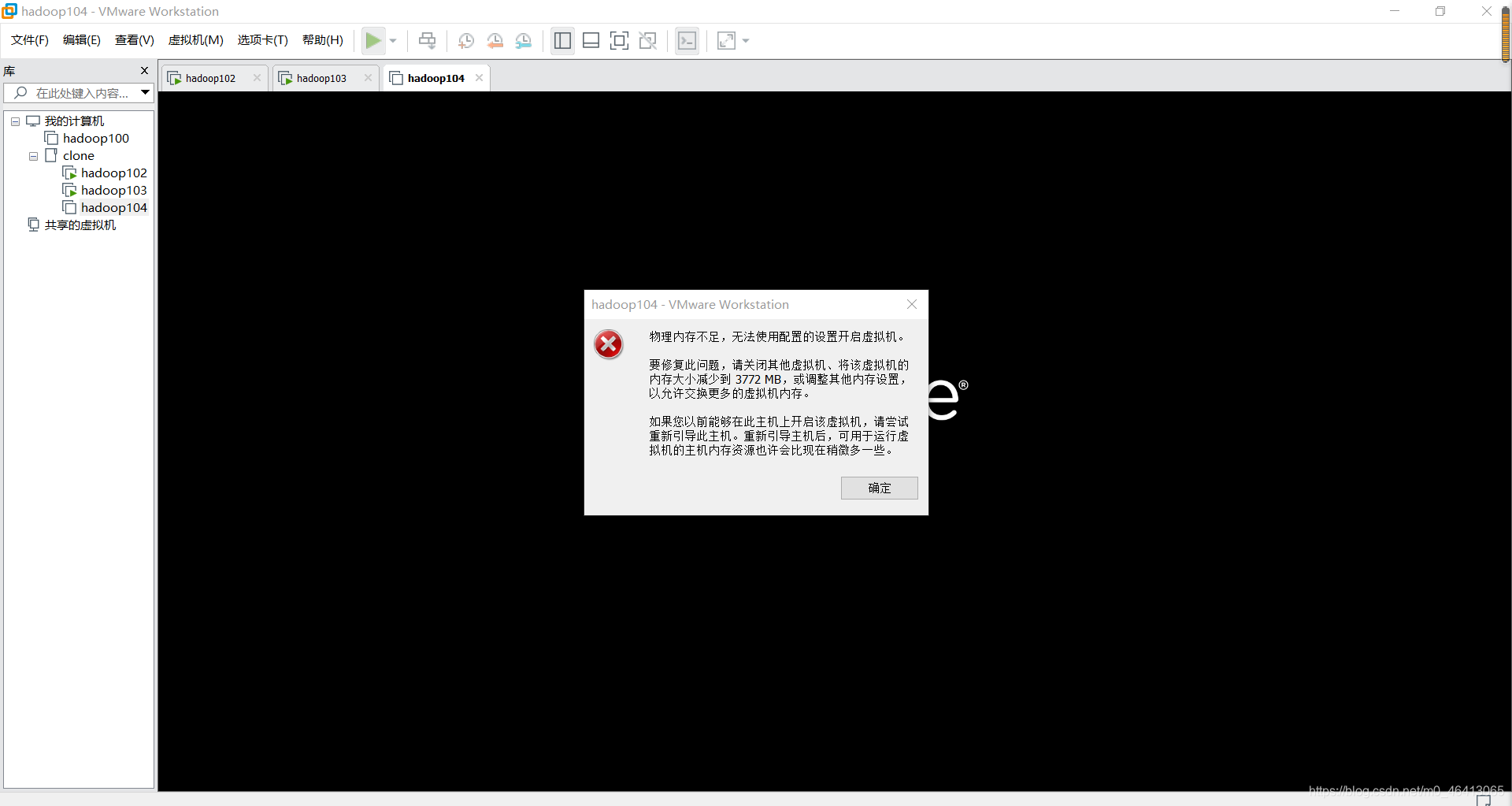
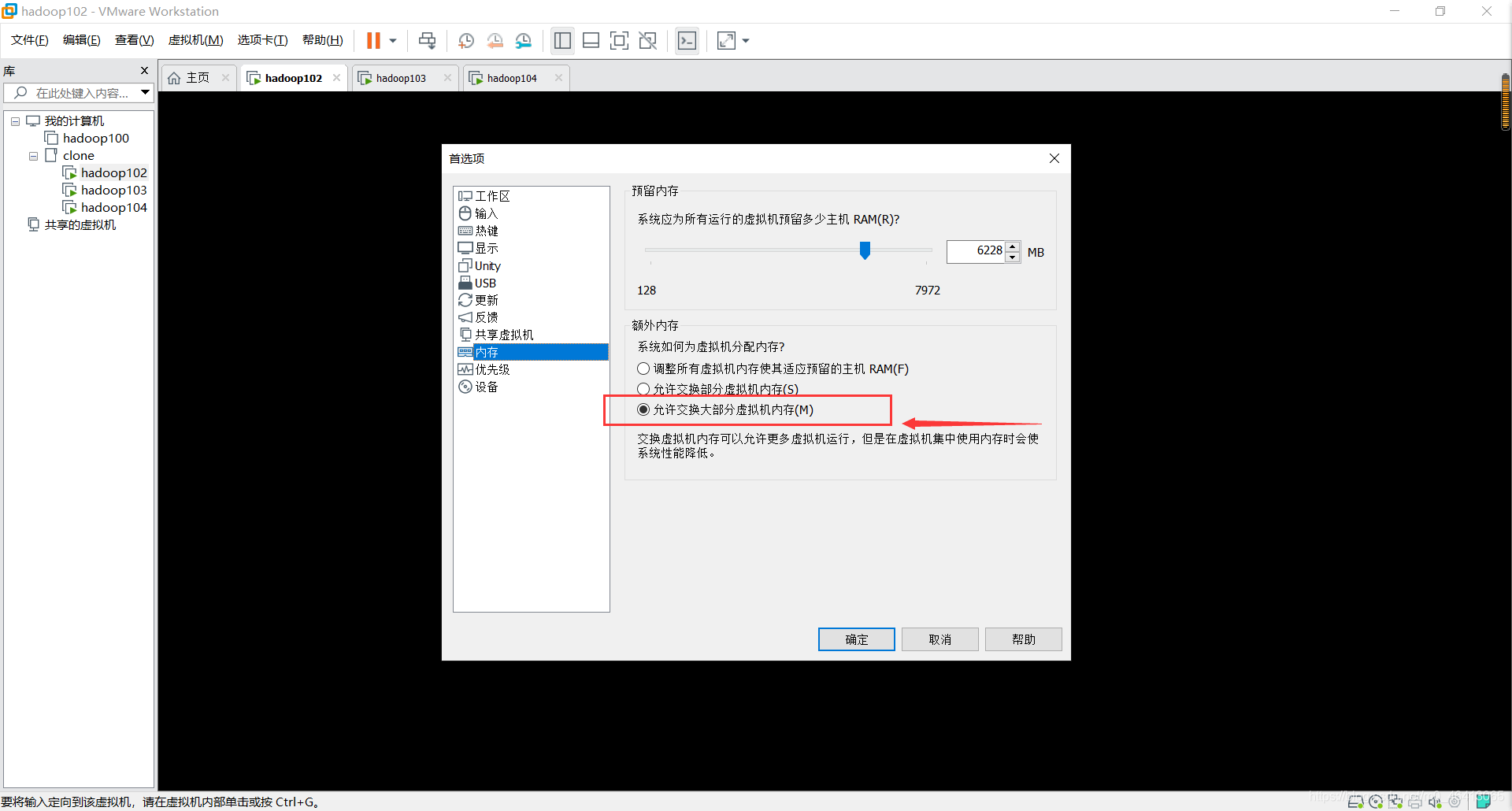
博主寻找过许多解决办法,最终找到一个最方便(智障)的方法供大家参考:
点击“编辑”———“首选项”,在弹出的对话框中选择左侧的“内存”,然后在最右侧选择“允许交换大部分虚拟机内存”即可,如下图所示
2 )rsync 远程同步工具
rsync 主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync 和 scp 区别:用 rsync 做文件的复制要比 scp 的速度快,rsync 只对差异文件做更
新。scp 是把所有文件都复制过去。
(1)基本语法
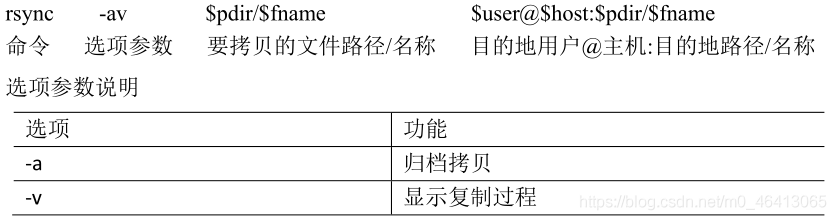
(2)案例实操
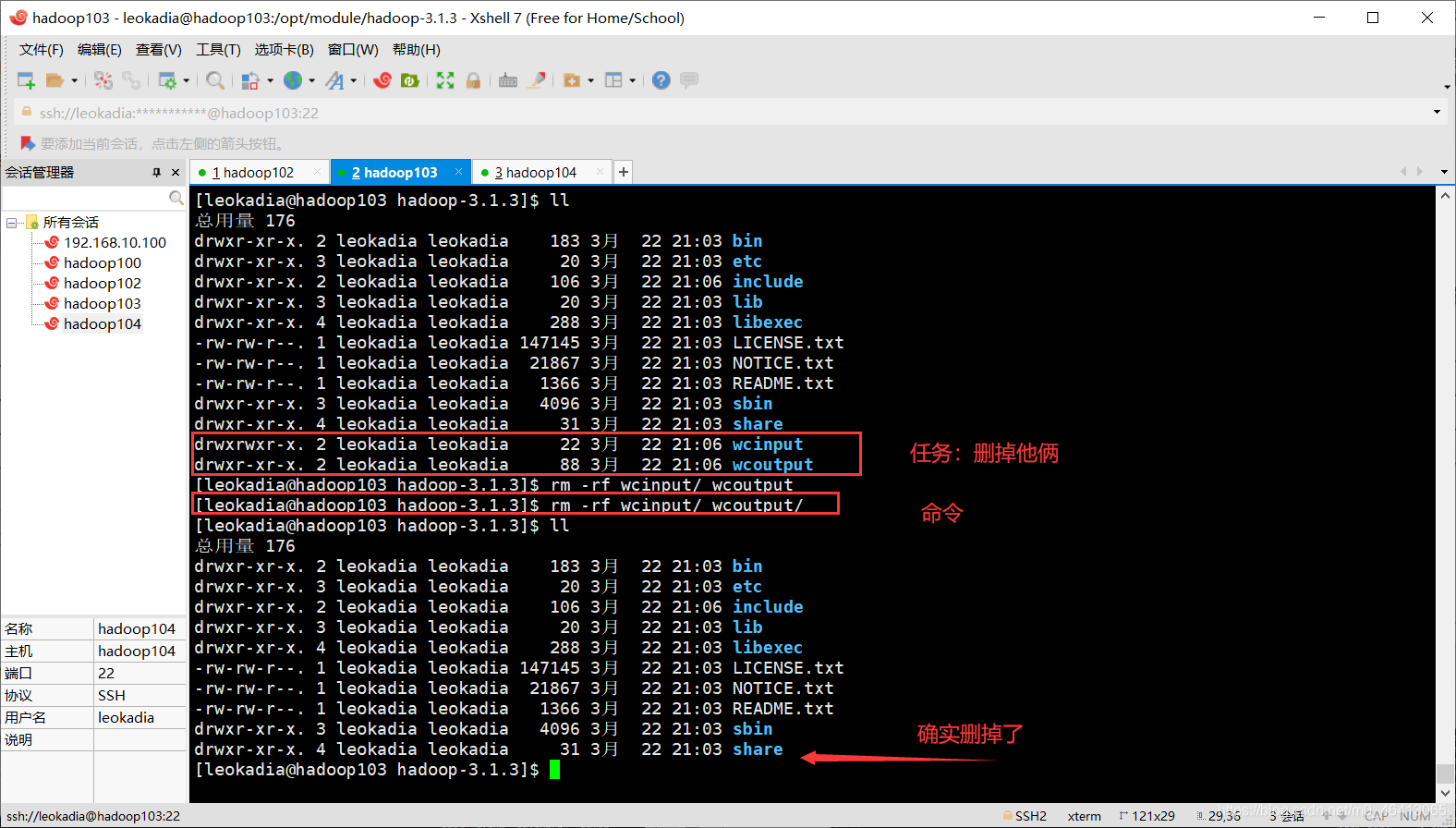
(a)删除 hadoop103 中/opt/module/hadoop-3.1.3/wcinput
[leokadia@hadoop103 hadoop-3.1.3]$ rm -rf wcinput/
(b)同步 hadoop102 中的/opt/module/hadoop-3.1.3 到 hadoop103
希望将 hadoop102 中的hadoop-3.1.3 到 hadoop103
看是所有的内容都拷贝,还是只拷贝差异性内容
[leokadia@hadoop102 module]$ rsync -av hadoop-3.1.3/ leokadia@hadoop103:/opt/module/hadoop-3.1.3/
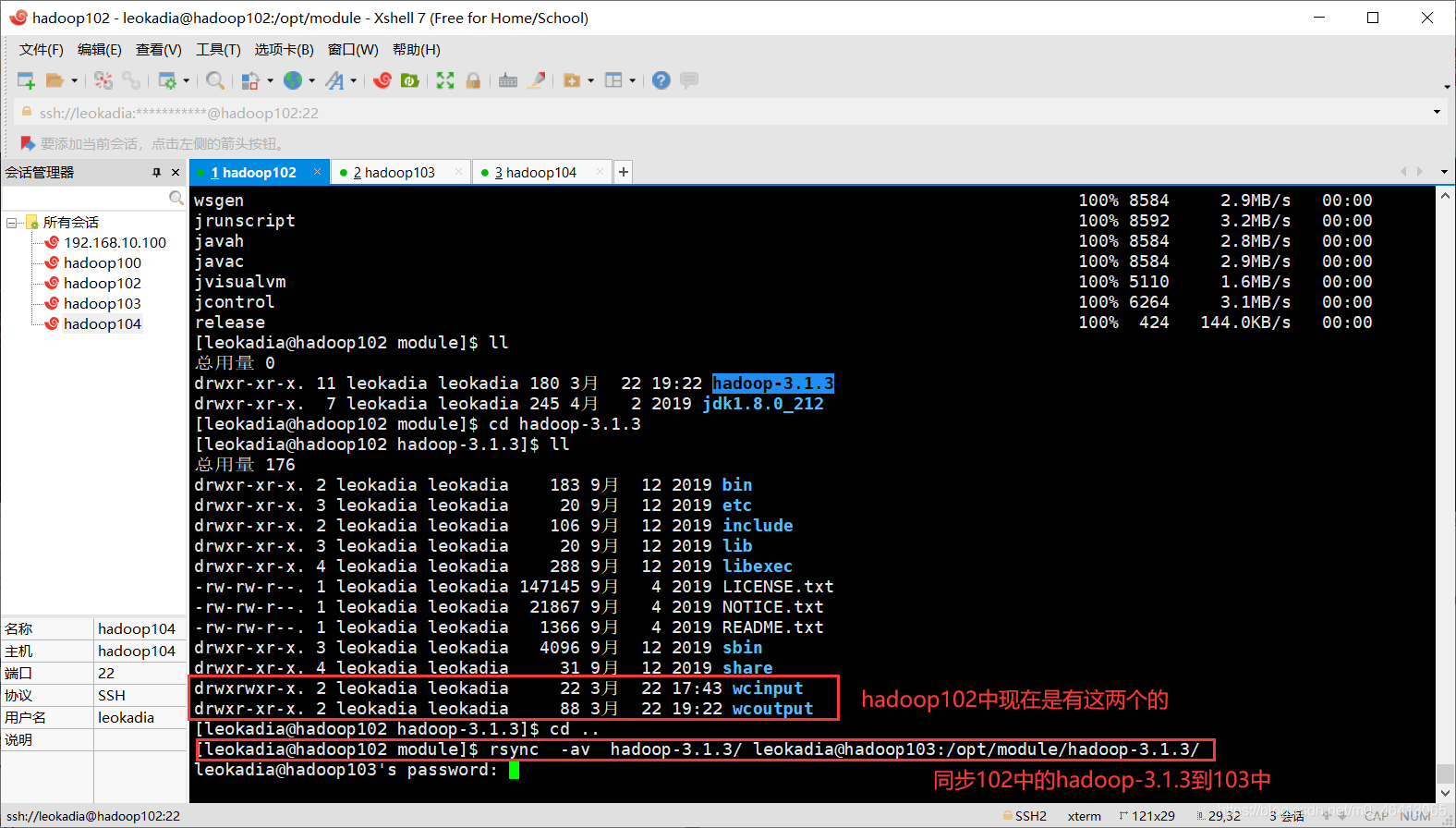
同步完成

在hadoop103中验证:同步成功

3 )xsync 集群分发 脚本
(1)需求:循环复制文件到所有节点的相同目录下
在家目录下创建一个文件,希望写一个脚本,一执行这个命令,a.txt就可以分发到相同的路径
(2)需求分析:
(a)rsync 命令原始拷贝:
rsync -av /opt/module leokadia@hadoop103:/opt/
(b)期望脚本:
xsync 要同步的文件名称
(c)期望脚本在任何路径都能使用(脚本放在声明了全局环境变量的路径)
[leokadia@hadoop102 ~]$ echo $PATH 查看 全局环境变量的路径
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/home/leokadia/.local/bin:/home/leokadia/bin
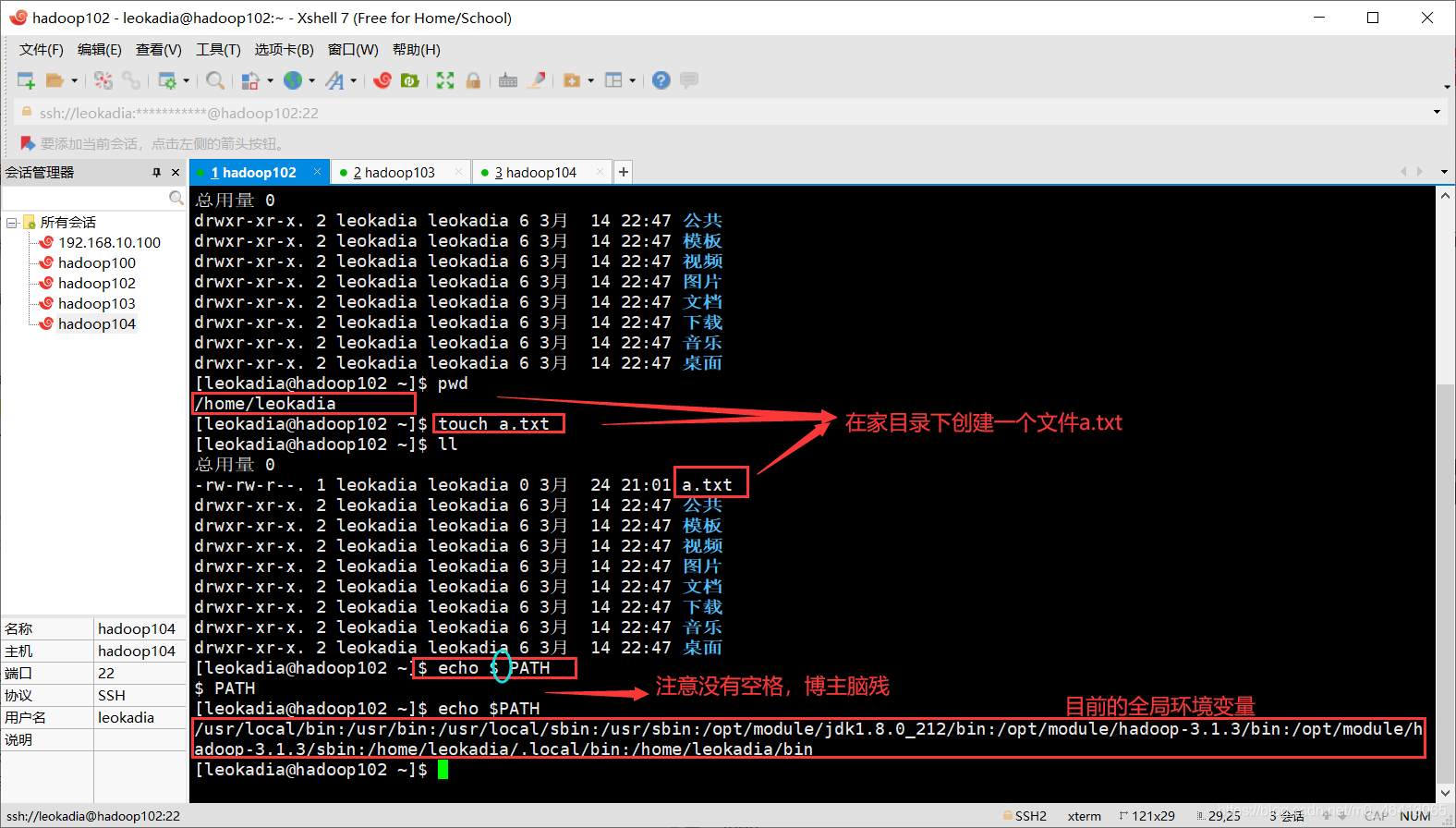
想在/home/leokadia/bin目录下将xsync 集群分发 脚本 放入,即可在全局使用这个脚本了
(其实也可以在家目录下创建这个脚本,在把这个脚本的路径放入全局变量环境)
(3)脚本实现
(a)在/home/leokadia/bin 目录下创建 xsync 文件
[leokadia@hadoop102 opt]$ cd /home/leokadia
[leokadia@hadoop102 ~]$ mkdir bin
[leokadia@hadoop102 ~]$ cd bin
[leokadia@hadoop102 bin]$ vim xsync
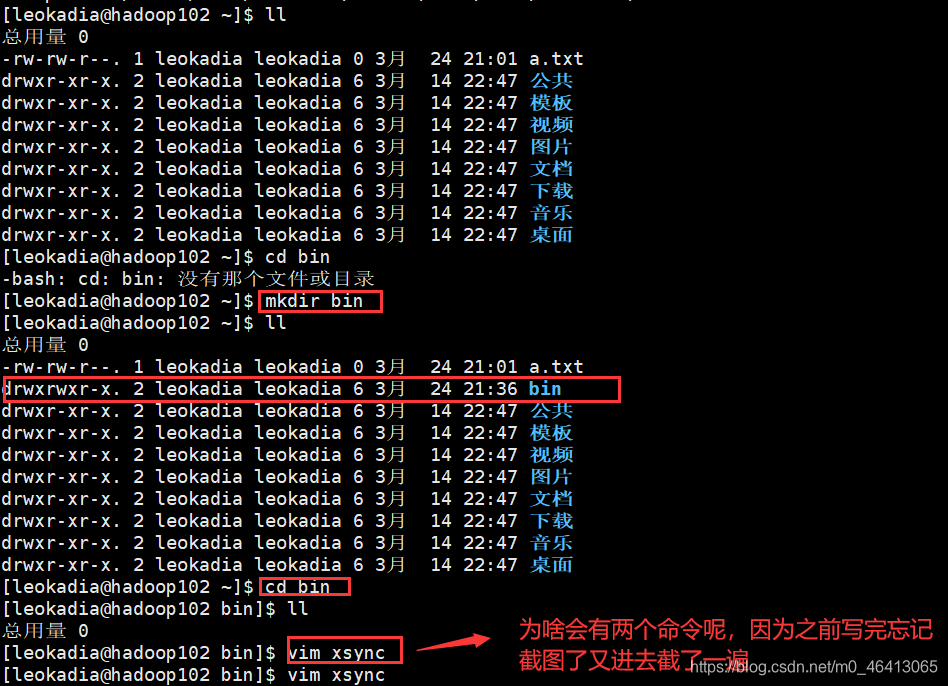
在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
# 判断参数是否小于1
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
# 对102,103,104都进行分发
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
# 如果不存在
else
echo $file does not exists!
fi
done
done
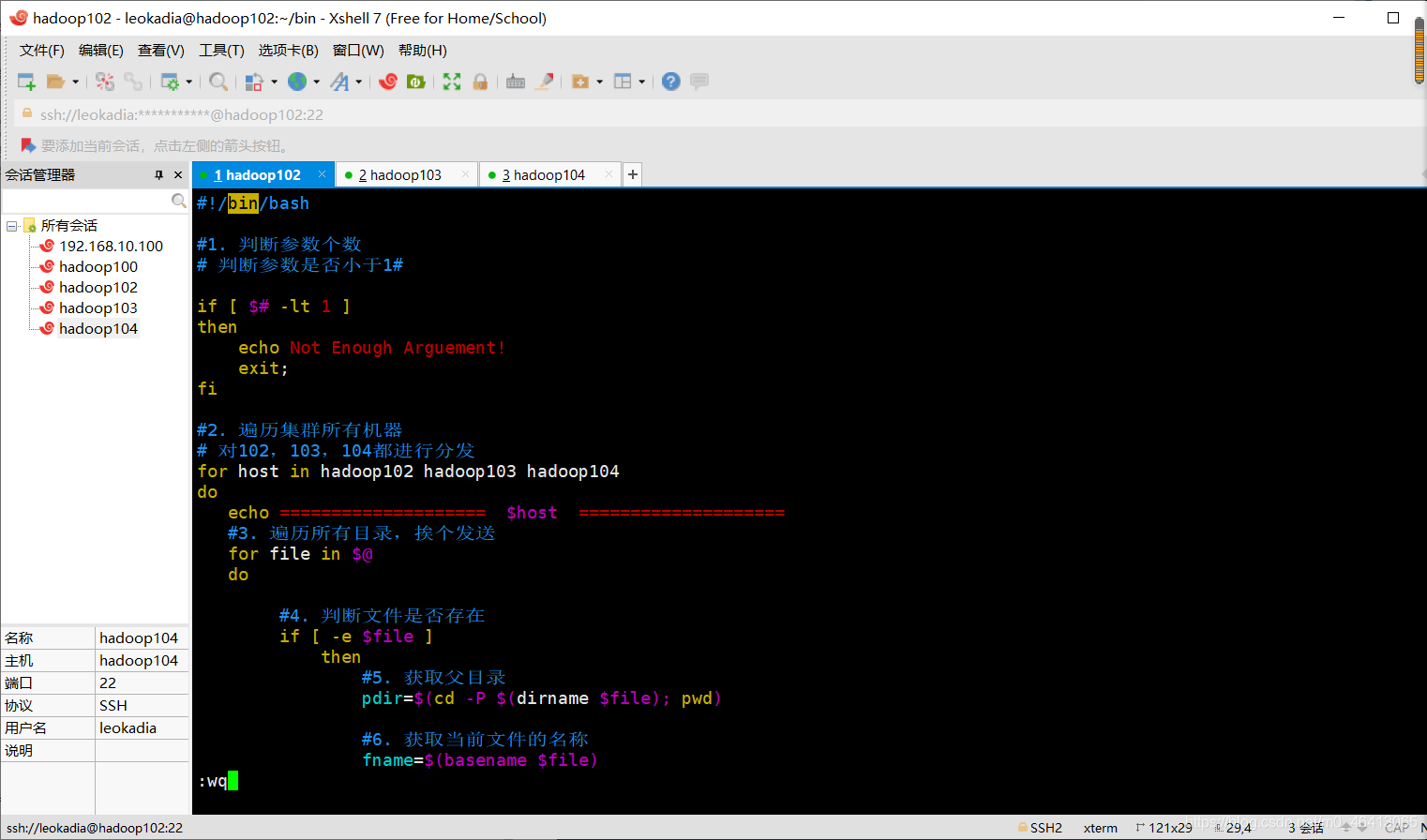
(b)修改脚本 xsync 具有执行权限
[leokadia@hadoop102 bin]$ chmod +x xsync
(c)测试脚本
[leokadia@hadoop102 ~]$ xsync /home/leokadia/bin

连输几次密码
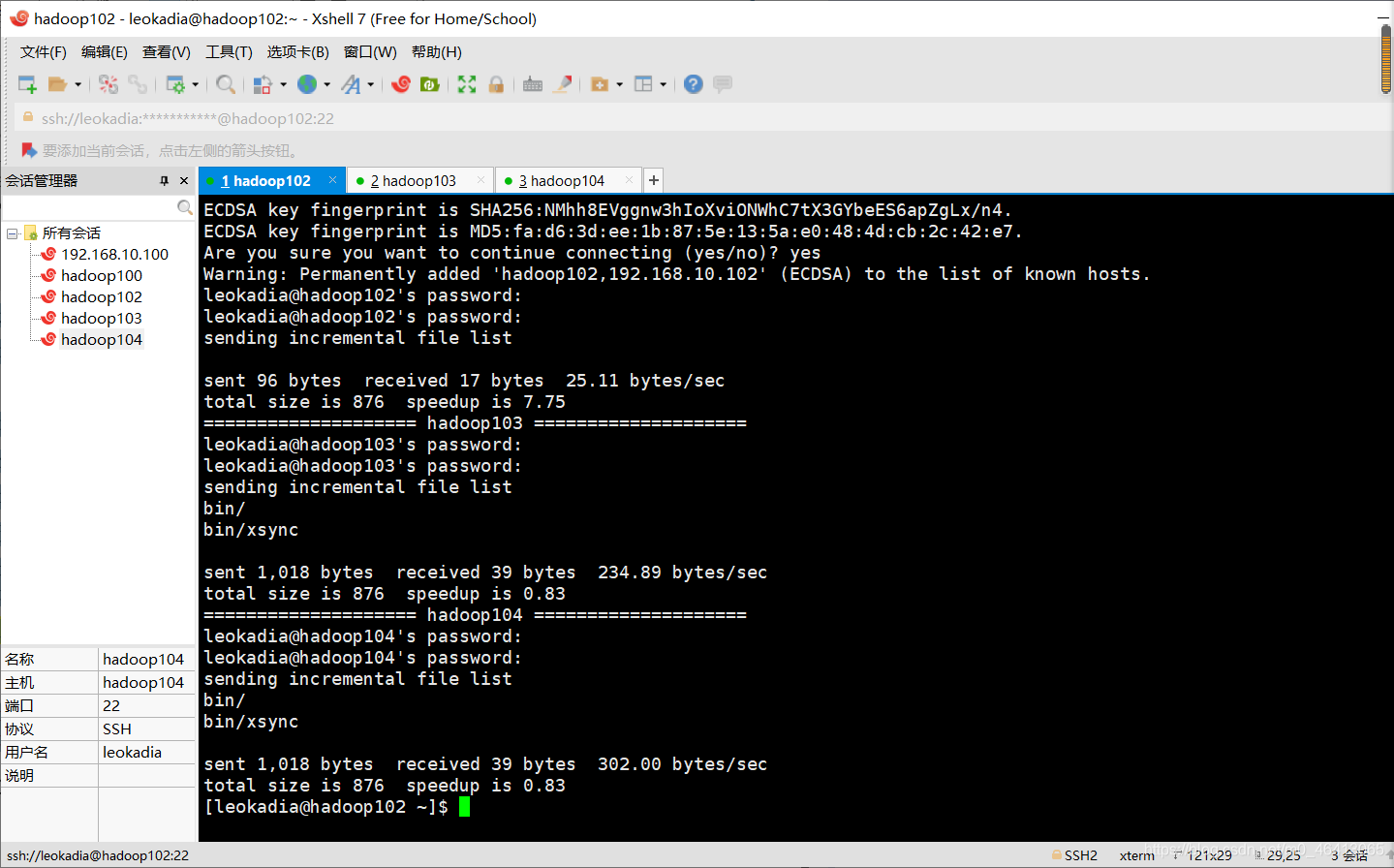
在hadoop103,hadoop104上验证,发现脚本传输成功
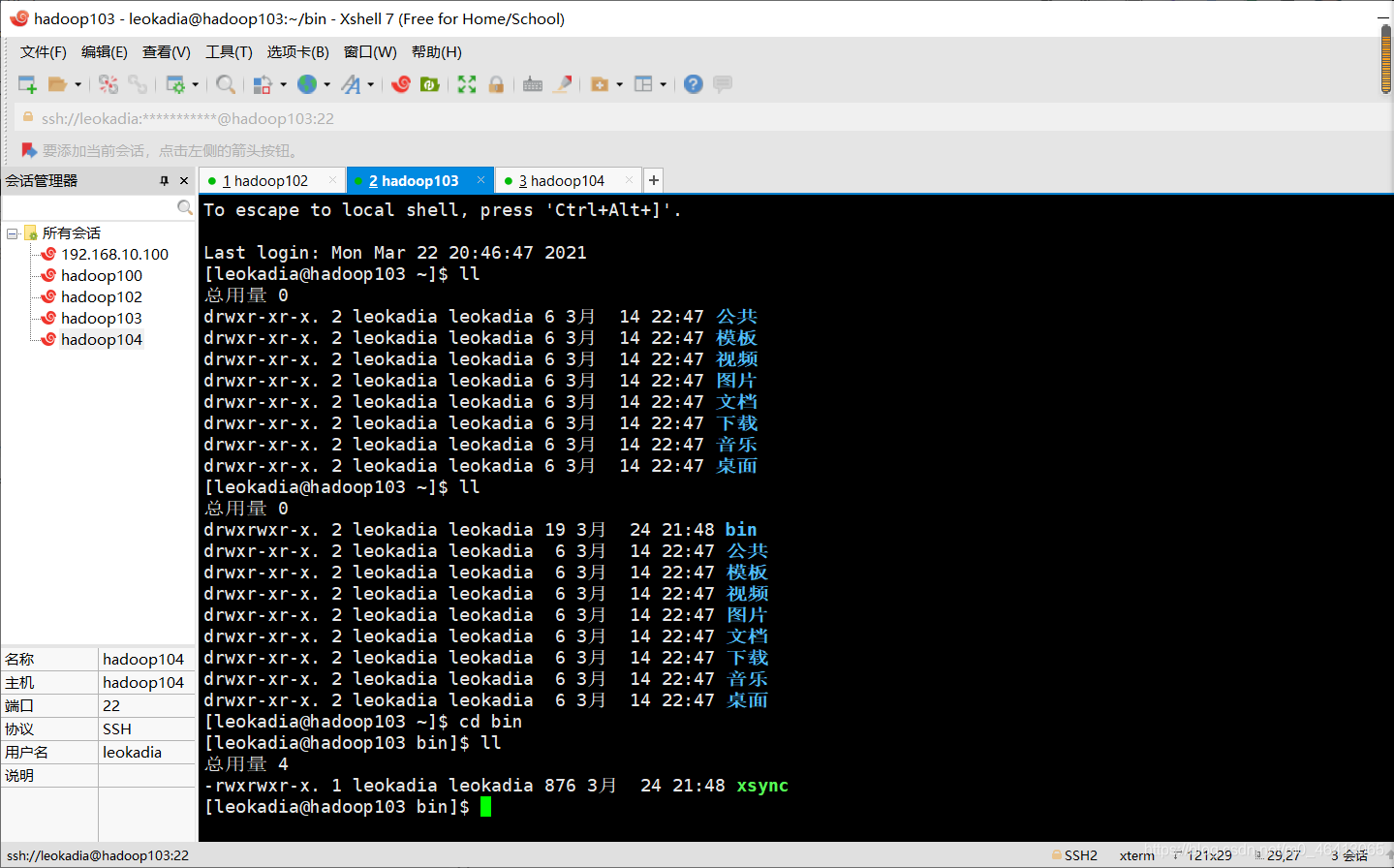
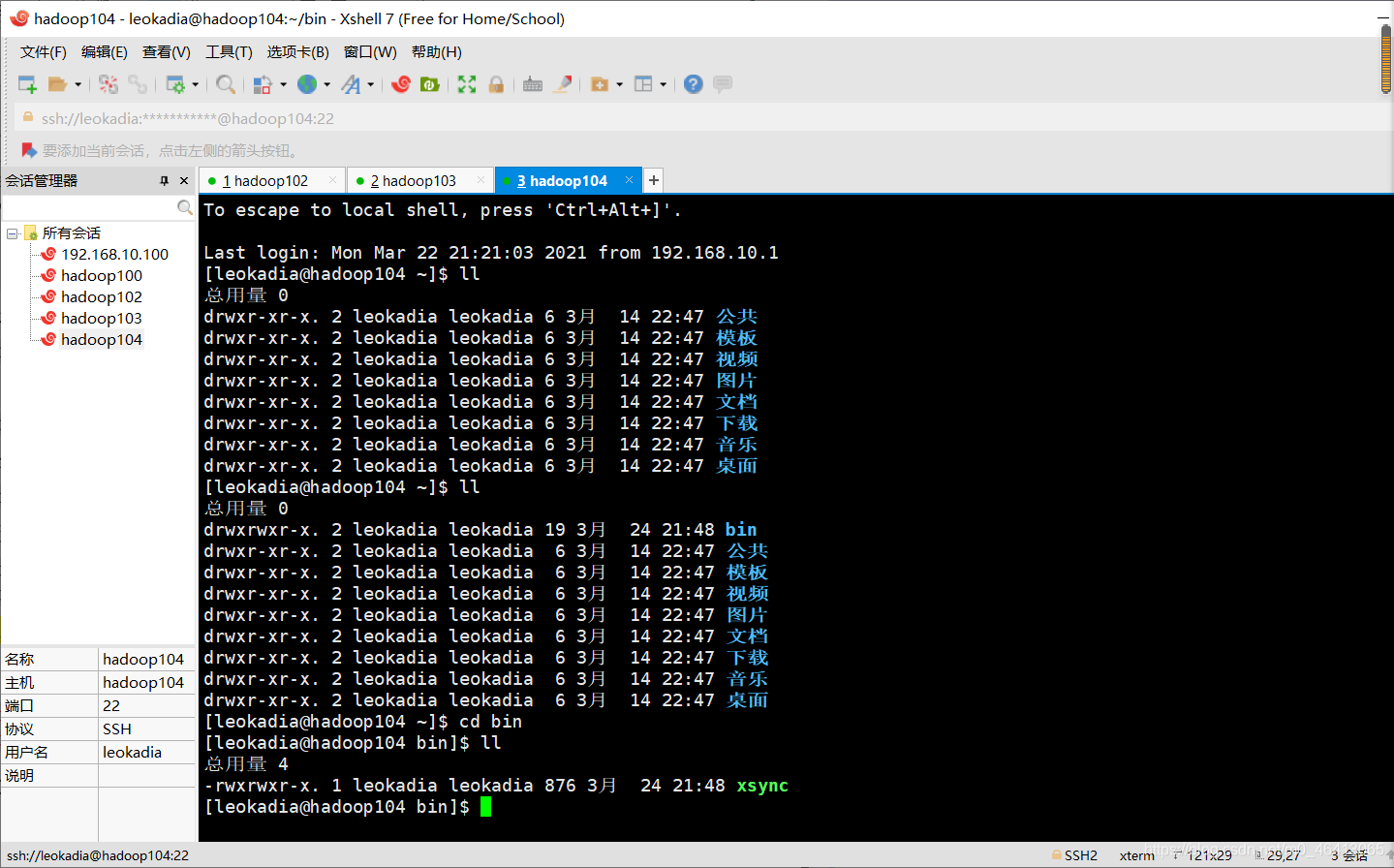
(d)将脚本复制到/bin 中,以便全局调用
[leokadia@hadoop102 bin]$ sudo cp xsync /bin/
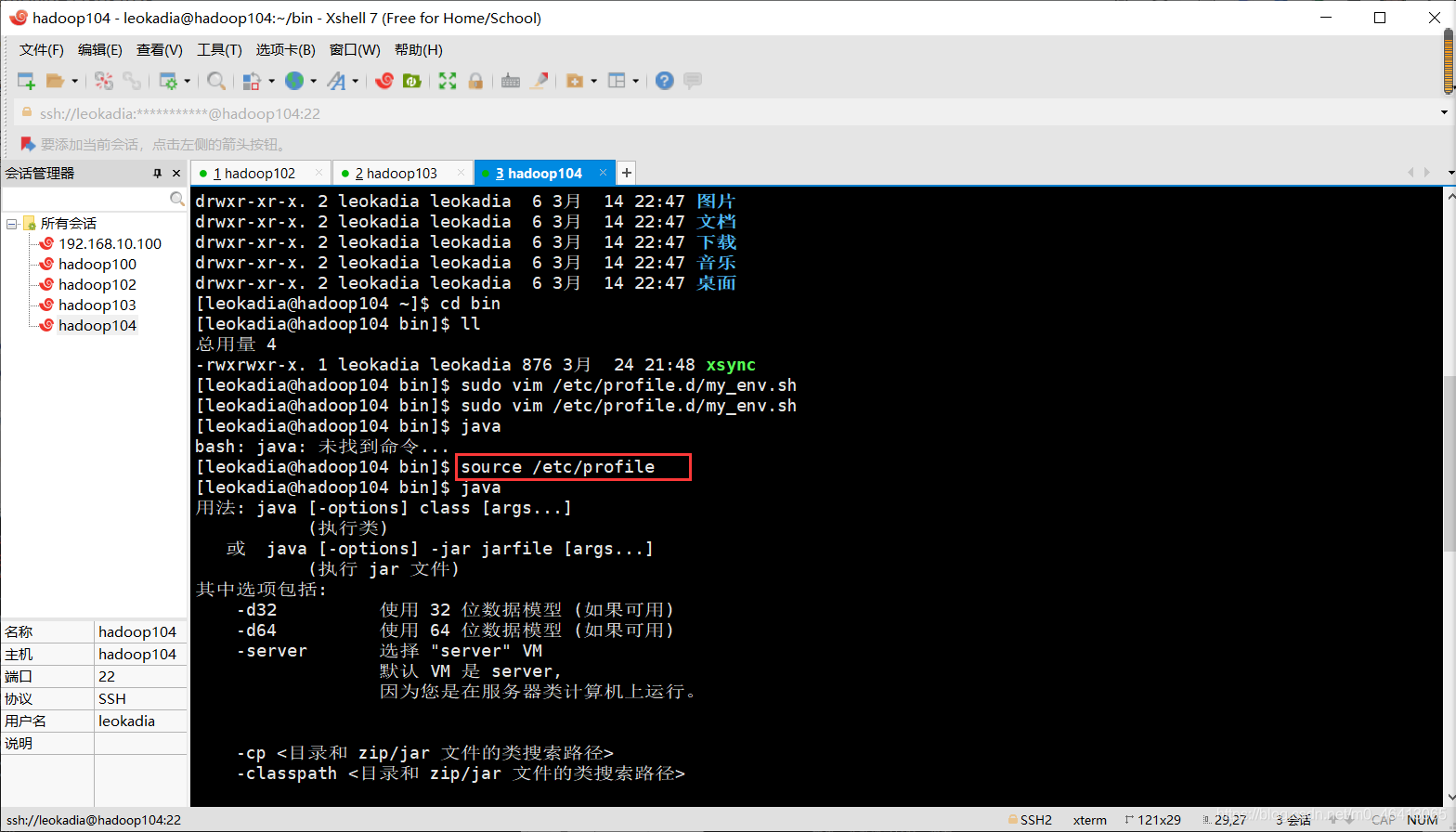
还记得之前我们hadoop103,hadoop104都没有配置hadoop和jdk的环境变量吗?
看下hadoop104目前的环境变量里的情况

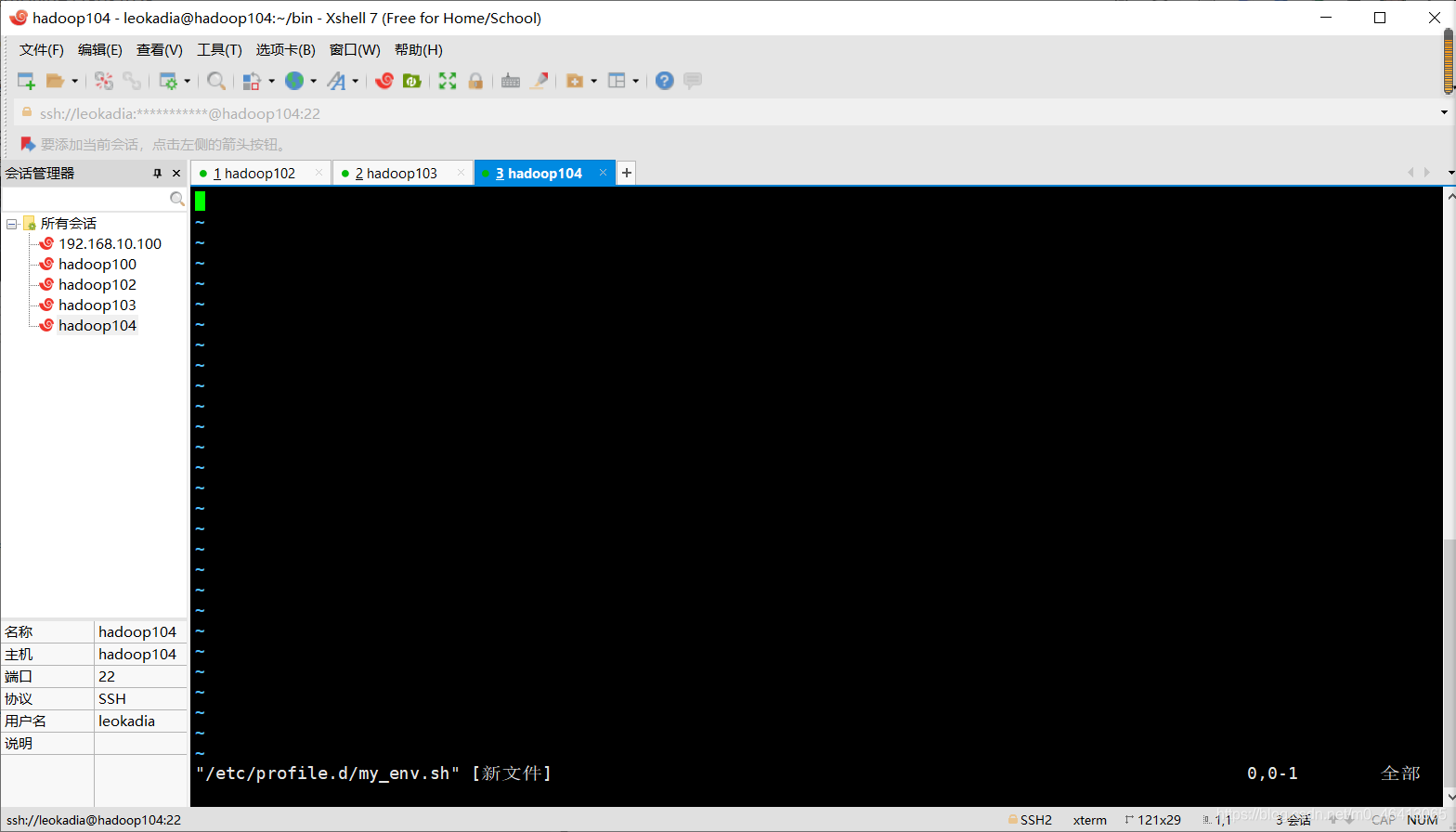
发现确实没有配置
这个脚本的用处来了!
我们用这个脚本分发环境变量
(e)同步环境变量配置(root 所有者)
我们先用这条命令试一下:
[leokadia@hadoop102 ~]$ xsync /etc/profile.d/my_env.sh
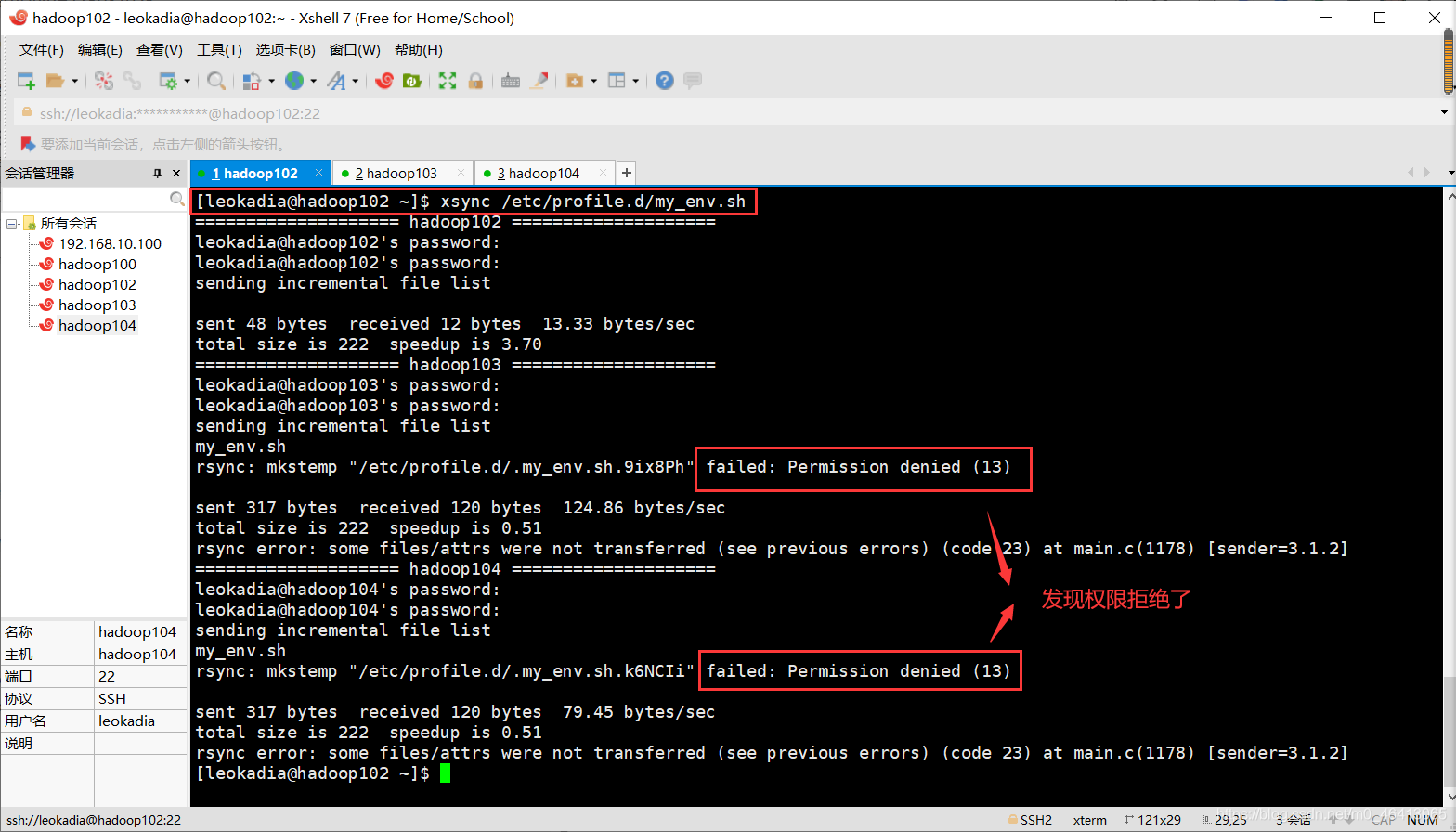
查看hadoop103/104中的,发现根本没有my_env.sh文件
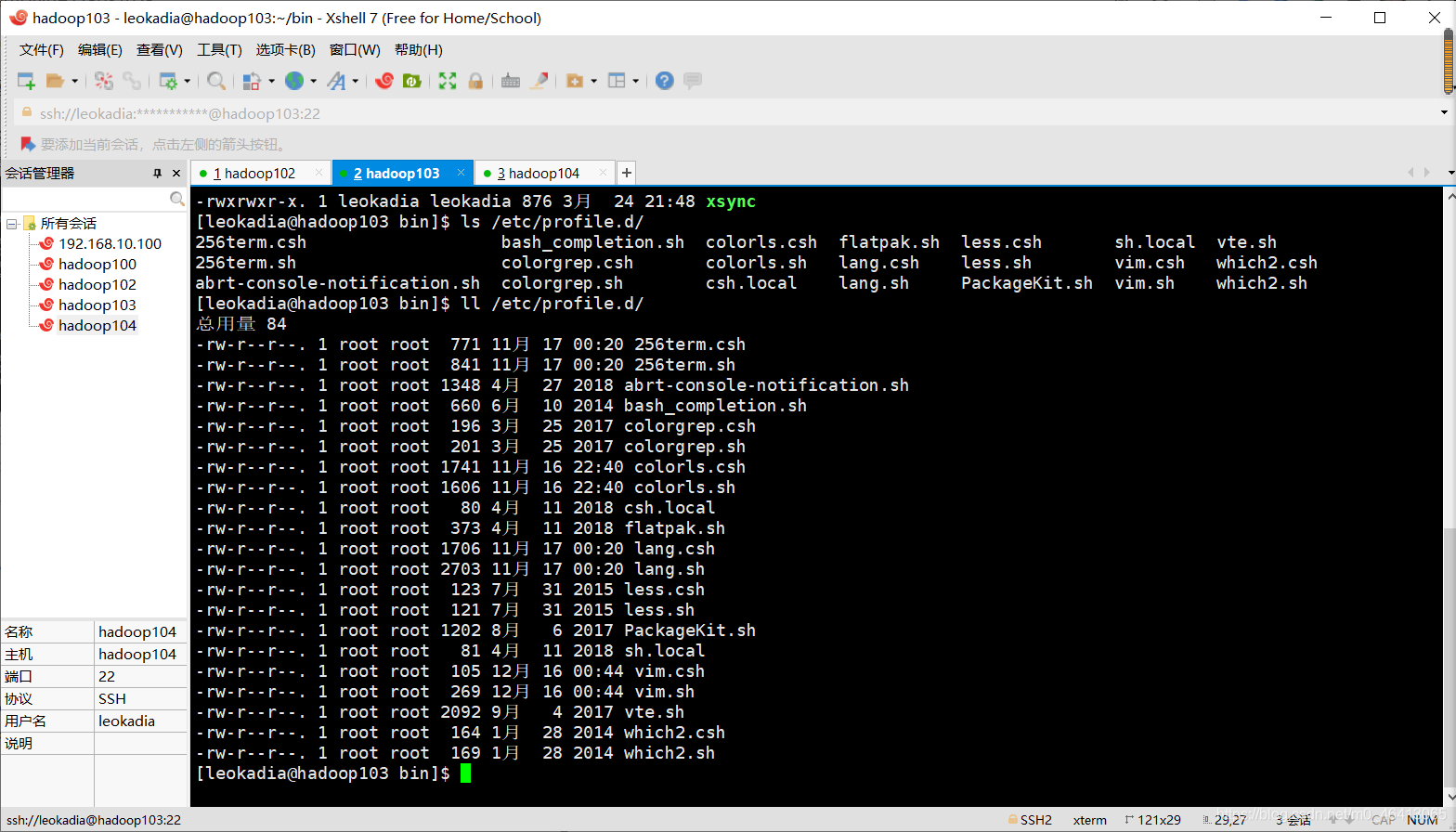
那我们加sudo试一下,发现根本找不到命令

为啥呢?
我加了sudo相当于我是root用户,但目前我现在脚本在家目录bin目录下,root账号使用不了这个路径。
那我们就加上这个绝对路径呗!
这次一定成!
[leokadia@hadoop102 ~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh
注意:如果用了 sudo,那么 xsync 一定要给它的路径补全。
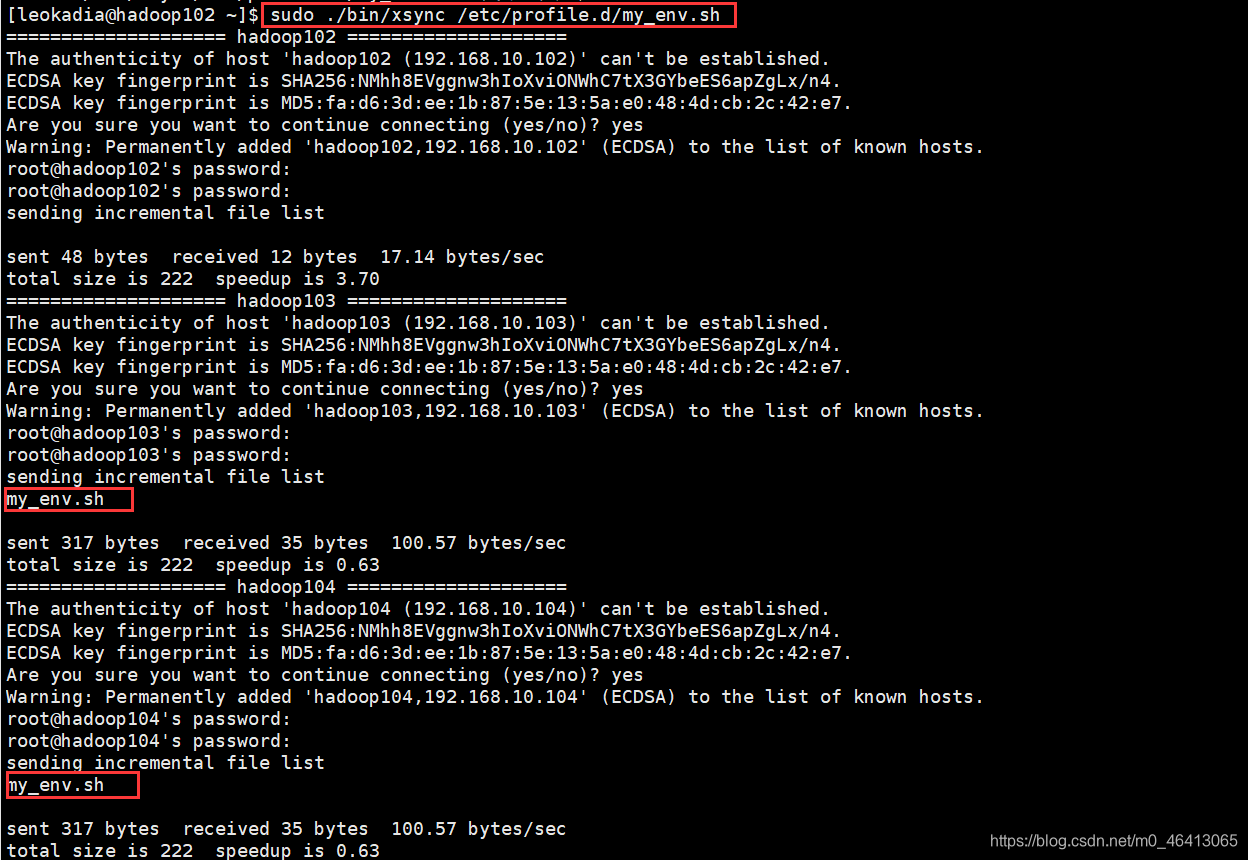
在hadoop103,hadoop104下验证一下:
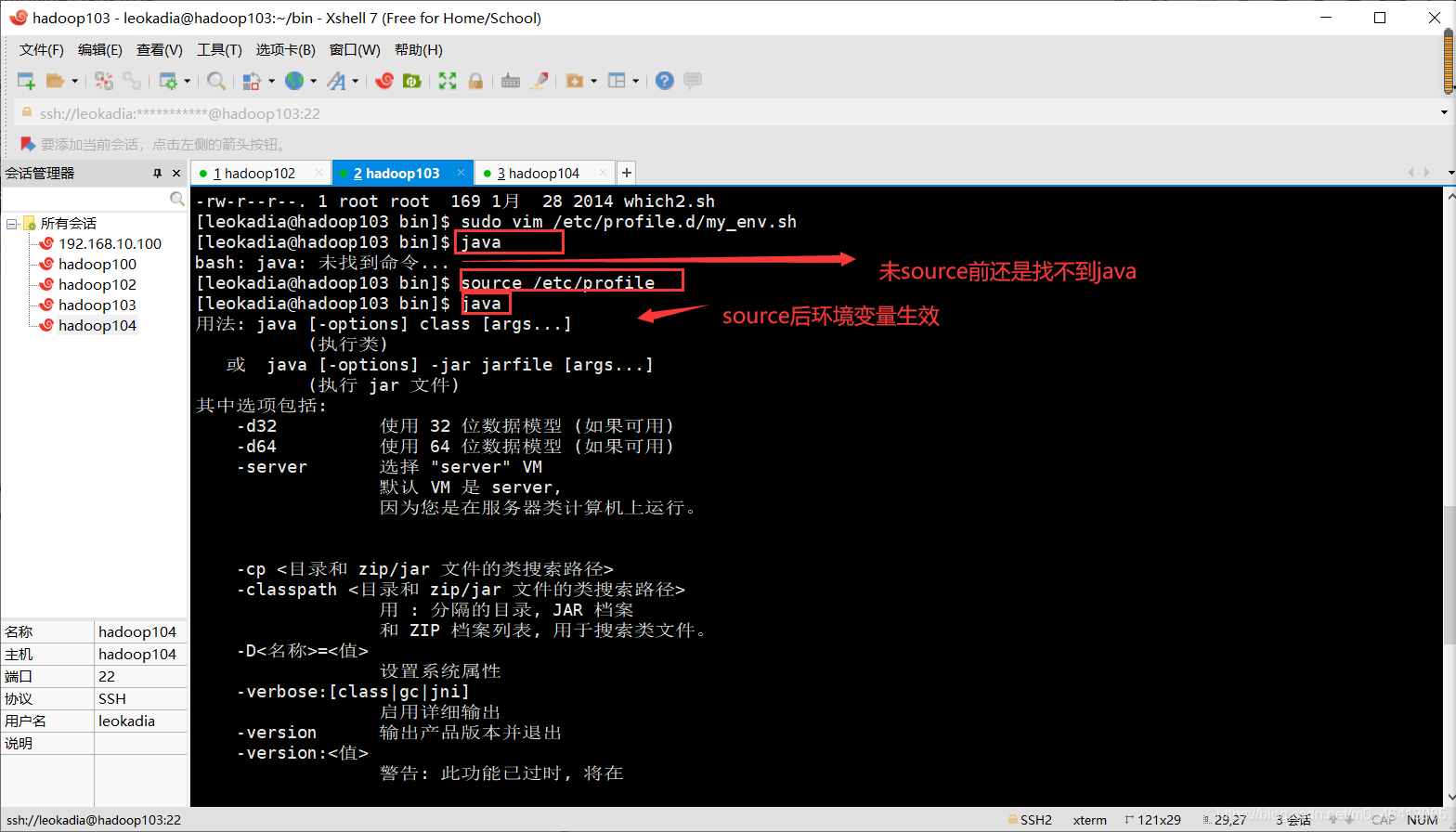
[leokadia@hadoop103 bin]$ sudo vim /etc/profile.d/my_env.sh

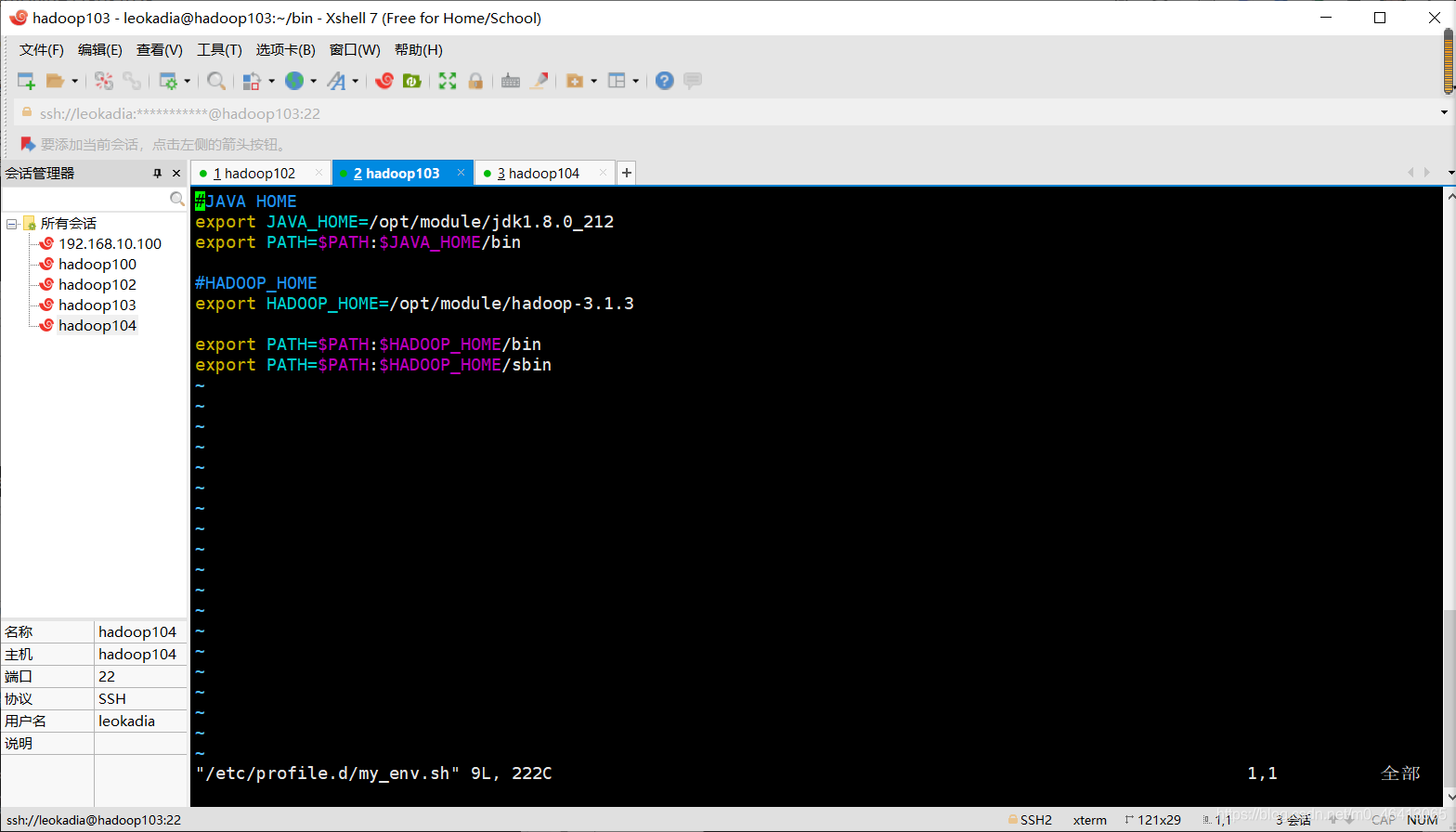
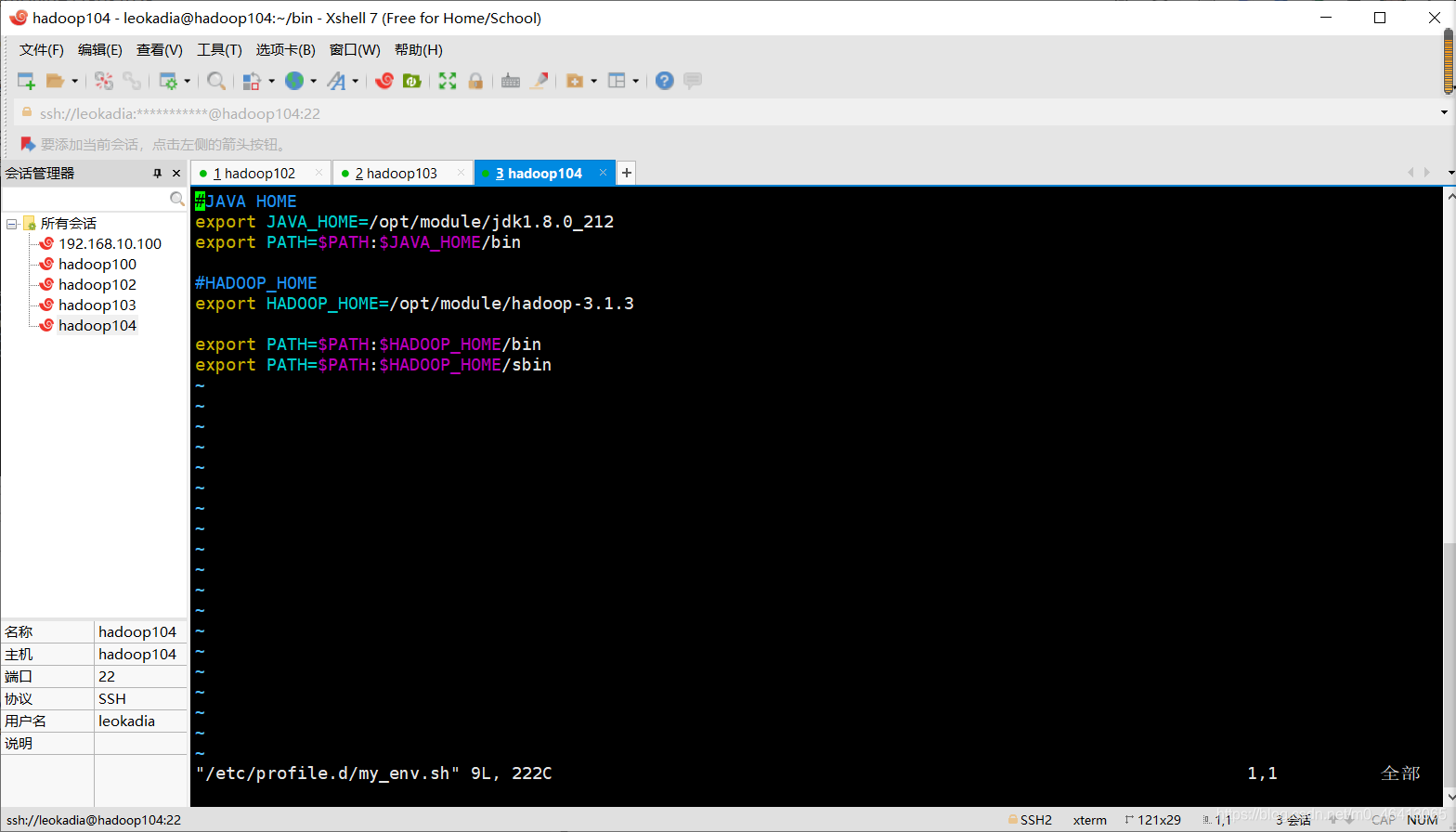
成功!
注意:让环境变量生效
[leokadia@hadoop103 bin]$ source /etc/profile
[leokadia@hadoop104 bin]$ source /etc/profile