
凡是搞计量经济的,都关注这个号了
所有计量经济圈方法论丛的code程序, 宏微观数据库和各种软件都放在社群里.欢迎到计量经济圈社群交流访问.

关于机器学习在计量分析中的应用,各位学者可以参阅如下文章:1.Python中的计量回归模块及所有模块概览,2.空间计量软件代码资源集锦(Matlab/R/Python/SAS/Stata), 不再因空间效应而感到孤独,3.回归、分类与聚类:三大方向剖解机器学习算法的优缺点(附Python和R实现),4.机器学习第一书, 数据挖掘, 推理和预测,5.从线性回归到机器学习, 一张图帮你文献综述,6.11种与机器学习相关的多元变量分析方法汇总,7.机器学习和大数据计量经济学, 你必须阅读一下这篇,8.机器学习与Econometrics的书籍推荐, 值得拥有的经典,9.机器学习在微观计量的应用最新趋势: 大数据和因果推断,10.机器学习在微观计量的应用最新趋势: 回归模型,11.机器学习对计量经济学的影响, AEA年会独家报道,12.机器学习,可异于数理统计,13.Python, Stata, R软件史上最全快捷键合辑!,14.Python与Stata, R, SAS, SQL在数据处理上的比较, 含code及细致讲解,15.Python做因果推断的方法示例, 解读与code,16.文本分析的步骤, 工具, 途径和可视化如何做?17.文本大数据分析在经济学和金融学中的应用, 最全文献综述,18.文本函数和正则表达式, 文本分析事无巨细。
前面,我们引荐了1.“机器学习方法出现在AER, JPE, QJE等顶刊上了!”,2.前沿: 机器学习在金融和能源经济领域的应用分类总结,3.Lasso, 岭回归, 弹性网估计在软件中的实现流程和示例解读”,4.回归方法深度剖析(OLS, RIDGE, ENET, LASSO, SCAD, MCP, QR),5.高维回归方法: Ridge, Lasso, Elastic Net用了吗,6.Lasso回归操作指南, 数据, 程序和解读都有,7.七种常用回归技术,如何正确选择回归模型?,8.共线性、过度/不能识别问题的Solutions,9.计量经济学与实验经济学的若干新近发展及展望,10.计量经济学新进展,供参考,11.最全: 深度学习在经济金融管理领域的应用现状汇总与前沿瞻望等,在学术同行间引起巨大反响。
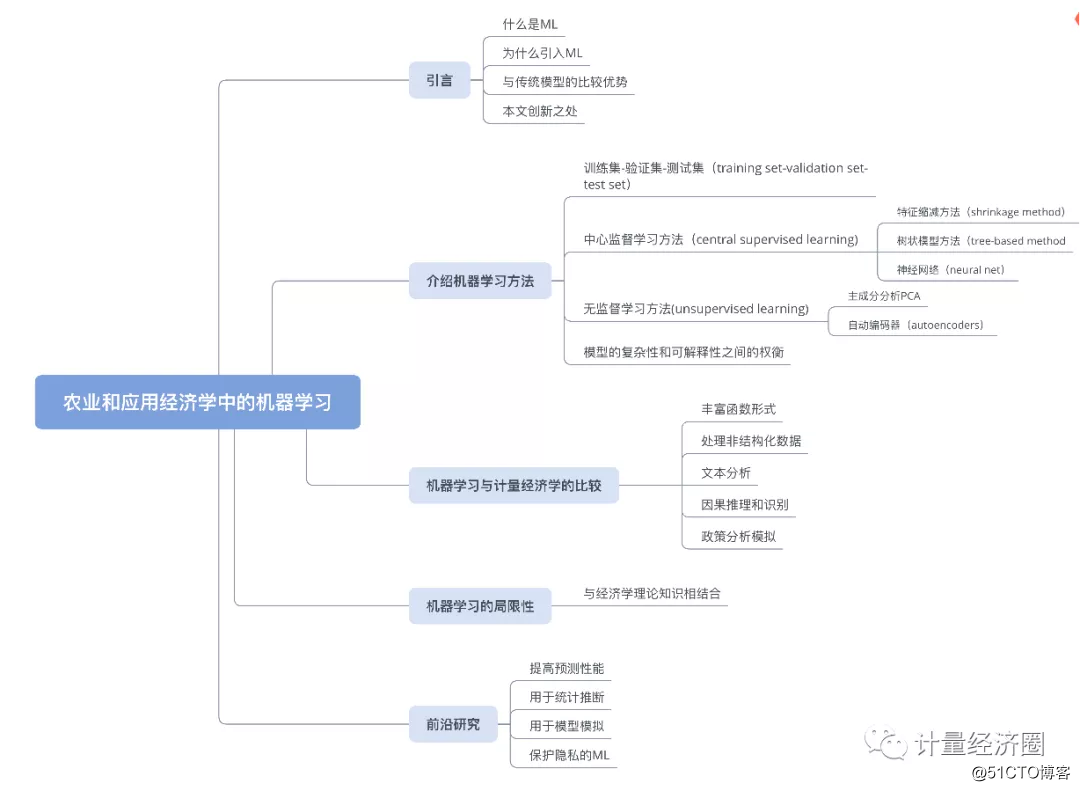
(一)丰富函数形式
1. 问题提出
(1)农业和环境经济学中的许多现象本质上是非线性的,是潜在的生物、物理、社会或经济过程的结果。例如,气候变量对产量的影响、地下水开采对抽水成本的影响或污染对健康的影响都可能包含非线性。
(2)对于时间,空间或社会网络,我们目前的方法也通常强加一些限制性的结构,如空间计量经济学中预先确定的邻域和相互作用的结构。
(3)通常,我们对异质性的特定方面感兴趣。而在大多数当前的方法中,应用经济学家估计平均效应,或者允许效应在不同的维度上或者在预先定义的有限数量的组之间有所不同,或者事后选择组,诱惑着去挑选那些符合研究者的先验或者那些产生显著结果的组。
(4)经济理论很少对人们试图估计的对象的具体形式给出明确的指导。它只提供有关形状限制的信息,如曲率或单调性。选择一个不能捕捉非线性、相互作用或异质和分布效应的模型可能会导致错误的描述偏差。这种偏差随着基础过程的非线性程度的增加而增加。
2.当前的计量经济学方法
当前的计量经济学工具箱已经提供了灵活的模型,但在许多情况下,计算需求限制了它们对大数据集(大“N”)或高维数据(大“K”)的适用性。
(1)随机系数模型(Random Coefficient Models),分位数回归模型(Quantile Regression Models)或混合模型(Mixture Models),允许一定的灵活性,但仍然对估计的关系强加限制性的线性假设,这种灵活性只是局部的,不是在解释变量的范围内灵活,因而限制了对经济环境变化的异质反应的能力。
(2)样条模型(Spline Models)、核模型(Kernel Models)和局部加权回归模型(Locally Weighted Regression Models)和GAM模型增加了更大的灵活性,但它们的应用通常仅限于有限数量的解释变量。
(3)数值贝叶斯推理方法(Numerical Bayesian Inference),如Gibbs 或 Metropolis Hasting这样的多中心抽样方法在处理大样本的能力方面是有限的
3.机器学习可以做什么
(1)集成树(Ensembles Of Trees)特别是梯度推进方法(Gradient Boosting Approaches)
梯度增强正在成为许多环境中最有效的预测工具;例如,信用评分和企业破产预测。虽然增强主要用于基于树的方法,但并不限于此。
-
Fenske、Kneib和Hothorn (2011年)开发了一种贝叶斯地理加性分位数回归方法(Bayesian Geoadditive Quantile Regression),该方法通过梯度增强进行估计。
-
在农业经济学中,Mrz等人(2016年)将这一方法应用于农田租赁费率。除了非常灵活之外,该方法还使用了自动数据驱动的参数选择,允许不同分位数上有不同参数。他们的结果揭示了协变量和租金之间存在着重要的非线性、异质性关系。
-
Ifft、Kuhns和Patrick (2018)发现,这些方法在预测农民信贷需求方面优于其他机器学习法和传统计量经济学方法。
(2)神经网络
神经网络还能够捕捉高度非线性的关系。神经网络和基于树的方法之间的一个重要区别是,使用神经网络是复杂的,并且通常需要用户指定更多的属性,例如层数和神经元,以及在训练期间进行更多的调整。 -
Cao,Ewing和Thompson (2012)发现单变量在风速预测方面优于单变量自回归综合移动平均(Autoregressive Integrated Moving Average,ARIMA)模型。
- Karlaftis和Vlahogianni (2011)比较了神经网络和ARIMA模型在交通领域的性能的研究并报告了神经网络的优越性能的证据。
与树状模型方法相比:神经网络提供了更自然的方法来处理超越诸如时间序列、面板或空间数据的横截面数据的非线性关系。
缺点:Marchi等人(2004年)质疑神经网络相对于logistic回归模型的优越性,认为模型应该尽可能的简约,并担心神经网络的过度拟合和可解释性。
优点:Beck,King和Zeng (2004)认为使用测试集控制过度拟合优于logit模型。最重要的是,logit模型可能需要做出不切实际的假设。例如,在他们的假设中,所有国家发生冲突的可能性是相同的,而我们预期影响是不同的,
(3)变分推理(Variational Inference)
变分推理通过允许更多的参数来增加模型的灵活性。它还可以有效地处理较大的数据集。变分推理的基本思想是用更容易计算的分布来近似复杂的分布。它提供了一种替代MCMC抽样方法的方法,用准确性来换取计算效率。
-
Athey等人使用变分推断来估计具有大量反映未观察到的特征的潜在变量的餐馆需求,这将挑战传统方法。
- Ruiz,Athey和Blei (2017)估计了一个潜在属性交互的顺序消费者选择模型,该模型使用高度分类的购物车数据,考虑了单个商品之间的交互。
(二)处理非结构化数据
1.问题提出
经济学家一般使用高度结构化的数据(如横截面、时间序列或面板)。而目前非结构化数据(如图像、文本或语音等)变得越来越可获得,传统计量经济学工具包对后者的用处有限。
2.当前方法
传统方法依赖于基于领域知识的手工特性聚合数据。例如,遥感数据被用来得出植被指数(NDVI),或诸如夜间光照强度的单一测量。手机记录被转换成特定的指数。同样,当处理文本数据时,索引通常是基于某些术语或短语的出现次数来导出的。
3.机器学习可以做什么
(1)端到端学习(End-To-End Learning)。
如果我们有大量的标记数据,我们可以使用“End-To-End Learning”,不依赖手工的特征或变量,而是让机器学习算法(通常是DNN算法)学会直接从原始数据中提取有用的特征。这种方法避免了传统方法中选择或聚集所隐含的信息丢失。
-
Rußwurm and Körner (2017)使用遥感数据(Sentinel 2 A图像)作为输入,并使用德国Bavaria 137,000多个标记田地的数据集来确定19个田地类别。
- You等人(2017年)使用多光谱遥感数据预测美国县级大豆产量。通过对数据生成过程做弱假设,他们能够减少输入数据的维数。
(2)无监督的DNNs预训练
无监督的DNNs预训练用大量未标记数据和有限标记数据,其思想是以无监督的方式依次训练神经网络的每一层。每一层都像一个自动编码器,它的目标是将输入映射到自身,同时采用某种形式的规范化。因此,该模型也称为堆叠式自动编码器。一旦第一层被训练(即第一自动编码器),学习的编码被给予第二层(第二自动编码器),然后第二层被训练并且其编码被给予下一层。这个过程持续到第二个最后一层,其输出可以被认为是输入数据的表示。最后一层然后使用标记数据进行训练,以将该学习的表示与目标变量相匹配,通常只涉及少量参数。训练可以在此停止,也可以使用标记的数据在最后的监督训练步骤中细化所有层的模型参数。
与PCA相比:无监督的预训练灵活性较高。
(3)迁移学习(Transfer Learning)
在一个环境中训练的模型和参数可以在另一个环境中使用。典型的应用是图像分类或目标识别。如VGG或ResNet这样的大型模型是在大量标记图像数据集(如ImageNet)上进行训练的。这些模型及其训练的参数可以被转移到其他图像识别任务中,在这些任务中,只有最后一层被训练,或者预处理的参数被用作起始值。在直觉层面上,即使一个模型最终被训练来区分狗和猫,模型的早期层次学习是通过如何识别图像中的一般结构,如边缘、线条或圆,这些对其他应用也是有用的。
(4)'Brute Force' Feature Engineering
'Brute Force' Feature Engineering使用确定性有限自动机(Deterministic Finite Automaton)自动生成大量特征,目的是尽可能多地捕捉原始数据的变化。然后在特征缩减回归中使用创建的特征来选择最有希望的特征,虽然定义特征需要更多的“手工制作”,而不是端到端的学习、转移学习或无监督的预培训,但在网络数据、轨迹、电话记录或家庭层面的跨国家扫描仪数据等输入数据特别复杂的情况下,这种方法很有潜力。
(三)文本分析
1.问题提出:解释变量较多
在许多领域,经济学家可以访问大量的数据集,包括观察数据的数量(N)和解释变量的数量(K)。例如土壤或天气数据,可以包括许多在高粒度空间和时间分辨率下观察到的特征(风、温度、降水量、蒸发等),这些特征通常随时间和/或空间的变化而不一致。通常,经济理论和领域知识对于选择应该包含在模型中的特定变量只能提供微弱的指导。
2.当前的计量经济学方法
(1)强加结构来选择K,这种方法只有在K < N时才可行,如AIC比较所有可能的模型组合,这只对小K可行,当K较大时,特别是在处理空间或时间上不一致的高分辨率数据时,数据通常是通过提取相关的手工特性来聚合的,这种聚集度量的设计需要特定的领域知识,信息的丢失是不可避免的。
(2)使用数据驱动的降维技术,如主成分分析(PCA)。贝叶斯变量选择或模型平均方法更灵活,理论上也更一致,但在行业中并不常用。
3.机器学习可以做什么
机器学习法在解决大K问题,尤其是K>N时很有用。但是即使当N > K时,这些方法也经常是有用的。一些不利于模型复杂性的机器学习方法,如lasso可以被视为变量选择技术,树形模型用于内部变量选择也可以很好地处理不相关的解释变量。
(1)无监督的降维方法,例如用于贪婪分层预训练的(堆叠)自动编码器或者作为特征提取器。
-
Li等(2016年)使用自动编码器基于传感器数据提供更好的空气污染预测,同时考虑到空间和时间相关性,并避免使用人工设计的特征。
-
Zapana等人(2017年)使用自动编码器提取特征来表征大气候时间序列数据。
-
Liu等(2015年)、萨哈、米特拉和南军地亚(2016年)和李等人(2018年)分别使用自动编码器来获得天气、季风和水质预报。
- Bianchi等(2018)、Li等(2018)将自动编码器还与RNNs相结合,以捕捉时间动态并处理丢失的观测数据。
优点:可以利用未标记的数据。
缺点:它们旨在尽可能多地保留底层数据的变化,但没有考虑到对于给定的任务,某些变化比其他变化更相关。例如,对于产量预测,天气的某个变化可能是不相关的(例如,生长海子外部的温度)。
(2)端到端学习
端到端学习方法可以考虑哪种变化最相关,但要求有“足够”的标记数据, “足够”取决于输入数据的维度和问题的复杂性。
(3)RNNs和CNNs
RNNs和CNNs非常适合处理大的K,特别适用于观测在空间或时间上不重合的情况。与无监督方法相比,神经网络的目标不是尽可能多地保留变异,而是提取与有监督预测任务相关的特征。
①RNNs的一个缺点是,尽管它们的体系结构擅长记忆事件的时间顺序,但它们不能很好地检测某个事件发生在哪个位置。此外,尽管RNN理论上可以记忆任意长度的序列,但在实践中,一旦输入序列变得过长,它们的性能就会迅速下降。
②CNN具有更长的有效记忆,并能处理更大的序列长度。同时,在CNN中,事件的时间安排可以更自然地预先安排。该模型因此可以得知冬季的天气事件与春季的天气事件有不同的影响。
(四)因果推理和识别
1.问题提出:需要预测反事实
我们没有观察到未经处理的观察结果(或经处理的对照观察结果)会发生什么,需要预测反事实。大多数因果推理的计量经济学方法都假设某种结构。
2.当前的计量经济学方法
(1)匹配
例如,最近邻对倾向分数,将由几个匹配变量组成的多维对象折叠成一维邻近度量的不同方式。
①双重稳健回归:A.匹配处理和对照观察B.使用由它们的匹配倾向分数加权的观察进行的处理来回归结果。这种方法对于匹配或回归阶段的错误指定都是稳健的。
②合成控制:其在处理前对结果匹配,当处理单位很少但时间序列较长时是有用的。局限性是对于许多可能的控制观察,估计每个控制的权重可能是有问题的。
(2)双重差分(Difference In Differences)
如果处理的选择是基于非时变的不可观测数据,并且观察了处理后的观测数据的预处理,那么就可以简单地应用一个单位固定效应的“双重差分”方法。局限性为模型假设平行趋势和普通冲击对处理单位和控制单位有相同的影响。如在评估一个地区的政策变化时,假设经济冲击对该地区和其他“控制”地区的影响相同,而当处理组中存在的异质性未被建模时,对处理组的估计可能产生偏差。
(3)两阶段最小二乘法(2SLS)
在内生回归的情况下,人们经常使用两阶段最小二乘法(2SLS)的工具。局限性为它假设在第一阶段和第二阶段都是线性关系,以及处理的同质性。
3.机器学习可以做什么
(1)反事实模拟(Counterfactual Simulation)
反事实模拟使用预处理和对照观测的数据,预测如果不进行处理,外源处理的观测结果会发生什么变化。将这一预测与处理观察的实际结果进行比较,可以确定处理效果。这些方法可用于随机处理或控制处理分配的准实验环境。
- Burlig等人(2017年)将面板数据方法与lasso相结合,从预处理数据中预测高频学校能源消耗的灵活反事实,以评估减少学校能源使用的方案的效果。
(2)双机器学习(Double ML,DML)
DML结合了机器学习法的预测能力和解决正则化偏差的方法。考虑下面的模型,其中试验的结果是处理的加性效应加上协变量的一些非线性函数(1),并且这些相同的协变量非线性地决定处理
(3)匹配的机器学习方法和面板方法(ML Methods for Matching and Panel Methods.)。
①匹配的机器学习方法
梯度增强树已被用于医学研究中的倾向分数匹配。模拟数据表明,在协变量之间的非线性和非加性关联下,增强树的表现很好。Doudchenko和Imbens (2016)使用弹性网络(Elastic Net)来估计这些权重,因为从根本上来说,这是一个预测问题,其中控制观测被用来预测趋势前处理观测。用于选择的降维机器学习技术经常与双稳健回归相结合,以控制模型指定中的潜在误差。
- Mullally和Chakravarty (2018年)应用这种方法来估计Nicaragua地下水灌溉方案的效果。
②面板方法
当处理是由可观察性决定时,标准方法是使用面板方法进行识别,建立一个差异框架。然后控制可能与处理位置相关的非时变的不可观察的事物。一些作者已经将机器学习方法用于面板设置,以允许降维和更灵活的功能形式。
可能存在的问题:A.许多系数实际上为零的假设可能与大多数个体异质性非零的观点相冲突。B.我们通常假设同一个体的误差随着时间的推移是相关的,这可能影响使用正则化选择的解释变量的数量。
(4)因果森林(Causal Forests)
①可以估计相当复杂的模型,根据预测能力选择协变量作为权重,因此对于添加非信息协变量是稳健的。
②可以在无基础的情况下一致地评估异基因处理效果。他们的算法生长“诚实”的树,根据一个子样本估计分裂,根据另一个子样本估计处理效果。
③可以在纯预测任务中生成置信区间也很有用。与DML相反,因果森林仅限于这种特定的机器学习法,以控制协方差对结果的影响。
-
Chernozhukov等人(2018)应用几种机器学习方法来估计随机处理对小额信贷干预对借款、自营职业和消费的异质性影响。他们确定受影响最大和最小的群体以及与他们相关的特征。
-
Carter, Tjernström and Toledo (2019)使用广义随机森林来评估Nicaragua小企业项目对农民结果的异质性影响,并找出对弱势家庭的最大影响。虽然他们发现总体成果不大,但那些在基线时处于不利地位的家庭从该方案中获益更多,突出了锁定目标的潜在好处。
- Rana和Miller (2019年)使用因果森林结合匹配来估计印度两种类型森林管理方案的异质性影响。
(5)IV和Deep IV。
①IV
如果预测因子与误差项不相关,即它们是外生的,那么反事实结果的预测只能识别政策或处理效果。有几篇论文采用机器学习技术来选择子集,以预测线性IV回归的第一阶段。
-
Bevis and Villa (2017)使用这种方法来估计母亲健康对儿童结局的长期影响,他们在母亲的早期生命中有大量来自天气变化的潜在工具。
- Ordonez,Baylis和Ramirez (2018)使用这种方法预测墨西哥Michoacan社区森林管理的采用情况,以评估其对森林结果的影响。它们有来自地点和活动或林务人员的多种潜在工具,影响社区森林管理计划的供应。
②Deep IV
Deep IV是一种2LS类型的方法,该方法使用机器学习法技术来放松2LS的限制性线性和同质性假设,并克服了非参数IV方法的计算限制。与其他机器学习方法一样,它也提供了一种变量选择的算法方法,这在面对大量可能的工具时可能是有用的。Deep IV第一阶段的估计方法是一个直接的监督预测任务,其中灵活的机器学习法工具,如神经网络,可以用来预测复杂的仪器和控制对处理的非线性影响。第二阶段也是受监督的机器学习设置。然而,用这种方法训练神经网络更加复杂,因为它需要在训练期间评估积分以导出损失函数的梯度。
(五)政策分析模拟
1.问题提出
除了计量经济学应用之外,我们的专业还大量使用计算模拟模型,尤其是用于政策分析。与政策相关的模型或建模系统的复杂性不断增加,这种复杂性在应用和校准中产生了巨大的计算需求。
2. 当前方法
ABM模型越来越多地被用作分析农业和环境经济问题。尽管它们很适合分析个体之间复杂的相互作用所产生的动态关系和涌现出的现象,但它们的区域覆盖范围、个体数量或模拟的个体行为复杂性通常受到计算约束等因素的限制。
3.机器学习可以做什么
(1)代理模型(Surrogate Modelling)
代理模型,也称为元模型(Meta-Modelling)或响应面模型(Response Surface Modelling),近似基础复杂模型的输入和输出之间的映射。这种方法的潜在优势在于,预测的准确性和维数仅受模型生成的待逼近数据量的限制。
①可用于模型校准,并在水资源建模,陆地表面模型,建筑能源需求和材料科学中广泛应用。使用代理模型进行校准的基本思想:A.在模拟模型输出的样本上训练替代模型;B.基于该代理模型执行校准,以找到与经验观察数据最接近的参数值。
②用于物理系统复杂模型的灵敏度分析。
这种方法仍然需要运行相对大量的底层模型来生成样本以训练代理模型。为了缓解这一问题,可采用自适应抽样(Adaptive Sampling)或迭代标定法(Iterative Calibration)等方法。
(2)生成式对抗网(Generative Adversarial Nets ,GANs)
GANs训练一个生成器和一个鉴别器模型。生成器旨在学习生成与实际图像相似的图像,而鉴别器旨在学习如何有效区分生成的图像和实际图像。将鉴别器结果反馈给发生器并以迭代方式提高其性能。在模型校准的情况下,模型生成器可以探索以何种方式来调整模型的参数,使得生成的输出数据尽可能接近观察数据,同时训练鉴别器来区分生成的数据和观察数据。
优点:不需要事先指定比较标准,鉴别器自己学习哪些特征对检测生成的数据最有用;而发生器的目标是尽可能接近地模拟观察到的数据。
四、经济学家能给机器学习带来什么
(一)为什么单纯的数据驱动模型是不够的?
1. 数据及其标签短缺
尽管数据可用性有所提高,但在许多应用中,我们仍然面临数据及其标签的短缺。
2.数据中包含的信息不足
例如,当处理罕见事件时,或者当结果非常嘈杂时,或者在处理高度复杂的过程和动态变化的非平稳模式时,即使是“大数据”也可能是不够的,在这些情况下,发现虚假相关性和发现非泛化关系的风险都很高。
3.数据的选择偏差
例如,手机数据只提供给那些能够使用手机的人;标签的质量可能因国家或地区而异。
(二)理论知识可以从两个方面帮助应对这些数据挑战。
1.理论领域的知识可以帮助理解一个模型为什么工作以及它是否已经学会了合理的关系。
2.结合理论知识可以提高机器学习法的效率(见第3.1节),尤其是在所描述的数据信息有限且过程复杂的情况下。
五、前沿研究
(一)提高机器学习的预测性能
1.引入结构信息
经济理论通常提供关于行为函数曲率(生产前沿、利润函数)或边际效应符号的信息。这种附加的结构信息在数据可用性有限和特征之间的复杂交互关系的情况下可能特别有帮助。
2. 监督方法和非监督方法相结合
(二)用于统计推断
将ML与统计推断过程相结合,从变分推理程序的具体情况发展到一个通用的方法,只需要说明一个概率经济模型,就可以从中产生一个随机样本。
(三)用于模型模拟
1.强化学习(Reinforcement Learning)
强化方法通过选择不同的动作并观察相关的奖励来学习,是一种优化方法。它们特别适合于顺序设置,其中代理按顺序执行多个操作,之前的操作影响后续操作的结果,并且反馈不是即时的,而是延迟的。他们也能处理不确定的环境,其结果不是决定性的。
强化学习越来越多地用于博弈论环境,但迄今为止政策相关性有限。进一步的发展可能有潜力在更具描述性的、与政策相关的模型中建立具有学习代理的模型,例如,代理根据自己的经验和环境(网络)提供的信息做出最佳战略选择。
2.GANs
GANs中的生成器和鉴别器算法之间的相互作用允许该方法了解什么特征是重要的,而不必先验地选择要校准的数据的特定的有限特征。因此可利用复杂的数据结构,并且生成的仿真模型通常更有效。
(四)保护隐私的机器学习
机器学习法研究的一个新的活跃领域促进了在多个数据集上模型的分布式训练,这些数据集不需要被共享。鉴于机器学习从数据中获取信息的强大能力,仅仅移除个人标识符已被证明不足以保护参与者的身份。此外,数据泄露正变得越来越普遍,引起了学者们对收集或分析机密数据的担忧。保护隐私的机器学习对未来的经济学家来说可能很重要,既允许使用机密数据,又有利于合作。
长按以上二维码查看原文PDF
下面这些短链接文章属于合集,可以收藏起来阅读,不然以后都找不到了。