机器视觉(四)——机器视觉应用
一、人脸识别
人脸识别需要在输入的图像中确定人脸(如果存在)的位置、大小和姿态,往往用于生物特征识别、视频监听、人机交互等应用中。2001年,Viola和Jones提出了基于Haar特征的级联分类器对象检测算法,并在2002年由Lienhart和Maydt进行改进,为快速、可靠的人脸检测应用提供了一种有效方法。OpenCV已经集成了该算法的开源实现,利用大量样本的Haar特征进行分类器训练,然后调用训练好的瀑布级联分类器cascade进行模式匹配。
OpenCV中的人脸识别算法首先将获取的图像进行灰度化转换,并进行边缘处理与噪声过滤;然后将图像缩小、直方图均衡化,同时将匹配分类器放大相同倍数,直到匹配分类器的大小大于检测图像,则返回匹配结果。匹配过程中,可以根据cascade分类器中的不同类型分别进行匹配,例如正脸和侧脸。
OpenCV已经集成了人脸识别算法,只需要调用OpenCV相应的接口就可以实现人脸识别的功能。
源码实现
1、初始化部分
初始化部分主要完成ROS节点、图像、识别参数的设置。
def __init__(self):
rospy.on_shutdown(self.cleanup);
# 创建cv_bridge
self.bridge = CvBridge()
self.image_pub = rospy.Publisher("cv_bridge_image", Image, queue_size=1)
# 获取haar特征的级联表的XML文件,文件路径在launch文件中传入
cascade_1 = rospy.get_param("~cascade_1", "")
cascade_2 = rospy.get_param("~cascade_2", "")
# 使用级联表初始化haar特征检测器
self.cascade_1 = cv2.CascadeClassifier(cascade_1)
self.cascade_2 = cv2.CascadeClassifier(cascade_2)
# 设置级联表的参数,优化人脸识别,可以在launch文件中重新配置
self.haar_scaleFactor = rospy.get_param("~haar_scaleFactor", 1.2)
self.haar_minNeighbors = rospy.get_param("~haar_minNeighbors", 2)
self.haar_minSize = rospy.get_param("~haar_minSize", 40)
self.haar_maxSize = rospy.get_param("~haar_maxSize", 60)
self.color = (50, 255, 50)
# 初始化订阅rgb格式图像数据的订阅者,此处图像topic的话题名可以在launch文件中重映射
self.image_sub = rospy.Subscriber("input_rgb_image", Image, self.image_callback, queue_size=1)
2、ROS图像回调函数
例程节点收到摄像头发布的RGB图像数据后进入回调函数,将图像转换成OpenCV的数据格式,然后预处理之后开始调用人脸识别的功能函数,最后发布识别结果。
def image_callback(self, data):
# 使用cv_bridge将ROS的图像数据转换成OpenCV的图像格式
try:
cv_image = self.bridge.imgmsg_to_cv2(data, "bgr8")
frame = np.array(cv_image, dtype=np.uint8)
except CvBridgeError, e:
print e
# 创建灰度图像
grey_image = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 创建平衡直方图,减少光线影响
grey_image = cv2.equalizeHist(grey_image)
# 尝试检测人脸
faces_result = self.detect_face(grey_image)
# 在opencv的窗口中框出所有人脸区域
if len(faces_result)>0:
for face in faces_result:
x, y, w, h = face
cv2.rectangle(cv_image, (x, y), (x+w, y+h), self.color, 2)
# 将识别后的图像转换成ROS消息并发布
self.image_pub.publish(self.bridge.cv2_to_imgmsg(cv_image, "bgr8"))
3、人脸识别
人脸识别直接调用OpenCV提供的人脸识别接口,与数据库中的人脸特征进行匹配。
def detect_face(self, input_image):
# 首先匹配正面人脸的模型
if self.cascade_1:
faces = self.cascade_1.detectMultiScale(input_image,
self.haar_scaleFactor,
self.haar_minNeighbors,
cv2.CASCADE_SCALE_IMAGE,
(self.haar_minSize, self.haar_maxSize))
# 如果正面人脸匹配失败,那么就尝试匹配侧面人脸的模型
if len(faces) == 0 and self.cascade_2:
faces = self.cascade_2.detectMultiScale(input_image,
self.haar_scaleFactor,
self.haar_minNeighbors,
cv2.CASCADE_SCALE_IMAGE,
(self.haar_minSize, self.haar_maxSize))
return faces
代码中有一些参数和话题名需要在launch文件中设置,所以还需要编写一个运行例程的launch文件。
<launch>
<node pkg="test2" name="face_detector" type="face_detector.py" output="screen">
<remap from="input_rgb_image" to="/usb_cam/image_raw" />
<rosparam>
haar_scaleFactor: 1.2
haar_minNeighbors: 2
haar_minSize: 40
haar_maxSize: 60
</rosparam>
<param name="cascade_1" value="$(find robot_vision)/data/haar_detectors/haarcascade_frontalface_alt.xml" />
<param name="cascade_2" value="$(find robot_vision)/data/haar_detectors/haarcascade_profileface.xml" />
</node>
</launch>
二 、物体跟踪
物体跟踪与物体识别有相似之处,同样使用特征点检测的方法,但侧重点并不相同。物体识别针对的物体可以是静态的或动态的,根据物体特征点建立的模型作为识别的数据依据;物体跟踪更强调对物体位置的准确定位,输入图像一般需要具有动态特性。
物体跟踪功能首先根据输入的图像流和选择跟踪的物体,采样物体在图像当前帧中的特征点;然后将当前帧和下一帧图像进行灰度值比较,估计出当前帧中跟踪物体的特征点在下一帧图像中的位置;再过滤位置不变的特征点,余下的点就是跟踪物体在第二帧图像中的特征点,其特征点集群即为跟踪物体的位置。该功能依然基于OpenCV提供的图像处理算法。
尽量选用纯色背景和色彩差异较大的测试物体。在画面中移动识别物体,即可看到矩形框标识出了运动物体的实时位置,可以针对实验环境调整识别区域、阈值等参数。
源码实现
1、初始化部分
初始化部分主要完成ROS节点、图像、识别参数的设置。
def __init__(self):
rospy.on_shutdown(self.cleanup);
# 创建cv_bridge
self.bridge = CvBridge()
self.image_pub = rospy.Publisher("cv_bridge_image", Image, queue_size=1)
# 设置参数:最小区域、阈值
self.minArea = rospy.get_param("~minArea", 500)
self.threshold = rospy.get_param("~threshold", 25)
self.firstFrame = None
self.text = "Unoccupied"
# 初始化订阅rgb格式图像数据的订阅者,此处图像topic的话题名可以在launch文件中重映射
self.image_sub = rospy.Subscriber("input_rgb_image", Image, self.image_callback, queue_size=1)
2、图像处理部分
例程节点收到摄像头发布的RGB图像数据后,进入回调函数,将图像转换成OpenCV格式;完成图像预处理之后开始针对两帧图像进行比较,基于图像差异识别到运动的物体,标识识别结果并进行发布。
def image_callback(self, data):
# 使用cv_bridge将ROS的图像数据转换成OpenCV的图像格式
try:
cv_image = self.bridge.imgmsg_to_cv2(data, "bgr8")
frame = np.array(cv_image, dtype=np.uint8)
except CvBridgeError, e:
print e
# 创建灰度图像
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (21, 21), 0)
# 使用两帧图像做比较,检测移动物体的区域
if self.firstFrame is None:
self.firstFrame = gray
return
frameDelta = cv2.absdiff(self.firstFrame, gray)
thresh = cv2.threshold(frameDelta, self.threshold, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.dilate(thresh, None, iterations=2)
binary, cnts, hierarchy= cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in cnts:
# 如果检测到的区域小于设置值,则忽略
if cv2.contourArea(c) < self.minArea:
continue
# 在输出画面上框出识别到的物体
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x + w, y + h), (50, 255, 50), 2)
self.text = "Occupied"
# 在输出画面上打当前状态和时间戳信息
cv2.putText(frame, "Status: {}".format(self.text), (10, 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)
# 将识别后的图像转换成ROS消息并发布
self.image_pub.publish(self.bridge.cv2_to_imgmsg(frame, "bgr8"))
代码中有一些参数和话题名需要在launch文件中设置,所以还需要编写一个运行例程的launch文件。
<launch>
<node pkg="test2" name="motion_detector" type="motion_detector.py" output="screen">
<remap from="input_rgb_image" to="/usb_cam/image_raw" />
<rosparam>
minArea: 500
threshold: 25
</rosparam>
</node>
</launch>
三、二维码识别
生活中越来越多的场景会用到二维码,无论是商场购物还是共享单车,二维码作为一种入口标志已经得到广泛应用。ROS中提供了多种二维码识别的功能包——(ar_track_alvar)
1、ar_track_alvar功能包
功能包ar_track_alvar的安装非常简单,直接使用以下命令即可:
sudo apt-get install ros-kinetic-ar-track-alvar
安装完成后,在ROS的默认安装目录中找到ar_track_alvar功能包。打开该功能包下的launch文件夹,可以看到多个launch文件。这些都是针对PR2机器人使用的二维码识别例程,可以在这些文件的基础上进行修改,让自己的机器视觉具备二维码识别的功能。
2、创建二维码
ar_track_alvar功能包提供了二维码标签的生成功能,可以使用如下命令创建相应标号的二维码标签:
rosrun ar_track_alvar createMarker AR_ID
其中AR_ID可以是从0到65535之间任意数字的标号,例如:
rosrun ar_track_alvar createMarker 0
可以创建一个标号为0的二维码标签图片,命名为MarkerData_0.png,并放置到终端的当前路径下。也可以直接使用系统图片查看器打开该二维码文件。
createMarker工具还有很多参数可以进行配置,使用以下命令即可看到使用帮助。
rosrun ar_track_alvar createMarker
createMarker不仅可以使用数字标号生成二维码标签,也可以使用字符串、文件名、网址等,还可以使用-s参数设置生成二维码的尺寸。
可以使用如下命令创建一系列二维码标签:
roscd robot_vision/config
rosrun ar_track_alvar createMarker -s 5 0
rosrun ar_track_alvar createMarker -s 5 1
rosrun ar_track_alvar createMarker -s 5 2
3、摄像头识别二维码
ar_track_alvar功能包支持USB摄像头或RGB-D摄像头作为识别二维码的视觉传感器,分别对应于individualNoKinect和individualMarkers这两个不同的识别节点。
4、Kinect识别二维码
同样可以使用Kinect等RGB-D摄像头识别二维码。
四、物体识别
ROS中集成了一个强大的物体识别框架——Object Recognition Kitchen(ORK),其中包含了多种三维物体识别的方法。
1、ORK功能包
在Ubuntu16.04下面进行操作的,由于该版本的kinetic并没有集成所有的ORK功能包,所以需要下面几步操作进行源码安装。
首先使用以下命令安装依赖库:
sudo apt-get install meshlab
sudo apt-get install libosmesa6-dev
sudo apt-get install python-pyside.qtcore
sudo apt-get install python-pyside.qtgui
下载rosinstall文件进行编译
文件链接:https://github.com/wg-perception/object_recognition_core
新建一个ork_ws工作空间,将ork.rosinstall.kinetic.plus文件直接download到ork_ws下面,然后按如下操作进行:
cd ork_ws
wstool init src [文件路径]/ork.rosinstall.kinetic.plus
下载功能源码:
cd src
wstool update -j8
git clone https://github.com/jbohren/xdot.git
cd ..
rosdep install --from-paths src -i -y
编译:
cd ork_ws
catkin_make
物体识别流程:
(1)创建需要识别的物体模型
(2)针对模型进行训练,生成识别模型
(3)使用训练后的识别模型进行物体识别
2、建立物体模型库
创建数据库
安装CouchDB工具:
sudo apt-get install couchdb
测试安装是否成功:
curl -X GET http://localhost:5984
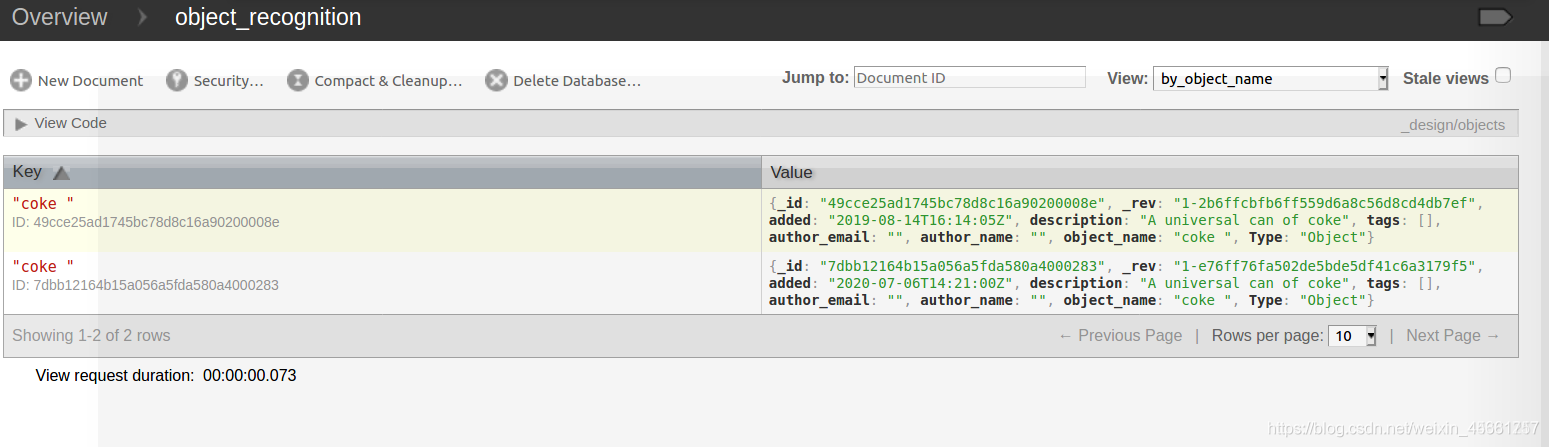
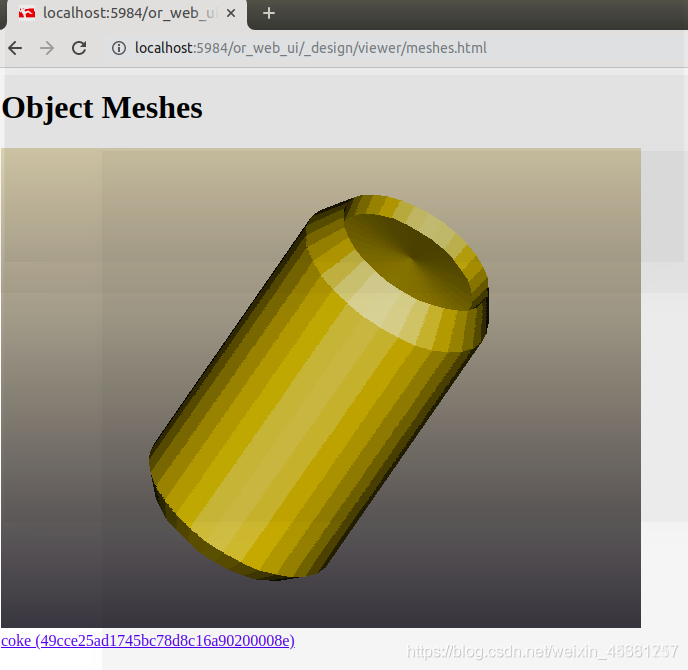
创建一条可乐模型数据:
rosrun object_recognition_core object_add.py -n "coke " -d "A universal can of coke " --commit
加载3D模型
下载已有的coke.stl模型,通过github下载:
git clone https://github.com/wg-perception/ork_tutorials
下载到src文件里;
然后把可乐模型加载到数据库里:
rosrun object_recognition_core mesh_add.py 49cce25ad1745bc78d8c16a90200008e [path]/ork_tutorials/data/coke.stl --commit
查看模型:
sudo pip install git+https://github.com/couchapp/couchapp.git
rosrun object_recognition_core push.sh
点击object_listing:
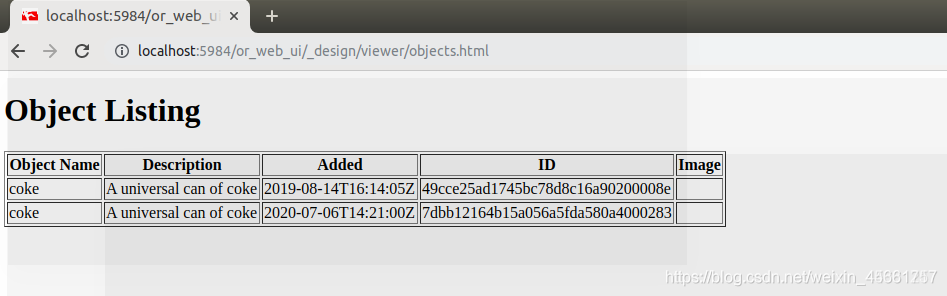
点击meshes:
3、模型训练
在数据库中加载了许多模型,我们需要进行训练生成匹配模板。
命令如下:
sudo object_recognition_core training -c `rospack find object_recognition_linemod`/conf/training.ork
4、三维物体识别