
文末有计量经济圈的重大资料福利。
引语:下面是关于计量经济学在具体操作中遇到的一些问题,以及他们的相关解答思路。计量经济学已经发展到了较为成熟阶段,但计量经济圈认为,理论计量需要在实证计量之前进行,否则我们就会失去一个分析框架。

3.1.Zellner-SUR与One step-SGMM方法,用Zellner-SUR方法的原因是什么?
答:SUR, 全称为Seemingly Unrelated Regression,是一个系列回归方程组,因为看起来这些回归方程之间没有关系,但他们的估计余项error term实际上是相关的。因此,我们需要分布求出各个余项,然后通过Variance-Covariance 矩阵来消除这中间的余项相关性,最终获得的估计才会更加有效。
2.求助:做完误差修正模型VECM后,想进行格兰杰因果检验用什么命令?stata里面貌似只有做完VAR时可以使用的vargranger这个命令?是否可以用gcause这个命令对变量进行两两检验?
答:Vecm与var实质上类似的,只不过vecm把不平稳的变量进行协整后,进行了Var款式的回归,最后出现了长短期之分。
所以,你如果想检验一次差分后的vecm的因果关系,你就按照var的路子塞进去差分过后的变量和之前通过ols回归过后留下的那个error term,这样vecm就相当于var,然后你就可以进行multivariate Granger causality检验基于Var。
就是说,把差分后的变量强制用var做一遍,然后用vargranger ,得出得格兰杰因果关系就是vecm的格兰杰因果关系。
3.下面的回归就是关键的解释变量不显著,我不知道怎么调整了?
Oneway (individual) effect Two steps model
Call:
pgmm(formula = y22 ~ lag(y22, 1) + lag(x11, 0) + lag(x12, 0) + lag(x21, 0:1) + lag(x22, 0) + lag(x23, 0) + lag(x24, 0) + lag(x31, 0) | lag(y22, 2:5), data = dd, effect = "individual", model = "twosteps", transformation = "ld")
Unbalanced Panel: n=32, T=1-8, N=248
Coefficients Estimate Std. Error z-value Pr(>|z|)
lag(y22, 1) 0.7577886 0.0948640 7.9882 1.370e-15 ***
lag(x11, 0) -0.0390686 0.0239760 -1.6295 0.103
lag(x12, 0) -0.0053499 0.0256653 -0.2084 0.83488
lag(x21, 0:1)0 0.9378587 0.0653638 14.3483 < 2.2e-16 ***
lag(x21, 0:1)1 -0.6913447 0.1057297 -6.5388 6.202e-11 ***
lag(x22, 0) 0.0997231 0.0413006 2.4146 0.01575 *
lag(x23, 0) 0.0304693 0.0160654 1.8966 0.05788
lag(x24, 0) -0.0453227 0.0197972 -2.2894 0.02206 *
lag(x31, 0) -0.0482559 0.0202909 -2.3782 0.01740 ---
Signif. codes: 0 ‘’ 0.001 ‘’ 0.01 ‘’ 0.05 ‘.’ 0.1 ‘ ’ 1
Sargan Test:p.value=0.68144
Autocorrelation test (1): p.value=0.0012981
Autocorrelation test (2): p.value=0.50829
Wald test for coefficients: p.value=< 2.22e-16
答:你用动态panel,或用random effect,试试。
4.Mean Groups (MG), Demeaned MG (DMG) and Common Corrleated Effects MG (CCEMG) estimators for heterogeneous panel models
答:对于mean groups主要用来解决fixed or random effects估计中设定的slope相同可能导致的不连贯性问题,所以mean group直接允许intercepts,slope,error等都可以在cross section间不同,这样估计出来的结果更连贯。
对于ccemg,主要是解决大panel data时,cross section彼此依赖的问题,也就是说,自变量和因变量都受到一个共同的但不可观测的因素影响,也允许slope不同,还可以延展到动态的panel data,平时用的工具变量和gmm解决动态panel data主要用于那些小面板数据。
5.面板回归空间误差的的三个检验的命令是啥?截面数据的命令是 spatdiag,面板数据咋检验?就是要检验面板数据有没有空间效应。这个面板空间交互性检验是用的什么命令? 陈强老师的书里面只有截面的命令spatdiag,w(w),w是空间权重矩阵。
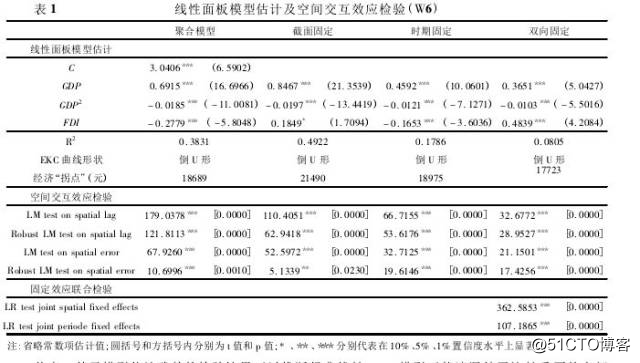
答:Spatial interactions panel data,我建议用这个命令"xsmle"。你当回归出来后,直接、间接、总的效应比较直观也知道显著性,还可以做postestimation。那个xsmle命令中应该有option (mi),你就可以用来处理unbalanced spatial panel。
6.有同学知道怎样画矢量图,用什么软件最方便么?
答:Coreldraw,当然也可以用adobe illustrator。
7.近来学习发现VAR正交化之后的脉冲响应函数(如乔利斯基分解之后的),是不是与SVAR的脉冲响应函数是一致的。感觉两者都用到了下三角矩阵的假设和相应的分解。
答:VAR带着choleski分解实际上等于svar的一种特例。Svar可以通过有不同的imposition而取得不一样的impulse response function。还有短期,长期之分,有just identified和over identified之分。
8.我想在相关性分析中标出3颗星星,怎么做?
答:要标星,用这个esttab
9.在哪里有faraway程序包?
答:去这个网址获得此包,
https://cran.r-project.org/web/packages/faraway/index.html
10.面板数据中有个变量不显著,但是删除了会影响其他变量显著性,那么这个变量就还是带着吗?各种效应这个变量都不显著。
答:不删可以,毕竟你不用这个变量解释东西。那可能这个控制变量和其他变量之间有比较严重的共线性。
11.对数据做回归,用两种不同的方程拟合,一个得到的残差比较小,一个比较均匀,哪个比较好呢?
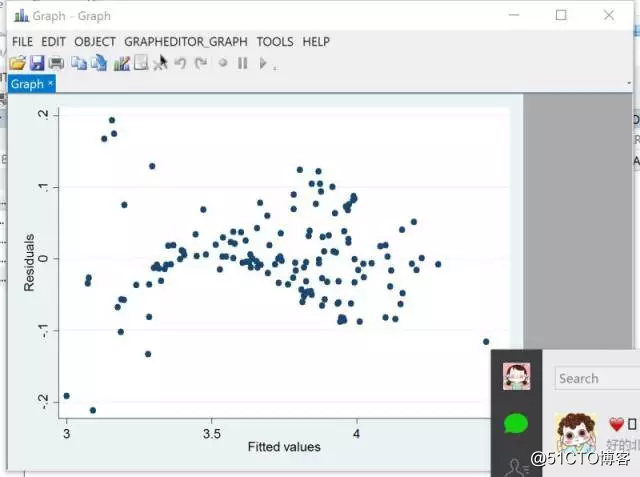
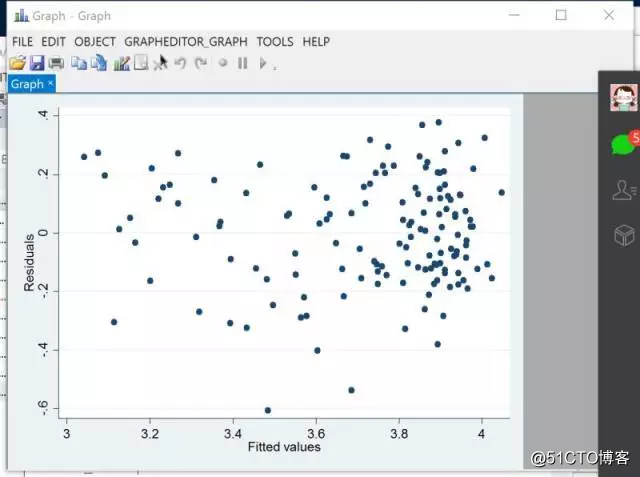
答:检查一下residual的自相关,residual与y的关系,residual 的concentration程度围绕0,等等。残差得符合normal distribution。
12.我用stata 做heckman两步,第二步还是probit,输入heckprob之后,出现了outcome does not vary; 的结果。我因变量都是0.1的啊?想请教一下错在哪里了?
答:注意Selection equation和Outcome equation的回归变量需要满足一些条件(Selection equation需要有一个回归变量没有在Outcome equation中出现过),还有保证两个Equations的被解释变量顺序正确。
13.想问一下,如果控制变量不显著该怎么解释呢?如何处理呢?
答:那证明,那个控制变量可能不影响你的解释变量与被解释变量之间的关系了。控制变量加入是为了检测其他变量的关系,当然你的情况可能这样的,你的主要解释变量可能因为控制变量对你的被解释变量影响力度超大而让你的所预想主要解释变量系数不明显。你确实需要检测一下你的控制变量与解释变量直接的相关性。
14.我想问下,在用stata做回归时,语句里面怎么区分是控制变量还是主要变量?还是语句里面不用区分,都放入回归模型中就行?
答:全部都放入,只是你在论文中分析时怎么表达而已。你看那些论文的模型主要变量后面都会跟一个控制变量集。
- 请教一个问题,在回归中,某个控制变量取对数与不取对数,对其他变量的估计结果有很大影响,想不通这是什么原因(自变量的相关系数都不大)。
答:取对数主要是考虑强制缩小outlier,还有就是靠近normality,你这个数据没有skeness 和kurtosis biasness,检查一下这个。
16.请教一个问题,面板数据变量y和x的相关系数不高,散点图也观察不出明显的关系,但是在控制个体和时间效应后,回归系数很显著,这种回归分析有问题吗?在回归前一定要先判断变量间的相关性吗?
答:对于Panel data,我们总是想要解决Unobserved heterogeneity,这些存在于个体或时间段上的差异性,将会因为我们的忽略而导致“Omitted variable bias”(考虑下Confounding variable)。而要解决这个问题,我们的方法fixed effect(控制个体间的差异性)和 between effect(控制时间段的差异性)。
而如果你在还没有控制个体和时间效应之前,发现regressors和regressed之间相关性不高;可当你在控制了两个效应后(即在回归方程中加入了个体和时间效应),却发现regressors和regressed之间相关性很大(回归系数很显著),这就明明显示了你差点犯了“Omitted variable bias”的问题,因此你应当使用Panel data的固定效应或随机效应进行回归。
17.面板数据是不是一开始就要在固定效应与随机效应中做选择?
答:实际上,固定效应回归总能够保证Consistency,只不过不能够保证Efficiency;而随机效应回归一般而言更加有效,但是不一定那么具有Consistency。
因此,在Hausman test中,你就是通过一个Asymptotic distribution组建一个分布,来平衡Consistency和Efficiency。在面板数据中,你需要先做选择的。
18.请问能帮忙解释一下面板工具变量回归出来的这一部分命令吗?中间那一部分弱识别那一部分右侧的数据是什么意思?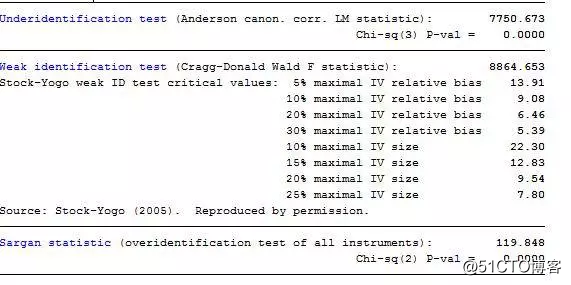
答:Underidentification test 即识别不足检验 其原假设是认为存在识别不足问题 或者说是工具变量与内生变量无关,这个结果可以说明你的工具变量与内生变量相关,但仍然可能存在弱工具变量这一问题。
Weak identification test 即弱工具变量检验 这是识别不足检验的进一步检验,其原假设是认为工具变量与内生性变量有较强的相关性,你的结果说明工具变量相关性还是比较高的。那最后一行的过度识别检验:H0,过度identified,H1,不是过度identified。
19.面板平滑回归(Panel Smooth Transition Regression)?Hansen的门槛回归(非线性)?
答:下载RATS计量软件,然后用GVTD.SRC程序包。Hansen的门槛GMM回归软件包R:http://www.ssc.wisc.edu/~bhansen/progs/et_04.R。门槛回归的Stata软件包命令:threshold。
20.①pcse 模型,31省市 ,8期,是不是太短了,不能用呢 ?
agl.pcse <- pcse(agl.lm, groupN=mydata$region, groupT=mydata$year,pairwise=TRUE)
Error in pcse(agl.lm, groupN = mydata$region, groupT = mydata$year, pairwise = TRUE) :
Error! A CS-unit exists without any obs or without any obs in common with another CS-unit. You must remove that unit from the data passed to pcse().
②请问下外标法或标准曲线怎么弄?
③用Excel做规划求解,目标单位格里直接输入类似=x1+x2可以吗?
④有用charls 数据的吗?请问“家庭人口数”这个怎么做?有没有知道工作经验这个变量在chns的哪个文件里面?
⑤stata新手请教群里大神,tsset如何设置不连续的时间序列?比如非交易日的情况。
