战斗民族开源 | ClickHouse万亿数据双中心的设计与实践
赵群 大数据技术与架构
By 大数据技术与架构
场景描述:Clickhouse是一个用于联机分析处理(OLAP)的列式数据库管理系统。
传统数据库在数据大小比较小,索引大小适合内存,数据缓存命中率足够高的情形下能正常提供服务。但残酷的是,这种理想情形最终会随着业务的增长走到尽头,查询会变得越来越慢。你可能通过增加更多的内存,订购更快的磁盘等等来解决问题(纵向扩展),但这只是拖延解决本质问题。如果你的需求是解决怎样快速查询出结果,那么ClickHouse也许可以解决你的问题。
关键词:Clickhouse OLAP
大数据技术与架构之前分享过《OLAP》的文章,里面提到一个俄罗斯Yandex公司开源的轻量级数据库Clickhouse。这篇文章是来自百分点的赵群分享的关于基于clickhouse构建数据中心的经验。
场景与挑战
数据存储:
数据量:2000亿+/日
高峰:500WRow/s
延时:<30秒 熔断/限流
2地双中心 查询/分析透明访问
查询:
1TB常规查询<10s
1TB聚合查询(排序/分组)<5m
综上所述,业务场景:
- OLAP引擎评估
- 超大规模的单表查询/分析
- 有一定的并发要求
- 实时性要求
期望OLAP引擎:
- PB级的数据存储
- 高性能的查询/分析能力
- 低延时写入及吞吐能力
- 数据压缩
- 跨中心能力

Clickhouse的2地双中心设计
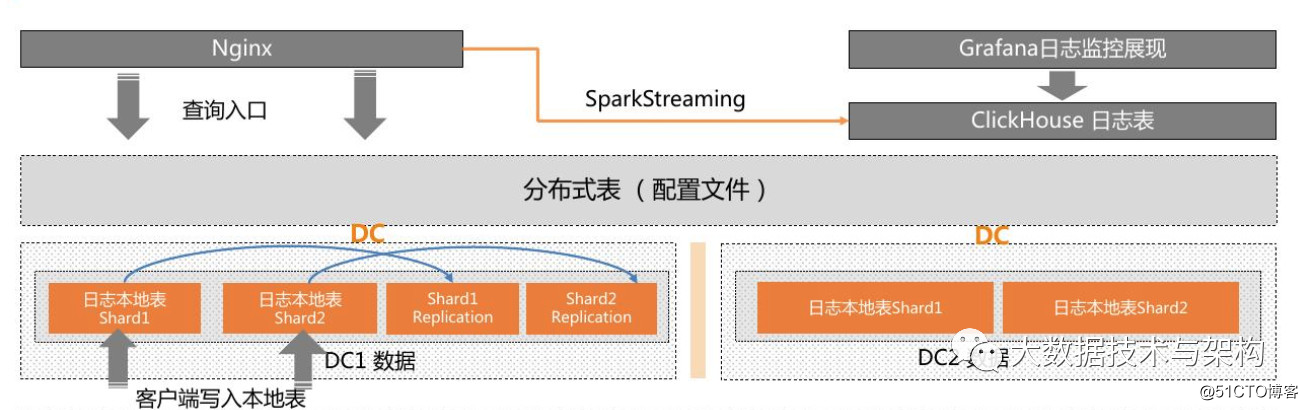
- ClickHouse跨中心透明访问。性能影响:1/4 ~1/3
- 禁止分布式写。
- 经过设计Replication是有稳定保障的
- Nginx负载均衡,路由分发,安全加固
- 日志采集、展现、分析
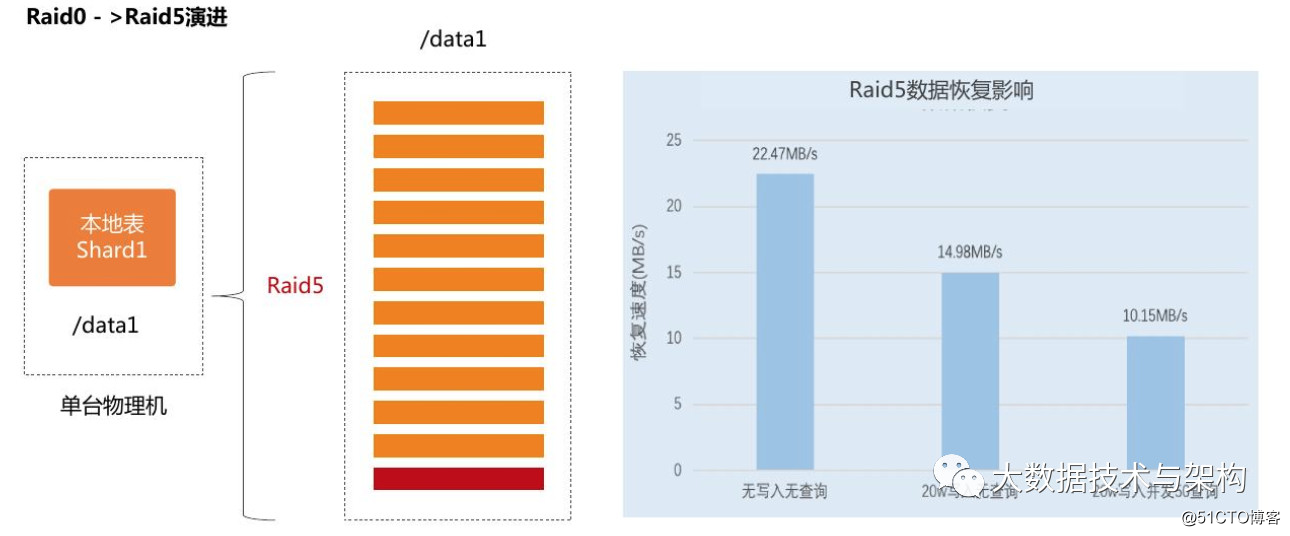
Clickhouse磁盘的Raid选择:
- Raid5增加磁盘数据可靠性和读取能力
- 热备盘减少运维压力
- 控制写入,保障查询性能
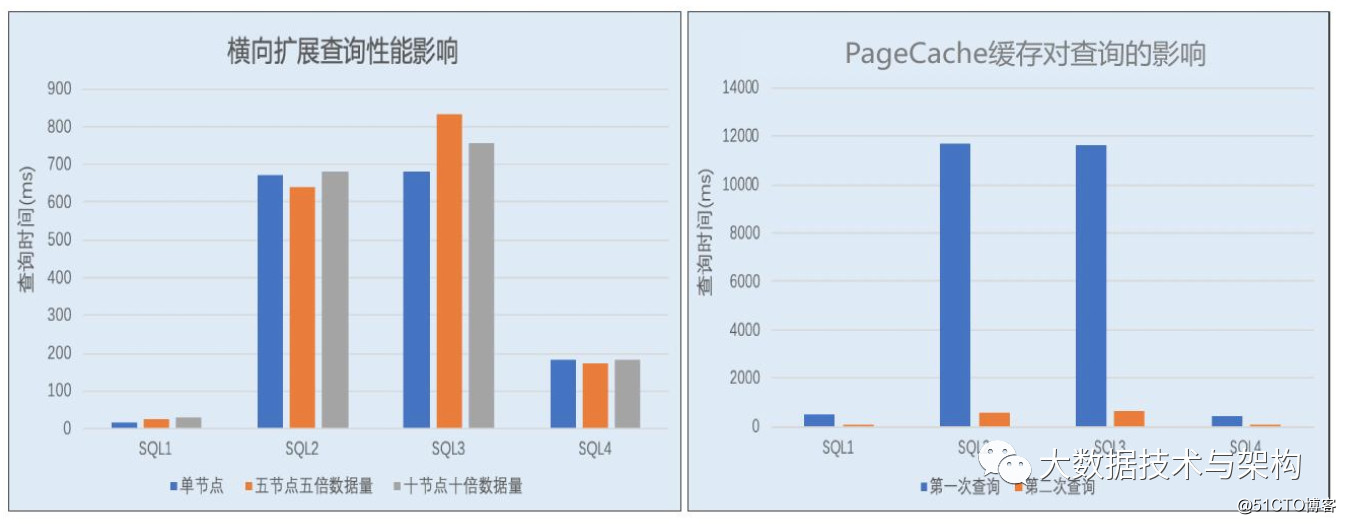
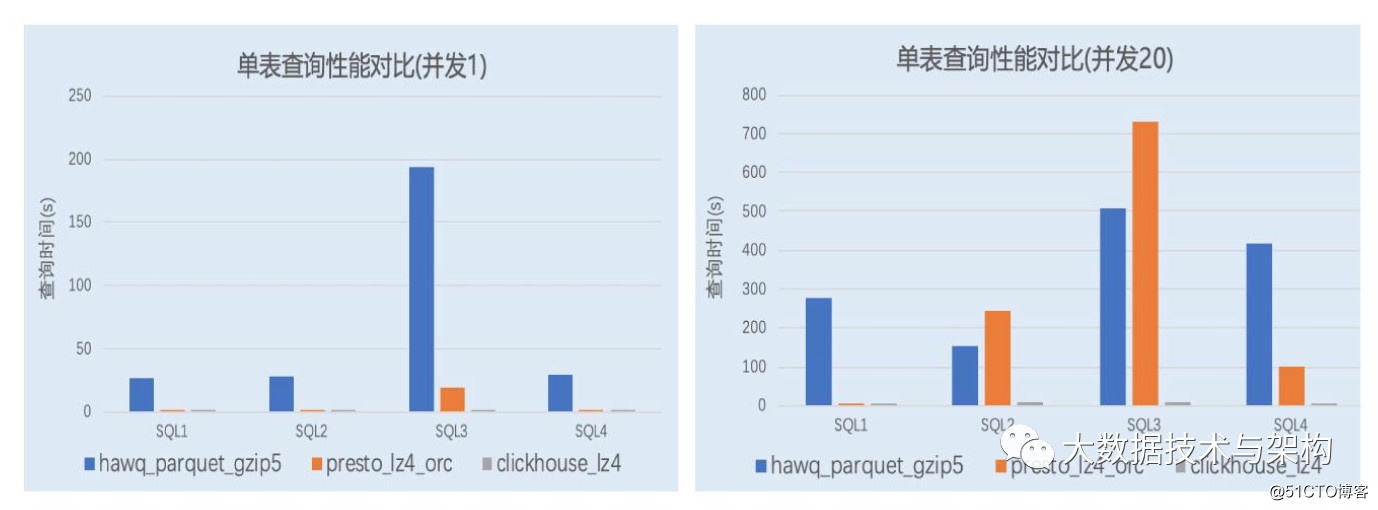
相关测试分析表明:
- 横向扩展对查询性能几乎无影响
- 可以基于单节点/分区评估查询性能
- 数据预热对查询有数量级提升
- 针对缓存更换条件同样生效
Clickhouse的写入稳定性设计
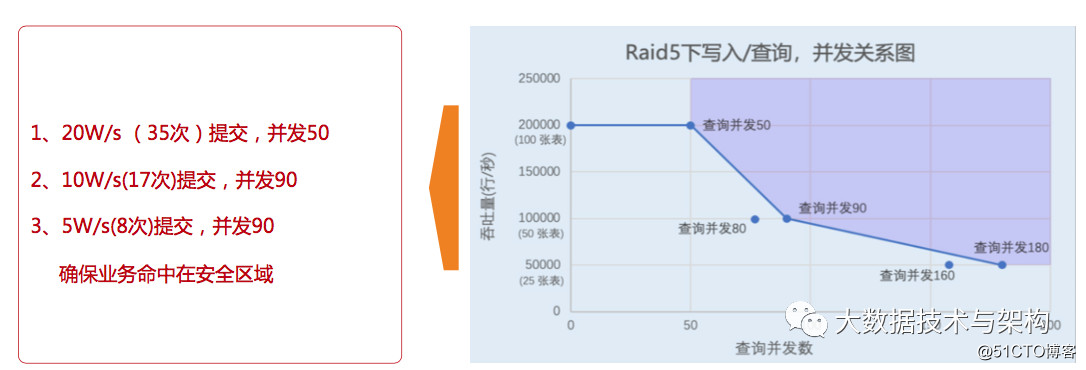
- 平衡好合并速度和Part数量的关系,一定是需要相对均衡的
- Part数量,实际代表着提交频率,一定是稳定,且经过估算的
- ClickHouse的查询和写入共同受限于Query数限制,需要分配好配额
- 禁止直接写入分布式表
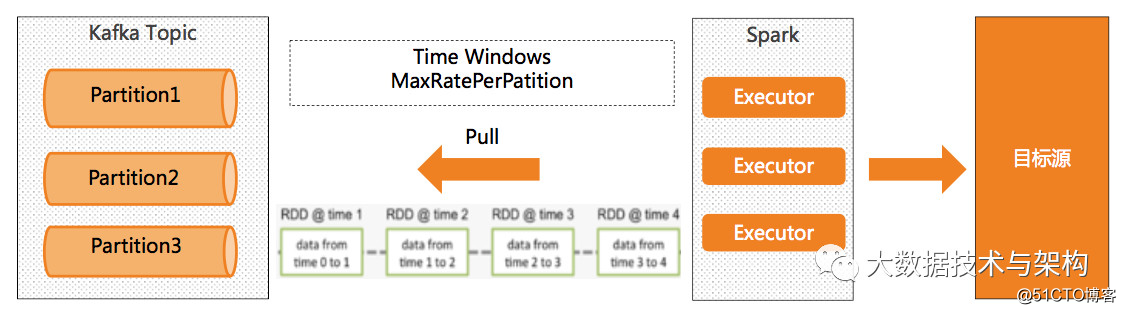
- 时间窗口保障持续稳定提交频率。(保障对ClickHouse写入的稳定)
- SparkStreaming 微批处理(控制处理上限),利用反压机制,实现处理能力动态平衡
- Spark on Yarn 资源可控。
- 以写入ClickHouse为例,目前一个Executor处理在30000/s 左右。
- 假设我们需要一个满足300W/s的处理能力。在源读取没有瓶颈的情况下,可以 Executor数 : 300 /3 = 100(个)
Clickhouse的查询优化
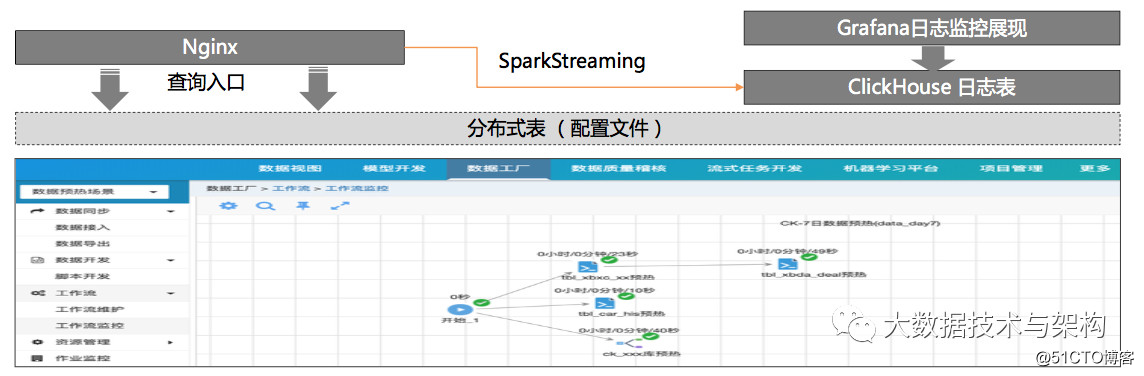
- 限制单条查询内存使用量和单节点查询内存使用量,预防节点Down机。
- Query数量限制异常:控制好配额/连接池。
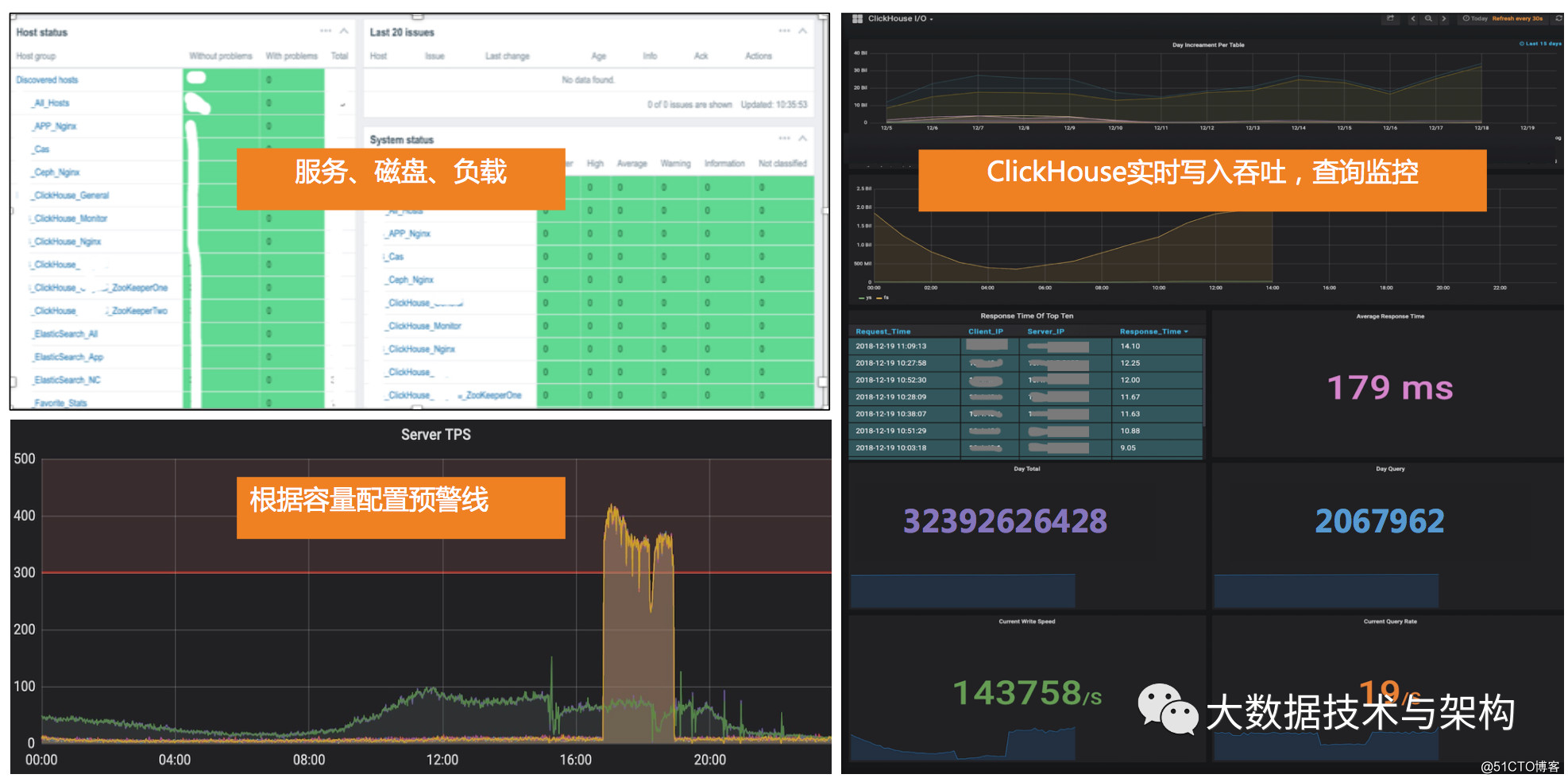
- 集群的Query日志,找出慢查询。我们直接通过Nginx收集了原始日志。
- 针对热数据进行查询预热。
其他参数优化: