BN层,全称Batch Normalization,译为批归一化层,于2015年提出。其目的在文章题目中就给出:BN层能够减少内部变量偏移来加速深度神经网络的训练。
源文链接:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
在这里从Batch size讲起,说一下自己的理解,BN层内容其实比较简单,但是为了方便理解我在这里加入一些思考过程,可能稍显冗杂,因而分为上下两个部分,参考链接会在下给出。
一、Batch size
Batch size是指一次训练所选取的样本数。在没有使用Batch Size之前,这意味着网络在训练时,是一次把所有的数据(整个数据库)输入网络中,然后计算它们的梯度进行反向传播,由于在计算梯度时使用了整个数据库,所以计算得到的梯度方向更为准确。但在这情况下,计算得到不同梯度值差别巨大,难以使用一个全局的学习率,所以这时一般使用Rprop这种基于梯度符号的训练算法,单独进行梯度更新。
在小样本数的数据库中,不使用Batch Size是可行的,而且效果也很好。但是一旦是大型的数据库,一次性把所有数据输进网络,肯定会引起内存的爆炸。所以就提出Batch Size的概念。
当然,Batch size的大小并非是固定的,也不是越大越好或者越小越好,而是随着具体的问题不断改变,这就需要不断的尝试。
二、Internal Covariate Shift
深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。为了训练模型,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。Google 将这一现象总结为 Internal Covariate Shift,简称 ICS.
在统计机器学习中有一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如 transfer learning / domain adaptation 等。而 covariate shift就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同。
即:对所有x ∈ X,有:Ps ( Y ∣ x = X ) = Pt ( Y ∣ x = X )
但是,Ps ( X ) ≠ Pt ( X )
可以看到,随着网络层数的加深,输入分布经过多次线性非线性变换,已经被改变了,但是它对应的标签,如分类,还是一致的,即使条件概率一致,边缘概率不同。
那如何去解决这一问题呢?思路就是对数据进行预处理,使其满足独立同分布,使特征分布均值为0,方差为1。
白化(Whitening)通常是机器学习中常用的一种规范化数据分布的方法,通过白化操作可以起到一定作用,但是白化的计算成本太高每一轮训练中的每一层都需要做白化操作;同时白化改变了网络每一层的分布,导致网络层中数据的表达能力受限。
因而,Normalization的方法被提出。
三、Normalization
1.正向传播过程,引用论文中的解释

输入:x1…xm,两个待学习的参数
输出:两个参数
(1)计算均值
(2)计算方差
(3)进行标准化,引入ϵ为了防止分母为0
(4)训练参数γ,β 并输出
在正向传播的时候,通过可学习的γ与β参数求出新的分布值
2.在反向传播的时候,通过链式求导方式,求出γ与β以及相关权值
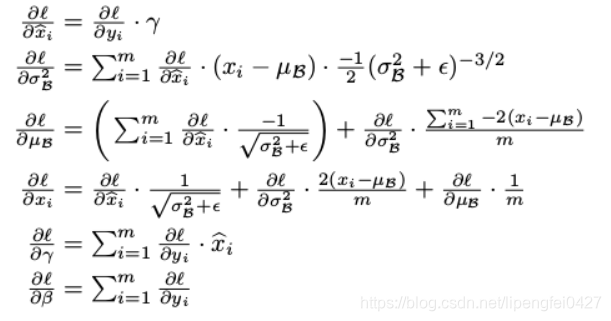
下半部分链接: https://blog.csdn.net/lipengfei0427/article/details/108996594