一、告警规则实现原理
目前Prometheus与Alertmanager已经连通,接下来我们可以针对收集到的各类指标配置报警规则,一旦满足报警规则的设置,则Prometheus将报警信息推送给Alertmanager,进而转发到我们配置的邮件中。在哪里配置?同样是在prometheus-configmap中: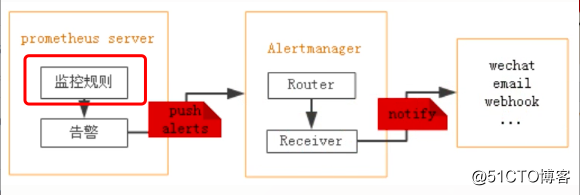
二、修改prometheus配置文件
prometheus-configmap.yaml 配置文件增加rule_files与alert_rules.yml
#一个ConfigMap上传两个配置文件,分别为prometheus.yml与alert_rules.yml
$ vim prometheus-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 30s
evaluation_interval: 30s
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files: #增加的内容
- /etc/prometheus/alert_rules.yml
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
... # 省略中间部分
alert_rules.yml: | #增加的内容
groups:
- name: node_metrics
rules:
- alert: NodeLoad
expr: node_load15 < 1
for: 2m
annotations:
summary: "{{$labels.instance}}: Low node load detected"
description: "{{$labels.instance}}: node load is below 1 (current value is: {{ $value }}"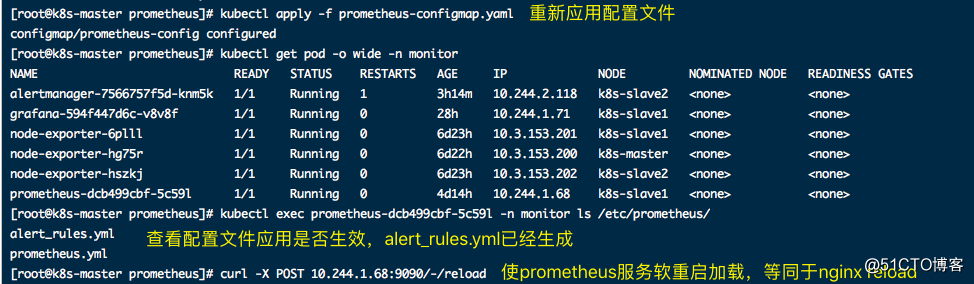
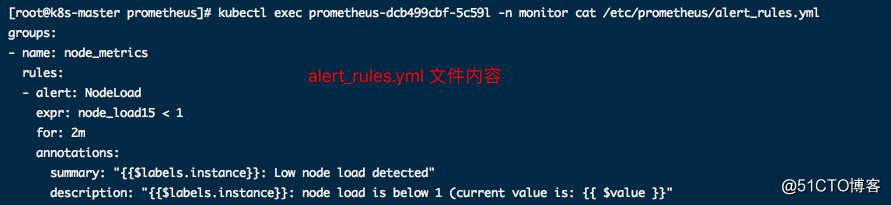
三、告警规则的理解
alert_rules.yml: |
groups:
- name: node_metrics
rules:
- alert: NodeLoad
expr: node_load15 < 1 #检查各节点cpu5分钟负载低于1的
for: 2m
annotations:
summary: "{{$labels.instance}}: Low node load detected"
description: "{{$labels.instance}}: node load is below 1 (current value is: {{ $value }}"- group.name:告警分组的名称,一个组下可以配置一类告警规则,比如都是物理节点相关的告警
- alert:告警规则的名称
- expr:是用于进行报警规则 PromQL 查询语句,expr通常是布尔表达式,可以让Prometheus根据计算的指标值做 true or false 的判断
- for:评估等待时间(Pending Duration),用于表示只有当触发条件持续一段时间后才发送告警,在等待期间新产生的告警状态为pending,屏蔽掉瞬时的问题,把焦点放在真正有持续影响的问题上
- labels:自定义标签,允许用户指定额外的标签列表,把它们附加在告警上,可以用于后面做路由判断,通知到不同的终端,通常被用于添加告警级别的标签
- annotations:指定了另一组标签,它们不被当做告警实例的身份标识,它们经常用于存储一些额外的信息,用于报警信息的展示之类的
规则配置中,支持模板的方式,其中:
- {{$labels}}可以获取当前指标的所有标签,支持{{$labels.instance}}或者{{$labels.job}}这种形式
- {{ $value }}可以获取当前计算出的指标值
一个报警信息在生命周期内有下面3种状态:
- inactive: 表示当前报警信息处于非活动状态,即不满足报警条件
- pending: 表示在设置的阈值时间范围内被激活了,即满足报警条件,但是还在观察期内
- firing: 表示超过设置的阈值时间被激活了,即满足报警条件,且报警触发时间超过了观察期,会发送到Alertmanager端
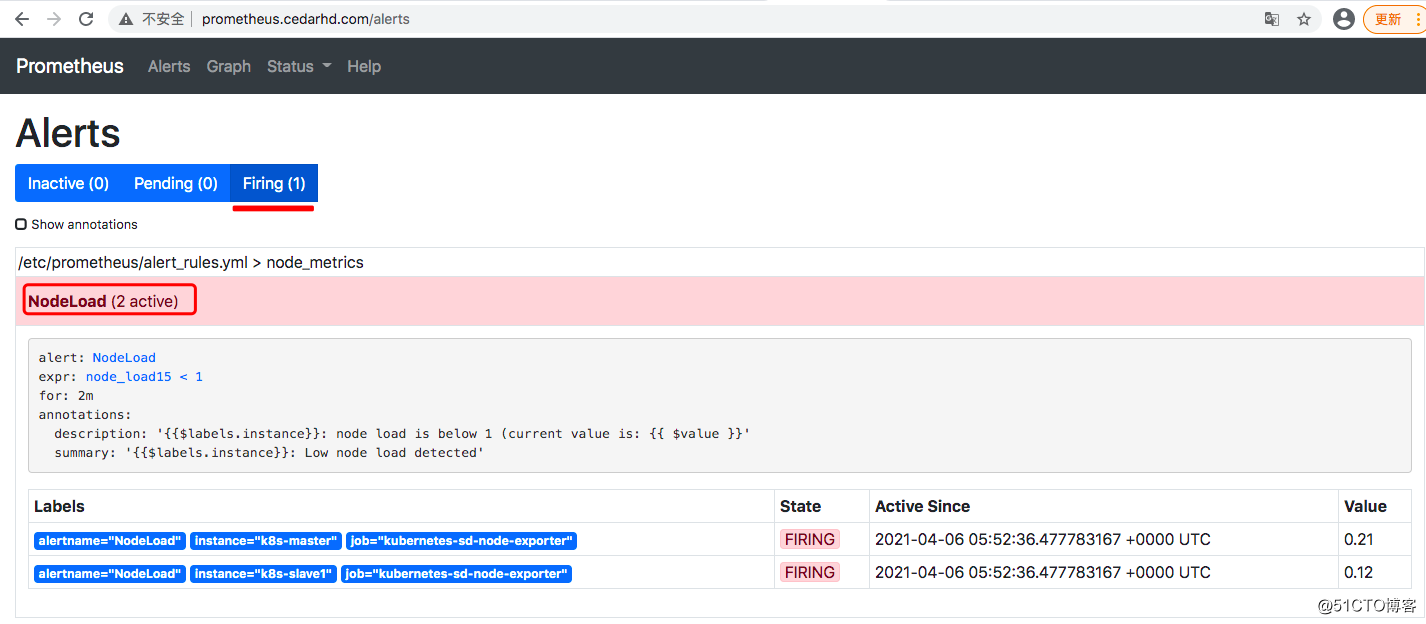
四、检查告警内容
Prometheus Alerts 内容
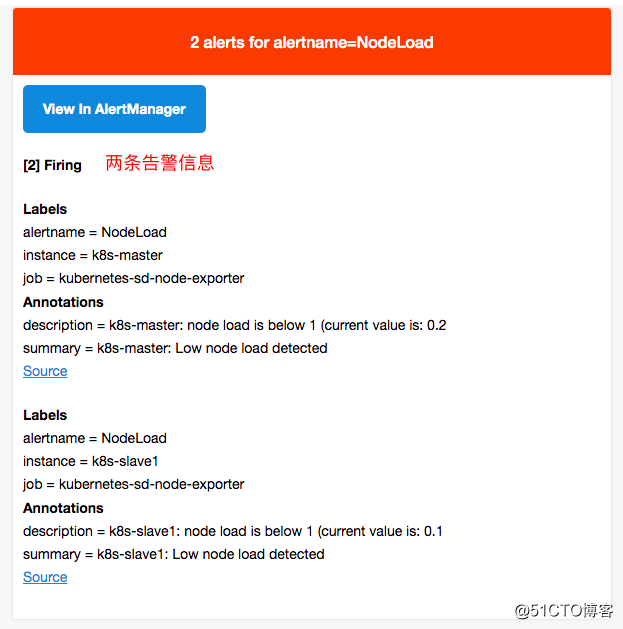
收到邮件告警与恢复信息

整个prometheus-configmap.yaml文件内容
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093 #通过alertmanager的svc方式推送
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- /etc/prometheus/alert_rules.yml
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'coredns'
static_configs:
- targets: ['10.96.0.10:9153']
- job_name: 'kubernetes-apiserver'
static_configs:
- targets: ['10.96.0.1'] #apiserver的svc
scheme: https #访问方式,默认是http
tls_config: #因apiserver的调用需有授权认证信息
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: 'kubernetes-scheduler'
static_configs:
- targets: ['10.3.153.200:10251']
- job_name: 'kubernetes-controller'
static_configs:
- targets: ['10.3.153.200:10252']
- job_name: 'kubernetes-sd-node-exporter'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- job_name: 'kubernetes-sd-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- target_label: __address__
replacement: 10.96.0.1
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
alert_rules.yml: |
groups:
- name: node_metrics
rules:
- alert: NodeLoad
expr: node_load15 < 1
for: 2m
annotations:
summary: "{{$labels.instance}}: Low node load detected"
description: "{{$labels.instance}}: node load is below 1 (current value is: {{ $value }}"