一)简介
RCNN的全称是Region-CNN,是第一个成功将深度学习应用在目标检测上的算法,作者Ross Girshick多次在PASCAL VOC的目标检测竞赛中折桂,2010年更带领团队获得终身成就奖。后续的Fast R-CNN、Faster R-CNN都是建立在RCNN上的。
二)R-CNN介绍
R-CNN遵循传统目标检测的思路,同样采取提取框、对每个框提取特征、图像分类、非极大值抑制四个步骤进行目标检测。只不过在提取特征这一步,将传统的特征(如SIFT、HOG特征等)换成了深度卷积网络提取的特征。
R-CNN的整体框架如下图所示。
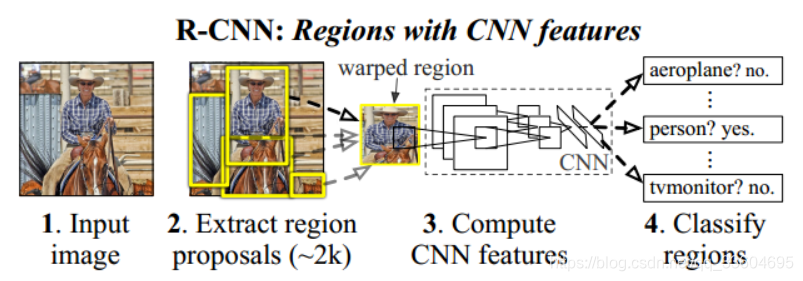
2.1)生成候选区域
对于原始图像,首先使用Selective Search搜寻可能存在物体的区域。Selective Search可以从图像中启发式地搜索出可能包含物体的区域,相比于穷举法,Selective Search可以减少一部分的计算量。
2.2)特征提取及分类
R-CNN需要将候选区域缩放至统一大小,再使用CNN提取特征。提取出特征后使用SVM进行分类,最后通过非极大值抑制输出结果。
R-CNN的训练可分为下面四步:
⚪在数据集上训练CNN。R-CNN论文中使用的是AlexNet网络模型,数据集为ImageNet。
⚪在目标检测的数据集上,对训练好的CNN做微调。
⚪用Selective Search搜索候选区域,统一使用微调后的CNN对这些区域进行特征提取,并将提取到的特征存储起来。
⚪使用存储起来的特征,训练SVM分类器。
尽管R-CNN的识别框架与传统方法的区别不是很大,但得益于CNN优异的特征提取能力,R-CNN的效果还是比传统方法好很多。但是R-CNN的缺点也很明显,计算量大,训练耗时。这些弊端都会在后续的Fast R-CNN、Faster R-CNN中得到一定的解决。