文章目录
1.从git上安装及单机配置和启动zk
安装包可以从官网中获得,示例中使用的安装包是zookeeper-3.4.12.tar.gz,同样将其复制到/opt目录下,然后解压缩,参考如下:
向/etc/profile配置文件中添加如下内容,并执行source/etc/profile命令使配置生效:
第三步,修改 ZooKeeper 的配置文件。首先进入$ZOOKEEPER_HOME/conf 目录,并将zoo_sample.cfg文件修改为zoo.cfg:
然后修改zoo.cfg配置文件,zoo.cfg文件的内容参考如下:




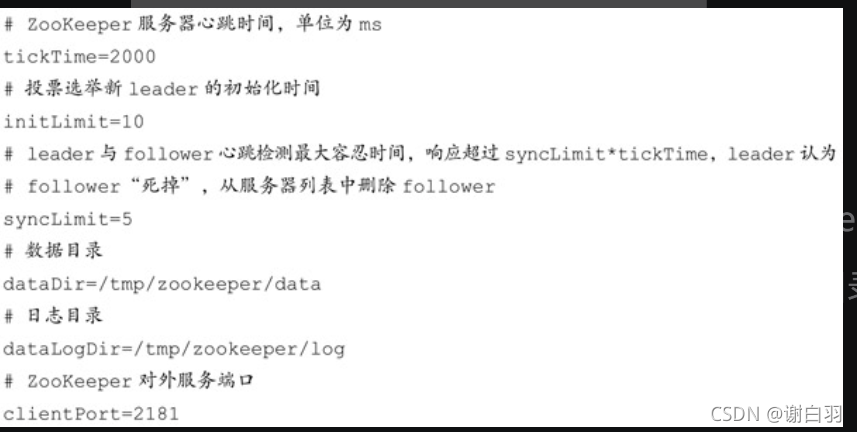
默认情况下,Linux系统中没有/tmp/zookeeper/data和/tmp/zookeeper/log这两个目录,所以接下来还要创建这两个目录

第四步,在${dataDir}目录(也就是/tmp/zookeeper/data)下创建一个myid文件,并写入一个数值,比如0。myid文件里存放的是服务器的编号。
第五步,启动Zookeeper服务,详情如下:

可以通过zkServer.sh status命令查看Zookeeper服务状态,示例如下:

以上是关于ZooKeeper单机模式的安装与配置,一般在生产环境中使用的都是集群模式,集群模式的配置也比较简单,相比单机模式而言只需要修改一些配置即可
2.zk集群的搭建
1)简历域名映射
首先在这3台机器的/etc/hosts文件中添加3台集群的IP地址与机器域名的映射,示例如下(3个IP地址分别对应3台机器):

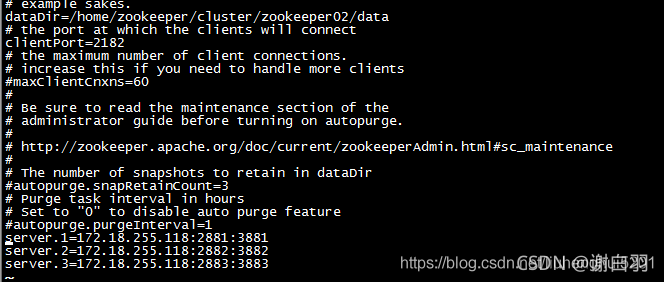
2)修改三台zk的配置(zoo.cfg里面修改)
传送门:有个哥们写的很好

类似下面的图片
(端口记得防火墙设置下)
3)启动zk服务器
为了便于讲解上面的配置,这里抽象出一个公式,即 server.A=B:C:D。其中 A 是一个数字,代表服务器的编号,就是前面所说的myid文件里面的值。集群中每台服务器的编号都必须唯一,所以要保证每台服务器中的myid文件中的值不同。B代表服务器的IP地址。C表示服务器与集群中的 leader 服务器交换信息的端口。D 表示选举时服务器相互通信的端口。如此,集群模式的配置就告一段落,可以在这3台机器上各自执行zkServer.sh start命令来启动服务。
3.安装并单机配置kafka
1)安装及配置kafka
在安装完JDK和ZooKeeper之后,就可以执行Kafka broker的安装了,首先也是从官网中下载安装包,示例中选用按照包的是kafka_2.11-2.0.0.tgz,将其复制至/opt目录下并进行解压缩,示例如下:

接下来需要修改broker的配置文件$KAFKA_HOME/conf/server.properties。主要关注以下几个配置参数即可:

如果是单机模式,那么修改完上述配置参数之后就可以启动服务。如果是集群模式,那么只需要对单机模式的配置文件做相应的修改即可:确保集群中每个broker的broker.id配置参数的值不一样,以及listeners配置参数也需要修改为与broker对应的IP地址或域名,之后就可以各自启动服务。注意,在启动Kafka 服务之前同样需要确保 zookeeper.connect参数所配置的ZooKeeper服务已经正确启动。
2)启动kafka
启动Kafka服务的方式比较简单,在$KAFKA_HOME目录下执行下面的命令即可:
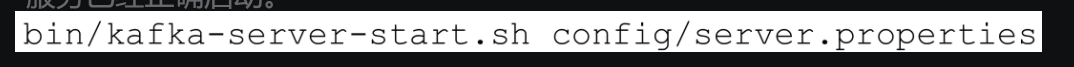
如果要在后台运行Kafka服务,那么可以在启动命令中加入-daemon参数或&字符,示例如下:

可以通过jps命令查看Kafka服务进程是否已经启动,示例如下:

jps命令只是用来确认Kafka服务的进程已经正常启动。它是否能够正确地对外提供服务,还需要通过发送和消费消息来进行验证
4.kafka的生产和消费
1)创建主题
创建一个分区数为 4、副本因子为 3 的主题topic-demo,示例如下:

- 命令:
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --create --topic topic-demo --replication-factor 3 --partitions 4
- 参数说明
--zookeeper指定了Kafka所连接的ZooKeeper服务地址
--topic指定了所要创建主题的名称
--replication-factor 指定了副本因子
--partitions 指定了分区个数
--create是创建主题的动作指令
--describe 还可以通过这个展示主题的更多具体信息
2)发送和消费信息
创建主题topic-demo之后我们再来检测一下Kafka集群是否可以正常地发送和消费消息
- 消费者订阅主题
通过kafka-console-consumer.sh脚本来订阅主题topic-demo,示例如下

- 命令:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic-demo
- 参数说明
--bootstrap-server指定了连接的Kafka集群地址
--topic指定了消费者订阅的主题
(目前主题topic-demo尚未有任何消息存入,所以此脚本还不能消费任何消息。)
- 发送信息到相关主题
我们再打开一个shell终端,然后使用kafka-console-producer.sh脚本发送一条消息“Hello,Kafka!”至主题topic-demo,示例如下:

- 命令:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-demo
(生产对应主题的消息)
- 参数说明:
--broker-list指定了连接的Kafka集群地址
--topic指定了发送消息时的主题
(示例中的第二行是通过人工键入的方式输入的,按下回车键后会跳到第三行,即“>”字符处)
此时原先执行 kafka-console-consumer.sh脚本的 shell终端中出现了刚刚输入的消息“Hello,Kafka!”,示例如下(
订阅的地方出现了hello)

- 备注
读者也可以通过输入一些其他自定义的消息来熟悉消息的收发及这两个脚本的用法。不过这两个脚本一般用来做一些测试类的工作,在实际应用中,不会只是简单地使用这两个脚本来做复杂的与业务逻辑相关的消息生产与消费的工作,具体的工作还需要通过编程的手段来实施。
5.kafka服务器参数配置
Kafka 安装与配置的说明中只是简单地表述了几个必要的服务端参数而没有对其进行详细的介绍,并且Kafka服务端参数(broker configs)也并非只有这几个。Kafka服务端还有很多参数配置,涉及使用、调优的各个方面,虽然这些参数在大多数情况下不需要更改,但了解这些参数,以及在特殊应用需求的情况下进行有针对性的调优,可以更好地利用 Kafka为我们工作。下面挑选一些重要的服务端参数来做细致的说明,这些参数都配置在
$KAFKA_HOME/config/server.properties文件中。
1.zookeeper.connect
举例填写:
zookeeper.connect=localhost:2181/kafka
说明:
1)可以配置为localhost:2181,如果ZooKeeper集群中有多个节点,则可以用逗号将每个节点隔开,类似于 localhost1:2181,localhost2:2181,localhost3:2181这种格式。
2)最佳的实践方式是再加一个chroot路径,这样既可以明确指明该chroot路径下的节点是为Kafka所用的,也可以实现多个Kafka集群复用一套ZooKeeper集群,这样可以节省更多的硬件资源。包含 chroot 路径的配置类似于 localhost1:2181,localhost2:2181,localhost3:2181/kafka这种,如果不指定chroot,那么默认使用ZooKeeper的根路径
------------------------------
2.listeners和advertised.listeners
举例填写:
listener=PLAINTEXT://172.17.0.52:9002
说明:
1)该参数指明broker监听客户端连接的地址列表,即为客户端要连接broker的入口地址列表,配置格式为protocol1://hostname1:port1,protocol2://hostname2:port2,其中protocol代表协议类型,Kafka当前支持的协议类型有PLAINTEXT、SSL、SASL_SSL等,如果未开启安全认证,则使用简单的PLAINTEXT即可
2)hostname代表主机名,port代表服务端口,此参数的默认值为 null。比如此参数配置为PLAINTEXT://198.162.0.2:9092,如果有多个地址,则中间以逗号隔开。如果不指定主机名,则表示绑定默认网卡,注意有可能会绑定到127.0.0.1,这样无法对外提供服务,所以主机名最好不要为空;如果主机名是0.0.0.0,则表示绑定所有的网卡
3)与此参数关联的还有advertised.listeners,作用和listeners类似,默认值也为 null。不过advertised.listeners 主要用于 IaaS(Infrastructure as aService)环境,比如公有云上的机器通常配备有多块网卡,即包含私网网卡和公网网卡,对于这种情况而言,可以设置advertised.listeners参数绑定公网IP供外部客户端使用,而配置listeners参数来绑定私网IP地址供broker间通信使用
------------------------------
3.broker.id
举例填写:
broker.id=2
说明:
1)该参数用来指定Kafka集群中broker的唯一标识,默认值为-1。如果没有设置,那么Kafka会自动生成一个
2)这个参数还和meta.properties文件及服务端参数broker.id.generation.enable和reserved.broker.max.id有关
------------------------------
4.log.dir和log.dirs
举例填写:
log.dirs=/root/3rd/kafka_2.11-2.3.0/log
说明:
1)Kafka 把所有的消息都保存在磁盘上,而这两个参数用来配置Kafka 日志文件存放的根目录
2)一般情况下,log.dir 用来配置单个根目录,而 log.dirs 用来配置多个根目录(以逗号分隔),但是Kafka并没有对此做强制性限制,也就是说,log.dir和log.dirs都可以用来配置单个或多个根目录
3)log.dirs 的优先级比 log.dir 高,但是如果没有配置log.dirs,则会以 log.dir 配置为准。默认情况下只配置了log.dir 参数,其默认值为/tmp/kafka-logs
------------------------------
5.message.max.bytes(在3.4.6版本中是socket.request.max.bytes:套接字将会接收的数据大小,做限制防止被OOM)
举例填写:
socket.request.max.bytes=104857600
socket.send.buffer.bytes=102400 //一次发socket的数据量100k
说明:
1)该参数用来指定broker所能接收消息的最大值,默认值为1000012(B),约等于976.6KB。如果 Producer 发送的消息大于这个参数所设置的值,那么(Producer)就会报出RecordTooLargeException的异常
2)如果需要修改这个参数,那么还要考虑max.request.size (客户端参数)、max.message.bytes(topic端参数)等参数的影响。为了避免修改此参数而引起级联的影响,建议在修改此参数之前考虑分拆消息的可行性。