系列文章目录
第1天:读入数据
第2天:read()、readline()与readlines()
第3天:进度条(tqdm模块)
第4天:命令行传参(argparse模块)
第5天:读、写json文件(load()、loads()、dump()、dumps())
第6天:os模块、glob模块
第7天:pandas.DataFrame
第8天:DataFrame的三种数据处理基本操作(df.drop(), df.fillna(), df.drop_duplicates())
python数据分析学习第9天记录
前言
昨天我们学习了pandas模块中DataFrame的三种基本数据处理操作,并给出了实例。今天继续学习pandas模块下对数据处理的另外两种操作:
- 将值转换为属性/特征
- 数据合并、连接(merge,join,concat)
一、今天所学的内容
主要内容为pandas模块如何对DataFrame这一数据类型进行将数据输入模型前的预处理工作。
二、知识点详解
2.1 将值转换为属性/特征
在进行数据分析的过程中我们常常需要将值转换为属性或者特征。比如,会将性别这一列会出现的两个值:“男”、“女”转换成0和1,便于后续数据模型的分析与操作。
那么接下来我们就分析一下离散特征的编码。什么是离散特征(变量)呢?简单来说,就是指其数值只能用自然数、整数、计数单位等描述的数据。例如,职工个数(总不能是1.2个吧),成绩A+等。
那么离散特征的编码分为两种情况:
1、离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码
2、离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}
本文先讲解取值之间没有大小意义的编码方式,使用pandas可以很方便的对离散型特征进行one-hot编码。
让我们举例说明吧~
先来创建一个DataFrame:(如果这个地方忘记参数怎么设置,请参考上一篇)
import pandas as pd
data = {
"姓名":["张三","李四","王五","Luliu","XIAOQIQI"],
"年龄":["18","20","19","20","17"],
"专业":["计算机","网络工程","物联网工程","通信工程","电子"],
"成绩":["95","90","88","89","93"]
}
df = pd.DataFrame(data, index = ["1","2","3","4","5"],
columns = ["姓名","年龄","专业","成绩"])
print(df.head())
上面这段代码定义了一个pandas的DataFrame。现在我们要对“专业”这一列进行编码。
y = pd.get_dummies(df.专业, prefix='专业')
print(y.head())
执行结果如下:
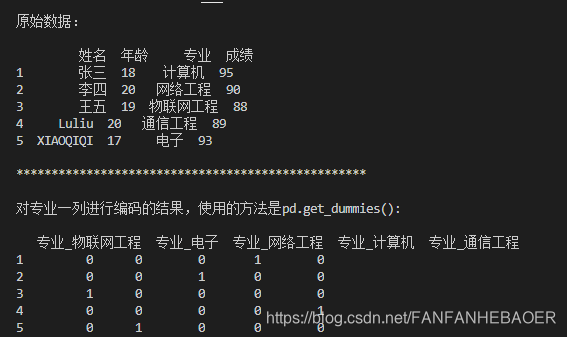
结果图的上半部分是原始数据,下面是对专业这一属性进行编码的结果。
get_dummies 是利用pandas实现one hot encode的方式。详细参数请查看官方文档吧~
这里插播一句,代码执行结果可能看起来不太美观,因为是直接在终端执行的。如果追求更清晰更美观的结果展示,可以用vs code最近支持的jupyter notebooks。配置很方便,很好用。接下来我会专门更新一篇配置方式与基本使用。
继续讲解属性编码。在对特定的列:”专业“ 编码后,可以将其合并到元数据中。
合入代码如下:(pd.join()下面讲到,不熟悉的 同学可以先看下面内容,再回过头来看这里)
df = df.join(pd.get_dummies(df.专业))
合入结果就是这样啦:

是不是很简单~
2.2 数据合并、连接(merge,join,concat)
在数据处理的过程中,常常需要对数据进行连接、合并操作。这一小节就来说说数据拼接那些事儿。
首先我们来了解三个函数的用法,在过程中学会数据合并和连接:merge()、join()、concat()。
2.2.1 merge()
pandas提供了一个类似于关系数据库的连接(join)操作的方法merage,可以根据一个或多个键将不同DataFrame中的行连接起来
语法如下:
merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False)
用于通过一个或多个键将两个数据集的行连接起来,类似于 SQL 中的 JOIN。
该函数的典型应用场景是:针对同一个主键存在两张包含不同字段的表,现在我们想把他们整合到一张表里。在此典型情况下,结果集的行数并没有增加,列数则为两个元数据的列数和减去连接键的数量。
只看函数语法的话会觉得过于复杂,我刚开始学习的时候也有点懵。不过其实掌握这个函数最常见的方法就可以了。
为了使用df.merge() ,我们需要再定义一个dataframe:
df2 = pd.DataFrame({
'姓名':['XIAODUDU','皮卡丘','王麻子',"张三","李四"],
'年级':[1,2,3,4,5]})
可以从构造的 新数据看出,我们定义了姓名到年级的一个映射,在姓名这个列表中又定义了五个人,与之定义了每个人的年级。如果这时候将df2与之前定义的df做merge操作,我们使用不加任何参数的函数对其进行处理:
df3 = pd.merge(df,df2)
print(df3)
此时打印结果为:

也就是说,df.merge()在默认情况下是对两个dataframe中都有的列进行属性值的相同查询,如果 属性值相同,则将该行打印到新的dataframe。所以我们先定义的df和后定义的df2在“姓名”这一列中属性值的交集为:[“张三”, ‘李四“’],所以python会自动将这两行的内容整合到新的dataframe中。
那么到这里我们初步掌握了df.merge()。此时也许还是没办法解决同学们的需求,也许两个初始的dataframe中相同索引值的属性列不值一列,那么到时候按照哪个键值来进行排序,都是可以选择的。预知后事如何,请听下次分解!~
2.2.1 join()
join方法提供了一个简便的方法用于将两个DataFrame中的不同的列索引合并成为一个DataFrame。函数语法如下:
join(self, other, on=None, how='left', lsuffix='', rsuffix='',sort=False):
直接看函数语法看不出太多东西。很多知识都需要反复实践才能记得更牢固。因此,也是举一个pd.join()的例子吧~
首先还是定义一个新的dataframe。先来回顾一下原来的数据:

我们先定义一个与上面数据毫不相关的的dataframe:
df3 = pd.DataFrame({
'面积':['122','78','135',"88","64"],
'年级':[1,2,3,4,5]})
df4 = df.join(df3)
print(df4)
运行结果如下:
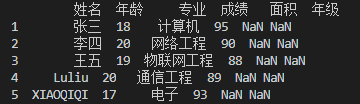
毫无灵魂的数据合并呐!
所以两个dataFrame不能完全不相干。那么应该怎样定义两个数据dataFrame才可以使用join函数呢?
经过多角度学习,我觉得总结的不错的博客摘抄如下(链接地址:http://www.srcmini.com/30938.html,侵删):
当我们想要串联我们的DataFrame时, 我们可以通过垂直或并排堆叠它们来相互添加。组合这些DataFrame的另一种方法是在每个数据集中使用包含公用值的列。使用公共字段组合DataFrame的方法称为”连接”。我们用于组合DataFrame的方法是join()方法。包含公用值的列称为”联接键”。
当一个DataFrame是一个查找表, 其中包含添加到另一个DataFrame中的其他数据时, join()方法通常很有用。这是一种方便的方法, 可以将两个索引不同的DataFrame的列合并为一个DataFrame。
也就是说,要想发挥join()的作用,必须在两张dataFrame查找表中的数据是有重叠部分的。
所以我们再举一个可以使用join()函数的例子,来演示一下join()函数的工作方式:
import pandas as pd
df1 = pd.DataFrame({
'姓名': ['XIAODUDU','皮卡丘','王麻子',"张三","李四"], '年级':[1,2,3,4,5]})
df2 = pd.DataFrame({
'姓名': ["张三","李四","王五","Luliu","XIAOQIQI"], "成绩":["95","90","88","89","93"]})
df_join = df1.join(df2.set_index('姓名'), on='姓名')
print(df_join)
结果如下:
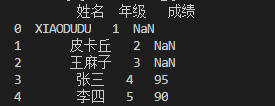
是不是稍微理解了join()函数的工作方式?可以看出,上面姓名这一列是按照df1的属性值来罗列的。我们也可以让连接结果显示两个dataframe中某一列的并集,或者按照df2的姓名的属性值罗列。怎么做到呢?
取决于两个参数:
lsuffix:它是指具有默认值””的字符串对象。它使用左框架重叠列中的后缀。
rsuffix:它是指一个字符串值, 其默认值为””。它使用右框架重叠列中的后缀。
我们执行下面这行代码:
print(df1.join(df2, lsuffix='_df1', rsuffix='_df2'))
执行结果如下:
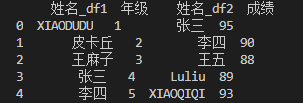
可以看到, 当我们定义了lsuffix、rsuffix时,会将这两张表机械地连接在一起。好了,join()函数就先简单介绍到这里啦。
2.2.3 concat()
concat()的用法先简单举一个例子吧:
df_concat = pd.concat([df1,df2])
print(df_concat)
结果如下:
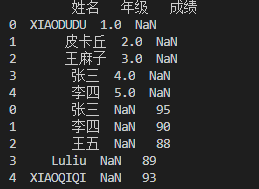
可以看出就是单纯地把两个dataframe连接在了一起。至于加上参数的变形,则需要认真阅读一下pandas这部分的官方文档啦。
总结
昨天对DataFrame的三种基本操作进行了学习,今天介绍了DataFrame的两种数据处理基本操作: 将值转换为属性/特征、数据合并/连接操作。
那么今天就到这里了,明天继续为大家带来DataFrame的数据处理操作。list如下:
- 排序,排名
- 索引重置
祝大家变得更强,明天见!
今天的小tips:
- 运动是一项坚持一段时间就会爱上的习惯。每天锻炼一会儿,也会让大脑更活跃。