爬虫在我看来就是从一个接口找到下一个接口,不断的找到接口最终找到自己想要的
博主自小喜欢看漫画,这个图片爬虫自然要拿漫画来开刀。
首先,自然是导入各种各样的库
包含requests、BeautifulSoup、os
import requests
from bs4 import BeautifulSoup
import os
headers={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36"}#读写头
all_url='http://www.manhuatai.com/'#读写头,拟人化,越完善越好
start_html=requests.get(all_url,headers=headers)#获取网页内容
start_html.encoding='utf-8'#防止出现乱码有时候可以gbk换着用
Soup=BeautifulSoup(start_html.text,'lxml')#万能的beautifulsoup解析
print(Soup)
运行成功
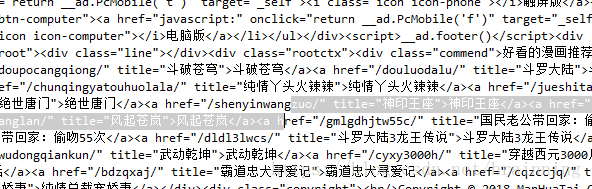
瞅准编辑推荐
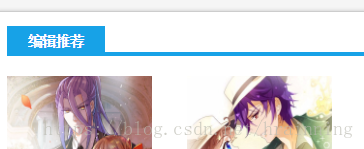
打开浏览器看看他们都放在哪
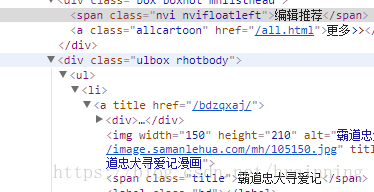
可以发现漫画们都在<div>里的class="ulbox rhotbody"下的<a>中
获取所有在此栏目下的网址以及作品名
import requests
from bs4 import BeautifulSoup
import os
headers={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36"}#读写头,拟人化,越完善越好
all_url='http://www.manhuatai.com/'#网址
start_html=requests.get(all_url,headers=headers)#获取网页内容
start_html.encoding='utf-8'#防止出现乱码有时候可以gbk换着用
Soup=BeautifulSoup(start_html.text,'lxml')#万能的beautifulsoup解析
#print(Soup)
all_a=Soup.find('div',class_="ulbox rhotbody").find_all('a')
for a in all_a:
title=a.get_text()
href=a['href']
print(href,title)
使用老套路
运行一下结果怎么好像有点不对。。。。

经过重重努力,最终放弃作品名保留网址就够,反正拼音也够用
import requests
from bs4 import BeautifulSoup
import os
headers={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36"}#读写头
all_url='http://www.manhuatai.com/'#网址
start_html=requests.get(all_url,headers=headers)#获取网页内容
start_html.encoding='utf-8'#防止出现乱码有时候可以gbk换着用
Soup=BeautifulSoup(start_html.text,'lxml')#万能的beautifulsoup解析
#print(Soup)
all_a=Soup.find('div',class_="ulbox rhotbody").find_all('a')
for a in all_a:
href=a['href']
print(href)
但是这些网址还不完整,把他拼全,然后在解析获取一波
import requests
from bs4 import BeautifulSoup
import os
headers={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36"}#读写头
all_url='http://www.manhuatai.com/'#网址
start_html=requests.get(all_url,headers=headers)#获取网页内容
start_html.encoding='utf-8'#防止出现乱码有时候可以gbk换着用
Soup=BeautifulSoup(start_html.text,'lxml')#万能的beautifulsoup解析
#print(Soup)
all_a=Soup.find('div',class_="ulbox rhotbody").find_all('a')
for a in all_a:
href=a['href']
#print(href)
lage_url=all_url+href[1:]
#print(lage_url)
lage_url_get=requests.get(lage_url,headers=headers)
lage_url_soup=BeautifulSoup(lage_url_get.text,'lxml')
print(lage_url_soup)
这样就可以接着进行下去了
点第一个漫画进去自己想要的所有章节的网址
从表面上来看,这次有规律多了
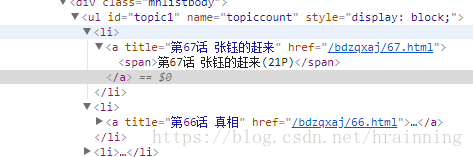
好家伙这次总能让我抓标题了
这次很开心的瞬间码上,发现又出错了。。。。
import requests
from bs4 import BeautifulSoup
import os
headers={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36"}#读写头
all_url='http://www.manhuatai.com/'#网址
start_html=requests.get(all_url,headers=headers)#获取网页内容
start_html.encoding='utf-8'#防止出现乱码有时候可以gbk换着用
Soup=BeautifulSoup(start_html.text,'lxml')#万能的beautifulsoup解析
#print(Soup)
all_a=Soup.find('div',class_="ulbox rhotbody").find_all('a')
for a in all_a:
href=a['href']
#print(href)
lage_url=str(all_url)+href[1:] #没有str TypeError: can only concatenate list (not "str") to list
#print(lage_url)
lage_url_get=requests.get(lage_url,headers=headers)
lage_url_soup=BeautifulSoup(lage_url_get.text,'lxml')
#print(lage_url_soup)
all_url=lage_url_soup.find('div',class_='mhlistbody').find_all('a')
for a_a in all_url:
title=a_a.get_text()
href_s=a_a.get('href')
print(title,href_s)

经过各方打探,知道了是切片出现了问题(split函数)但是无法修改呀,所以我选择强行把切片的步骤删了,直接将一级网址拼接。于是就解决了。
import requests
from bs4 import BeautifulSoup
import os
headers={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36"}#读写头
all_url='http://www.manhuatai.com/'#网址
start_html=requests.get(all_url,headers=headers)#获取网页内容
start_html.encoding='utf-8'#防止出现乱码有时候可以gbk换着用
Soup=BeautifulSoup(start_html.text,'lxml')#万能的beautifulsoup解析
#print(Soup)
all_a=Soup.find('div',class_="ulbox rhotbody").find_all('a')
for a in all_a:
href=a['href']
#print(href)
lage_url='http://www.manhuatai.com'+href#href直接就是str
#print(lage_url)
lage_url_get=requests.get(lage_url,headers=headers)
lage_url_soup=BeautifulSoup(lage_url_get.text,'lxml')
#print(lage_url_soup)
all_url=lage_url_soup.find('div',class_='mhlistbody').find_all('a')
for a_a in all_url:
title=a_a.get_text()
href_s=a_a.get('href')
print(title,href_s)

好了,终于又可以继续了
点开一个章节,寻找每一张图的地址(依然是老方法find包含所有图片的上一级然后find_all)
finalist_url=lage_url+href_s[1:]#拼接
print(finalist_url)
先在最后一行悄悄加上这两行看看是不是又错了,没想到一次成功了,可以继续贴代码了
import requests
from bs4 import BeautifulSoup
import os
headers={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36"}#读写头
all_url='http://www.manhuatai.com/'#网址
start_html=requests.get(all_url,headers=headers)#获取网页内容
start_html.encoding='utf-8'#防止出现乱码有时候可以gbk换着用
Soup=BeautifulSoup(start_html.text,'lxml')#万能的beautifulsoup解析
#print(Soup)
all_a=Soup.find('div',class_="ulbox rhotbody").find_all('a')
for a in all_a:
href=a['href']
#print(href)
lage_url='http://www.manhuatai.com'+href#href直接就是str
#print(lage_url)
lage_url_get=requests.get(lage_url,headers=headers)
lage_url_soup=BeautifulSoup(lage_url_get.text,'lxml')
#print(lage_url_soup)
all_url=lage_url_soup.find('div',class_='mhlistbody').find_all('a')
for a_a in all_url:
title=a_a.get_text()
href_s=a_a.get('href')
#print(title,href_s)
finalist_url=lage_url+href_s[1:]
#print(finalist_url)
finalist_url_get=requests.get(finalist_url,headers=headers)
finalist_url_soup=BeautifulSoup(finalist_url_get.text,'lxml')
picture_url=finalist_url_soup.find_all('img')
print(picture_url)
直接找到最细致的地方瞅瞅,

什么。。又找不到
退回到更大的区间看看哪出问题了,
import requests
from bs4 import BeautifulSoup
import os
headers={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36"}#读写头
all_url='http://www.manhuatai.com/'#网址
start_html=requests.get(all_url,headers=headers)#获取网页内容
start_html.encoding='utf-8'#防止出现乱码有时候可以gbk换着用
Soup=BeautifulSoup(start_html.text,'lxml')#万能的beautifulsoup解析
#print(Soup)
all_a=Soup.find('div',class_="ulbox rhotbody").find_all('a')
for a in all_a:
href=a['href']
#print(href)
lage_url='http://www.manhuatai.com'+href#href直接就是str
#print(lage_url)
lage_url_get=requests.get(lage_url,headers=headers)
lage_url_soup=BeautifulSoup(lage_url_get.text,'lxml')
#print(lage_url_soup)
all_url=lage_url_soup.find('div',class_='mhlistbody').find_all('a')
for a_a in all_url:
title=a_a.get_text()
href_s=a_a.get('href')
#print(title,href_s)
finalist_url=lage_url+href_s[1:]
#print(finalist_url)
finalist_url_get=requests.get(finalist_url,headers=headers)
finalist_url_get.encoding='gkb'#居然又有乱码????换一个用
finalist_url_soup=BeautifulSoup(finalist_url_get.text,'lxml')
picture_url=finalist_url_soup.find('body')
print(picture_url)
结果

很好,整了半天,惨遭反爬,一句,mmp。眼睁睁的看着图片的地址却无法动它分毫
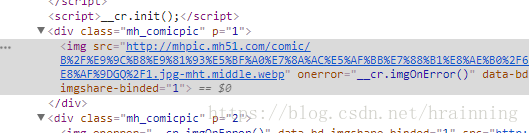
依旧不甘心,一步一步往前回溯,用浏览器登上我自己拼接出的网址,仔细一看,原来拼错了

多了个bdzqxaj/但是别的漫画标题字符个数不一致,这时候就不能再用切片了,这时候掏出了re模块
这时候变成了这样
import requests
from bs4 import BeautifulSoup
import os
import re
headers={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36"}#读写头
all_url='http://www.manhuatai.com/'#网址
start_html=requests.get(all_url,headers=headers)#获取网页内容
start_html.encoding='utf-8'#防止出现乱码有时候可以gbk换着用
Soup=BeautifulSoup(start_html.text,'lxml')#万能的beautifulsoup解析
#print(Soup)
all_a=Soup.find('div',class_="ulbox rhotbody").find_all('a')
for a in all_a:
href=a['href']
#print(href)
lage_url='http://www.manhuatai.com'+href#href直接就是str
#print(lage_url)
lage_url_get=requests.get(lage_url,headers=headers)
lage_url_soup=BeautifulSoup(lage_url_get.text,'lxml')
#print(lage_url_soup)
all_url=lage_url_soup.find('div',class_='mhlistbody').find_all('a')
for a_a in all_url:
title=a_a.get_text()
href_s=a_a.get('href')
#print(title,href_s)
finalist_url=lage_url+re.sub("\D",'',href_s)+".html"
#print(finalist_url)
url_headers = {
'Referer':finalist_url,
'Accept': 'image/webp,image/apng,image/*,*/*;q=0.8',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 UBrowser/6.1.2107.204 Safari/537.36'
}
finalist_url_get=requests.get(finalist_url,headers=url_headers)
finalist_url_get.encoding='gbk'#再次出现乱码,只好再次使用,没想到utf-8无效了换成gbk
print(finalist_url)
可以看见,网址都被抠出来了
由于此网址里的图片都是通过浏览而实时加载,且这些图片的地址都具有规律,因此再次拼接。。。但是之中都找不到,再此放弃待我学成归来