
文章目录
Abstract
- 可以说,深度学习最成功的案例之一就是迁移学习。在丰富的源集(例如 ImageNet)上预训练网络可以帮助提高性能,一旦在通常小得多的目标集上进行微调,这一发现对语言和视觉领域的许多应用程序都有帮助
- 然而,人们对其在 3D 点云理解中的有用性知之甚少。考虑到在 3D 中注释数据所需的工作量,我们认为这是一个机会
- 在这项工作中,我们旨在促进对 3D 表示学习的研究。与之前的工作不同,我们专注于高级场景理解任务(high-level scene understanding tasks)
- 为此,我们选择了一套不同的数据集和任务来衡量无监督预训练对大量 3D 场景源集的影响
- 我们的发现非常令人鼓舞:使用统一的三元组架构、源数据集和对比损失进行预训练,我们在室内和室外、真实和合成数据集的 6 个不同基准上实现了最近在分割和检测方面的最佳结果——证明学习的表示可以跨域泛化
- 此外,这种改进类似于有监督的预训练,这表明未来的努力应该有利于扩展数据收集而不是更详细的注释。
- 我们希望这些发现将鼓励对 3D 深度学习的无监督代理任务设计进行更多研究。我们的代码在 https://github.com/facebookresearch/PointContrast 上公开可用
Keywords: Unsupervised Learning, Point Cloud Recognition, Representation Learning, 3D Scene Understanding
1 Introduction
- 表征学习是深度学习研究的主要驱动力之一
- 在 2D 视觉中,在丰富的源集(例如 ImageNet 分类)上预训练网络可以帮助提高性能,一旦在通常小得多的目标集上进行微调,这一发现是许多应用程序成功的关键。
- 一个特别重要的设置是预训练阶段是无监督的,因为这开辟了利用实际上无限的训练集大小的可能性
- 无监督预训练在自然语言处理方面取得了显着的成功 [49, 13],并且最近在 2D 视觉中引起了越来越多的关注 [42, 3, 27, 63, 23, 42, 3, 40, 27, 69, 28, 87, 8]
- 在过去的几年里,随着 3D 表示学习方案数量的不断增加,3D 深度学习领域取得了长足的进步 [1, 16, 74, 21, 36, 67, 22, 15, 81, 12, 9]
- 然而,与 2D 相比,它仍然落后,显然,在所有 3D 场景理解任务中,从头开始对目标数据进行临时训练仍然是占主导地位的方法。值得注意的是,所有现有的表示学习方案都在单个对象或低级任务(例如配准)上进行了测试。
- 这种现状可以归因于多种原因:1)缺乏大规模和高质量的数据:与 2D 图像相比,3D 数据更难收集,标记成本更高,并且传感设备的多样性可能会引入剧烈的域差距(domain gaps); 2) 缺乏统一的骨干架构:与 2D 视觉相比,ResNets 等架构已被证明成功地作为用于预训练和微调的骨干网络,点云网络架构设计仍在不断发展; 3)缺乏一套全面的数据集和高层次的评估任务(high-level tasks)
- 具体来说,我们选择== ScanNet [11] 作为我们进行预训练的源集==,并在我们所有的实验中利用稀疏残差 U-Net (sparse residual U-Net )[51, 9] 作为主干架构,并专注于 3D 数据的点云表示
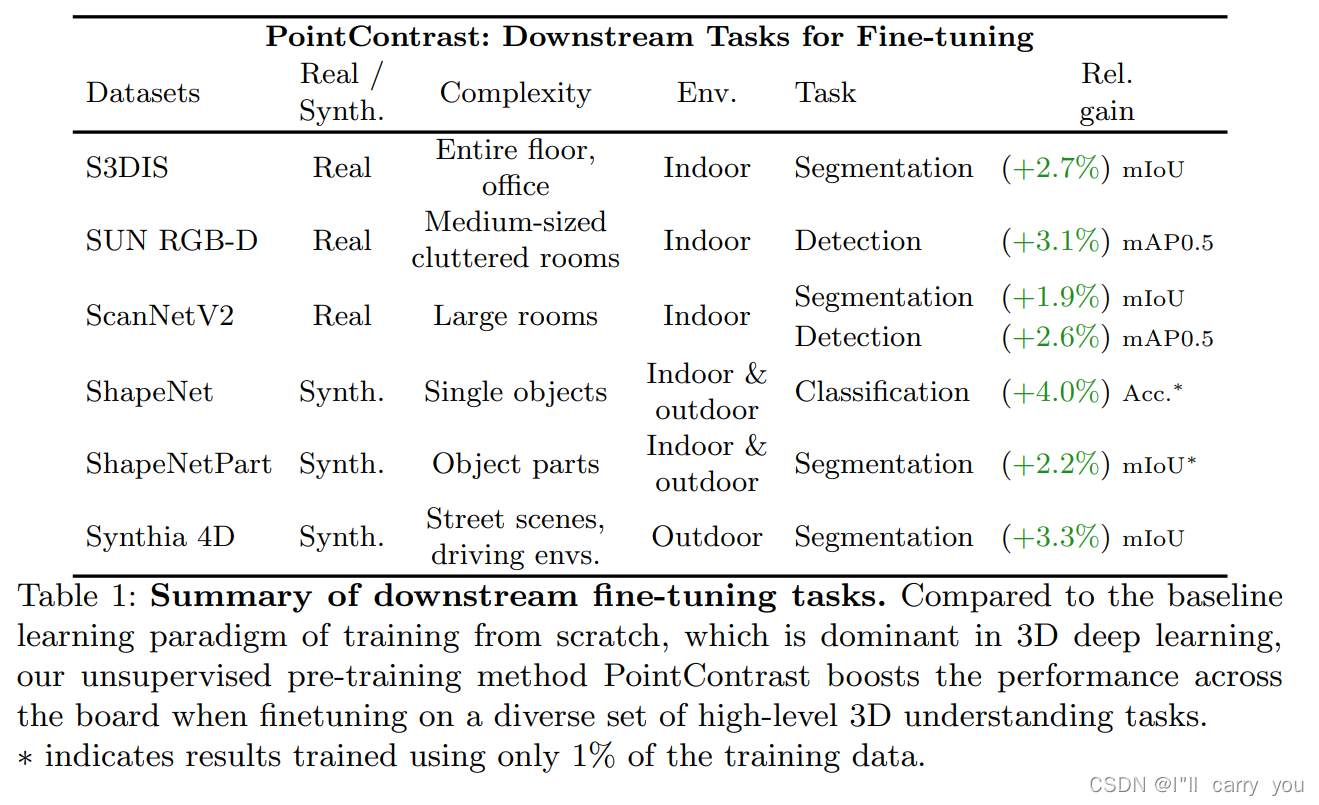
- 对于预训练目标,我们评估了两种不同的对比损失:Hardest-contrastive loss [10] 和 PointInfoNCE——InfoNCE 损失 [42] 的扩展,用于 2D 视觉的预训练。接下来,我们选择一组广泛的目标数据集和下游任务,包括:S3DIS [2]、ScanNetV2 [11]、ShapeNetPart [77] 和 Synthia 4D [52] 上的语义分割; SUN RGB-D [57, 55, 32, 70] 和 ScanNetV2 上的目标检测
- 值得注意的是,我们的结果表明所有数据集和任务的性能都有所提高(有关结果的总结,请参见表 1)。此外,我们发现在监督下进行预训练的优势相对较小。这意味着未来为预训练收集数据的努力应该有利于规模化而不是精确的注释
- 我们的贡献可以总结如下:
- 我们首次评估了 3D 点云中学习表示到高级场景理解的可迁移性。
- 我们的结果表明,无监督预训练提高了下游任务和数据集的性能,同时使用单一的统一架构、源集和目标函数
- 在无监督预训练的支持下,我们在 6 个不同的基准上实现了新的最先进的性能。
- 我们相信这些发现将鼓励我们改变处理 3D 识别的范式,并推动对 3D 表示学习的更多研究
2 Related work
-
Representation learning in 3D
- 众所周知,深度神经网络需要大量数据。这使得在数据集和任务之间迁移学习表示的能力非常强大。
- 在 2D 视觉中,人们对寻找最佳代理无监督任务的兴趣激增 [43, 83, 84, 14, 41, 18, 5, 42, 3, 40, 27, 69, 28, 87, 8, 10] .
- 我们注意到,虽然其中许多任务是低级的(例如像素或补丁级重建),但它们是根据它们对高级任务(如对象检测)的可迁移性进行评估的。
- 由于难以注释,3D 任务可能是无监督和迁移学习的最大受益者。这在一些关于单对象任务的工作中得到了展示,例如重建、分类和部分分割(reconstruction, classification and part segmentation) [1, 16, 74, 21, 36, 67, 22, 53]。
- 然而,通常很少关注超出单对象级别的 3D 表示学习。此外,在少数研究它的案例中,重点是配准(registration)等低级任务[15,81,12]。
- 相比之下,在这里我们希望通过关注可迁移性到更复杂场景的更高级任务来推动 3D 表示学习的研究。
-
Deep architectures for point cloud processing
- 在这项工作中,我们专注于学习点云数据的有用表示。
- 受 2D 领域成功的启发,我们推测实现这种进步的一个重要因素是神经架构的明显标准化。典型的例子包括 VGGNet [56] 和 ResNet/ResNeXt [26, 71]。
- 相比之下,点云神经网络设计还不够成熟,最近提出的大量新架构就可以看出这一点
- 这有多种原因。首先,是处理无序集的挑战 [47, 50, 80, 39]。其次,邻域聚合机制的选择可以是分层(hierarchical)的 [48, 33, 82, 16, 35],类似空间 CNN (spatial CNN-like)的 [30, 73, 37, 85, 59],光谱(spectral) [78, 62, 65]或基于图(graph-based)的 [72, 64, 68, 54]。最后,由于这些点是潜在 表面的离散样本,因此还考虑了连续卷积(continuous convolutions) [66,4,75]。
- 最近 Choy 等人。提出了 Minkowski Engine [9],这是子流形稀疏卷积网络 [20] 向更高维度的扩展。特别是,稀疏卷积网络有助于采用来自 2D 视觉的常见深度架构,这反过来又有助于标准化点云的深度学习。
- 在这项工作中,我们在所有实验中使用以 Minkowski Engine作为骨干网络构建的统一 U-Net [51] 架构,并证明它可以在任务和数据集之间优雅地传输
3 PointContrast Pre-training
- 在本节中,我们将介绍我们的无监督预训练流程(pipeline)。
- 首先,为了激发新的预训练方案的必要性,我们进行了一项试点研究,以了解 3D 深度学习中现有实践(ShapeNet 上的预训练)的局限性(第 3.1 节)。
- 在简要回顾了一个鼓舞人心的局部特征学习工作 - 完全卷积几何特征(Fully Convolutional Geometric Features)(FCGF)(第 3.2 节)之后,
- 我们介绍了我们的无监督预训练解决方案 PointContrast,在代理任务(第 3.3 节)、损失函数(第 3.4 节)、网络方面架构(第 3.5 节)和预训练数据集(第 3.6 节)。
3.1 Pilot Study: is Pre-training on ShapeNet Useful?
- 以前关于无监督 3D 表示学习的工作 [1, 16, 74, 21, 36, 67, 22, 53] 主要集中在 ShapeNet [7],这是一个单对象 CAD 模型的数据集。
- 一个基本假设是,通过采用 ShapeNet 作为 3D 中的 ImageNet 对应物,在合成单个对象上学习的特征可以转移到其他现实世界的应用程序
- 在这里,我们退后一步,通过研究一个简单的监督预训练设置来重新评估这个假设:我们只需在完全监督的 ShapeNet 上预训练一个编码器网络,然后在下游任务上使用 U-Net 对其进行微调(S3DIS语义分割)。
- 遵循 2D 表示学习的实践,我们在这里使用完全监督作为可以从预训练中获得的上限
- 我们训练了 200 个 epoch 的稀疏 ResNet-34 模型(详见第 3.5 节)。该模型在 ShapeNet 分类任务上实现了 85.4% 的高验证准确率
- 在图 1 中,我们展示了 (a) 从头开始训练和 (b) 使用 ShapeNet 预训练权重进行微调的下游任务训练曲线。至关重要的是,可以观察到 ShapeNet 预训练,即使是在监督方式下,也会阻碍下游任务学习。在许多潜在的解释中,我们强调了两个主要问题:
- Domain gap between source and target data:ShapeNet 中的对象是合成的、尺度归一化的、姿势对齐的,并且缺乏场景上下文(synthetic, normalized in scale, aligned in pose, and lack scene context)。这使得预训练和微调==数据分布( data distributions)截然不同 ==
- Point-level representation matters:在 3D 深度学习中,局部几何特征,例如那些由一个点及其邻居编码的,已被证明对 3D 任务具有区分性和关键性 [47, 48]。直接对对象实例进行训练以获得全局表示可能是不够的

- 这让我们重新思考了这个问题:如果预训练的目标是提高许多现实世界任务的性能,那么探索单个对象的预训练策略可能会提供有限的潜力。 (1) 为了解决域差距(domain gap)问题,直接在具有多个对象的复杂场景上预训练网络可能是有益的,以更好地匹配目标域分布(to better match the target distributions); (2)为了捕获点级信息(point-level information),我们需要设计一个代理任务和相应的网络架构,它不仅基于实例级/全局表示,而是可以在点级捕获密集/局部特征(not only based on instance-level/global representations, but instead can capture dense/local features at the point level)
3.2 Revisiting Fully Convolutional Geometric Features (FCGF)


3.3 PointContrast as a Pretext Task
-
FCGF 只关注低级任务的局部描述符学习。相比之下,一个好的预训练代理任务旨在学习对许多高级 3D 理解任务普遍适用和有用的网络权重。
-
为了获得 FCGF 的灵感并创建这样的代理任务,需要重新审视几个设计选择
- 在架构方面,由于推理速度是配准(registration)任务的主要关注点,因此 FCGF 中使用的网络非常轻量级;==相反,预训练的成功依赖于过度参数化的网络(over-parameterized networks),这在其他领域 [13, 8] 中得到了清楚的证明。 ==
- 在数据集方面,FCGF 使用特定领域的注册(registration)数据集,例如 3DMatch [81] 和 KITTI odometry [17],这些数据集缺乏规模和通用性。
- 最后,在损失设计方面,FCGF 中探索的对比损失是为注册(registration)量身定制的,探索其他替代方案很有趣。
-
在算法 1 中,我们总结了这项工作中探索的整体代理任务框架。我们将框架命名为 PointContrast,因为这个代理任务的高级策略是在点级别上对比两个转换后的点云

-
在这项工作中,我们主要考虑刚性变换,包括旋转、平移和缩放。附录中提供了更多详细信息。
-
最后,在两个视图中的点上定义对比损失:我们最小化匹配点的距离并最大化不匹配点的距离。
-
这个框架虽然来自一个非常不同的动机(几何局部描述符的度量学习),但与最近基于对比的2D无监督视觉表示学习方法有着惊人相似的管道[69,23,8]。
-
关键区别在于,大多数 2D 工作都集中在对比实例/图像上,而在我们的工作中,对比学习是在点级别(point level)密集完成的

3.4 Contrastive Learning Loss Design
Hardest-Contrastive Loss

PointInfoNCE Loss


个人备注:为什么在算法1有Mapping ? 因为点太多了,只考虑配对的点
3.5 A Sparse Residual U-Net as Shared Backbone

backbone 是 SR-UNet 是在[9]提出来的
3.6 Dataset for Pre-training


4 Fine-tuning on Downstream Tasks

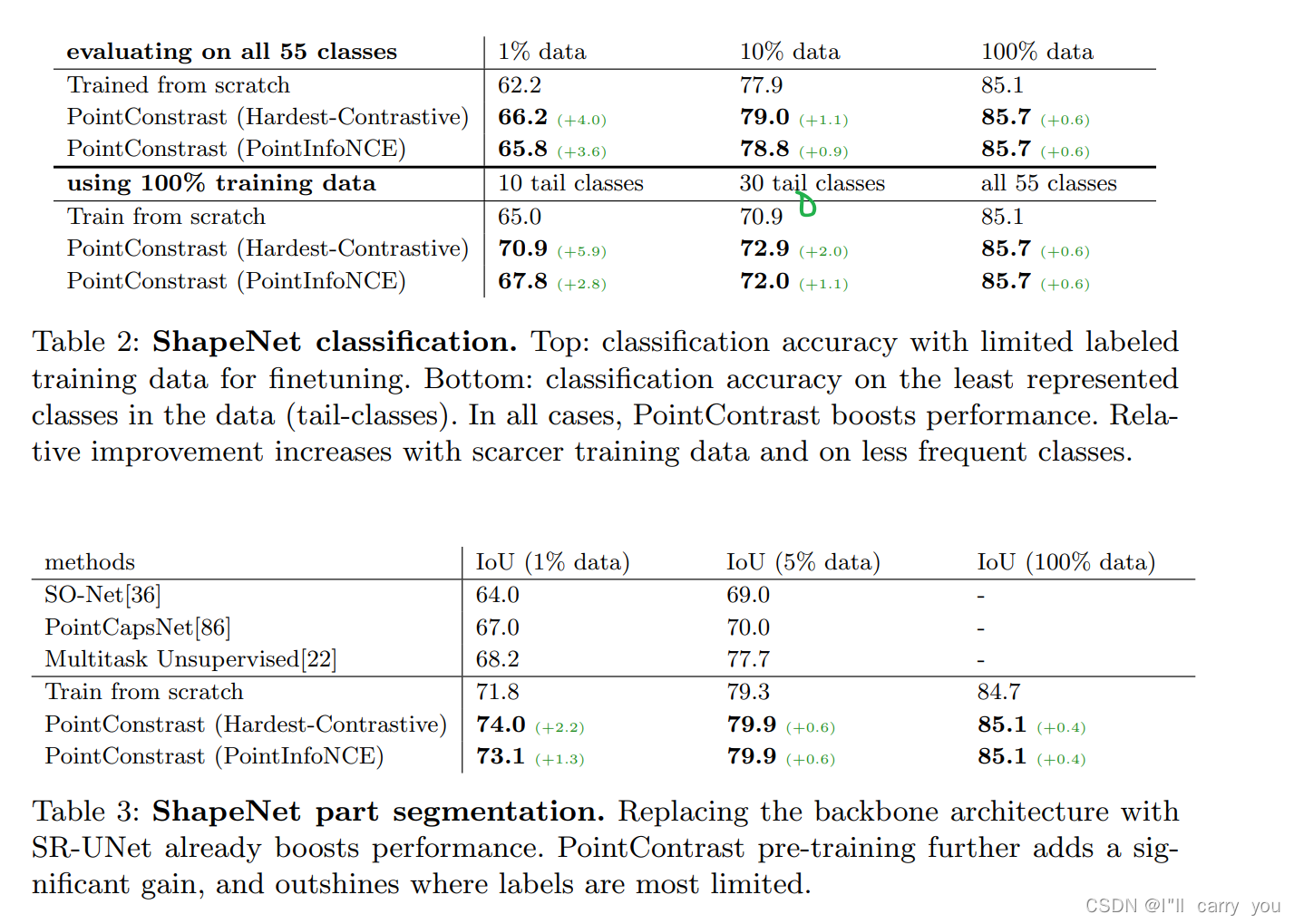
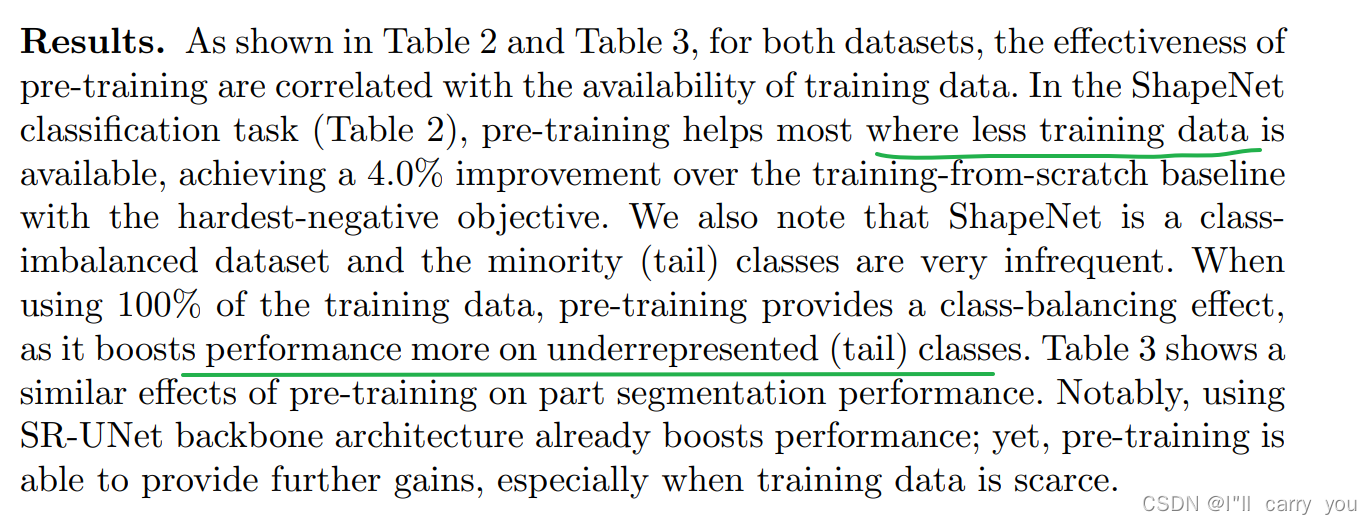
4.1 ShapeNet: Classification and Part Segmentation


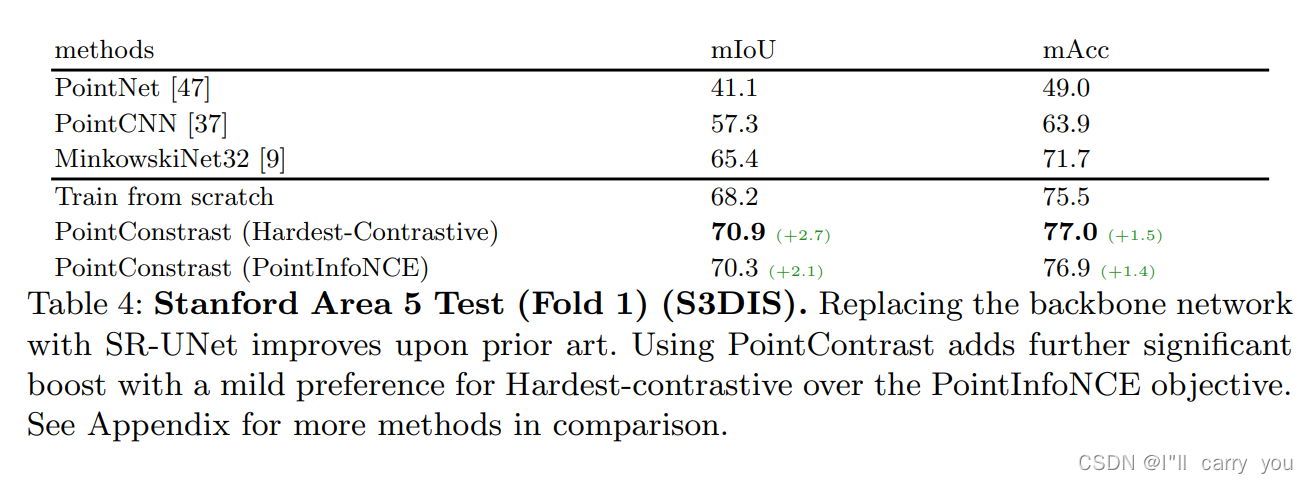
4.2 S3DIS Segmentation

4.3 SUN RGB-D Detection
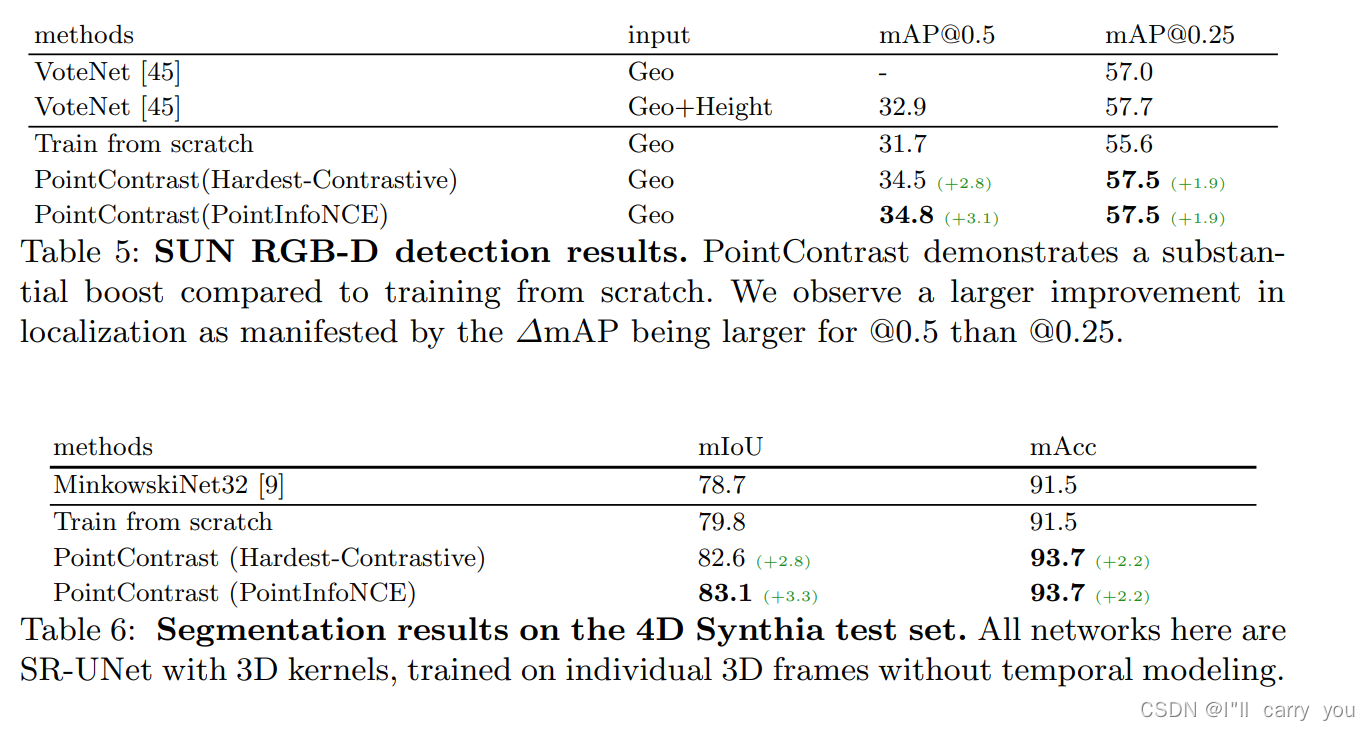
4.4 Synthia4D Segmentation
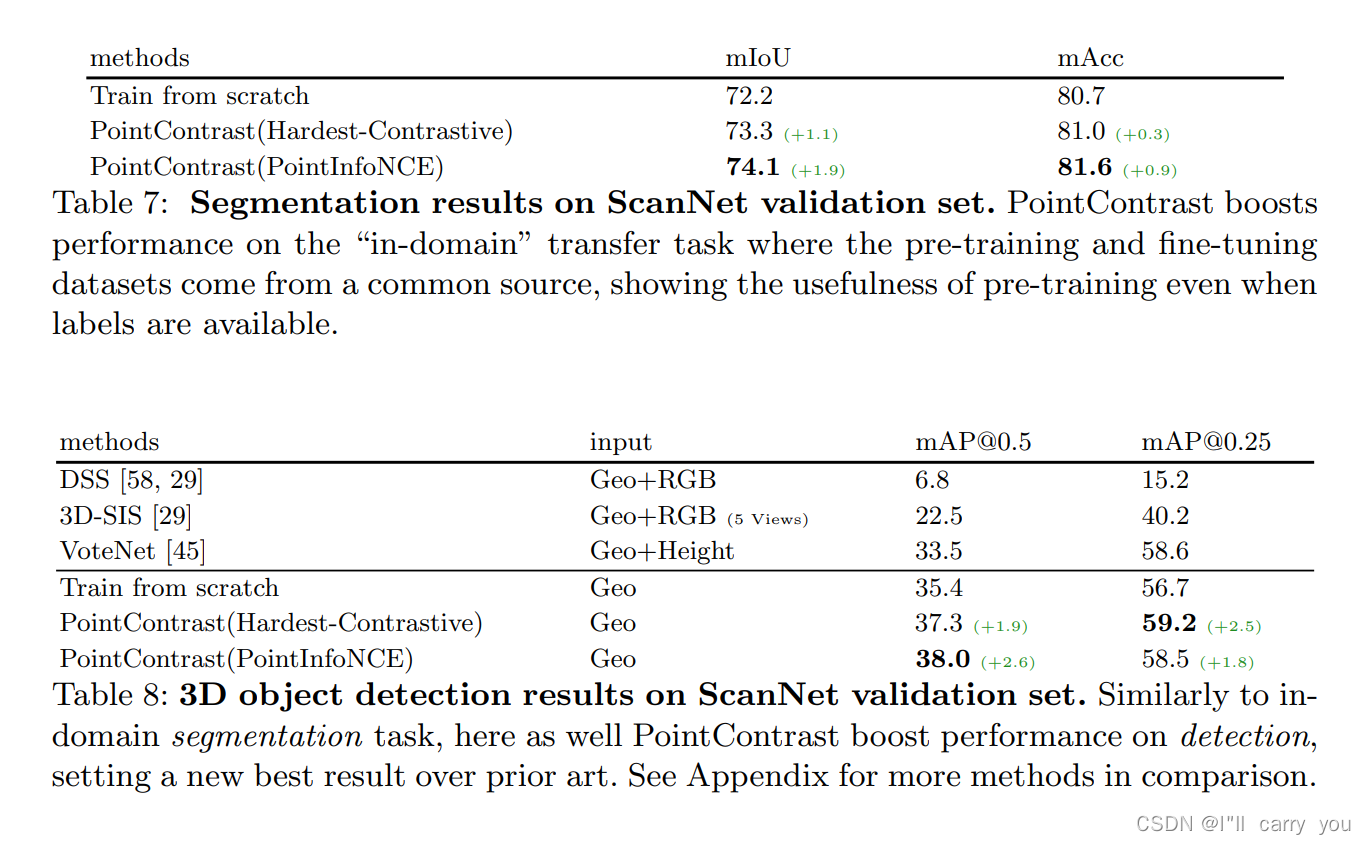
4.5 ScanNet: Segmentation and Detection
4.6 Analysis Experiments and Discussions
在本节中,我们展示了额外的实验,以提供对我们的预训练框架的更多见解。我们在下面的实验中使用 S3DIS 分割。
-
Supervised pre-training
- 虽然这项工作的重点是无监督预训练,但自然基线是与监督预训练进行比较。
- 为此,我们在 ScanNetV2 上使用从头开始训练的基线进行分割任务,并在 S3DIS 上微调网络。这产生了 71.2% 的 mIoU,仅比 PointContrast 无监督预训练好 0.3%。
- 我们认为这是一个非常令人鼓舞的信号,表明 3D 中监督和非监督表示学习之间的差距已基本缩小(参见 2D 中的多年努力)。
- 有人可能会争辩说,这是由于 ScanNet 的质量和规模有限,但即使在这种规模下,注释数千个房间所涉及的劳动力量也很大。
- 这一结果补充了我们迄今为止的结论:我们不仅应该将资源用于创建用于预训练的大规模 3D 数据集;但是如果要在扩展数据大小和注释数据之间进行权衡,我们应该倾向于前者
-
Fine-tuning vs from-scratch under longer training schedule
- 最近一项关于 2D 视觉的研究 [24] 表明,简单地从头开始训练更多的 epoch 可能会缩小与 ImageNet 预训练的差距。
- 我们进行了额外的实验,以在 S3DIS 上使用 2× 和 3× 调度从头开始训练网络,相对于我们默认设置的 1× 调度(10K 迭代,批量大小为 48)。
- 我们发现验证 mIoU 不会随着训练时间的延长而改善。
- 事实上,由于数据集规模较小,该模型表现出过拟合,在 20K 和 30K 迭代时分别实现了 66.7% 和 66.1% 的 mIoU。这表明许多 3D 数据集可能会落入“故障状态”[24],其中网络预训练对于良好的性能至关重要。
-
Holistic scene as a single view for PointContrast(整体场景作为 PointContrast 的单一视图)
- 为了表明 PointContrast 中的多视图设计很重要,我们尝试了一个不同的变体,
- 我们直接使用重建的点云 x(ScanNet 中的完整场景)PointContrast,而不是部分视图 x1 和 x2 。我们仍然对同一个 x 应用独立的变换 T1 和 T2。我们尝试了不同的变体和增强功能,例如随机裁剪、点抖动和丢失。
- 我们还尝试了不同自由度的 T1 和 T2 的不同变换。但是,使用最佳配置,我们可以在 S3DIS 上获得 68.35 的验证 mIoU,这仅比从头开始训练的基线 68.17 略好。这表明 PointContrast 中的多视图设置至关重要。
- 潜在原因包括:更加丰富多样的训练样本;由于相机不稳定性导致的自然噪声作为良好的正则化,如 [81] 中所观察到的
5 Conclusions
- 我们已经展示了对 3D 点云中学习表示到高级 3D 理解任务的可迁移性的广泛评估。
- 在我们的无监督预训练框架 PointContrast 的帮助下,我们在 6 个不同的基准测试中取得了最先进的结果,并证明了学习的表示可以跨域泛化。
- 我们希望这些发现将鼓励更多关于 3D 表示学习的研究
*