1.软件版本
matlab2019b
2.本算法理论知识
PPO算法是由OpenAI提出的,该算法是一种全新的策略梯度(Policy Gradient)算法,但是传统的策略梯度算法受到步长影响较大,而且很难选择出最优的步长参数,如果训练过程中,新策略和旧策略之间的差异过大将影响最终的学校效果。针对这个问题,PPO算法提出了一种新的目标函数,其可以通过多个训练步骤进行小批量的更新,从而解决了传统策略梯度算法中的步长选择问题。 但是PPO算法,其实现复杂度远低于TRPO算法。PPO算法的实现方式主要包括2种实现方式,第一种PPO算法是由CPU仿真实现的,第二种PPO算法是由GPU加速仿真实现的,其运行速度是第一种PPO算法的三倍以上。强化学习网络相对于传统的基于监督学习的神经网络算法,其实现困难之处在于梯度函数计算,损失函数计算方面,但是PPO算法在算法复杂度,精度以及实现难易度方面达到最优的平衡状态。
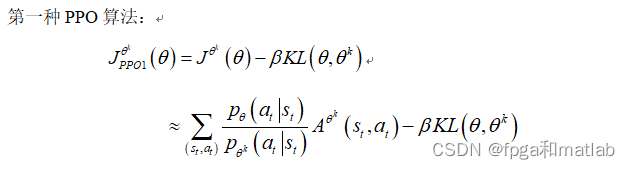
这种PPO算法实现过程较为简单,其类似TRPO算法的公式,通过参数进行限制性操作。