GHM Loss是Focal loss的升级版,它对难样本进行了深入的分析,认为并非所有的难样本都值得关注。有一些难样本属于标签错误的,不应该进行加强。GHM Loss根据loss的梯度模长(1-softmax(x) , 既输出值的导数)区间统计频率,用频率的作为系数,调节梯度值。因此,在GHM Loss中bin的最大值是1,此时GHM loss与交叉熵是完全一样的。关于GHM Loss更多描述详细可以参考
Gpytorch 12 支持任意维度数据的梯度平衡机制GHM Loss的实现(支持ignore_index、class_weight,支持反向传播训练,支持多分类)_万里鹏程转瞬至的博客-CSDN博客梯度平衡机制GHM(Gradient Harmonized Mechanism)Loss是Focal loss的升级版,源自论文https://arxiv.org/abs/1811.05181。Focal loss针对难易样本的不平衡而设计,通过调节系数可以缩小易样本在loss中的比例,使得难样本的loss权重变大。但是并非所有的难样本都是值得关注的,GHMLoss对梯度进行直方图统计,统计情况如图1所示。按照一定范围计算频率,将loss值与梯度模长频率的倒数相乘。这样子可以使容易样本(数量多,梯度值小..https://hpg123.blog.csdn.net/article/details/122567806之所以会实现paddle的GHM loss,是因为博主等待了很久都没有在paddle相关的官方库里面看到这个loss,因此在这里进行实现。
1、GHM Loss实现
需要注意的是博主实现的paddle版与torch版有所不同,这是因为paddle的一些api与torch有所不同。更重要的原因是,博主对api的使用更加娴熟。
import numpy as np
from paddle import nn
import paddle
from paddle.nn import functional as F
class GHM_Loss(nn.Layer):
#bins: 梯度模长的值(softmat(pred_x)的导数, 即1-softmat(pred_x),最大值为1)
def __init__(self, bins=0.1, weight=None, reduction="mean", ignore_index=None):
super(GHM_Loss, self).__init__()
self.class_dim = 1
self._bins = bins
self.reduction = reduction
self.ignore_index = ignore_index
self.nll_loss = nn.NLLLoss(reduction="none",ignore_index=ignore_index)
self.ce_loss_with_alpha = nn.CrossEntropyLoss(reduction="none", weight=weight, soft_label=False,axis=self.class_dim,ignore_index=ignore_index)
# 对于-log((sigmoid(x))与-log((softmax(x))函数,x对于x的导数为1-softmax(x)
def loss_grad(self, x, target):
print(x.shape,target.shape)
x_target = -self.nll_loss(x, target)
#print('x_target:', x_target)
return 1 - x_target
# 根据梯度模长与bins的大小计算每一个bin的倒频率信息
def calc_sample_weights(self, g, bins):
# 将梯度模长划分到具体的bin区间
# 如以0.1位间隔 [0.01,0.32,0.22,0.33,0.93]=>[0,4,2,4,10]
g_bin = paddle.floor(g / (bins + 0.0001)).astype('int64')
#g_bin = paddle.cast(g_bin, 'int64')
# 统计每一个区间的频率信息
max_bin = int(1 / (self._bins))
bin_count = paddle.zeros((max_bin,))
for i in paddle.arange(0,max_bin):
bin_count[i] = (g_bin == i).sum().item()
#print("bin_count:", bin_count)
# 取出非0的bin的数量,调整频次信息。避免大部分的beta=N / gd (倒频率系数),大于1
N = bin_count.sum()
nonempty_bins = (bin_count > 0).sum().item()
bin_count = bin_count * nonempty_bins
# 防止0做除数
#gd = paddle.clamp(bin_count, min=0.01)
gd = paddle.clip(bin_count, min=0.001, max=1e10)
# 计算每一个bin的倒频率信息
beta = N / gd
#print("N pixle:", N)
#print("bin_weight:", beta)
sample_weights = beta[g_bin]#与torch的用法不一样
return sample_weights
def forward(self, preds, target):
# 这一部分仅仅是为了计算权重系数,无需进行梯度计算
with paddle.no_grad():
# 需要注意,exp(x)可能会导致溢出
softmax_x = nn.Softmax(axis=self.class_dim)(preds.detach())
#print("softmax_x:",softmax_x)
# 获取目标数据的梯度模长
g = self.loss_grad(softmax_x, target)
#print("loss_grad:", g)
# 根据梯度模长与bin计算出倒频率信息,并计算出样本权重
sample_weights = self.calc_sample_weights(g, self._bins)
#print("sample_weights:", sample_weights)
# 计算出交叉熵的loss
#print("preds, target:",preds.shape, target.shape)
loss_of_ce = self.ce_loss_with_alpha(preds, target)
loss = loss_of_ce*sample_weights
if self.ignore_index is not None:
# 获取要忽略的类别的mask, target中不相等的loss值为0
valid_mask = (target != self.ignore_index).astype('int64')
#print('shape_before:',loss.shape,valid_mask.shape)
loss = loss[valid_mask==1]
#print('shape_after :',loss.shape)
return self.reduce_loss(loss, self.reduction)
def reduce_loss(self, loss, reduction='mean'):
return loss.mean() if reduction == 'mean' else loss.sum() if reduction == 'sum' else loss2、loss的使用
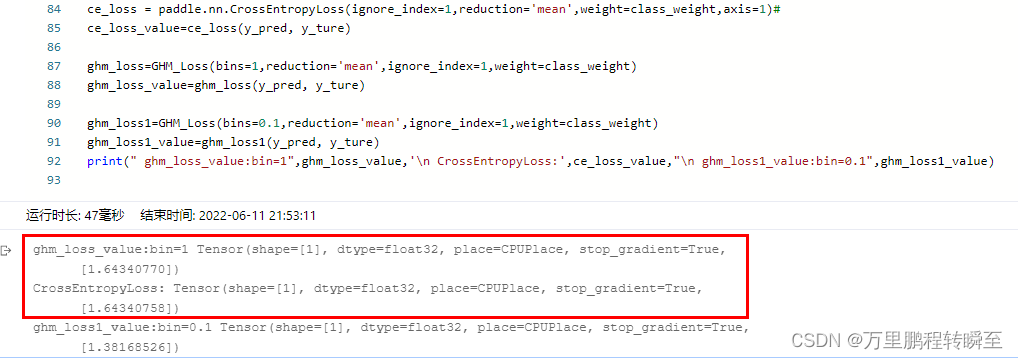
在这里使用GHM loss,在bin设置为1时,输出值与CE loss一模一样的。且在,reduction=mean时,输出结果也是与CE loss一模一样的。在设置class_weight后【博主也搞不定这个不一样】,mean的结果就有一些不一样的,但是sum的结果还是一模一样的。
y_pred=paddle.to_tensor(np.random.uniform(0,1,size=(10,5,32,32)),dtype=paddle.float32)
y_ture=paddle.to_tensor(np.random.randint(0,5,size=(10,32,32)),dtype=paddle.int64)
class_weight=None#paddle.to_tensor([2,1,0.5,0.2,0.1])
ce_loss = paddle.nn.CrossEntropyLoss(ignore_index=1,reduction='mean',weight=class_weight,axis=1)#
ce_loss_value=ce_loss(y_pred, y_ture)
ghm_loss=GHM_Loss(bins=1,reduction='mean',ignore_index=1,weight=class_weight)
ghm_loss_value=ghm_loss(y_pred, y_ture)
ghm_loss1=GHM_Loss(bins=0.1,reduction='mean',ignore_index=1,weight=class_weight)
ghm_loss1_value=ghm_loss1(y_pred, y_ture)
print("alpha=[2,1,0.5,0.2,0.1], gamma=0")
print(" ghm_loss_value:bin=1",ghm_loss_value,'\n CrossEntropyLoss:',ce_loss_value,"\n ghm_loss1_value:bin=0.1",ghm_loss1_value)代码输出结果如下所示
3、编码经验
以前博主一直用torch.where生成mask进行数据选择,后面通过观摩paddle官方中focal loss的实现后学习到了使用bool 运算直接生成mask去获取特定值。
if self.ignore_index is not None:
# 获取要忽略的类别的mask, target中不相等的loss值为0
#print('shape_before:',loss.shape,valid_mask.shape)
loss = loss[target != self.ignore_index]此外,paddle api与torch api在某些函数上是不一样的。除了paddle.where,还有以下
值域裁剪:torch gd = torch.clamp(bin_count, min=0.01)
值域裁剪:paddle gd = paddle.clip(bin_count, min=0.001, max=1e10) 需要人为指定另一个值0(设置最大值或者最小值)